基于改进胶囊网络的文本细粒度情感分类方法
2021-11-19李清霞李启明
江 涛,李清霞,李启明
(1.广东理工学院信息技术学院,广东肇庆 526100;2.广东工业大学网络信息中心,广东广州510006)
1 引言
文本情感分析属于信息检索、自然语言处理、人工智能领域的交叉问题,可明确文本描述的情感内容[1]。以往的情感分析大多是对篇章结构、段落结构的句子实施分析,而伴随用户需求日益显著,此类层级的情感分析粗糙度显著,一个段落或一句话仅表达一种情感态度,不能高精度描述用户想了解的内容。
目前已有研究人员对文本情感分类问题进行专题研究,文献[2]提出了基于细粒度多通道卷积神经网络的文本情感分析方法,该方法可深入挖掘文本深层次的语义信息,实现文本情感分析,但是该方法不适用于文本样本数较多的情况。文献[3]提出融合注意力机制的多语言文本情感分析方法,该方法的优势在于可实现多语言文本情感分析,但对具有歧义的文本情感的分类精度有待优化。
针对上述问题,以文本细粒度情感分析为主,细粒度情感可以在指定的角度分析文本的情感态度,提出基于改进胶囊网络的文本细粒度情感分类方法,以期实现文本细粒度情感分类。
2 基于改进胶囊网络的文本细粒度情感分类方法
2.1 基于信息增益改进贝叶斯模型的文本词义消歧方法
文本歧义词语对文本细粒度情感分类效果存在直接影响,例如,对汽车性能评价语句中,常常存在“不错”、“还可以”此类评价,此种文本给人的直观情感存在判断模糊不清的情况,这对文本细粒度情感分类精度存在负面干扰[4]。为此,在实施文本细粒度情感分类之前,使用基于信息增益改进贝叶斯模型的文本词义消歧方法,实现文本词义消歧。
2.1.1 基于信息增益最大原则的改进思想
引入文本特征词语的位置信息,以此优化贝叶斯模型的词语分辨性能。文本特征词语位置信息能够使用信息增益最大原则对文本特征集实施优化,提高对歧义词语判断共享最显著的上下文词语权重,以此凸显它们对词义判断的价值[5-6]。分析文本特征词语位置信息与词义判断问题的联系,得到位置权重,实现文本词义优化。
使用熵的方法能够计算贝叶斯模型引入文本新信息前后的不确定性,按照不确定性的变化能够计算文本词义信息的增益度。先把上下文里各个词纳为一个种类,运算整个上下文环境的统计不确定性,简称为熵G(Context)。整个上下文环境的不确定性,简称为条件熵G(Context|Up),Up代表文本词语集合。熵的运算方法是
G(Context)=-W(Context)×logW(Context)
(1)
其中,W(Up)是文本词语Up在训练语料里出现的频率。
(2)
其中,文本中全部词语出现的频度是θ;θ(Up)是Up出现的频度。
条件熵的运算方法是:
(3)
其中,O(Up)是词语Up在某指定位置出现的概率。
熵与条件熵之差可描述上下文环境的信息的增益量,信息增益量JK是:
JK=G(Context)-G(Context|Up)
(4)
