基于混响时间感知的深度学习语音去混响方法
2021-11-20王小军马建芬张朝霞
王小军,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600;2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
目前已经提出了许多去混响技术[1-5]。一种直接的方法是估计房间脉冲响应(RIR)的反滤波器[6]。然而,这种方法通常需要一个最小相位假设,而在实践中几乎很难满足这一假设[6]。另外一些研究试图通过同态变换来分离语音和混响[7,8]。然而当以人的听觉系统为目标时,它们的去混响效果并不好。
近年来,深度神经网络(DNN)[9,10]得益于其强大的回归能力,也被利用在语音增强[11]、语音分离[12]中。根据训练目标的不同,监督式语音分离方法可以分为基于掩蔽的方法和基于幅度谱估计的方法。其中基于幅度谱估计[13]的方法直接从混响语音中估计出纯净语音的幅度谱结合原始的相位信息来恢复语音,而基于掩蔽的方法[14]通过计算每个T-F单元内目标语音与混响语音的功率之比来估计纯净语音的幅度谱。而单一使用某种方法可能会使最终结果中存在一些“灰色区域”[15],影响最终去混响的效果。
本文将基于掩蔽和基于幅度谱估计的方法整合为一个多目标DNN。并且进一步研究在特征提取阶段不同RT60下设置不同的帧移系数(S)和语音上下文窗系数(W)对去混响语音质量的影响。研究表明一方面在强混响条件下,当S取值较小时,即使以增加计算复杂度为代价,也无法获得良好的去混响效果。另一方面,在特征提取时加大W的值往往会降低RT60下去混响语音的质量。基于这些研究结果本文采用S和W作为关键的特征提取参数,并结合多目标DNN设计了一种混响时间感知DNN,同时考虑两个系数对语音去混响的作用。通过实验对比,进一步探讨本文方法是否可以提高语音去混响的效果。
1 基于混响时间感知的特征提取方法
在本节1.1和1.2中将从理论方面论述帧移系数和语音上下文窗系数在语音去混响系统中的作用。在1.3中将S和W两系数作为关键参数设计了一个混响时间感知DNN。
1.1 帧移系数(S)对于去混响算法的影响
