利用随机森林的单粒子翻转软件故障注入方法
2021-11-22曹子宁
程 义,庄 毅,曹子宁
(南京航空航天大学 计算机科学与技术学院,南京 211106)
1 引 言
随着嵌入式应用程序领域内技术的迅速发展,计算机应用程序在复杂性和规模都在不断增长.同时,严格的功率限制和元器件冗余的减少促使半导体行业从业者在设计集成电路时继续精简结构降低电压.这种趋势一方面使硬件元器件高度集成化,另一方面提高了其对外部硬件故障的敏感性,如辐射效应或电磁干扰等[1]引发的硬件故障.这对嵌入式系统的设计和开发提出了新的挑战.
航空航天领域的工作环境中存在着大量的高能粒子,这些高能粒子会引发一系列的单粒子效应,影响相关计算机设备的正常运行.单粒子效应(Single Event Effect)是指高能带电粒子穿过微电子器件的灵敏结构时,造成器件逻辑状态的非正常改变或器件损坏的现象[2].单粒子翻转是高能带电粒子使元器件的逻辑状态发生翻转的一种单粒子效应[3].
为了提高嵌入式系统的可靠性,在设计时就需要对系统中潜在故障进行分析并采取一系列手段对相应的故障进行检测、恢复或补偿.随机或永久性的硬件故障都会对系统运行的各个层面产生不同的影响.相较于永久性的硬件故障,计算机硬件的瞬时故障存在时间和空间的随机性和不可预测性.这使得该类瞬时故障问题更加难以应对,并提高了应对瞬时故障能力在设计可靠性系统时的重要性.故障注入技术是现行可靠性评估技术的主要方法之一,被广泛应用在各个领域[4-6].相关安全标准(如ISO 26262[7])也强烈建议在验证嵌入式系统的可靠性时应用故障注入技术.主流的故障注入技术按照所注入故障的方式分为硬件故障注入和软件故障注入两类[8].硬件故障注入技术存在成本高、自动化水平低等缺陷;而软件故障注入技术,不仅可以较好地模拟硬件故障,而且可以对应用程序产生直接影响,更受到研究者与开发人员的青睐.
故障按照对应用程序产生的影响分为:控制流错误和数据流错误两大类[5].目前这两种故障的软件注入技术都得到了长足研究和广泛应用.但是同时兼顾控制流错误和数据流错误的软件故障注入研究和工具较少.另一方面传统的故障注入工具注入故障的方案较为简单,一般是仅在某条指令处随机的注入单粒子翻转故障[2,9,10].事实上这些注入的故障不一定能引发程序的控制流错误和数据流错误,有些甚至属于无效故障,即故障注入前后程序运行和执行结果没有发生变化.因此设计能够同时兼顾控制流错误和数据流错误,且能够通过智能决策注入有效故障的故障注入工具成为当下亟需探索的研究方向.
本文主要贡献如下:在通用嵌入式计算机硬件架构的基础上,讨论了主要硬件器件能否产生控制流和数据流错误及其对程序运行的影响;并在此基础上提出了一种基于随机森林的故障注入方法,设计并且实现了该系统.该系统使用随机森林方法,根据被注入程序的指令的各项特征,对程序指令各个器件发生单粒子翻转故障的敏感性预测,生成故障序列,最后在程序运行时根据故障序列,对程序进行自动故障注入.相比已有方法,本文所提出的基于随机森林的单粒子翻转模拟软件故障注入方法具有实施成本低、自动化水平高、故障覆盖率高、故障有效率高等优点.相关实验证明了本文所提出方法的有效性和优越性.
2 相关工作
目前程序故障注入的方法主要分为两大类:硬件故障注入与软件故障注入.其中软件故障注入还分为传统的软件故障注入和基于机器学习的软件故障注入.
