中国上市公司“高送转”预测研究
——基于灰色预测与支持向量回归模型混合分析
2021-11-22麦继芳赵海清
麦继芳,赵海清
(岭南师范学院 数学与统计学院,广东 湛江 524048)
近年来,我国证券市场的快速发展催生了一批题材股.其中,“高送转”题材股深受国内外众多学者关注.对“高送转”预测问题的研究,现行的主要研究方法有logistic 回归分析方法及logistic 模型与其他模型相结合的分析方法.文献[1]采用logistic 回归模型对创业板上市公司“高送转”的影响因素进行分析,研究结果表明:创业板上市公司“高送转”的主要影响因素是公司总市值及其股价.文献[2]使用logistic 回归模型与主成分分析相结合的方法,构建高送转股票的预测模型,预测准确度最高可达80.91%.文献[3]运用logistic 回归模型和支持向量机集成的方法对上市公司是否实施“高送转”行为进行预测分析.文献[4]采用 logistic 回归和决策树方法构建两种预测模型,最后基于损失函数确定权重将两种预测模型按权重进行线性组合建立组合模型,预测准确度最高可达85.19%.笔者在已有的研究基础上,结合灰色预测模型与支持向量回归模型的优势,混合应用灰色预测模型与支持向量回归模型对上市公司是否“高送转”进行预测分析.
1 研究方法
1.1 Lasso 方法
Lasso 方法[5]是将参数估计与变量选择同时进行的一种正则化方法.它通过构造一个惩罚函数,使得一些不显著变量的系数压缩为零的方式进行特征变量选择,其参数估计公式为:

1.2 灰色预测模型
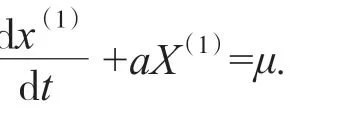
其中,X(1)为X(0)进行一次累加得到的序列,序列为X(1)={X(1)(k),k=1,2,…,n},序列X(0)={X(0)(i),i=1,2,…,n}为一非负单调原始数据序列.灰色预测模型的优点是预测精度高,参数估计方法简单.
1.3 支持向量回归模型

2 指标设置及数据预处理
数据源自2012 至2019 年的沪深股市A 股,共3 466 个上市公司的样本数据.结合现有的数据特征,笔者挑选20 个特征变量进行研究分析(见表1).