目前大多数去混响算法使用短时傅里叶变换(STFT),用Xn(ejω)[16]表示,它同时在时间和频率两个维度上对信号进行采样,以获得语音的离散时间频率表示。式(1)对Xn(ejω) 进行采样,时间速率为(即帧移)R
(1)
其中,r表示帧的索引下标,w(rR-m) 表示分析窗口,帧移系数R在文献[17]中称为Xn(ejω) 的时间采样率,与信号x(n) 的时间采样率Ts不同。
在传统的STFT时间采样中,为了方便解决实际问题,帧移系数通常固定为帧长的一半[18],然而,在混响环境中,传统的方法是低效的[1,2],因为它使用的是固定的时间分辨率,没有考虑到不同混响环境下相邻帧之间的相互影响。对于较弱的混响,反射的声音到达声音接收器所需的时间较短,导致时域内的密集叠加。对于强混响来说密集的帧率是不需要的,反而需要提供较高的时间分辨率,因此合理的方法应该是根据不同的混响程度采取不同的去混响策略。
1.2 语音上下文窗系数(W)对去混响算法的影响
在特征提取阶段,考虑到语音信号的时间连续性,总是把当前帧和相邻帧的声学特征合并为一个特征向量作为DNN的输入,特征向量可以表示为
Y=[y(l-d,1),…,y(l-d,k),…,y(l,1),…,
y(l,k),…,y(l+d,1),…,y(l+d,k)]
(2)
其中,y(l,k) 表示混响语音信号的第l帧位于频带k的幅度谱分量。d表示相邻帧的数量,传统方法中d的值总是被人为设置为固定值。在最近提出的基于DNN的增强框架[11]中,证明了使用更大的d值可以提高增强语音的连续性。但是在混响条件下,帧间相关性取决于RT60的值,如式(3)所示。在混响环境中,源语音x(n) 和相应的麦克风接收信号y(n) 可以通过以下方式进行关联
y(n)=x(n)*h(n)
(3)
其中,h(n) 表示RIR,*表示卷积运算。y(n) 的自相关可以有如下表示
φyy(k)=φxx(k)*Rh(k)
(4)

1.3 基于混响时间感知的特征提取方法
传统的基于DNN的语音去混响方法中,在训练阶段,回归DNN[14]通过一组多条件数据进行训练,这些数据由对数功率谱(LPS)表示的混响语音和纯净语音组成。在去混响阶段,将训练好的DNN与输入语音的LPS特征进行非线性映射,生成相应的增强LPS特征。所需的相位可以直接从原始语音中提取,因为人耳对此类信息不敏感。最后用估计的幅度谱和混响语音相位来重建语音波形[18]。
