面向阅读推广评论数据的书目个性化推荐方法探究*
2021-11-18叶颖
叶颖

摘 要 图书馆阅读推广活动所产生的用户数据对于进行与读者有关的研究具有重要价值。論文通过LDA主题模型对阅读推广活动中读者书目推荐评论的主题内容进行挖掘,再使用余弦定理进行相似度计算,然后根据计算结果、融合读者背景信息进行个性化的书目推荐。实验结果表明,论文构建的书目推荐方法能够依据读者参加的阅读推广活动的内容进行相关书目的推荐,拓展了图书馆阅读推广服务有关研究的应用范围,为图书馆书目的采购与推荐工作提供了有益的参考。
关键词 LDA 困惑度 相似度 推荐方法
分类号 G251.4
DOI 10.16810/j.cnki.1672-514X.2021.10.006
Research on Bibliographic Personalized Recommendation Method for Reading Promotion Review Data
Ye Ying
Abstract The user data generated by library reading promotion activities is of great value for the research related to readers. This paper uses LDA topic model to mine the topic content of readers bibliographic recommendation comments in reading promotion activities, then uses cosine theorem to calculate the similarity, and then carries out personalized bibliographic recommendation according to the calculation results and integrating readers background information. The experimental results show that the bibliographic recommendation method constructed in this paper can recommend relevant bibliographies according to the contents of reading promotion activities participated by readers, expand the application scope of relevant research on library reading promotion services, and provide a useful reference for library bibliographic procurement and recommendation.
Keywords LDA. Perplexity. Similarity. Recommendation method.