将信息增益熵设成上下文词语权重,导入改进贝叶斯模型的文本词义消歧模型中,实现文本词语消歧。
2.1.2 改进贝叶斯模型的文本词义消歧模型
使用改进贝叶斯模型的文本词义消歧模型实现文本词语消歧的方法是:
(5)
其中,D0、W依次是文本中歧义词、词语出现概率;Dstar是消歧后文本。
2.2 基于改进稠密胶囊网络模型的文本细粒度情感分类方法
基于改进稠密胶囊网络模型的文本细粒度情感分类方法的改进之处主要在于引入自主力机制,增大需识别文本深层次特征的特征权值,提高文本细粒度情感分类精度。自注意力模型借鉴全局依赖学习的原理,建立非局部块,对文本特征中深层次特征实施加权,实现文本特征间全局依赖学习[7]。自注意力模型能够协助网络模型在胶囊网络训练学习时着重分析文本深层次特征间的相关性,提取细粒度情感,并且可以在小样本条件下优化文本细粒度情感分类效果[8-10]。
此外,传统胶囊网络使用的动态路由算法在优化分类准确率之时,因为算法自身使用子胶囊和父胶囊间的全连接结构,网络参数运算量将随着文本特征的增多而增多,致使特征运算负载变大,所以,传统胶囊网络仅适用于小规模文本细粒度情感分类问题。基于改进稠密胶囊网络模型的文本细粒度情感分类方法中,还使用局部约束动态路由算法,完成局部范围中胶囊路由选取与变换矩阵共享,则子胶囊仅可以在一个提前设置的本地窗口路由与父胶囊联系,且胶囊网络里相同种类的胶囊变换矩阵具有共享性。
2.2.1 自注意力模型
1)特征相似度与注意力掩模运算
设置1×1卷积核是a(y)、b(y)、c(y),使用此卷积核完成文本细粒度情感特征跨通道信息融合
a(y)=Vay
(6)
b(y)=Vby
(7)
c(y)=Vcy
(8)
其中,Va、Vb、Vc属于胶囊网络参数;a(y)、b(y)可运算文本细粒度情感特征相似度,可用来建立注意力掩模,c(y)用来构建被掩模特征图;y属于文本细粒度情感特征值。相似度rij运算方法与注意力掩模δij运算方法是
rij=a(yi)b(yi)
(9)
(10)
其中,M是文本细粒度特征数量;yi属于文本细粒度情感特征中索引是i的特征值。i、j代表特征索引值;rij可运算文本细粒度情感特征中索引位置j特征值对应于索引i位置特征值的相似度;将δij实施归一化,运算索引j位置特征值的全局相似度响应值,以此建立注意力掩模矩阵。
2)文本细粒度情感自注意力特征运算
文本细粒度情感自注意力特征的运算公式是
(11)
xj=βzj+yi
(12)
其中,zj是掩模特征索引j位置中,文本细粒度情感的自注意力特征值;权重参数是β;xj是文本细粒度情感的自注意力特征;索引i位置文本细粒度情感自注意力特征值是yi。
2.2.2 局部约束动态路由算法
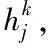
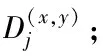
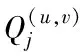
(13)