为了提高系统的性能和增强系统的鲁棒性,本文提出了一种环境感知方法,利用不同混响环境下不同的帧间叠加和帧间相关性的特点,设计了一个混响时间感知DNN,在将对数功率谱特征(LPS)输入给训练好的DNN之前,根据混响程度的不同,采用两个RT60相关参数,即语音帧的帧移系数(S)和DNN输入处的语音上下文窗系数(W)进行特征提取。
如图1所示,将S和W这两个关键的设计参数集成到训练和去混响阶段。在训练和去混响阶段,S和W取决于语句级别的RT60,而RT60估计器之后是一个查找表,它根据估计的RT60值得到最佳的S和W,用于去混响阶段的特征提取。后续3.2.1和3.2.2将详细介绍这两个关键参数如何影响实验结果,在3.2.3中提供查找表用于实验。
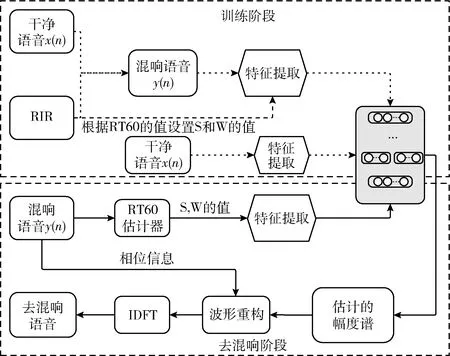
图1 系统总体流程
2 基于DNN的掩蔽与幅度谱联合估计
目前基于DNN的语音去混响的训练目标包括时频掩蔽和语音幅度谱估计,单一的目标都只能描述语音的一部分特征,并不能完美估计出干净语音,因此提出了一种基于DNN的掩蔽与幅度谱联合估计的方法,通过多目标DNN,输入特征同时计算两个不同的目标:语音幅度谱和理想比例掩蔽(IRM),网络结构如图2所示。
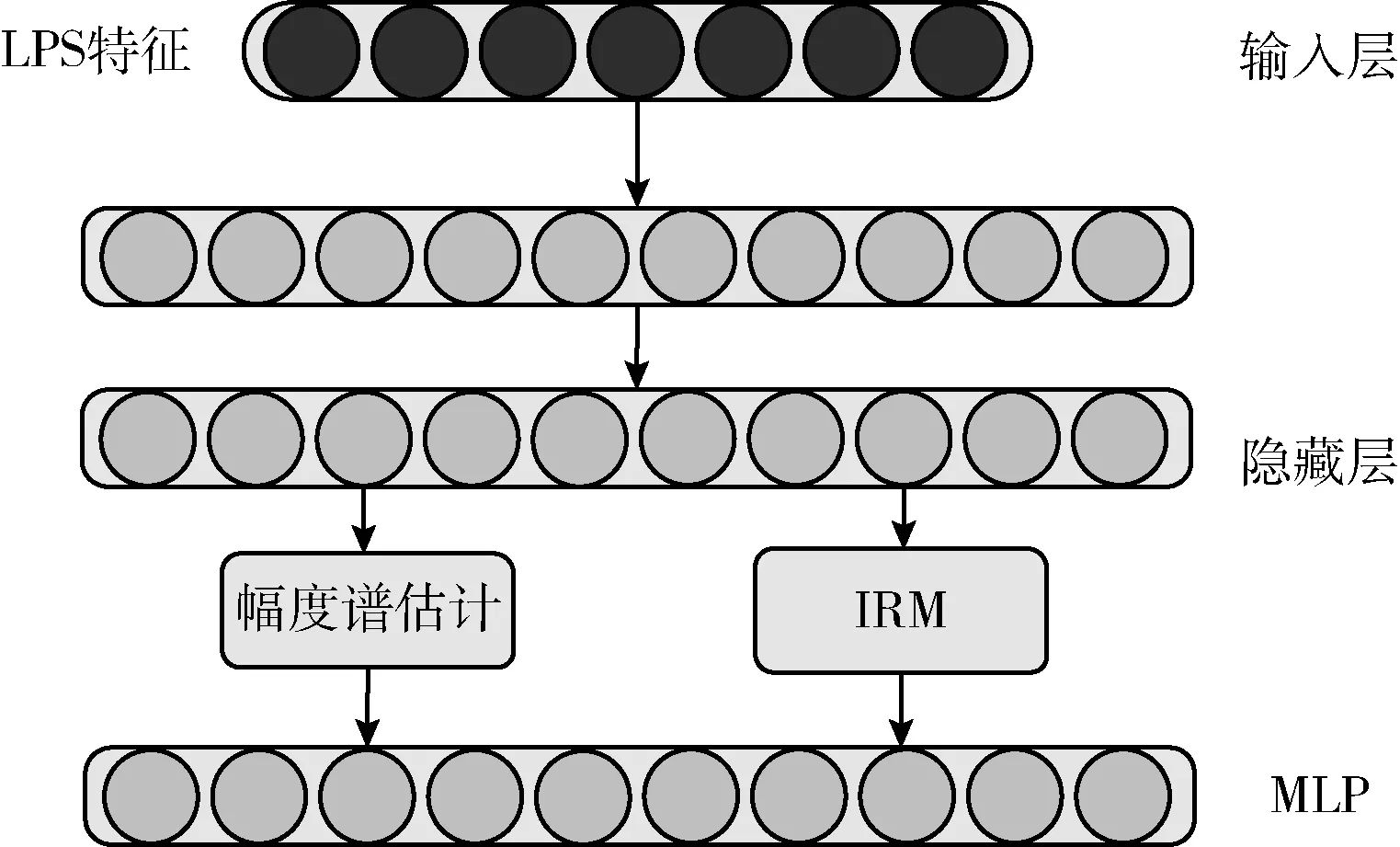
图2 多目标DNN
在语音增强阶段首先使用混响信号的短时傅里叶变换(STFT)来计算输入特征。在采样频率为16 kHz的情况下,根据RT60估计器的值来确定帧移系数(S)和语音上下文窗系数(W),从而得到LPS特征,网络的训练目标为IRM和纯净语音幅度谱,其中IRM的定义如下
(5)
假设S(t,f) 和N(t,f) 不相关的情况下,S(t,f)2和N(t,f)2分别表示T-F单元内的语音能量密度和混响能量密度,在计算幅度谱估计和IRM掩蔽过程中使用最小均方误差作为代价函数[13,14],并对每个目标赋予相同的权值。
