基于情感分析和PCA-LSTM 模型的股票价格预测
2021-11-19宋丽娜
宋丽娜
(华北电力大学 数理学院,北京 102206)
0 引言
传统的股票价格预测方法主要依托于股票历史交易数据。乔若羽基于股票历史交易数据构建一系列神经网络模型来预测股票价格,探索了不同模型对股票价格预测的效果。[1]冯宇旭等利用LSTM 模型结合股票基础变量对股票价格进行预测,证明LSTM 模型在股票价格预测上有较好的预测效果。[2]鹿天宇等在对股票价格进行预测过程中,利用主成分分析方法降低神经网络的变量输入维度,提高了模型的运行速度和精度。[3]魏健等利用主成分分析方法对四个模型预测的结果进行权值确定形成组合模型,发现组合模型的效果比单模型的效果好。[4]然而这些方法忽略了股票价格的其他影响因素,具有一定的局限性。随着互联网的普及,部分学者开始研究文本信息的情感分析对股票价格预测的有效性。肖亭等利用股评文本的情感分析结果预测股票价格上涨或下跌的趋势。[5]刘斌将股指序列与量化的文本情感序列输入BP 神经网络进行股指预测建模。[6]冉杨帆等以股票价格数据和股票新闻数据为基础,将情感分析方法与BP 神经网络和SVR 支持向量回归结合进行股票价格预测。[7]杨妥等证明利用SVM-LSTM 模型融合情感极性特征的股指预测较传统预测方法在预测精度上效果更好。[8]
综合上述研究,结合股票文本信息的情感指标构建模型对股票市场进行预测的方法成熟可行。然而模型中时间序列指标复杂冗余,考虑对所有指标进行降维和特征提取的研究却很罕见,故本文提出一种融合股票交易数据和文本情感数据的PCA-LSTM 股票价格预测模型。
1 股票价格预测模型建立
1.1 预测模型的构建
在综合考虑股票价格的影响因素后,运用PCA 方法对股票交易指标和股票文本情感指标进行降维处理。将得到的主成分作为LSTM 神经网络的输入变量,利用LSTM 神经网络进行模型的训练及预测,模型构建过程如图1。
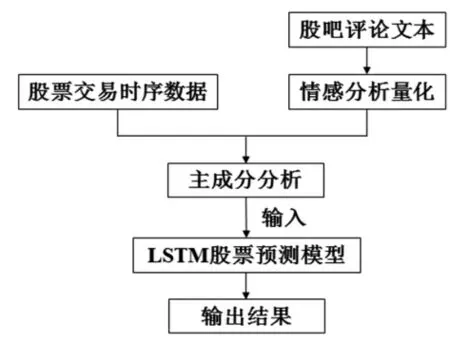
图1 股票价格预测流程
1.2 PCA 主成分分析方法
PCA 主成分分析是机器学习中的一种无监督变量降维方法,是在最大程度保留原始变量信息的前提下,利用正交变换将多个变量转换为较少的几个线性不相关的综合变量,达成变量降维的目的。
主成分分析可以分为如下几个步骤:
第一,原始指标数据标准化处理。标准化可表示为:

第二,计算样本相关系数矩阵R=[rij]p,其中rij为样本变量xi与xj的相关系数。
第三,计算特征值与特征向量。对相关系数矩阵R 求解特征方程得到p 个特征根,对其按大小排列:,之后分别求出特征根所对应的特征向量ej,(j=1,2,…,p)
第四,计算方差贡献率及累计方差贡献率:

第五,通过保证主成分的累计贡献率η∑(k)能够超过80%,以确定最小的正整数k,最终得到主成分的个数,并将其对应的k 个特征向量构成特征向量矩阵B。
1.3 LSTM 网络结构
LSTM 长短时记忆网络是循环神经网络的改进模型,其在网络状态内添加了记忆细胞状态,并通过增加遗忘门、输入门、输出门三个元件使得某一时刻的输出受当前时刻的输入和上一时刻的输出共同影响。以下公式表示LSTM 模型中遗忘门、输入门、输出门的状态值。
遗忘门ft:ft=σ(Wf*[ht-1,xt]+bf)
输入门it:it=σ(Wi*[ht-1,xt]+bi)
输出门Ot:Ot=σ(Wo*[ht-1,xt]+bo)
LSTM 的输出值ht:ht=Ot*tanh(Ct)
其中σ 表示sigmod 函数,Wf、Wi、Wc、Wo分别表示遗忘门、输入门、记忆细胞、输出门的权重矩阵,bf、bi、bc、bo表示遗忘门、输入门、记忆细胞、输出门的偏置项。
2 数据预处理
2.1 数据采集
本文选用了平安银行(000001)从2010 年1 月4 日到2020 年4 月30 日共2 440 个交易日的股票交易时序数据和文本数据。其中涉及的股票交易时序指标如开盘价、最高价、最低价、收盘价和成交量;技术指标包括能量潮、威廉指标、乖离率和布林带。本文选取东方财富网旗下财富社区下股吧论坛平安股吧帖子作为文本信息的来源。
2.2 文本情感分析
文本情感分析包括文本预处理、构建情感词典和文本量化。具体量化步骤如下。
2.2.1 文本预处理
首先采用Python 中文“结巴”分词对平安银行的股票评论文本进行分词处理;然后将目前使用较多的哈工大停用词表和百度停用词表的去重综合版作为停用词表,对分词后的所有词汇进行遍历,识别出停用词后并删除。
2.2.2 情感词典的构建
本文关于股票评论情感分析的情感词典主要包括两个部分,一部分是基础情感词典的集合,如知网情感词典(Hownet)、台湾大学情感词典(NTUSD)等;另一部分是利用jieba 分词结合TF-IDF 统计方法获得文本中词频的排序前1 000 个关键词中的情感词。另外,程度副词表和否定词表由基础的情感词汇表中剥离出来。表1 为情感词典部分内容示例。

表1 情感词典部分内容示例
2.2.3 文本量化
基于情感词典的文本情感值的计算过程是以建立的情感词汇表为基础,由Python 代码建立多个循环语句来对分词的词语进行遍历识别和计算实现的。具体计算公式如下:
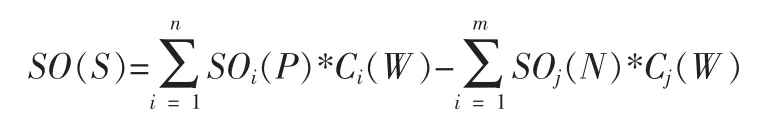
其中C(W)表示程度副词或否定词的权值,SO(P)表示积极情感词的权重,SO(N)表示消极情感词的权重。SO(S)大于0时,记为积极情感;SO(S)等于0 时,记为中立情感;SO(S)小于0 时,记为消极情感。
判断完每条评论的情感倾向后,可以计算出第i 天该股票的情感值,生成股票的情感指标序列,其中计算公式为:
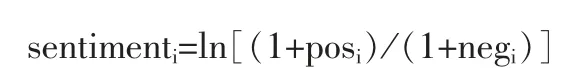
其中,posi表示第i 天的积极文本数,negi表示第i 天的消极文本数。
3 实证分析
在交易日的维度上,将每个交易日的股票交易时序指标与情感指标进行融合。运用SPSS 软件对所有股票影响因子序列进行PCA 降维分析,得到各主成分的总方差、方差贡献率和累计方差贡献率如表2,3 个主成分的累计方差达到80%以上,说明用这三个主成分就可以近似表示全部指标变量的信息。

表2 总方差解释表
将PCA 降维生成的3 列主成分数据代替原来的样本数据作为LSTM 神经网络的输入变量进行预测建模。
股价预测平台为Python3.7 环境Tensorflow 框架下Keras学习库,并将数据集2020 年1 月2 日之后的数据作为测试集来验证模型的预测效果。为证明基于情感分析和PCA-LSTM模型的股票价格预测(M1)的优越性,本文采用基于所有变量的LSTM 模型(M2)和BP 模型(M3)作为对比模型,预测结果如图2,误差结果对比情况如表3。结合图2 和表3 可知,本文提出的基于情感分析和PCA-LSTM 模型预测效果最好,且其MAPE、MAE、RMSE 值最小。

表3 模型的预测结果误差分析

图2 模型对比结果
4 总结
股票价格受多方面因素的影响,本文从量价和文本角度出发,以平安银 行(000001)从2010 年1 月4 日到2020 年4 月30 日共2 440 交易日的股票交易时序指标与文本情感指标数据作为PCA-LSTM 模型的输入特征进行训练及预测。结果表明,本文提出的基于情感分析和PCA-LSTM 模型具有较高预测精度,并且其结果要优于LSTM 模型和BP 神经网络。