2.1 硬件故障注入
基于硬件的故障注入方法通常在附加硬件设备的辅助下,将故障注入到系统中[8].这类故障注入的方法往往需要定制的硬件设备,具有实施成本高、设备特异性、耗时时间长、无法自动化、结果难观察、降低硬件使用寿命等问题.现阶段的主要研究工作是通过一些硬件调试设备对硬件设备进行故障注入,或者通过软件仿真模拟硬件设备的方式来实现自动化故障注入.Zhang等人提出了基于管道的故障注入技术[11],通过该技术可以加快故障注入的流程,从而能够对基于SRAM的FPGA中发生的单粒子翻转故障进行模拟.Bhattacharya提出一种基于FPGA的故障仿真技术[12],可在设计的早期阶段设计和开发测试资源,验证测试台以及互连电路.Khosrowjerdi等人提出了一种虚拟化故障注入方法[13],该方法集成了QEMU、GDB和LBTest,能够自动化的生成故障并注入到嵌入式系统中.Coelho等人设计了一种名为NETFI-2的故障注入平台[14],该故障注入平台能够在FPGA中模拟单粒子翻转故障并注入到集成电路中.Moorthi基于FPGA设计了一套可编程的硬件故障注入框架[15],使用该框架可以将模拟生成单粒子翻转故障,并将该故障注入到指定的元器件.这些硬件故障注入方法可以较好的模拟单粒子翻转故障现场,但是存在故障注入方案泛化性差、实施成本高和单次故障注入开销大等缺点.
2.2 传统的软件故障注入
除了用物理手段进行故障注入的方法,基于软件的故障注入技术也是一类常见的故障注入技术.软件故障注入通过特定的程序对系统软件、硬件错误状态进行仿真[16].较之硬件故障注入方法,软件方法具有实施成本低、能够针对特定的程序、易于观察故障注入效果、可以对注入故障进行追踪、可特定针对控制流或者数据流错误进行故障注入、故障注入开销小的特点.现有的研究工作一般针对数据流或者控制流错误,来研究发生相应故障对程序的影响,进而提出了相应故障的容错算法.如Porpodas设计了一种基于时序的故障注入工具ZOFI[17],这种故障注入工具能够模拟发生在寄存器上的瞬态故障并注入.Ahmad等设计了一种纯软件的故障注入技术LDSFI[18],该技术可以在程序运行时自动的将单粒子翻转故障注入到二进制代码中.Osinski等人通过考虑微体系结构和应用程序级别的单个故障的假设[19],讨论分析了不同策略下注入控制流错误以及相应的差异.Zhang等人基于LLFI设计了一种模拟分析瞬时故障的方法[20],并使用该方法研究了指令SDC脆弱性.这些软件故障注入方法在故障注入时一般采用随机的方式,极易注入无效故障.并且这些故障注入方法由于使用的场景仅限于数据流或者控制流错误,存在泛用性较差等问题.
2.3 基于机器学习的软件故障注入
为了减少软件故障注入的成本和增加故障注入技术的泛用性,一些机器学习算法被运用到了软件故障注入技术中.如Yang等人基于SVM提出了PVInsiden[21],该技术使用SVM来识别指令是否是易导致数据静默错误(Silent Data Corruption,SDC)的指令,但是这种方案仍然只适用于数据流错误,对控制流错误无效.Jha等人提出了一种基于机器学习的故障注入引擎DriverFI[22],能够挖掘自动驾驶汽车的影音系统的安全性和故障.该引擎主要针对内存中的单粒子翻转引发的数据流错误,不能注入CPU中器件的单粒子翻转故障和一些控制流错误.
2.4 小结
综上所述,基于硬件故障注入方法虽然具有贴近单粒子翻转现场优点,但存在成本高,注入位置随机、不能指定程序进行故障注入,难以观察故障注入的结果、易对硬件造成损坏等问题.传统的基于软件的故障注入方法存在注入故障的有效性难以保证,并且只针对控制流错误或数据流错误,存在故障覆盖率低等问题.但是基于软件的故障注入技术实施成本低,能够指定注入故障的程序,还具有易于追踪注入的故障、观察注入故障的结果等优点.而基于机器学习的故障注入技术能够有效的对故障空间进行剪枝,增加注入故障的有效性,但是目前缺少能够同时兼顾数据流和控制流的故障注入技术.本文在使用传统的故障注入技术注入形成的原始故障集的基础上,使用随机森林算法生成指令脆弱性预测模型,使用该模型能够预测程序指令对各个部件单粒子翻转的脆弱性;进而在此基础上形成被注入故障程序的故障序列,即故障注入时在指令对应的故障序列中选取较为脆弱的故障进行故障注入,提高故障注入的有效性.