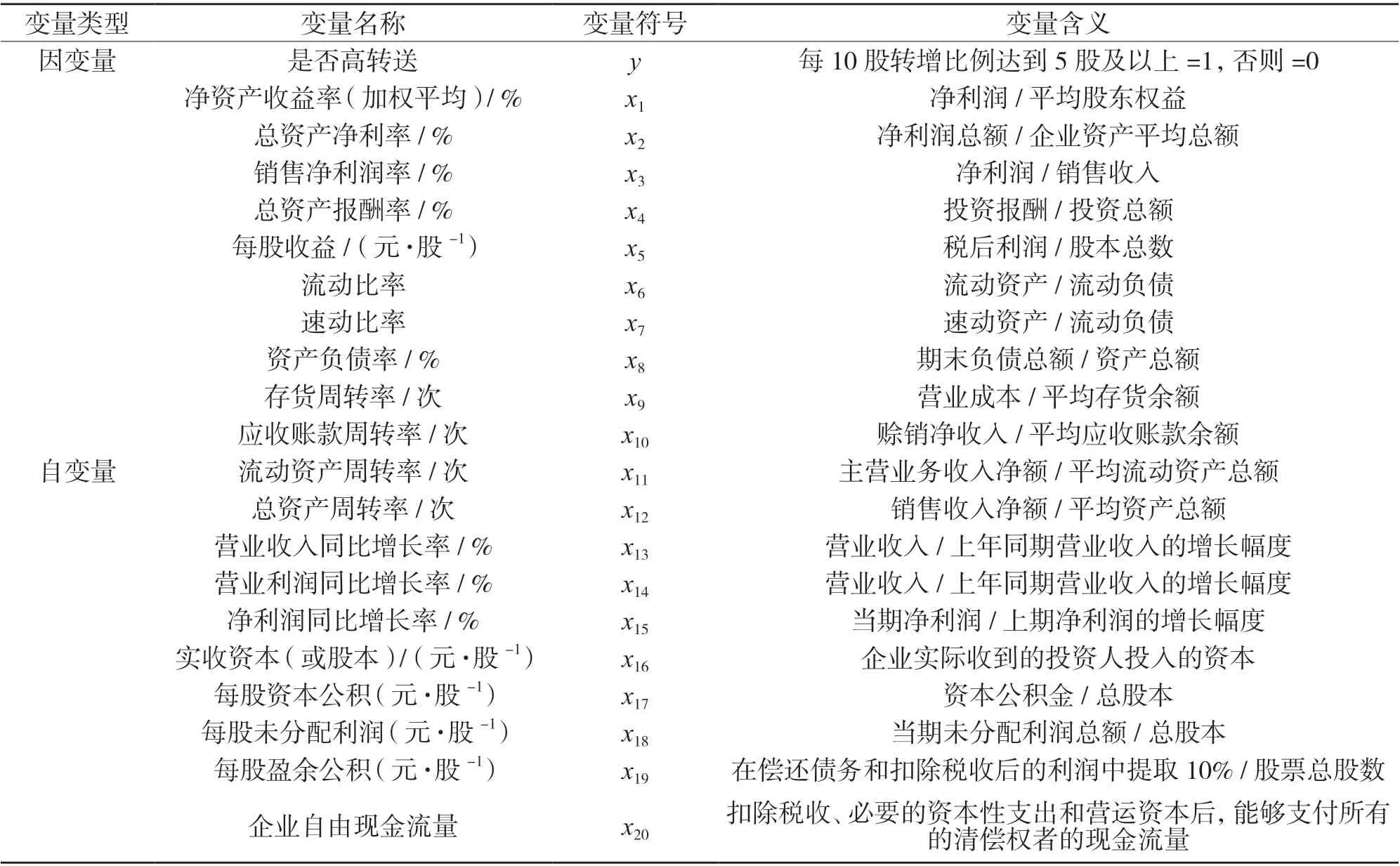
表1 初步筛选的变量
在进行模型构建前,若没有对数据进行合理的清洗就直接用于建立模型,会导致模型的拟合结果出现严重偏差,因此在建模之前对数据进行清洗就显得尤为必要.数据预处理过程分3 个步骤完成:(1)缺失数据的处理.由于原始数据量大,缺失数据占比非常少,直接删除缺失样本数据对后续问题分析影响不大,因此对缺失样本数据采取直接删除的处理方式.(2)异常值处理.利用3σ原则对异常值进行处理,将超过上下限的极端值分别用-3*σ或+3*σ替代[9].(3)为了消除数据的量纲影响,便于不同量级的指标能够进行加权和比较,对所有的特征数据进行标准化处理.
3 结果分析与讨论
3.1 相关性分析
若自变量间存在高度相关关系,模型估计的准确性将会降低,甚至会出现违背经济意义的现象.为了识别自变量间是否存在高度相关关系,对自变量进行相关性分析.由表2 可知,x2和x4、x2和x5的、x4和x5、x6和x7、x6和x8之间的Pearson 相关系数分别为0.98、0.64、0.64、0.98、-0.62,表明自变量间存在多重共线性问题.
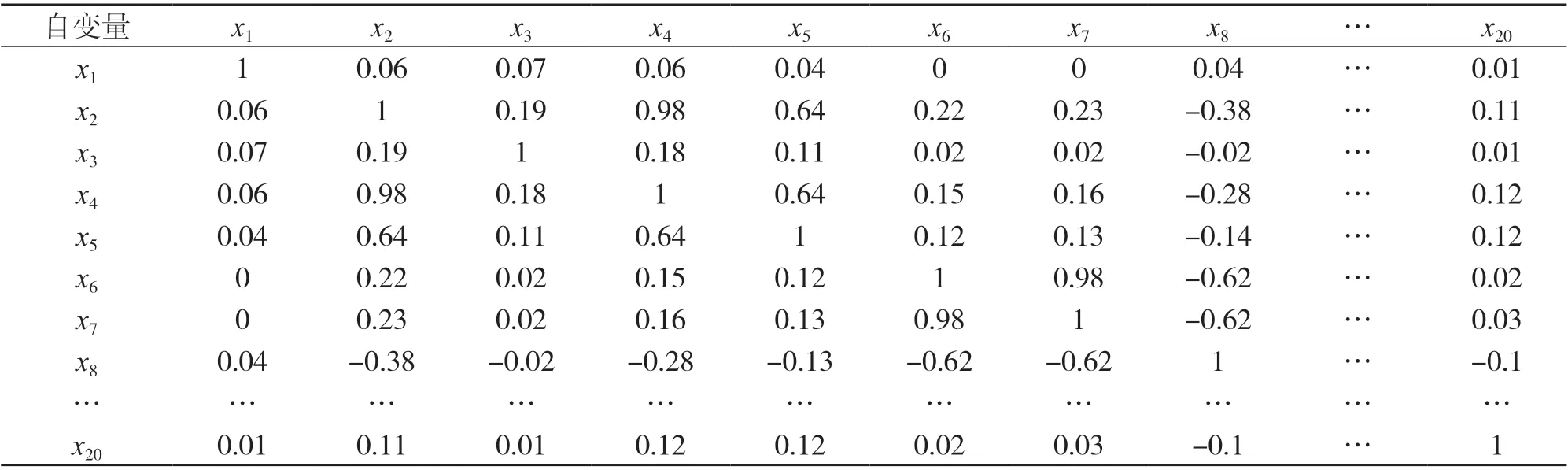
表2 各自变量间的Pearson 相关系数
3.2 Lasso 特征变量选择方法
由相关性结果分析可知,自变量间存在多重共线性问题,需对自变量进行筛选处理.利用Lasso 算法进行变量筛选,对公式(1)的中的参数进行求解,对于每个给定y值,该算法会寻找一个最优的λ,使得某些系数压缩为零,从而达到特征变量选择的目的.使用python 编程计算得出自变量的系数 .由计算结果可知,净资产收益率(x1)、每股收益(x5)、速动比率(x7)、资产负债率(x8)、流动资产周转率(x11)、净利润同比增长(x15)、每股资本公积(x17)和每股未分配利润(x18)这8 个自变量的系数表现为非零,其他12 个自变量的系数全部为零(表现不显著).因此,剔除系数为零的自变量.
