考虑样本类别不平衡的电网故障事件智能识别方法
2021-11-20卫志农石东明孙国强臧海祥沈培锋
卫志农,石东明,张 明,孙国强,臧海祥,沈培锋
(1. 河海大学 能源与电气学院,江苏 南京 211100;2. 国网江苏省电力有限公司南京供电分公司,江苏 南京 210019)
0 引言
电网运行状态异常或发生故障时,监控系统将产生大量中文文本形式的告警信息。调度人员难以快速准确判别对应的事件类型,而基于人工智能的故障诊断技术能通过对监控信息的推理分析实现故障事件的自主识别[1],有效缩短异常事件判别时间,并提升后续事件处理效率,提高电网运行管理水平。
自然语言处理技术和机器学习的深入应用使计算机能够学习数字化表达后的告警信息,并挖掘海量数据中的特征,从而使电网智能告警逐渐摆脱对人工经验的依赖[2]。同时,深度学习作为机器学习的重要分支,通过扩展神经元层的方式构建更为深层的神经网络,可以深入挖掘输入的电力数据中的隐含关键特征。文献[3]构建了基于卷积神经网络CNN(Convolution Neural Network)的电网假数据注入攻击检测模型;文献[4]利用双向长短期记忆网络Bi-LSTM(Bidirectional Long-Short-Term Memory network)建立了底层量测数据与电力系统暂态稳定类别之间的非线性映射关系。上述深度学习模型具有较好的泛化能力,但需要足量样本支撑模型训练。电网中不同设备故障发生率存在差异,导致部分故障样本量偏少,因此历史故障样本中存在类别不均衡现象,不利于智能诊断系统的模型训练与参数学习过程,影响事件识别结果。
目前,关于不平衡数据集的处理方法主要分为数据预处理法和分类法2 种。数据预处理法通过合成或丢弃一定数量样本,降低各类别样本量的差距,如单一的欠采样、过采样[5-6],以及结合2种方法的混合采样[7],该类方法改变了数据分布,一定程度上破坏了样本特征信息。分类法能够保留样本全部初始信息,包括代价敏感学习和集成学习。代价敏感学习通过引入代价敏感因子,增大模型训练过程中对少类别样本的错分代价,从而提高该类别样本的分类可靠性。文献[8]直接将错分代价嵌入神经网络,以降低各类别样本的平均错分代价;文献[9]提出了一种基于代价敏感学习的决策树剪枝方法,在剪枝阶段引入代价敏感的思想,使模型总损失值达到最小;文献[10]通过对不同类别设置不同的代价因子,得到总代价最小的支持向量机SVM(Support Vector Machine)分类器,文献[11]在此基础上,将SVM 核函数作为选取特征的标准,进一步提高了SVM算法对不平衡数据的分类准确率。上述方法在改善对少类别样本分类效果的同时,会影响多类别样本的判别结果,不能有效提升模型的整体性能。集成学习可以将多个子分类模型(下文简称子模型)进行融合,从而得到一个整体性能较好的分类器。Boosting、Bagging 和Stacking 算法[12-13]通过不同方式实现模型融合,但只适用于弱分类器。模型融合是一种整合多个强分类器的集成学习方法,目前常用的有最大值法、均值法、求和法等[14],此类方法根据子模型计算出的各类别后验概率或结果标签,采用特定公式进行模型融合。但这种对各类别样本分类结果进行无差别融合的方法,原理较为简单,无法整合子模型的优势。