3 单粒子翻转故障
硬件级别的单粒子翻转故障会影响程序行为,例如内存或者寄存器中的数据错误会影响程序的控制流和数据流错误.分析计算机的体系结构,单粒子翻转故障可以在系统中的任何抽象层次传播.星载、机载等嵌入式计算机的硬件架构如图1[23]所示.

图1 星载嵌入式计算机通用系统架构
单粒子翻转故障主要发生在处理器和存储部件或者非标准的设备(如摇杆、打印机)中[5],其他的硬件器件发生单粒子翻转的概率较低.其他部件的单粒子故障最终都可以映射为处理器和内存中的单粒子翻转故障.按照故障发生的硬件位置,单粒子翻转故障可以分为处理器故障、存储器故障等.其中处理器故障又可以划分为寄存器和运算单元故障,而存储故障又可以分为内存故障和外存故障.表1总结并描述了硬件故障类型,并列举了对应的数据/控制流错误类型.由于大部分外部设备通过总线传输数据,因此将这些外部设备的故障归类为总线错误.从表1中我们不难看出指令译码器、内存、外存中同时存在控制流错误和数据流错误.

表1 硬件故障类型
指令译码器负责将复杂的机器语言指令解译成运算逻辑单元(ALU)和寄存器能够理解的格式即相应的电气信号.因此当指令译码器中发生单粒子翻转故障时,可能导致非跳转指令翻转为跳转指令,继而引起程序跳出正常的执行顺序,表现为控制流错误;当指令译码器遇到跳转指令,跳转的目的地址因为位翻转而程序跳出正常的执行顺序,也表现为控制流错误.一般以上两种情况较为少见,发生在该元件中的更多的是数据流错误.
发生在内存中控制流错误主要是发生在代码区.与指令译码器中的类似,出现非跳转指令翻转为跳转指令和跳转指令的目的地址发生翻转,而表现出的控制流错误.该类错误属于瞬态错误,当重新读入程序时,即可纠正该类错误.外存中控制流错误出现的原因与内存中出现的原因一致.此外发生在内存和外存中的位翻转而导致的程序故障是持续性的,这种持续性体现在内存和外存中的单粒子翻转故障不像是指令寄存器、指令译码器中的故障属于“一次性”的:指令寄存器、指令译码器中的单粒子翻转不会影响到下次执行本条指令.但是内存和外存中的单粒子翻转故障下次执行同样的指令,相同的故障仍会发生.这是因为内外存中保存的指令一旦发生单粒子翻转,程序执行时在取指令阶段读取到的指令都是翻转后的指令.这种持续性的故障可以通过重新载入/编译程序来解决.