阅读推广在过去二十年多年中逐渐成为图书馆的主流服务之一,目前已经发展为图书馆服务中最具活力、最能体现图书馆核心价值的一环[1]。阅读推广服务由阅读指导发展而来,而后经历读者咨询等形式上的变化,最后演化为如今的阅读推广服务[2]。通常意义下,图书馆阅读推广的主要工作可以分为激发阅读意愿、培养阅读能力、跨越阅读障碍三个方面。随着信息技术的迅猛发展,阅读推广的服务范围与内容越来越广泛,形式越来越多样,服务也由线下逐步转移到了线上。在不断的积累与完善中,图书馆阅读推广服务产生了大量的读者推荐数据,这些数据与传统的书目借阅数据在图书馆读者行为的研究中具有同样重要的意义,因此如何利用图书馆阅读推广数据进行读者研究,甚至于提升文献借阅指标,进行智慧化的精准服务,成为了图书馆阅读推广服务研究的一个新方向。
1 相关文献综述
1.1 图书馆阅读推广的有关研究
当前国内外阅读推广的有关研究可以分为三个方面。首先是图书馆阅读推广的基础理论、制度、体系的有关研究,如于良芝等[3]从循证图书馆学的角度对图书馆阅读推广的研究领域进行划分,明确了阅读推广的研究内容;Elliott[4]指出,阅读推广在进行读者服务中具有极为重要的意义,它是图书馆服务的基本组成部分,建立有效的制度体系对图书馆的发展至关重要;张伟[5]通过对阅读推广活动中各种内部资源要素进行规划和设置,构建了阅读推广管理制度体系;谢蓉等[6]提出了图书馆阅读推广的定义,明确了阅读推广的目标与类型,为阅读推广的发展提供了理论依据。其次是图书馆阅读推广的模式、案例、实践的有关研究,如Tilley[7]研究了鼓励对青少年进行漫画以外儿童书籍的阅读推广的活动策略;耿寒冰等[8]研究孤儿学生的阅读情况,发现其阅读中出现的问题,通过阅读循环圈理论提出为孤儿等弱势群体进行阅读推广服务的模式与策略;孙媛媛等[9]以二十四节气为切入点将中华传统文化与阅读推广进行融合,研究了针对高校图书馆的立体阅读推广模式。最后,还有对阅读推广服务影响与评价的有关研究,如岳修志[10]提出了针对阅读推广活动的评价指标以及全民阅读体系及其评价指标,同时依据这些指标对阅读推广活动的过程及其要素进行了分析;刘一鸣等[11]针对传统文化类有声书的阅读推广服务构建了绩效评价指标体系,从内容等多个维度出发,提出传统文化类有声书的阅读推广服务策略。
从上述文献综述可以发现,国内外有关阅读推广的研究从概念入手确定了阅读推广的定义,提供了阅读推广的理论基础;从案例入手介绍了阅读推广的应用情况,进行了阅读推广的可行性分析;从评价入手分析了阅读推广的实施效果,为阅读推广进一步提升服务质量提供了策略和措施。然而笔者发现,针对阅读推广数据利用与分析的有关研究较为少见,因此如何利用阅读推广评论数据扩展图书馆用户行为分析的范围,成为了阅读推广有关研究的一个新领域。
1.2 图书馆书目推荐的有关研究
当前国内外图书馆书目推荐的有关研究一方面集中在分析圖书相似度后依据用户借阅记录进行推荐,如Tewari[12]依据图书内容提出了一种基于内容过滤、协同过滤和关联规则挖掘的图书推荐方法;田野等[13]将馆藏数据与外部相关的关联数据相融合,依据内容关联相似图书针对不同用户进行书目推荐。另一方面书目推荐的有关研究依据用户相似度,为相似用户推荐具有共同特征的图书,如Vaz等[14]根据读者书单的相似性对读者进行分类,并根据读者的不同类型进行书目的分类推荐;Sohail等[15]根据用户的书评构建图书标签,依据标签的相似性为用户提供图书的分类推荐;彭博[16]融合用户的背景信息与借阅数据,为具有相似特征的用户进行个性化的书目推荐。
在图书馆书目推荐的有关研究中,学者们多依据读者的借阅行为与图书内容标签作为数据来源进行书目推荐,而针对读者的有关特征进行的推荐研究多以读者的年龄、职业、专业等固定属性进行分类,由于读者数据采集的难度,难以根据读者的内在特征,如性格、爱好等进行分类,致使分类精度较低。而图书馆阅读推广服务中产生的数据,如读者的推荐、评论、点赞等,为内在特征的分类提供了新的数据来源,弥补了当前书目推荐研究的缺失。