本实验使用的神经网络有两个隐藏层,每个隐藏层具有相同数量的节点2048个,隐藏层的激活函数为整流线性单元(ReLU),在输出层中,由于幅度谱的值均大于0,所以对于纯净语音的幅度谱估计,输出变换函数为ReLU,对于IRM目标,由于IRM(t,f) 的值都在[0,1]之间,所以选择sigmoid作为激活函数。预训练的学习率为0.38,而后进行微调,mini-batch设置为128。为了防止过拟合将Dropout的值设置为0.18。

(6)
其中,h(·) 是MLP[10]所代表的变换函数。MLP只有一个由1600个ReLU节点组成的隐藏层,以估计值与目标值之间的MSE作为损失函数,公式如下

(7)
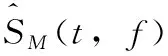
3 实 验
本节主要介绍实验配置及语音评价标准,在3.1中将本文提出的多目标DNN与传统的单目标DNN在同等条件下进行实验对比,在3.2中使用控制变量法在多目标DNN的基础上得到不同RT60下最优的S和W的值,进而建立混响时间感知DNN并将新的网络模型与前两种模型进行实验对比。
实验在尺寸为6 m×4 m×3 m(长宽高)的仿真房间中进行。扬声器和麦克风的位置分别在(2,3,1.5) m和(4,1,2) m处。用像源法(ISM)[2]模拟了10种RIR,RT60范围为0.1 s~1.0 s,增量为0.1 s。为了产生一个高质量的DNN模型,选择来自TIMI语料库随机的480条训练话语与生成的RIR卷积以构建一个大的训练集合,从而产生大约6 h的混响语音。在测试阶段,为了测试DNN在未知环境下的鲁棒性,将RT60的范围设置为0.1 s~1.0 s,增量设置为0.05 s(而不是0.1 s),产生19种不同的RIR与从TIMIT测试集中随机选取的50个话语卷积构建测试集。形成了19×50条含混响的语音测试集。
3.1 多目标DNN与单目标DNN对比
为了对比网络结构对于去混响系统的影响,此部分并没有涉及到1.1及1.2中的混响时间感知方法。在特征提取阶段使用固定的S和W的值,通过实验比较多目标DNN相对于单目标DNN的语音质量感知评价(PESQ)[19]和短时客观可懂度(STOI)[20]得分。
语音以16 kHz采样。帧长度为32 ms,并且根据常规帧移速率策略将帧移设置为16 ms(即帧移系数=帧长度的一半),输入的语音上下文窗口大小设置为7帧。计算每个重叠加窗帧的512点DFT。然后用257维对数功率谱特征向量训练DNN。最后使用PESQ和STOI两种指标来评价去混响结果。