下面以图2中的汇编代码为例,分析各个硬件设备可能导致的数据流错误:1)若在指令寄存器保存指令2时发生单粒子翻转,翻转后的机器码为:8b 45 fb,则对应的汇编代码为:mov-0x5(%rbp),%eax,则寄存器eax中的数据保存向错误的内存地址,发生数据流错误;2)指令译码器发生数据流错误的情形和指令寄存器类似,但是故障发生在指令译码时,指令译码器的单粒子翻转故障可以等效为指令寄存器中的指令在同位置发生单粒子翻转故障;3)操作控制器主要负责决策寄存器之间建立数据通路的任务,若在执行指令1时发生单粒子翻转,本该保存到寄存器edx中的数据保存到其他寄存器中,则会影响到指令3的执行结果造成数据流错误,可以等效为指令寄存器中的指令在同一位置发生单粒子翻转故障;4)若执行指令2时,CPU中的寄存器edx发生单粒子翻转故障导致数据流错误,会对指令3执行的数据结果为错误结果;5)逻辑运算单元、总线单元、数据高速缓存中发生单粒子翻转故障,都是通过寄存器简介造成数据流错误,他们中数据的来源和去向都是寄存器,一般可以视为寄存器单粒子翻转故障;6)指令4属于访存指令,通过变址寄存器rbp和偏移地址-0x14访问内存,并将内存中的数据存储到寄存器eax中,若执行指令4时,要访问的内存发生单粒子翻转故障,则存储到寄存器eax中的数据就出现错误,导致数据流错误;7)外存中的单粒子翻转故障更多的是影响保存在外存中的程序,如1)指令2翻转为8b 45 fb,也会造成数据流错误,可以视为程序载入内存时发生在内存中的单粒子翻转故障.
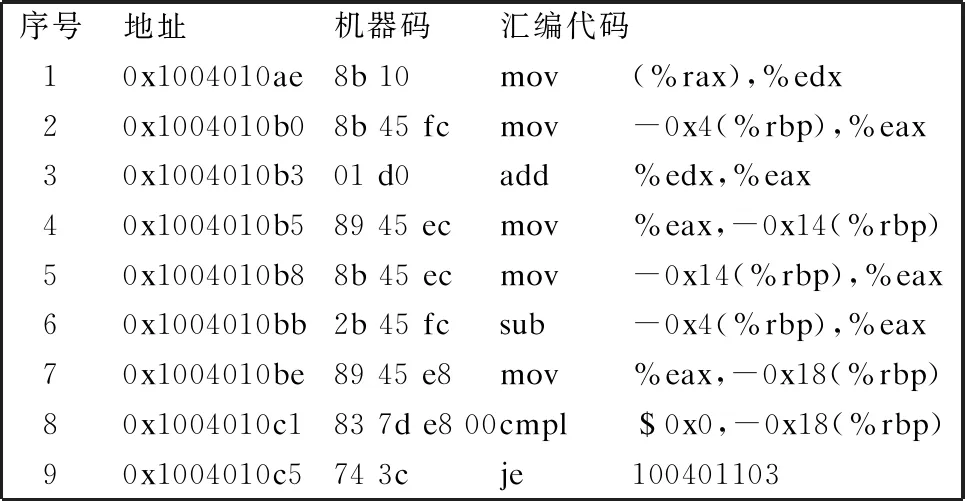
图2 x86-64汇编代码示例
下面分析图2中可能发生的控制流错误:1)程序计数器中保存的当前执行指令的下一个指令,如执行指令1时,此时程序计数器中的内容应为:0x1004010b0,即为指令2的内存地址,若程序计数器发生单粒子翻转故障,使得程序计数器中的内容翻转为0x1004010b3,则执行完指令1后程序执行指令3,程序出现控制流错误;2)指令寄存器、指令译码器发生控制流错误,通常是单粒子翻转故障发生在跳转指令使得跳转指令变为其他指令,或者更改程序跳转的目的地址,使得程序发生控制流错误,比如指令9发生单粒子翻转故障je指令变成jne指令或者跳转的目的地址变为0x1004010ae,可以等效为指令寄存器中的指令在同位置发生单粒子翻转故障;3)内存、外存中的控制流错误与指令寄存器、指令译码器类似,都是由于位翻转瞬时故障发生在跳转指令或者更改目的地址时,使得程序发生控制流错误.
从上面可以看出各类硬件的单粒子翻转故障都可以等效的看作寄存器单粒子翻转故障和内存单粒子翻转故障;并且同一指令发生单粒子翻转的硬件器件不同,发生在同一硬件器件上翻转的位置不同对程序造成的影响也不同;同时单粒子翻转故障注入时需要的参数为翻转的部件和翻转的位置.因此在设计故障注入系统的故障注入决策时,必须掌握被注入故障的指令对器件发生单粒子翻转故障和翻转位置的敏感性,以及被注入故障的指令发生数据流/控制流错误与注入故障器件和翻转位置的相关性,以达到单粒子翻转故障的高效注入.