针对上述方法的特点、局限性,本文以Bi-LSTM为基础分类器,提出一种基于代价敏感学习和模型自适应选择融合的多分类问题处理方法,在提高少类别样本的分类精度的同时,保持对多类别样本的准确分类。针对某市电网公司调度中心的告警信息的测试结果表明,本文方法对于各类故障均具有良好的判别结果,进一步验证了其在电网故障事件识别中的优越性和可靠性。
1 Bi-LSTM原理
CNN 和循环神经网络RNN(Recurrent Neural Network)是目前应用最为成熟、广泛的2种深度学习模型。RNN 考虑输入信息中的序列特征,擅长处理时序信息,Bi-LSTM 通过改进RNN,解决了RNN 模型训练中梯度消失与梯度爆炸的问题,并结合当前输入前、后时刻的隐含信息,进一步提高了RNN 对时序信息的挖掘能力。因此本文采用Bi-LSTM 作为基础分类器,完成对内部具有自然时序关系的电网告警信息的处理。
Bi-LSTM 的结构单元包含输入、长短期记忆网络LSTM(Long Short Term Memory network)链、输出3 个部分,其中LSTM 链由2 个反向LSTM 拼接而成,该网络结构包括输入门、遗忘门、记忆单元和输出门,具体结构见附录A图A1。
输入门对当前时刻的网络输入信息进行控制,通过Sigmoid 神经网络层和tanh 层计算当前输入中保存到记忆单元的信息,如式(1)、(2)所示。
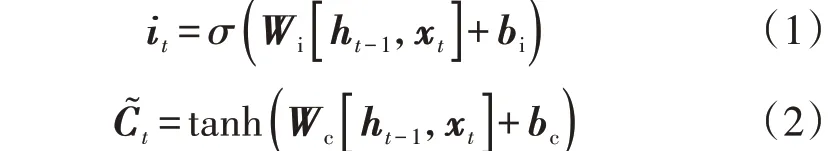
式中:it、C͂t分别为t时刻(当前时刻)输入门、临时记忆单元的状态;Wi、Wc分别为输入门、临时记忆单元的权值矩阵;ht-1、xt分别为t-1 时刻(前一时刻)隐含层的输入、t时刻的输入;bi、bc分别为输入门、临时记忆单元的偏置;σ(⋅)为Sigmoid激活函数。
遗忘门保存长期重要信息,按式(3)计算t-1 时刻隐含层中能够保留在当前时刻记忆单元的信息。

式中:ft为t时刻遗忘门的状态;Wf、bf分别为遗忘门的权值矩阵和偏置。
遗忘门保留序列数据的长期重要信息,输入门临时记忆单元使得当前时刻的无用信息不进入记忆单元,两者按式(4)共同决定记忆单元保存的信息。
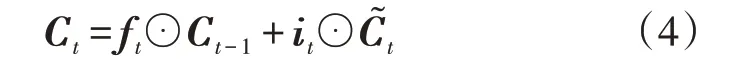
式中:Ct、Ct-1分别为t时刻和t-1 时刻记忆单元的输出值;⊙表示按元素相乘。
输出门由当前时刻的输入、记忆单元和前一时刻的隐含层确定。

式中:Ot、ht分别为t时刻输出门、LSTM 的输出;Wo、bo分别为输出门的权值矩阵和偏置。
Bi-LSTM 结合2 个时序相反的LSTM,构成了结构单元中的LSTM 链,能够同时获取当前输入前、后时刻的特征信息,其单元结构见附录A图A2。