进一步分析可知,净资产收益率(x1)、每股资本公积(x17)和每股未分配利润(x18)可看作为一个公司盈利的一部分,能确保获得一定的盈利空间,这可作为送转股的前提条件. 从公司管理者的视角分析来看,公司是否能分配到利润、盈余公积和资本可对公司实施“高送转”方案起到关键性作用.
每股收益(x5)与“高送转”行为之间有着较强的正相关关系.王琛[8]在中小板上市公司股票“高送转”市场反应及影响因素研究中也证实了当中小板上市公司的股价越高,公司实施“高送转”方案的可能性越大.众所周知,我国证券市场以中小投资者为主,过高的股价会让他们产生“恐高情绪”,不利于投资者投资,股价过低又会使变现成本高.所以当股价过高时,企业通过拆分股票等行为让股价降低,从而激发投资活力.因此,股价越高的公司越容易发生“高送转”行为.又由于速动比率(x7)=速动资产/流动负债*100%,即速动比率越高,企业的速动资产越多,更倾向于发生“高送转”行为.
资产负债率(x8)、流动资产周转率(x11)和净利润同比增长(x15)都与企业实施“高送转”行为成反比,即资产负债率、流动资产周转率和净利润同比增长越低,企业实施“高送转”的可能性越高.综上,以上结论与实际情况基本相吻合.
3.3 构建预测模型
首先,对2012—2018 年的数据(本文称为历史数据集)分别建立logistic 回归模型和支持向量回归模型(训练模型);接着,对每个特征因素建立灰色预测模型,得到各个特征因素2019 年的预测值;最后,将建立好的训练模型与灰色预测模型相结合,对各上市公司2019 年的“高送转”情况进行预测,并将预测值与真实值进行对比分析.
基于Lasso 方法挑选出来的特征变量,对2012-2018 年的数据分别建立logistic 回归模型和支持向量回归模型,所得回归结果见表3.由logistic 回归模型回归结果可知,仅有特征变量x5、x7和x17表现显著,其残差离差值为:290.74,AIC 值为308.74;由SVR 回归结果可知,在3 466 家上市公司中,支持向量数目达3 277 个,训练误差率为0.054.