4 指令单粒子翻转脆弱性特征提取
从第3节可知在某些指令处注入寄存器单粒子翻转故障不会引发程序故障,有些指令对注入的内存单粒子翻转故障不敏感.因此研究指令单粒子翻转脆弱性,是提高故障注入有效性的关键.为了研究指令对器件发生单粒子翻转故障和翻转位置的敏感性,以及被注入故障的指令发生数据流/控制流错误与注入故障器件和翻转位置的相关性,我们定义指令单粒子翻转的脆弱性为发生单粒子翻转后导致程序发生故障的概率,指令数据流脆弱性为发生单粒子翻转后导致程序发生数据流错误的概率,指令控制流脆弱性为发生单粒子翻转后导致程序发生控制流错误的概率.为了注入故障的有效性,必须在故障注入时根据注入故障的类别(数据流错误、控制流错误和两者兼有之的故障),在相应的脆弱性中选择最高的故障选择注入.下面对影响程序的脆弱性的指令特征进行分析,为指令脆弱性的预测提供依据.
4.1 寄存器单粒子翻转脆弱性特征
本节讨论发生在寄存器上的单粒子翻转.指令的单粒子翻转脆弱性与下面几个因素有关:1)指令类型;2)指令操作数个数;3)寄存器类型.首先指令类型与指令单粒子翻转的数据流/控制流脆弱性相关,在保持其他条件不变的情况下执行周期长的指令容易发生单粒子翻转,从而引发程序发生数据流/控制流错误.跳转指令与其他指令相比更不容易发生数据流错误,这是因为跳转指令不使用数据寄存器,所以跳转指令对通用寄存器中的单粒子翻转瞬时故障有天然的屏蔽作用;其次指令操作数的个数与指令单粒子翻转的数据流脆弱性相关,在保持其他变量不变的情况下,操作数数量越多单粒子翻转命中使用的寄存器的概率越高.最后,发生单粒子翻转的寄存器类型与指令的数据流/控制流脆弱性相关.在保持其他条件不变的情况下,显然程序计数器发生单粒子翻转故障时必然会导致控制流错误.而指令寄存器较大概率导致控制流错误.而一些通用寄存器由于使用频率较低,即使发生单粒子翻转,也不一定会导致程序发生故障.
4.2 内存单粒子翻转脆弱性特征
本节讨论了发生在内存中的单粒子翻转.指令的单粒子翻转脆弱性与下面几个因素有关:1)指令在程序执行序列中的位置;2)发生单粒子翻转的内存地址.
指令有效故障空间是指:程序在执行到对应指令时发生单粒子翻转会导致程序故障的内存地址范围.执行到某些指令时,部分内存单元在本程序结束前都不会再使用,所以这片地址空间发生的单粒子翻转故障不会引起程序故障.程序执行序列中不同指令有效故障空间不同;发生在数据区、堆栈区的单粒子翻转故障只会导致程序出现数据流错误;代码区的单粒子翻转故障,仅在操作码由非跳转指令翻转转为跳转指令或跳转指令翻转为非跳转指令时才会造成控制流错误.而指令操作码在一个指令中占比较小,因此发生在代码区的单粒子翻转在多数情况下仍属于数据流错误.
5 基于随机森林的故障注入框架
基于上述影响指令数据流/控制流的脆弱性的特征分析,本文提出了基于随机森林的故障注入的基于随机森林的故障注入框架.本文设计的基于随机森林的故障注入框架整体流程如图3所示.包含指令脆弱性预测模型建立、故障序列生成和故障注入3个部分.下面对3个部分分别进行介绍.

图3 基于随机森林的故障注入
5.1 指令脆弱性预测模型
要使用随机森林算法对指令的脆弱性进行预测,需要收集相关的特征和对应的结果从而形成数据集.