使用Rev表示混响语音,使用S_MAP和S_IRM分别表示基于幅度谱估计和IRM算法通过DNN训练得到的增强语音,将本文提出的DNN模型表示为Muti_DNN,搭建过程及参数设置参见论文第2节。S_MAP和S_IRM的搭建的过程参考Kaldi[16],有2个隐藏层,每层2048个节点。预训练的学习率为0.4。后续进行微调,学习率为0.000 08。mini-batch设置为128,输出层的激活函数为线性(linear)函数,其它层的激活函数都设置为整流线性单元(ReLU)。在3个隐藏层之后添加了0.18的dropout可以有效的防止过拟合。
表1,表2为3种方法的PESQ和STOI得分对比,方法A表示S_MAP,方法B表示S_IRM,方法C表示Muti_DNN,在6小时的训练数据下,传统的单目标DNN和所提出的多目标DNN在不同RT60的测试集上的平均PESQ和STOI结果见表1和表2。与未经处理的混响语音相比,在所有RT60情况下,基于多目标DNN的去混响系统的PESQ平均得分提高了0.34,高于其它两种方法。这一结果表明,所提出的多目标DNN系统同时具有强大的回归和泛化能力。此外,与单目标DNN相比,本文提出的DNN模型在所有RT60下STOI得分提高了4%~25%,多目标DNN的另一个优点是在所有RT60下都能提高语音质量的2种客观指标。而传统的单目标DNN在低RT60下与原始混响语音相比,出现了一些PESQ和STOI得分下降的情况。
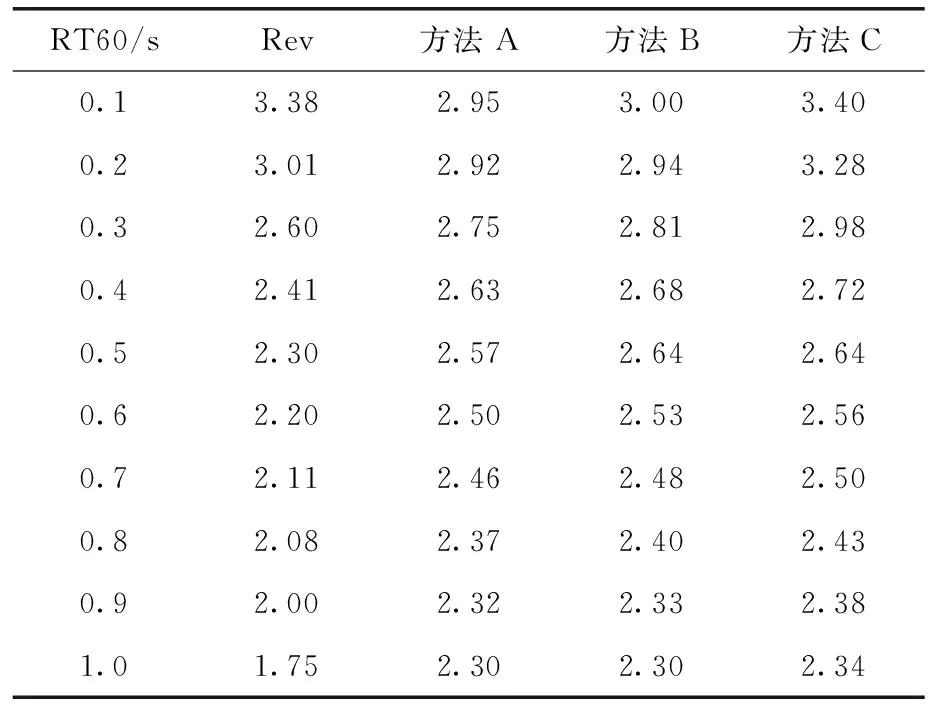
表1 PESQ得分对比
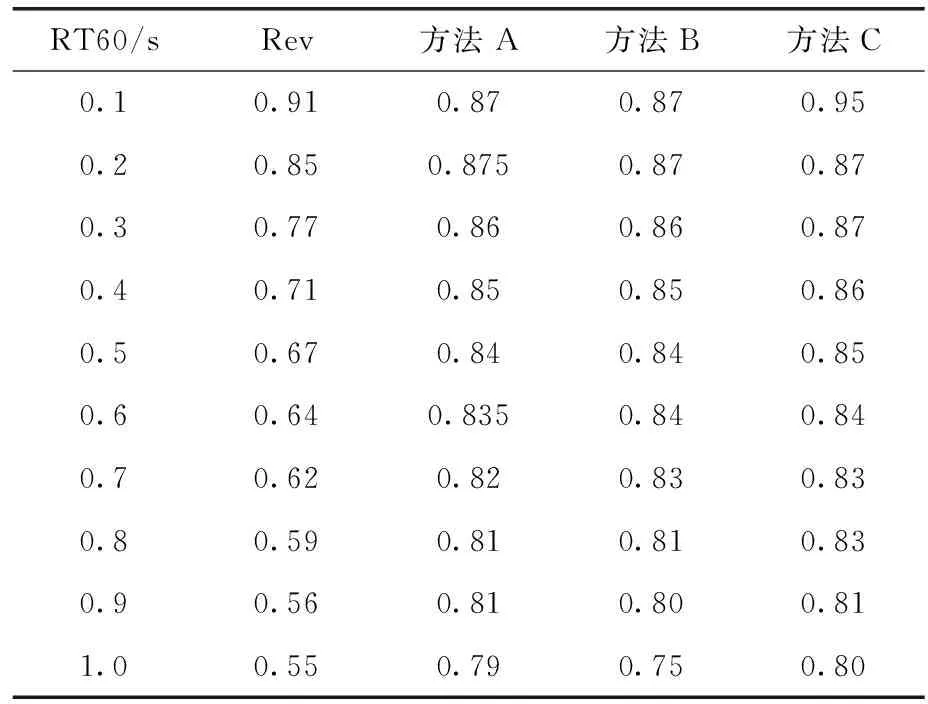
表2 STOI得分对比
3.2 混响时间感知DNN
以下实验设置与3.1相同。使用6小时的混响语音作为训练数据集来训练DNN模型。在3.2.1和3.2.2中,首先将训练集中的语音根据的RT60的值进行分类,对每种混响语音使用控制变量法,在特征提取阶段设置固定的S或W其中一个的值,改变另一个值来训练多目标DNN,分别建立了帧移系数感知DNN(语音上下文窗系数为固定值)和语音上下文感知DNN(帧移系数为固定值),然后使用训练好的DNN对各种RT60值下的混响语音进行去混响,去混响后的语音使用PESQ进行评价。在3.2.3中建立