2 面向阅读推广的书目推荐算法及关系构建
在高校图书馆的线上阅读活动中,读者都会在阅读行为中留下相关的阅读偏好与评论,据此可以产生书目推荐数据与书目评论数据。由于参与读者实名制的原因,可以通过图书馆管理系统同时获取读者的专业、年级等外部属性数据。读者的推荐数据代表了其对图书的喜好;读者的评论数据可以挖掘其内在特征与书目的内容特征,外部属性数据的补充则可以进一步强化读者相似性的提取。使用高校图书馆阅读推广中的评论数据进行读者特征与书目内容的挖掘相较于当前基于豆瓣读书、微博等社会化媒体进行的研究更贴合图书馆读者的实际情况,其数据挖掘与书目推荐的效果也更加精确。
2.1 读者相似度计算方法
读者在阅读推广活动中的书目推荐评论一方面概括了所推荐书目的主要内容,另一方面评论中的语言风格、用词方式则是读者思维与性格的体现。提取评论的主要内容并加以精炼,可以将书目内容与读者个性相结合,找出爱好相同类型书目及性格相近的读者并进行分类。
在用户评论内容的提取上,文章采用LDA主题模型对阅读推广活动中的读者推荐评论进行主题识别。LDA模型是一种三层贝叶斯概率模型[17],通过分析文档、主题、词项,假设所有的文档中有一定数量的隐含主题,通过一定概率抽取主题,然后再选定主题中抽取的特征词,通过预设的迭代次数得到足够的特征词[18],文档中包含特征词的概率为:
(1)
对每位读者的推荐评论进行主题识别后,由于参与阅读推广活动的读者数量有限,如果直接从主题关键词相似程度来计算读者相似度,会由于读者评论数据的稀疏性而造成相似度为0的情况,而增加LDA主题模型所提取主题关键词的个数则会忽略读者评论中的语义相似度,进一步放大数据稀疏性所带来的影响,因此需要根据主题内容的特征对读者进行分类,将具有一定特征的读者视为一类,以增加读者评论数据的关联程度。鉴于上述情况,文章以读者为单位,将每位读者的评论汇集为一篇文档,采用文档集合的最优主题数量作为读者分类的基数。但LDA模型无法确定文档集合的最优主题数量,因此文章使用困惑度[19]指标,通过计算文档集合的困惑度来决定最优主题数,计算公式为:
(2)
其中p(w)代表测试集中每一个词的出现概率,N表示测试集,按照主题数量通过公式对文档集合进行困惑度计算,选择变化程度最高的主题数作为最优主题数。
文章将同一分类中的读者相似度计为1,而不同分类间的相似度使用余弦定理进行计算,以选定分类为入口进行两两计算,其值越接近于1,则表明两类读者越相似,计算公式为:
(3)
为了更进一步地体现读者特征,文章把从图书馆管理系统中得到的读者外部属性作为相似度增项加入到最终相似度的计算中,如两位读者处于同一年级则相似度为1,若不同则为0;同理,两位读者属于同一专业则相似度为1,不同则为0。读者的年级信息、专业信息和基于评论内容计算的相似度按1:1:8的比例,作为最终用户相似度的计算结果。
2.2 读者—书目关系构建
文章根据阅读推广中的读者推荐数据进行读者—书目关系的构建,构建方法为:若读者在21天中推荐的书目只有一个,则读者与书目之间建立关联关系,关系权重为1;若读者在21天中推荐了多个书目,则按照单一书目推荐天数占总推荐天数的比例乘以1,作为单一书目的与读者间关联关系的权重。其计算公式为:
(4)
其中P为读者与书目间的关系权重,dr为单一书目的推荐天数,d为阅读推广活动持续的天数,在文章的研究中取值为21。