Ht经过激活函数运算后即可得到样本属于各类别的概率,默认取概率最大的类别作为计算结果。
2 基于代价敏感学习和模型自适应选择融合的电网故障识别方法
电网告警信息为中文文本形式,此类非结构化的文本数据需要转化为结构化的数字表达,才能输入Bi-LSTM 模型训练学习。本文采用Word2vec 模型训练得到告警数据的分布式向量。Word2vec 是一款由谷歌于2013 年公开开源的词向量计算工具[15],其基本思想是通过神经网络将每个词映射成固定维数的实数向量,所有向量构成蕴含语义信息的词向量空间,不同词向量在该空间中的距离可以表征词语之间的语义相似性。词向量训练完成后,计算单条告警信息中所有词向量的平均值,得到固定维数的故障样本句向量。
2.1 方法流程
传统Bi-LSTM 模型更趋向于将样本判为训练集数量多的类别,以减小损失值。本节提出一种基于代价敏感学习和模型自适应选择融合的电网故障事件识别方法,其能够显著降低样本类别不均衡对电网故障事件识别结果的影响。电网故障事件识别的流程如附录A图A3所示,具体步骤如下:
1)利用Word2vec 模型将分词后的电网告警信息转化为高维向量,并求均值得到告警数据句向量,向量维度设置为300,向量化过程如图1所示;
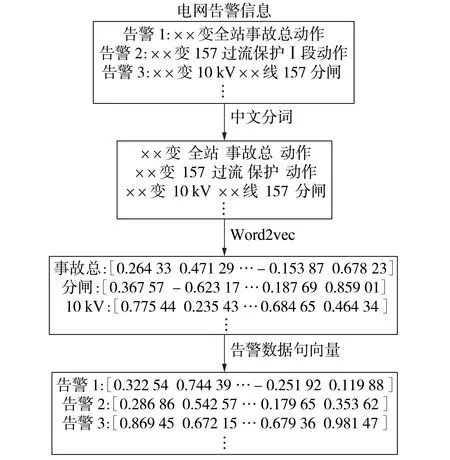
图1 电网告警信息向量化过程Fig.1 Vectorization process of power grid warning information
2)构建传统深度学习模型,即采用交叉熵损失函数的Bi-LSTM,输入故障样本进行监督训练并调参,得到对大样本故障类别具有较好识别率的子模型1;
3)自定义一个多分类代价敏感损失函数,代替模型1 中的交叉熵损失函数,增大模型训练过程中对小样本的错分代价,其余过程同步骤2),得到能够准确识别小样本故障的子模型2;
4)将每例故障样本输入子模型1、2 进行判别后,采用模型自适应选择融合方法对判别结果进行融合,得到最终的故障事件识别结果并输出。
2.2 多分类代价敏感损失函数
传统的损失函数对所有类别的样本设置相同的错分权重,因此少类别样本的损失易被淹没。本文基于Lin Tsung-yi 等人提出的焦点损失函数[16],构建适用于多分类问题的代价敏感损失函数γFL,如式(8)所示。
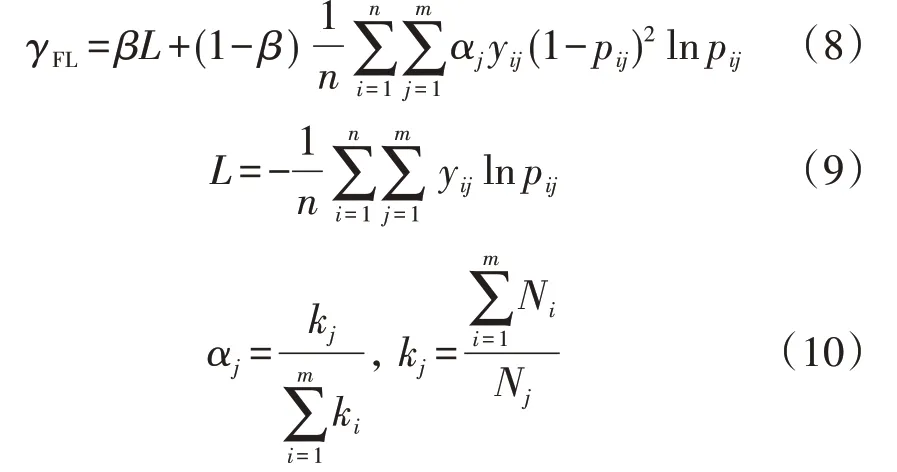
式中:m和n分别为样本类别数和样本总数;yij和pij分别为样本i属于类别j的真实概率和预测概率;β∈[0,1],为 调 制 因 子;L为 交 叉 熵 损 失 函 数;αj∈[0,1],为权重因子,能够区分不同类别样本的错分代价,样本量越大,该类别样本的错分代价越小,否则错分代价越大;Nj为属于类别j的样本的数量。