了一个S和W值的查找表。在3.2.4中同时考虑S和W设计了混响时间感知DNN,并进行了一系列对比实验。
3.2.1 帧移系数感知DNN(SA_DNN)
为了研究帧移系数在去混响算法中所起的作用,本实验将语音上下文窗系数设置为7帧,将帧移系数分别设置为2 ms、4 ms、8 ms、16 ms、32 ms。粗体字的数字表示每种RT60下的平均PESQ分数的最大值。Rev表示未经处理的混响语音。
赫施在《解释的有效性》中说:“没有人能够确定地重建别人的意思,解释者的目标不过是证明某一特定的读解比另一种读解更为可能罢了。在阐释学中,证明即是去建立种种相对可能性的过程。”
从表3中的数据可以看出,去混响的效果受帧移系数的影响很大,因为这些粗体数字显示最佳帧移随RT60变化而变化。在RT60≤0.8 s的条件下,大部分RT60下的最佳帧移为8 ms,在RT60≥0.8 s的情况下,S=16 ms(传统帧移系数)分别优于2 ms、4 ms和8 ms。在这种情况下,即使以增加计算复杂度为代价,较低的帧移也无法获得更好的去混响效果。这结果与1.1中的分析一致。在帧移系数大于16 ms的条件下,即帧移系数被设置为32 ms时与混响语音相比,也并没有提高RT60≤0.7 s的PESQ分数。这说明去混响算法在帧率不足的情况下无法准确重建波形,影响了去混响效果。
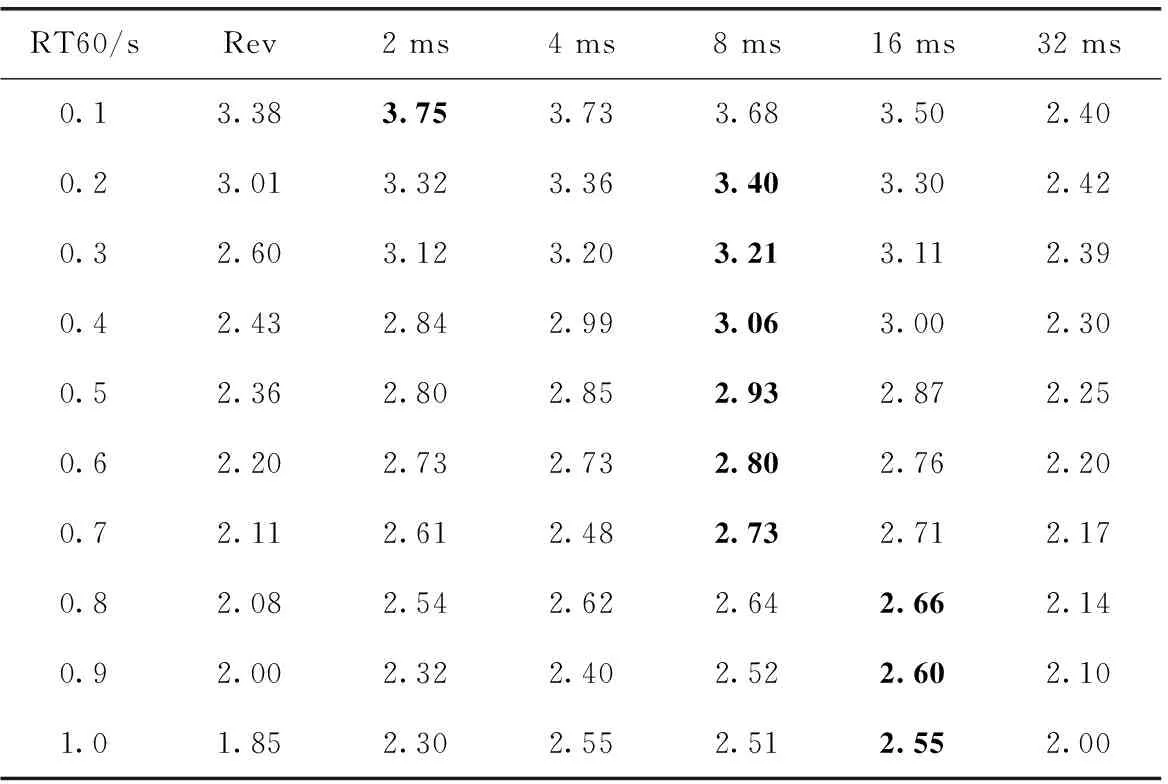
表3 不同RT60下不同帧移系数的PESQ得分
3.2.2 语音上下文感知DNN(WA_DNN)
为了研究语音上下文窗系数在去混响算法中所起的作用,本实验将帧移系数设置为8 ms,将语音上下文窗系数分别设置为3 frame、5 frame、7 frame、9 frame、11 frame。粗体的数字表示在DNN中,每种RT60下的平均PESQ分数的最大值。Rev表示未经处理的混响语音。