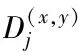
(14)
(15)
2.2.3 损失函数
使用改进稠密胶囊网络模型损失函数KLost在原间隔损失函数中引入重构损失项
KLost=KC+εKR
(16)
其中,间隔损失函数、重构损失函数、误差平衡系数依次是KC、KR、ε。间隔损失项可以优化胶囊网络模型对文本细粒度情感的分类精度,重构损失项可判断胶囊网络特征重构误差[12]。
2.2.4 分类步骤
输入:需细粒度情感分类的文本样本Dstar
输出:文本细粒度情感分类结果Dout
1)建立自注意力特征模型,提取文本细粒度情感特征;
2)建立胶囊层,此层分为2层主胶囊层与分类胶囊层,2层主胶囊层中具有32个胶囊,各个胶囊包含16个卷积核,各个胶囊输出16维激活向量。分类胶囊层输出激活向量Dout,激活向量可描述文本细粒度情感分类结果;
3)重构输入的需细粒度情感分类文本样本,把第2个主胶囊层设成输入,依次连接卷积层,将文本细粒度情感特征维度卷积核步长是1的反卷积层与重构输入样本的卷积层进行扩充,输出重构样本;
4)计算重构样本特征与原始样本特征的损失函数,选取合适的训练轮数,优化网络模型对文本细粒度情感的分类精度。通过上述步骤,实现文本细粒度情感分类。
3 实验分析
3.1 实验环境设置
实验硬件环境设置为Win10+Ubuntu1604双系统,16GB内存,GTX1080显卡,Intel Core i7 CPU,1T硬盘,并在MATLAB仿真软件中,采用Python2.7编程语言以及Java工具包自然语言处理工具进行对比实验。
将所提方法的胶囊网络每步训练时间设成10ms,各轮文本特征训练时间是400ms,所提方法的损失函数曲线如图1所示。
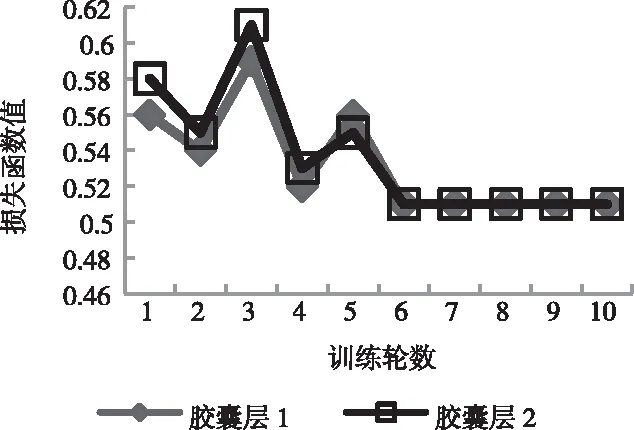
图1 所提方法损失函数曲线图
由图1可知,所提方法两个胶囊层的损失函数值在第6轮训练中趋于稳定,且最小,此时分类性能最佳。为此,在所提方法应用效果测试中,将所提方法训练轮数设成6次。
3.2 文本细粒度情感分类效果
3.2.1 多种文本细粒度情感分类效果评价
为测试所提方法对多种文本细粒度情感分类效果,使用国际上常用的查准率、召回率、F1三个指标判断。查准率(Precision ratio)、召回率(Recall)、F1(F-measure)三个指标的数学公式是:
(17)
(18)
(19)
对某聊天系统里文本细粒度情感实施分类,文本细粒度情感类型依次是喜悦、悲伤、惊奇、愤怒、恐惧、厌恶。在MATLAB软件中导入此聊天系统中聊天记录,聊天记录六种文本细粒度情感的聊天记录为3000条,每种情感文本是500个,详细设置如表1所示。

表1 实验文本设置
使用所提方法、文献[2]方法、文献[3]方法同时进行文本细粒度情感分类,三种方法对聊天记录六种文本细粒度情感的分类效果如图2、图3、图4所示。
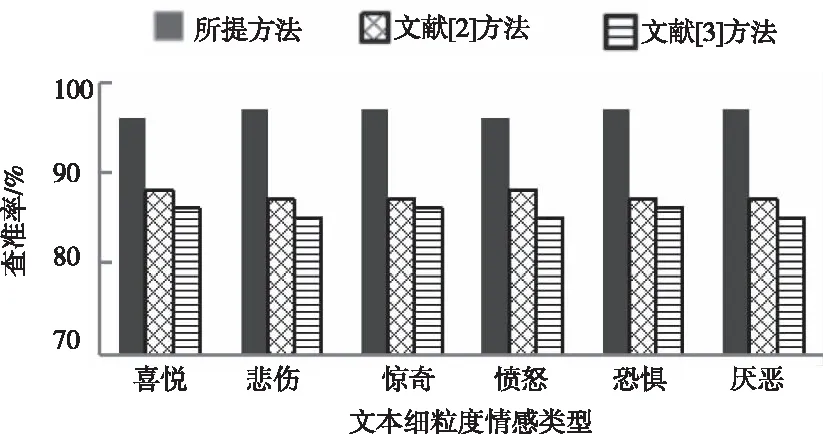