γFL由两部分组成,第一部分为传统交叉熵损失函数L,第二部分为考虑类别不平衡影响的代价敏感损失值计算。通过调制因子β调节两者权重,β越小,第二部分占比越大,γFL对各类别样本的区分程度越高。作为一种代价敏感损失函数,γFL通过对各类别样本设置不同的权重因子,提高对少类别样本的错分代价,从而提高该类样本的分类准确性。
2.3 模型自适应选择融合方法
训练样本不平衡度较大时,γFL中少类别样本的错分代价过大,破坏了模型对多类别样本的分类效果。本节提出一种综合考虑召回率与准确率的模型自适应选择融合方法,在代价敏感学习的基础上进一步改善模型的整体分类性能。该方法首先以样本类别为出发点,选择召回率大的子模型代表该类别样本的分类标准,使得模型融合后能够尽可能全面地识别出此类别样本;再结合子模型对各类别样本的分类准确率,推理得到最终的判别结果,从而降低模型融合后的整体误判率。该方法的流程图见附录B 图B1。以样本总数为n、样本类别为m、子模型个数为2为例,模型融合的具体过程如下。
1)计算子模型k(k=1,2)对类别j(j=1,2,…,m)样本的分类召回率Rkj,如式(11)所示。对于每个样本类别,选择分类召回率大的子模型作为分类基准,由此设定各类别的融合标签σj,如式(12)所示。
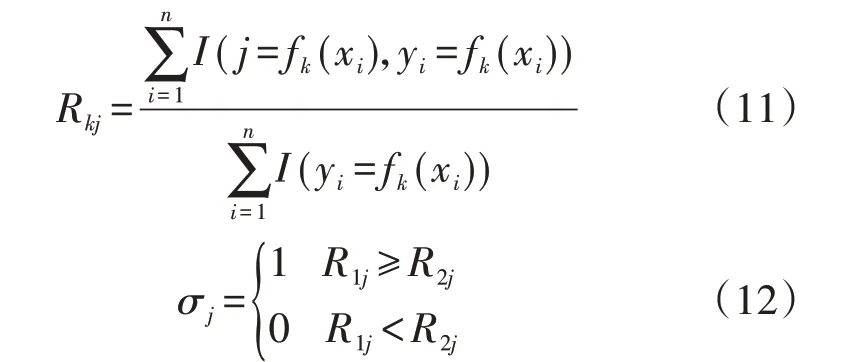
式中:fk(xi)为子模型k对样本xi的预测标签;yi为样本xi的真实标签;I(·)为逻辑判断,括号内表达式成立时取1,否则取0。
2)对于类别j样本,结合σj取该类别样本分类召回率较大的子模型,按照式(13)计算类别j样本的分类准确率,将其作为准确率矩阵Δ的第j个元素,由此得到按分类召回率大小筛选出的准确率矩阵Δ如式(14)所示。

式中:Pkj为子模型k对类别j样本的分类准确率;Pσj j为结合σj选取的召回率较大的子模型对类别j样本的分类准确率。
3)根据子模型分类结果,按照式(15)设置各样本的融合标签。
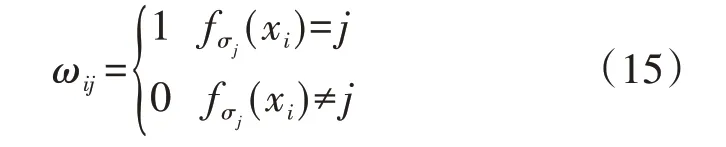
式中:ωij为样本xi对类别j的融合标签;fσj(xi)为结合σj选取的召回率较大的子模型对样本xi的分类结果。
σj由式(15)计算得到,反映了能够代表类别j样本分类结果的子模型标签,若该标签对应的子模型对样本xi的分类结果与类别j一致,则将xi对类别j的融合标签设置为1,否则为0。在此基础上按照式(16)计算融合后样本xi属于各类别的后验概率。

式中:Πi为由后验概率组成的矩阵,其第j列表示样本xi属于类别j的概率。Πi中最大值对应的列索引即模型融合的输出类别标签。Πi=0 时,取分类效果较好的子模型的分类标签作为输出结果(默认为子模型1)。模型融合后的输出结果表达式为:

式中:max(Πi)为Πi中的最大值。
模型自适应选择融合方法依次考察子模型的召回率与准确率指标,在分析子模型分类性能的基础上进行决策,整合各子模型的分类优势,得到最终的输出结果,实现了模型的选择性融合与信息互补,同时可推广应用于2个以上子模型参与融合的场景。