首先使用传统的故障注入程序针对目标程序注入故障,然后收集故障结果和注入故障时执行指令的相关特征,形成数据集;然后将数据集分为训练集和测试集,使用训练集建立基于随机森林算法的故障注入指令脆弱性预测模型.随机森林算法具有精度高、抗过拟合能力强、属于非线性模型等优点[24],本文采用随机森林算法来训练得出指令脆弱性预测模型.
随机森林算法是由Breiman等提出的[24],随机森林是一种结构简单的组合型分类算法,使用随机的方式从多个分类回归树中构建分类模型,并且分类回归树之间没有关联.本文采用随机森林算法来生成指令脆弱性预测模型.
5.2 生成故障序列
首先从被注入故障的程序中提取指令序列,然后对提取出的指令序列中的每一个指令提取相应的指令特征,将提取的指令特征输入到上一步中得到的基于随机森林的指令脆弱性分类器中,从而预测处指令对发生在寄存器和内存上的单粒子翻转故障的脆弱性,最后根据每条指令对寄存器和内存中的单粒子翻转故障的脆弱性形成故障序列.故障序列由3个寄存器和1个地址范围构成,其中3个寄存器是使用随机森林预测出的指令寄存器单粒子翻转脆弱性最高的3个相关寄存器,地址范围是使用随机森林预测出的指令故障空间.与图2中的指令序列对应的故障序列如表2所示.
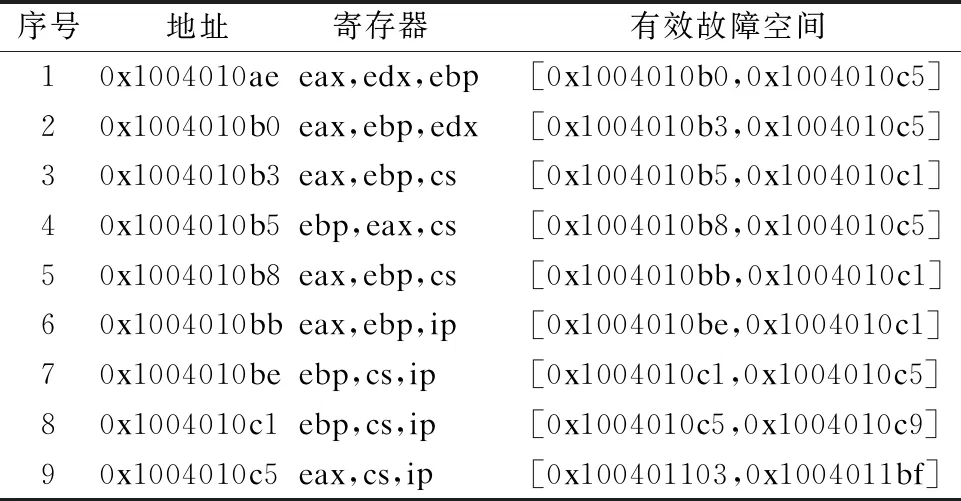
表2 指令(图2)对应的故障序列
5.3 故障注入
故障注入的步骤如下:
步骤1.提取被注入故障程序的指令序列;
步骤2.使用指令脆弱性预测模型预测出指令序列中的每一条指令的故障序列;
步骤3.根据用户设定的单粒子翻转故障的数量,从指令序列中随机选取对应数量的指令;
步骤4.使用gdb运行被注入故障的程序,在选定的注入故障的指令处插入断点,当程序运行到插入的断点时,根据断点所在的指令位置查询故障序列,得到该指令处的单粒子翻转故障敏感寄存器和有效故障空间.
学生在语文学习中的障碍主要是由于缺乏对所学内容了解不够而没有产生学习兴趣。现在我们可以用多媒体帮助学生由抽象变为具体,加上教师恰到好处的点拨讲解使学生更容易理解和把握所学内容。
步骤5.根据工作模式选择故障注入的方式:若处于自动故障注入故障模式中时,从单粒子翻转故障敏感寄存器或有效故障空间中随机选取一个注入单粒子翻转故障;若故障注入程序处于手动控制模式,则提供该指令处的单粒子翻转故障敏感寄存器和有效故障空间.