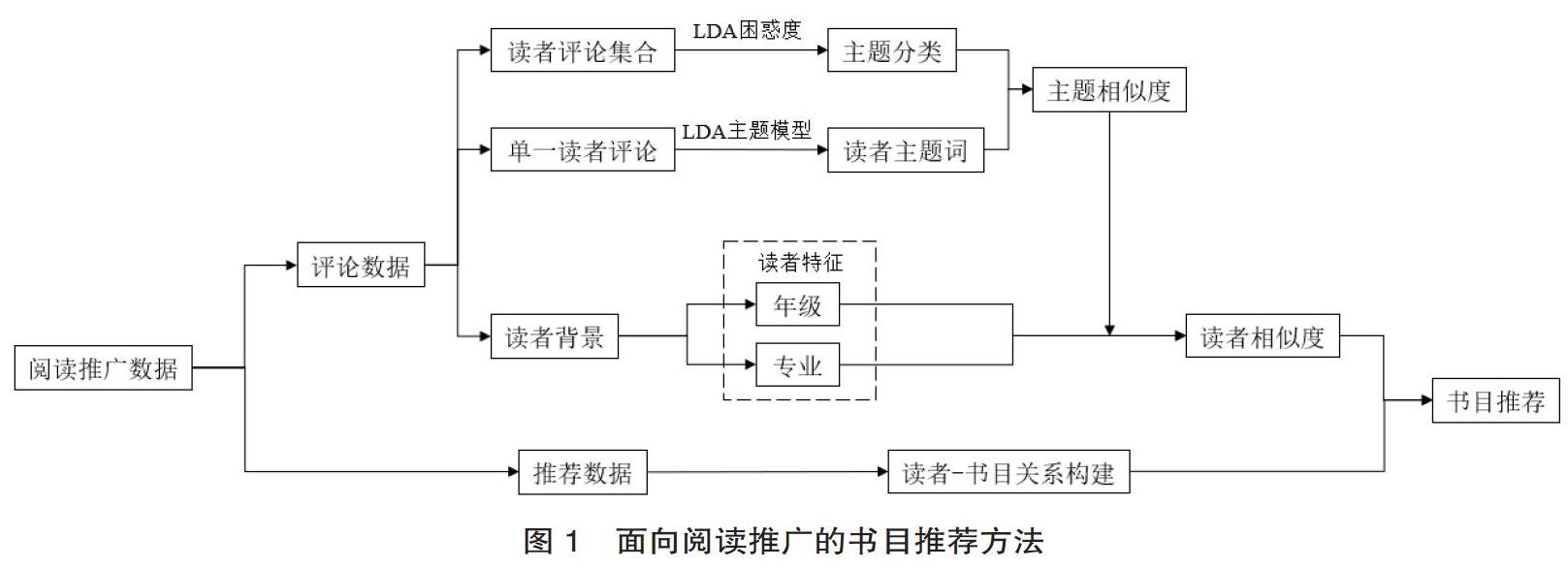
综合上述内容,面向阅读推广的书目推荐模型如图1所示,书目推荐以选定读者为切入点进行读者相似度的计算,最终的书目推荐权重以读者相似度计算值与读者—书目关系的乘积取得。其计算公式为:
(5)
其中Rs代表读者相似度,P代表读者—书目关系权重,Br值越接近于1,代表书目推荐的优先度越高,最终推荐结果根据Br的值由高到低排列。面向阅读推广的书目推荐方法如图1所示。
3 实验
文章以中南财经政法大学“阅跑中南”阅读推广活动的第一季为数据来源。中南财经政法大学“阅跑中南”阅读推广活动开始于2018年9月,活动内容为读者连续21天阅读一本或多本书籍,并坚持每天在“阅跑中南”线上专区发布话题,进行阅读打卡,期间可以任意选择书籍进行阅读。打卡内容为语音朗诵、图片记录、视频分享、阅读心得、读书笔记、人生感悟、思维导图等。第一季活动共有709名读者报名参加,发表话题5628条。本实验将读者、推荐书目与话题内容进行关联,对单个读者推荐同一本书的话题数进行累加,以计算该书在读者推荐书目中的权重,并同时通过图书馆管理系统同步读者专业及年级的背景信息。
3.1 读者相似度的计算
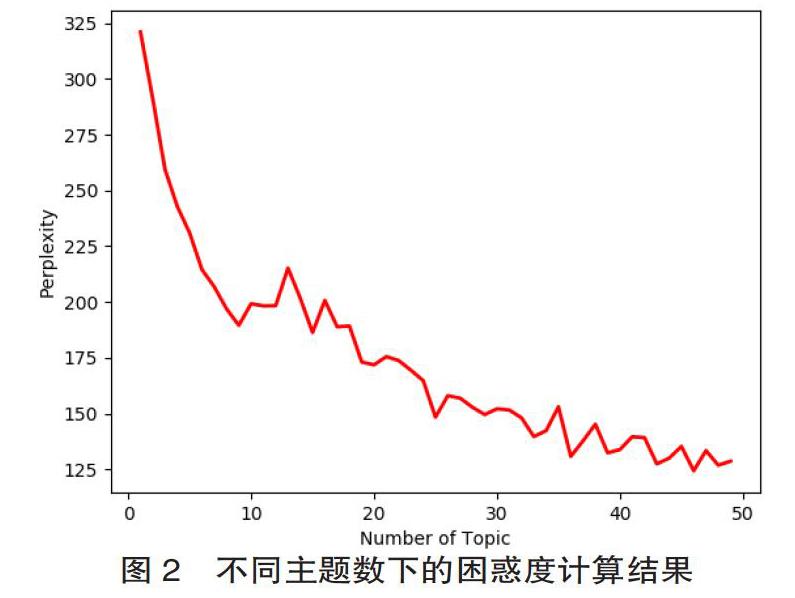
文章首先对阅读推广活动中的读者评论进行分词,分词工具选用Python语言下的Jieba分词工具包,停用词表选取哈工大停用词表。分词后的结果显示每位读者在整个活动中发表评论的词数平均值为274,文章按5%的比例抽取关键词作为读者评论的主题代表,因此LDA模型在每个主题下选取的主题关键词数k都取值为14。随后根据上文中的LDA困惑度计算方法,选择主题词个数14进行困惑度的计算,以确定潜在的最优主题数K,计算范围选择的主题个数为1~50。计算结果如图2所示,横轴表示主题个数,纵轴表示困惑度值。从图中可以发现,主题增加,困惑度值呈波动下降;随着主题取值的进一步增加,困惑度值不断减小且趋于稳定。在主题个数为9时,困惑度出现首次波动并呈现出局部极小值,之后继续增加主题数所得收益要小于增加主题数的投入,因此确定9为最优主题数[20],即表示在数据集中的评论内容可以被分为9类,相应地也代表参加本次阅读推广活动的读者根据其评论内容可以被分为9种类型。
在确定了最优主题数后,文章使用LDA主题模型对阅读推广读者评论进行主题分类,模型的超参数取α=50/K,β=0.01,迭代次数设置为50次,主题数选择为9,主题关键词数目选择为14。通过LDA主题模型获取的主题分类如表1所示,主题关键词后的数字代表该关键词与该主题的关联程度,也代表其在分类中的重要程度。
随后文章利用表1的结果进行读者相似度计算。该计算方法是以某一位读者为切入点来计算出与其处于同一分类下的其他读者,而后根据其他读者的背景信息进行复合加权,选择评论内容最相似读者的关联书目进行推荐。
文章以系统编号69924406的读者为例进行读者相似度计算,其在21次的阅读推广活动打卡中有15次推荐《人间有味是清欢》、3次推荐《不可承受的生命之轻》、3次推荐《并购之后》。通过LDA主题模型以主题数1、主题关键词数14计算其评论中的主题关键词。结果如表2所示,该读者属于分类6,而后根据余弦定理计算该读者与其他分类中读者的相似度。将读者进行分类是为了避免前文中读者评论数据的稀疏性影响所有读者间关联关系的建立,分类后由于所有分类间具有一定的相似度,也就不会影响单个读者间关联关系的建立,继而建立所有参加阅读推广活动读者间推荐书目的关联。