3 算例分析
为验证本文方法有效性,选取某市电网调度中心2016、2017 年的历史告警信息进行算例分析。首先根据工程需要,确定了若干种需要调控人员第一时间重点关注的异常跳闸类事件,然后以带关键词“分闸”的告警信息为标志,提取该信息前后一段时间窗内的离散告警信息集合,当满足一定规则时,构成各类标签化事件样本。从中提取9 种重要故障事件对应的样本,共得到13 554 例故障事件样本。从每类故障事件样本中随机选取25 例作为测试集,其余作为训练集,并在训练过程中随机抽取训练集中5%的样本作为验证样本,以优化模型参数。每组实验取10 次测试结果的平均值作为参考标准。故障事件样本分布情况如表1所示。

表1 故障事件样本数量统计Table 1 Number statistics of fault event samples
分类模型常用的评价指标有召回率、准确率、F1值。召回率、准确率计算公式分别见式(11)、(13),子模型k属于类别j样本的F1值的计算公式为:

F1 值是一种综合考量准确率与召回率的综合评价指标,通常F1 值越大,模型的分类性能越好。对于多分类模型,取所有类别的F1 值的期望作为该模型的整体F1值指标。经过测试对比,Word2vec 模型和Bi-LSTM 模型的参数设置情况分别见附录C表C1、C2。
3.1 基础分类器性能验证
为了验证Bi-LSTM 在电网故障事件识别中的优越性,设置3组对比实验,分别采用以CNN、LSTM以及结合CNN 与注意力(Attention)机制的组合深度学习模型Attention-CNN 作为基础分类器。其中CNN 设置3 种卷积窗口,尺寸分别为3、4、5,每种窗口的卷积核数目为100,采用ReLU 激活函数,其他所需参数同附录C 表C2;LSTM 的参数同附录C 表C2。以不同深度学习模型作为基础分类器,对算例进行实验对比,得到准确率、召回率、F1值3种评价指标,结果如图2所示。

图2 深度学习模型的评价指标对比Fig.2 Comparison of evaluation indexes among deep learning models
由图2 可以看出:CNN 虽然具有局部感知能力强的特点,能够很好地处理图像信息,但在处理时序信息时效果欠佳;Attention-CNN 在CNN 的基础上引入注意力机制,能够强化局部告警信息中蕴含的关键特征权重,以优化模型对不同的告警事件的特征提取,但依然无法捕捉时序关联特征,导致模型总体性能提升不大;LSTM 擅长处理时序信息,电网告警信息属于时间相关的数据,因此分类效果比CNN 更好;Bi-LSTM 模型的准确率、召回率与F1 值均最大,进一步体现了Bi-LSTM 基于LSTM 进行的改进能够考虑当前输入的前、后时刻的信息,优化分类效果,作为基础分类器的性能优于其他3 种对比模型。后续实验均以Bi-LSTM模型作为基础分类器。
3.2 模型融合方法性能验证