图2 查准率对比结果
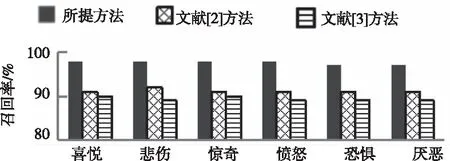
图3 召回率对比结果
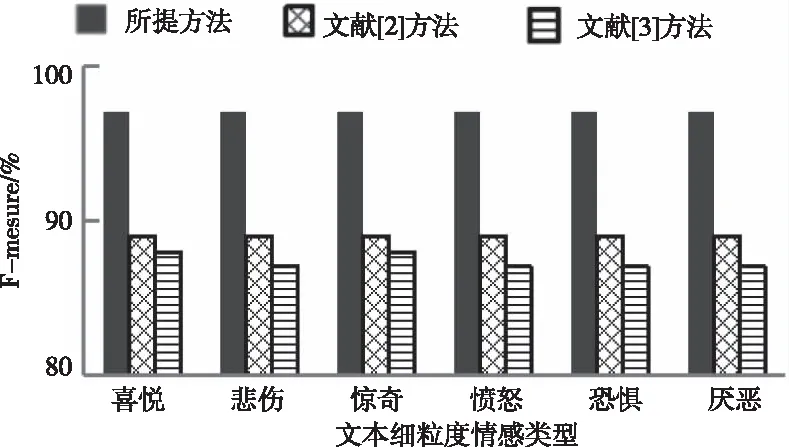
图4 F-measure对比结果
由图2、图3、图4可知,所提方法、文献[2]方法、文献[3]方法对表1中文本进行细粒度情感分类后,所提方法分类结果的查准率、召回率、F1值均大于95%;文献[2]方法、文献[3]方法分类结果的查准率、召回率、F1值均低于95%,由此可知,相比文献[2]方法和文献[3]方法,所提方法对多种文本细粒度情感分类效果较好。
3.2.2 具有歧义的文本细粒度情感分类精度评价
使用所提方法、文献[2]方法、文献[3]方法对存在词语歧义的文本进行文本细粒度情感分类。存在词语歧义的文本如表2所示。

表2 存在词语歧义的文本
使用Kappa系数检验三种方法对具有歧义文本细粒度情感的分类精度,Kappa系数检验的公式是
(20)
其中,p1、p2依次是具有歧义文本细粒度情感分类结果与实际情感的实际一致率、期望一致率。Kappa系数越接近1,表示具有歧义文本细粒度情感的分类结果与实际情感一致性较高;Kappa系数越接近0,表示具有歧义文本细粒度情感的分类结果与实际情感一致性较低。
所提方法、文献[2]方法、文献[3]方法对四种存在歧义文本细粒度情感分类结果的Kappa系数测试结果依次如表3所示。
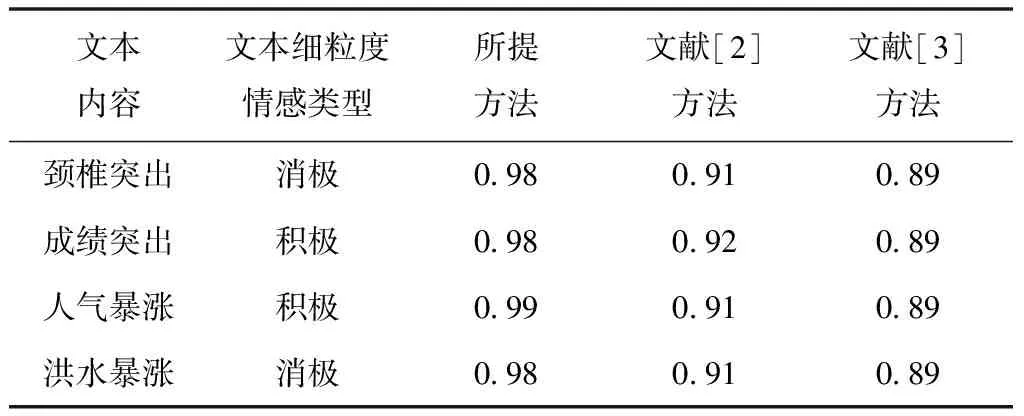
表3 三种方法Kappa系数测试结果
由表3可知,三种方法对四种存在歧义文本细粒度情感分类结果的Kappa系数差异较为明显。所提方法对四种存在歧义文本细粒度情感分类结果的Kappa系数最大值为0.99,所提方法对具有歧义文本细粒度情感的分类结果与实际情感一致性较高;文献[2]方法、文献[3]方法对四种存在歧义文本细粒度情感分类结果的Kappa系数均小于所提方法。由此可知,所提方法对具有歧义文本细粒度情感的分类精度较高,原因是所提方法使用了基于信息增益改进贝叶斯模型的文本词义消歧方法,有效去除文本词义歧义,提升文本细粒度情感分类精度。
4 结论
胶囊网络属于一种新型网络结构,与卷积神经网络的标量输入与输出模式相比,胶囊网络使用向量描述文本特征,能够合理兼顾文本深度层次的语义信息。提出基于改进胶囊网络的文本细粒度情感分类方法,可优化文本细粒度情感分类效果,存在一定使用价值。具体应用价值体现如下:
1)对某聊天系统里的文本细粒度情感实施分类后,当文本细粒度情感类型依次是喜悦、悲伤、惊奇、愤怒、恐惧、厌恶时,所提方法分类结果的查准率、召回率、F1值均大于95%,对多种文本细粒度情感分类效果较好;
2)所提方法对四种存在歧义文本细粒度情感分类结果的Kappa系数最大值为0.99,与1十分接近,所提方法对具有歧义文本细粒度情感的分类结果与实际情感一致性较高,能够有效提升文本细粒度情感分类精度。