6 实验与分析
为了验证本文提出的基于随机森林的故障注入方法的有效性,本文进行了相关实验.实验的硬件环境:CPU为i5-3470,内存为8G;使用的操作系统为Ubuntu-16.04.1 i686,Linux内核版本为4.15.0-106,编译器使用的是gcc-5.4.0.为了收集训练数据和测试的数据集,本文从GitHub上爬取72个使用C语言编写的程序,这些程序的类型包括b-tree、bfs、dijksra和fibonacci等49种类型,然后使用gcc 编译作为被故障注入的程序,然后针对寄存器故障和内存故障分别进行了故障注入实验.
6.1 寄存器单粒子翻转故障注入实验
本部分的实验首先收集被注入寄存器单粒子翻转故障程序的所有可能执行的指令序列和计算机所有的寄存器.为了减少故障之间的影响,假设程序一次执行仅发生一次单粒子翻转故障,即仅在一条指令处注入一个寄存器单粒子翻转故障.按照程序指令的执行序列和寄存器列表依次注入故障.图4给出了4种注入方法故障有效率的箱线图,故障有效率为注入故障后引发程序出现数据流/控制流错误的故障注入次数占总故障注入次数的比率.图5给出了控制流注入和基于随机森林注入故障覆盖率的箱线图,故障覆盖率为注入有效故障占程序所有有效故障中的比.

图4 4种注入故障有效率
图4中可以看到随机注入故障的有效率在40%以下,仅有两个程序故障有效率超过40%,72个程序的平均故障率为28.90%.即采用随机故障注入的方式,故障注入的有效率不到30%,使用随机注入的方式注入故障的有效率低于三分之一.数据流注入故障的有效率和随机故障注入有效率略低于随机注入,平均故障有效率为23.57%,数据流注入由于指令的覆写作用而导致故障有效率低.而本文提出的基于随机森林的故障注入方法,是将上述故障注入的结果随机选取70%作为训练数据集,30%作为测试数据集,使用训练数据集训练指令寄存器故障预测器,然后使用测试数据测试训练的效果.而基于随机森林的故障注入方法在测试集中的故障有效率大多数在80%左右,最高为 96%.经过计算,基于随机森林的故障注入平均故障预测准确率为80.42%.因此与随机注入的方式相比,使用随机森林的方法实有效的提高了注入故障的有效率.
从图4中可知控制流注入故障有效率与本文提出的方法接近;但是控制流注入会极大的降低有效故障的覆盖率.控制流注入和本文方法的有效故障覆盖率如图5所示,控制流注入的有效故障覆盖率在40%-50%之间,对有效故障的覆盖率不足,而基于随机森林的故障覆盖率均在70%以上,故障覆盖率分布在75%到90%之间,72个程序的平均故障覆盖率为82.72%.随机注入是在指令和寄存的全体集合中随机选取,所以随机注入的方式故障覆盖率为100%;基于随机森林的注入方式由于使用了随机森林算法对故障进行预测,不能覆盖所有的有效故障,所以与随机注入的方式相比故障覆盖率有所下降.