子模型1采用交叉熵损失函数,子模型2采用由式(8)构建的代价敏感损失函数(β=0.1)。为对比本文的模型自适应选择融合方法(简称选择法)的实用性,分别利用最值法、求和法对子模型进行融合。对于每个样本,最值法取各子模型中最大后验概率对应的类别标签作为融合结果;均值法计算所有子模型后验概率的均值,得到融合后的后验概率,并将最大概率对应的类别标签作为最终输出结果。子模型与不同模型融合方法的分类召回率如表2 所示,整体评价指标对比如图3所示。
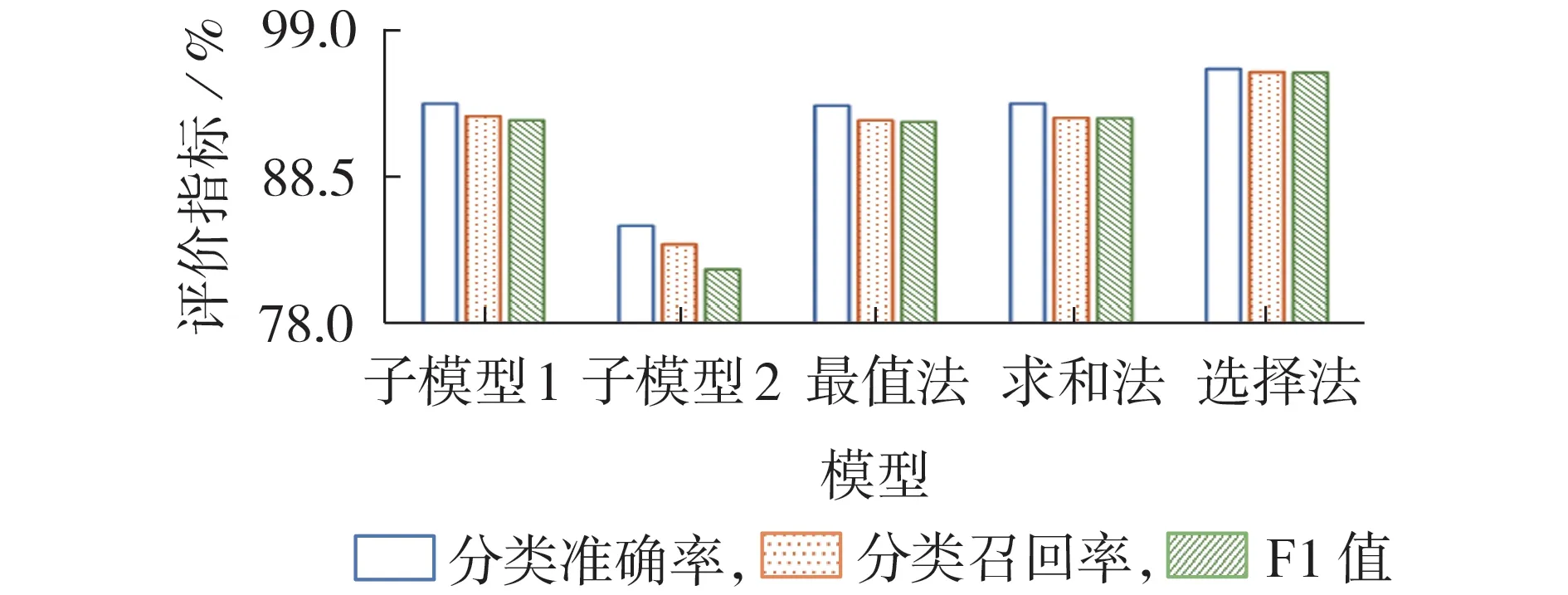
图3 子模型与模型融合方法的评价指标对比Fig.3 Comparison of evaluation indexes among submodels and model fusion methods

表2 子模型与融合算法的分类召回率Table 2 Classification recall rate of submodels and fusion methods
对表2、图3进行分析后可得到如下结论。
1)由表2 可见:由于训练样本类别的不平衡,子模型1 对样本量较大的故障事件的识别效果更好,而对样本量小的故障事件的识别效果较差,其中对类别9 样本的分类召回率仅为69.74%;由于样本类别不平衡度极大,子模型2 中样本量大的故障事件的权重因子很小,因此对多类别样本的召回率显著降低,其中对类别1—3 样本的分类召回率分别为53.87%、69.21%、52.34%;而对少类别样本的召回率明显提高,对类别9样本的分类召回率增至95.68%。
2)结合表2 和图3 可以看出:最值法、求和法单纯从子模型预测的后验概率出发,不能对子模型的性能进行分析,因此无法有效结合各子模型学习到的信息,导致整体分类结果无明显改善;模型自适应选择融合方法,综合考虑了子模型的召回率与准确率指标,对于每个样本均能够灵活地选择子模型的预测结果,从而保留子模型的优势性能,实现信息互补,在保证多类别样本的分类效果的同时,有效增强了对少类别样本的识别能力,准确率、召回率、F1 值相比子模型均有进一步的提升,分别达到了95.97%、95.78%、95.74%。
3.3 整体性能验证
使用基于Python 的imblearn 工具包设置4 组实验,对比分析本文方法在整体性能上的优越性与可靠性。在进行模型训练前,4 组实验分别采用少数类别样本合成技术SMOTE(Synthetic Minority Oversampling TEchnique)[17]、Borderline-SMOTE方法(kind=‘borderline-1’)[18]、SMOTE 与编辑最近邻混合采样方法(SMOTE-ENN)[19]和SMOTE-Tomek[20]混合采样方法按默认参数处理训练样本,依次记为方法1—4。4种对比方法与本文算法的分类召回率见表3,整体评价指标对比见图4。
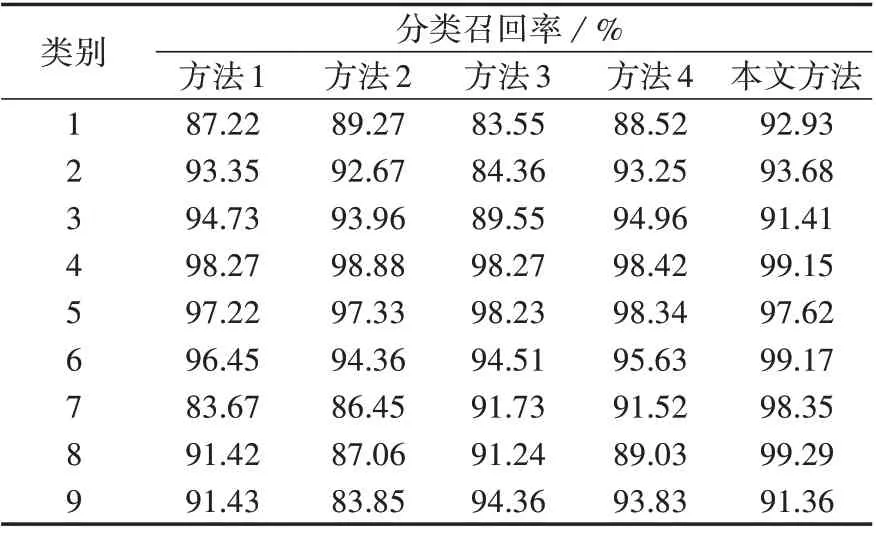