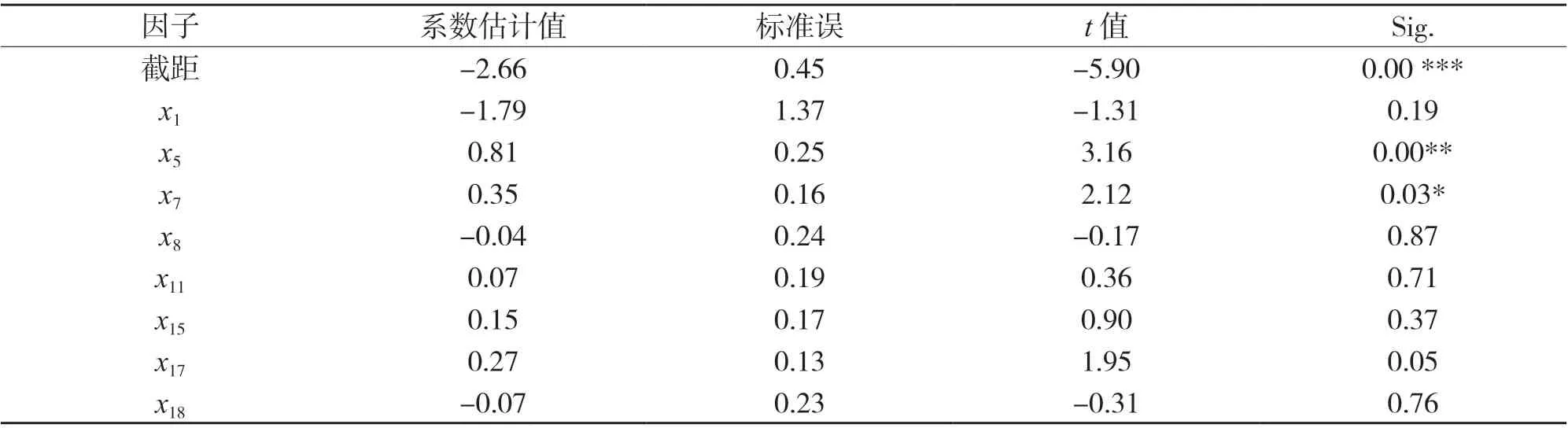
表3 logistic 模型的回归分析结果
对2012—2018 年每只股票各影响因素特征值的数据建立灰色预测模型,预测出2019 年各影响因素的特征值.以下以第一支股票为例,表4 展示了第一支股票2019 年各影响因素特征值的预测结果,由于篇幅原因,以下仅展示本文第一支股票x7与x18的真实值与预测值的对比效果.该只股票所有变量的预测效果都通过预测精度检验.图1 显示了自变量与的预测值x7与x18真实值较接近,再次验证了这两个特征变量的预测效果良好.

表4 第一支股票2019 年各变量预测值
将以上各个特征的灰色预测模型预测结果分别代入已构建好的logistic 回归模型和支持向量回归模型中进行拟合,比较分析以上两种方法得到的测试结果(见表5).由表5 可知,混合应用灰色预测模型与支持向量回归模型预测的准确率约为94.52%,而混合应用灰色预测模型与logistic 回归模型预测的准确率约为71.12%,前者比后者的预测准确率大约提高了23.40%,表明前者所得预测效果更加接近真实情况.图1 为灰色预测模型与支持向量回归模型混合应用的预测值与真实值的对比分析结果.结果显示,除了少部分预测值有所偏离真实值,大部分预测值与真实值近乎重合,再次证明了混合应用灰色预测模型和支持向量回归模型相结合的研究方法更适用于预测上市公司“高送转”情况.

表5 模型预测结果比较
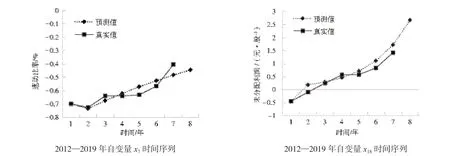
图1 预测值与真实值对比图
4 结语
笔者通过混合应用灰色预测模型和支持向量回归模型对上市公司是否实施“高送转”进行研究.首先,使用Pearson 相关系数分析方法进行分析,发现自变量间存在严重的多重共线性现象.因此,使用Lasso 变量选择方法进行变量选择,得到8 个影响的因子.基于Lasso 方法挑选出来的特征变量,对历史数据分别建立logistic 回归模型和支持向量回归模型(训练模型),紧接着建立灰色预测模型,得到各个影响因素2019 年的预测值.再将灰色预测分析的结果分别代入以上两个训练模型中,预测各个上市公司2019年的“高送转”实施情况.通过比较分析预测值与真实值的结果,证明了灰色预测模型和支持向量回归模型相结合预测上市公司是否实施“高送转”更可靠.