从表4中可以看出,粗体数字代表的最佳上下文系数随RT60变化而变化,一个明显的趋势是RT60的值越大,就需要更多的上下文信息。在RT60=0.1 s时,上下文窗设置为5 frame、7 frame、9 frame、11 frame得到的PESQ呈严格的下降趋势,尽管它们之间的差异很小。说明在混响程度较低时更多的上下文信息不能获得更高质量的增强语音。这可以用1.2中的理论分析来解释。而在严重混响的条件下(如RT60=1 s),由于帧间相关性强,使用更多的语音上下文信息会提高PESQ的得分。此外,当混响程度较高时,W为3frame会导致严重的语音上下文信息丢失从而使PESQ的得分几乎落后与其它所有相同RT60下的DNN。
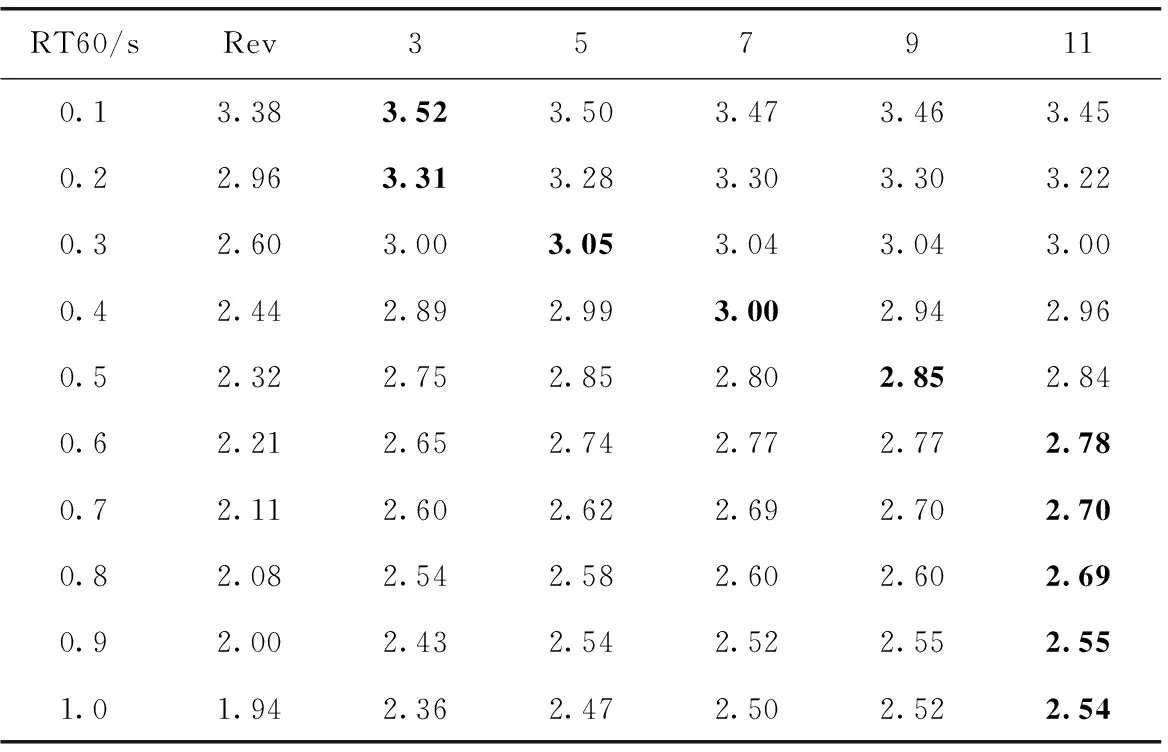
表4 不同RT60下不同语音上下文窗系数的PESQ得分
3.2.3 RT60查找表的建立
根据3.2.1和3.2.2中的实验结果,同时考虑S和W的值对语音去混响的影响,设计了RT60查找表,见表5。其中不同RT60对应的最佳S和W的值由表3和表4得出。

表5 RT60查找
3.2.4 混响时间感知DNN(RA_DNN)
最后,同时将S和W同时作为关键参数设计成RA_DNN 并给出了实验结果来评估RA_DNN在实际情况下的去混响表现,首先在去混响阶段使用了RT60估计器[12]得到语句级别的RT60估计值,然后将得到RT60估计值四舍五入到0.1的倍数,通过查找RT60表找到最佳的S和W的值来进行特征提取。另外随机抽取了100条不在训练集中的测试语音来测试RA_DNN在未知混响下的鲁棒性,使用RA_DNN(方法3)与单独考虑S或W的SA_DNN (方法1)和WA_DNN(方法2)进行对比实验。结果如下:
从表6和表7中可以看出。RA_DNN系统在所有RT60,包括极弱(RT60=0.1 s)和严重(RT60=1 s)混响情况下,比SA_DNN和WA_DNN实现了更高的PESQ和STOI的得分。结果表明,所提出的RA-DNN具有足够的鲁棒性,能够同时处理轻度混响和重度混响,而这在以前的算法[2,5]中是困难的。具体来说,在RT60=0.1 s时,与未处理的混响语音相比,本文提出的RA_DNN的PESQ和STOI分别提高了0.39 dB和0.07 dB,而WA_DNN的PESQ和STOI仅提高了0.14 dB和0.06 dB。并且随着RT60值的不断升高RA_DNN的PESQ和STOI得分的下降趋势也小于SA_DNN和WA_DNN,说明RA_DNN具有更强的环境适应性。