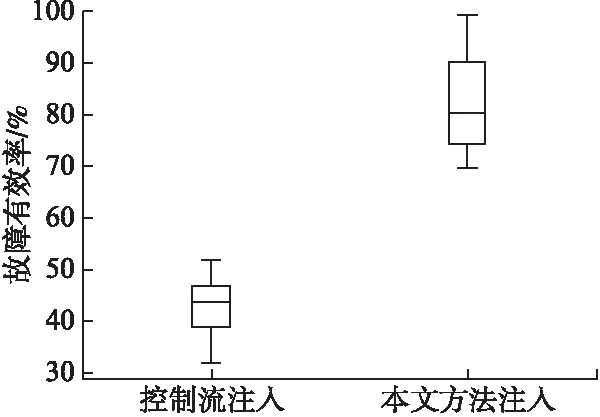
图5 故障覆盖率箱线图
6.2 内存单粒子翻转故障注入实验
与离散的寄存器不同,一个程序内存既是离散又是连续的,程序内存的离散性体现在:程序不同的部分(动态库)的内存地址是离散的、程序动态申请的内存是离散的,但是程序模块内部的地址又是连续的.本文首先将获取程序各个部分的内存地址范围,再将它们拼接成一个整体;然后采用定长的方式将内存分成几个故障注入区,这些故障注入区可以根据内存拼接的方式重新映射到原有的程序部分中.为了避免注入故障之间的影响,并且本问题出的注入方法针对的是单粒子翻转故障,假设程序中的内存单粒子翻转故障仅发生在执行某个指令时翻转内存中的某比特位上.因此,在收集内存单粒子翻转故障注入数据时,本文按照指令序列和内存故障注入区,采用一次仅在一条指令处中的一个内存故障注入区注入一个单粒子翻转故障.表3给出了按照0.5kb、0.7kb、0.8kb和1kb的方式划分故障注入区的平均故障有效率.从表3中不难看出随着故障区划分的粒度越来越粗糙,注入故障的有效率迅速降低,最后仅有个位数的有效故障率,也就是说在内存单粒子故障上,使用随机的故障注入方式故障注入的有效率极低.
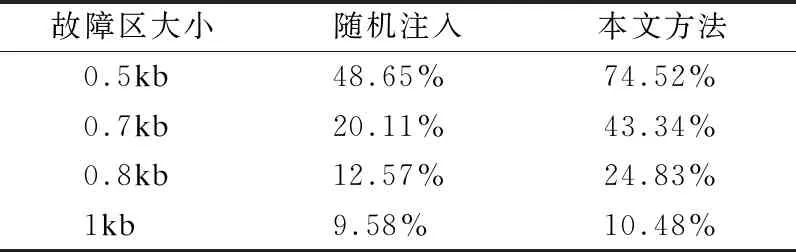
表3 不同大小故障注入区的平均故障有效率
基于随机森林故障注入的实验使用0.5kb的故障区划分方式的收集到的数据.随机选取70%作为训练数据集,30%作为测试数据集,使用训练数据集训练内存单粒子翻转故障预测器,然后使用测试数据测试训练的效果.最终基于随机森林的预测器在测试集上的故障有效率平均为74.52%,有效的提高了内存单粒子翻转故障注入的有效率.此外,本框架中的内存单粒子翻转故障注入预测器故障注入的有效率和数据收集时内存故障注入区划分的细粒度有关,1kb的故障注入区的划分方式训练出的预测器有效率仅为10.48%,故障注入的有效率接近随机注入的故障有效率.
实验结果表明当划分的注入故障区域越小时,本文所提出的基于随机森林的故障注入方法对故障注入的有效率提高的越明显;当划分的故障区域越大时,随机注入的故障有效率和本文的大致相同,使用机器学习算法对故障有效率提高效果不明显.
7 结 论
针对传统故障注入方法有效性不足、有些仅注入控制流错误和有些仅注入数据流错误的问题,本文提出了一种基于随机森林的故障注入方法,该方法根据基于传统故障注入方法的获取程序指令的各项特征和故障注入结果,然后将收集的数据分为训练数据集和测试数据集,在训练数据集上使用随机森林算法训练出指令脆弱性预测模型,根据该预测模型对被注入程序的各指令不同部件单粒子翻转故障的脆弱性进行预测,选取每个指令寄存器脆弱性最强的3个故障和有效故障空间形成故障序列,故障注入时从故障序列中选取对应的项中随机选取一个故障进行注入.最后通过实验,与传统的故障注入方法进行对比,分析了该故障注入方法的有效性,该故障注入方法相比同类故障注入方法,可以极大的避免注入不能引起程序故障的无效单粒子翻转故障,并且与单纯的注入数据流错误和控制流错误的故障注入方法相比,这种方法能够兼顾两种故障注入,也可以侧重于一种故障,应用更具有泛化性.