表3 对比方法和本文方法的分类召回率Table 3 Classification recall rate of comparison methods and proposed method
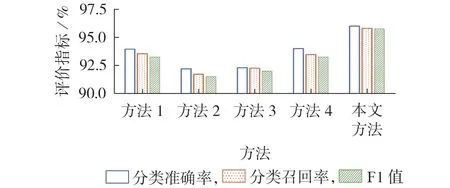
图4 对比方法和本文方法的评价指标对比Fig.4 Comparison of evaluation indexes among comparison methods and proposed method
综合表3和图4可以看出:
1)与其他考虑样本类别不平衡的对比方法相比,本文方法的3种评价指标均为最大,达到了95%以上,对各类故障事件的分类召回率也均在90%以上;
2)对于样本类别不平衡度较大的数据集,过采样算法易合成噪点数据,破坏样本分布信息;混合采样算法中欠采样的引入会丢失部分样本特征,破坏模型对多数类样本的识别效果;
3)本文方法不改变样本初始分布,保留全部特征信息,在提高少数类样本的分类召回率的同时,有效维持了多数类样本的分类召回率并提高了其分类准确率,因此整体故障识别效果得到了显著提高。
4 工程实际应用
以2018 年8 月17 日“温比亚”台风过境当天所截取的某信息密集时段内监控信息作为对象,验证本文方法的实际应用效果。
当天13:27—13:31 时段共产生了4 146 条告警信息,系统从告警信息中提取出7 项事故跳闸事件,并通过本文方法在0.5 s 内得到故障事件识别结果,包括线路单相瞬时故障、单相永久故障、相间故障以及一项历史样本极少的母线故障实例,经过验证,识别结果均正确,其中母线故障事件识别结果如表4所示。虽然在线应用样本量少,但是本文方法表现出较高的识别准确率,并正确识别出一项发生概率极低的母线故障事件,具有良好的工程应用价值。

表4 母线故障实例识别结果Table 4 Recognition result of instance of bus fault
5 结论
本文针对电网故障事件中的样本类别不平衡现象,提出一种基于代价敏感学习和模型自适应选择融合的多分类问题处理方法,实现了电网告警事件的智能识别。基于对某市电网公司调度中心告警历史信息的实验测试,所得结论如下:
1)通过本文构建的多分类代价敏感损失函数,在损失函数中引入代价敏感因子,增大了少数类电网故障事件的错分代价,优化模型对该类样本的特征学习能力,从而改善模型对少数类电网故障事件的识别性能;
2)综合考虑召回率与准确率的模型自适应选择融合方法,对2 个具有不同性能特点的模型进行融合,结合子模型的优势,实现了模型的信息集成与优势互补,在保留对多数类故障事件识别能力的基础上,提高了少数类故障事件的识别率,得到整体效果更好的电网故障识别模型。
后续可考虑将规则推理方法与深度学习进行深度结合,提高电网中人工智能模块的可靠性,同时进一步扩展可识别事件的类型。
附录见本刊网络版(http://www.epae.cn)。