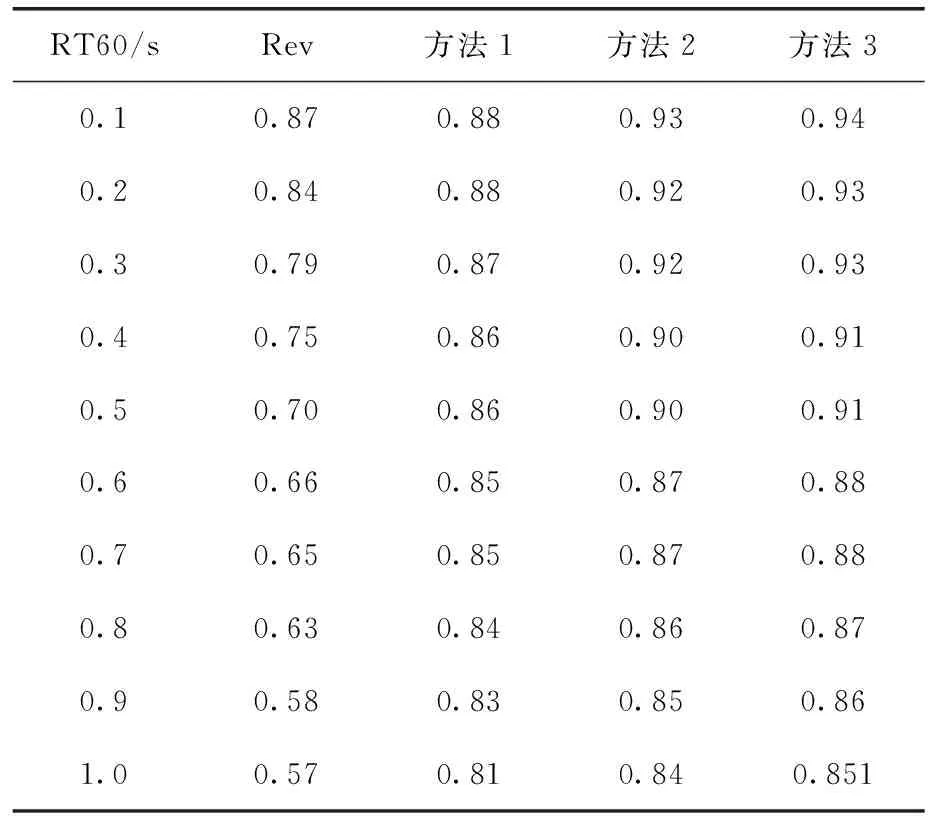
表6 3种方法的STOI得分对比
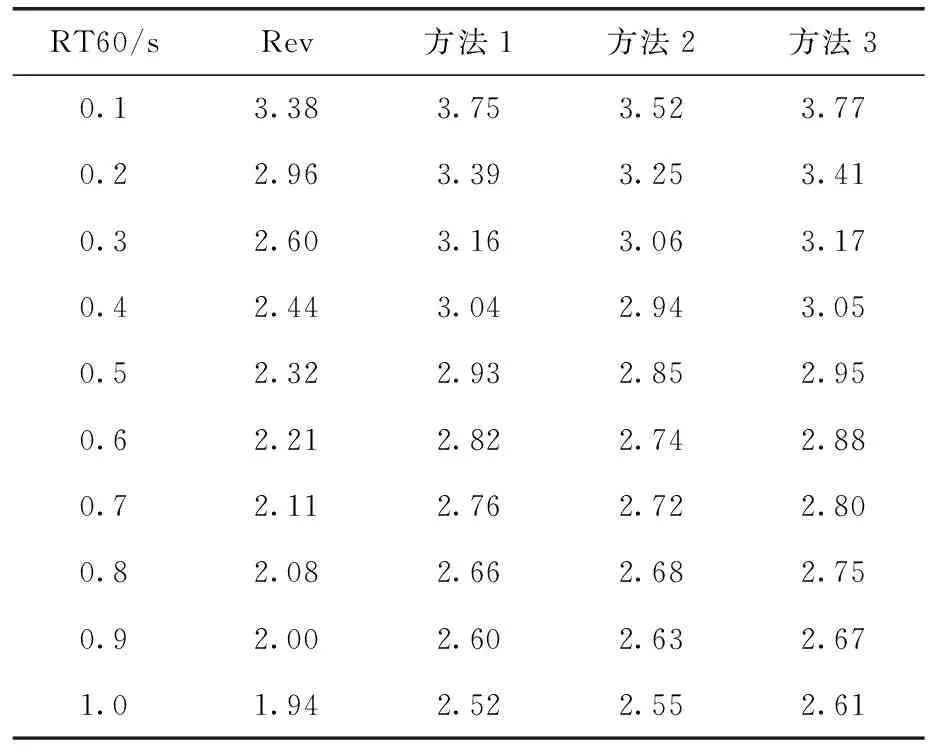
表7 3种方法的PESQ得分对比
图3展示了一条测试语句在RT60=0.6 s时的语谱图,图3(a)表示纯净语音PESQ=4.50,图3(b)表示混响语音PESQ的值为2.24,图3(c)为使用SA_DNN进行去混响后的语音的语谱图,PESQ的值为2.74,图3(d)为使用WA_DNN进行去混响后的语音的语谱图,PESQ的值2.70。图3(e)为使用RA_DNN进行去混响后的语音的语谱图,PESQ的值3.07。
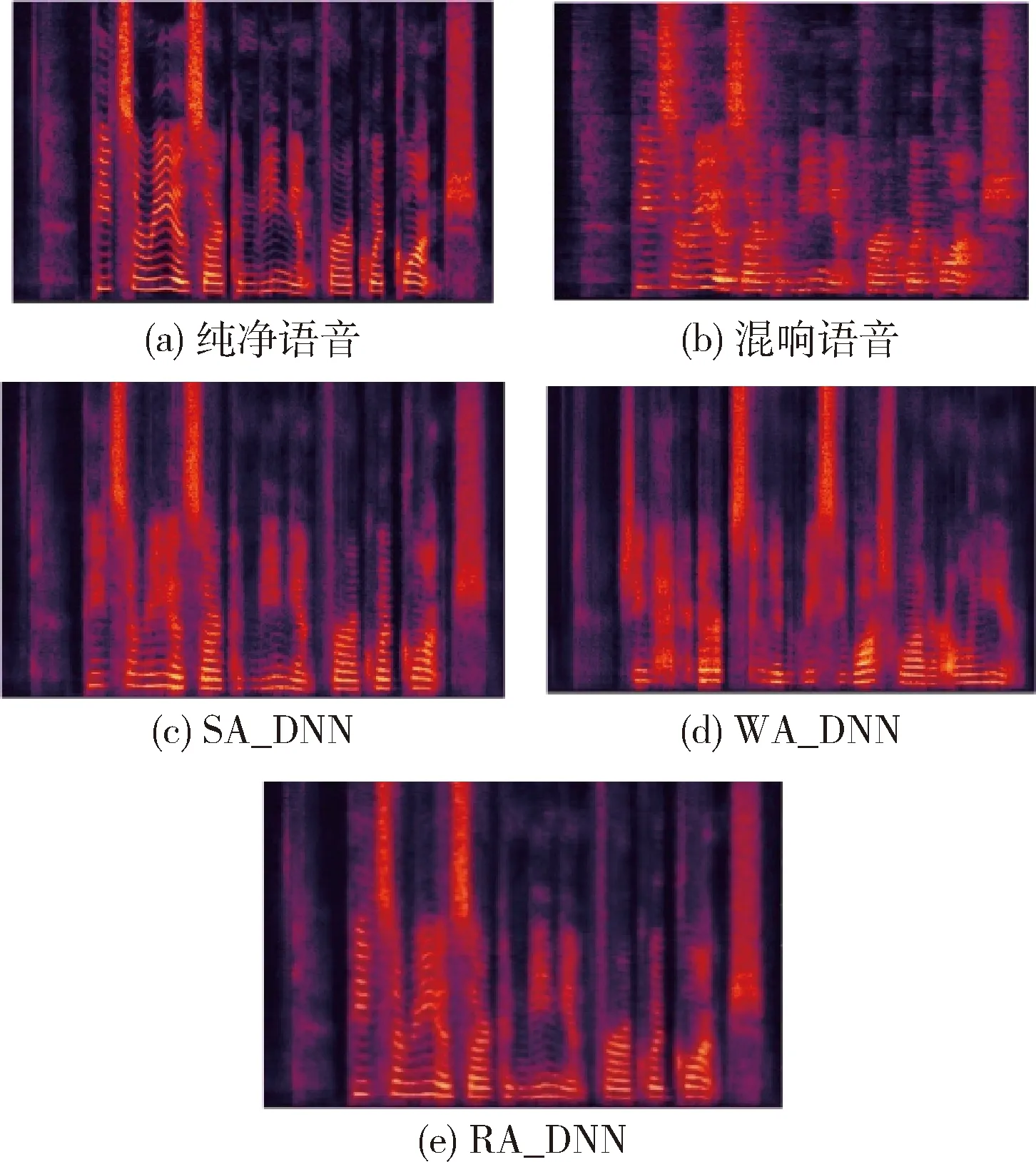
图3 语音信号语谱图对比
从图3中可以看出,使用SA_DNN得到的结果图3(c)在低频部分的谐波结构是非常模糊的,PESQ得分提高了0.5,而使用WA_DNN方法得到的结果图3(d)无法恢复大部分的中频信号,PESQ得分提高了0.46,而RA_DNN对混响语音的低频和中频信号都恢复的比较明显,条纹清晰,基线明显,PESQ的得分提高了0.83。因此可以得出结论通过改变不同混响程度下特征提取时的S和W的值,可以达到优化语音去混响的效果。
4 结束语
本文利用基于DNN的回归模型,将传统的基于幅度谱估计的方法和基于IRM的方法进行结合,提出了多目标DNN,同时估计纯净语音幅度谱和IRM掩蔽采用最小均方误差作为MLP的代价函数,将两种目标结合得到最终的幅度谱估计,对混响语音进行去混响。多目标DNN相比单目标DNN在每种RT60下的混响语音测试中都能提高语音质量和可懂度,验证了所提出的方法具有强大的回归能力和鲁棒性。接下来展示了帧移系数和语音上下文窗系数如何影响语音的去混响结果,通过引入与RT60相关的帧移系数和语音上下文窗系数,提出了RA_DNN。对比结果表明,通过考虑不同RT60下的时间分辨率和帧间相关性,所设计的DNN模型在包括极弱(RT60=0.1 s)混响和强混响(RT60=1 s)在内的大范围RT60下均优于传统方法。今后可以引入注意力机制,对RT60相关参数进行更加高效且准确的估计。