在获得读者评论相似度后,文章根据前文中的方法,将该读者的背景信息与各分类中读者的背景信息进行匹配,引入读者专业与年级进行加权读者相似度的计算。与该读者同专业背景的读者专业相似度为1,不同则为0,专业判定标准以国务院学位委员会学科评议组审核的《授予博士、硕士学位和培养研究生的学科、专业目录》中的12种学科门类为依据划分;读者年级相似度依照本科、研究生年级进行划分,与该读者同年级的读者年级相似度为1,不同则为0。专业、年级、评论相似度按1:1:8的比例加权计算最终读者相似度。
3.2 基于读者相似度的书目推荐
读者相似度是衡量读者间是否具有共同特征的指标,本实验通过读者相似度挖掘读者间的关联关系,再根据相关读者的推荐书目为目标读者进行书目推荐,书目推荐结果的前5名如表3所示。由于不同读者在阅读推广活动中推荐书目的天数不一,经过加权计算后,最相似的是读者在阅读推广活动中推荐了多本书目,导致其推荐书目在最终的相似度计算结果中权重较低。
从表3中关联读者书目前5名的推荐表可以发现,目标读者“69924406”推荐权重最大书目为于丹著的《人间有味是清欢》,主要内容是对人生、文化、社会、生活的再度思考,这也是她面对连连争议和读者、媒体、学界的种种误解,首度自剖成长经历和心路历程,涉及生活感受、旅行随想、对女儿的教育体悟等。推荐书目表中,威廉·萨默赛特·毛姆著的《人性的枷锁》叙述了主人公菲利普从童年时代起在家庭、学校和社会中三十年的生活经历,反映了主人公成长过程中的迷惘、挫折、痛苦、失望、探索及其所受到的身体缺陷、宗教和情欲的束缚,以及主人公最后擺脱这些枷锁的成长历程,其主要内容是叙述成长的过程,与目标读者推荐书目相似。余华著的《我只知道人是什么》分享了他的观察和思考,内容包罗万象,从往事到现实,从自我到时代,既漫谈生活体验,也谈及创作心得,展现出一位优秀作家对生活的深刻洞察、对一切事物理解后的超然。雪小禅著的《繁华不惊,银碗盛雪》散文集旨在记录生活中不曾在意的温柔细节和光阴之美。郑渊洁著的《皮皮鲁压缩人生7天》从童话视角讲述人生压缩的故事,为读者带来人生的启示。施瓦尔贝著的《生命最后的读书会》讲述其与母亲通过读书会开始的一段阅读广度和人生深度的对话之旅。以上的推荐结果表明,文章采用的书目推荐方法能够以某一读者为计算切入点,依据该读者与其他读者参加阅读推广活动时的书目推荐评论内容进行个性化的相似书目推荐。同时根据中南财经政法大学图书馆现有的书目馆藏,在前5的推荐书目中,有2册不在图书馆纸质资源的馆藏中,文章推荐方法在进行书目推荐的同时,还能够为图书馆书目的荐购工作提供数据支持。
3.3 结论
在针对图书馆读者参与阅读推广活动的内容进行了个性化的书目推荐的实验中,首先计算读者评论集合中的LDA主题模型困惑度,依据困惑度得到基于评论内容的读者分类依据。随后通过LDA主题模型以单个读者评论的集合得到读者主题关键词,并根据其与主题分类相似度的大小将其划入相对应的主题分类中。最后在以主题分类为依据的读者相似度计算中加入读者的背景信息权重,根据相似读者推荐图书时间的多少,按照相似度的高低为目标读者进行书目推荐。在书目推荐结果的准确性上,推荐结果显示该方法能够根据目标读者评论的内容找到其他读者推荐的内容相似的书目,同时根据读者相似程度、读者推荐书目重要程度对推荐书目进行排序。在书目推荐结果的范围上,由于阅读推广活动中读者推荐书目的类型既包含传统的纸质出版物,也有部分网络文献,极大地丰富了书目推荐的内容;同时由于部分推荐图书尚未购置进图书馆馆藏,该书目推荐方法也为图书馆荐购工作提供了一定的数据支持。在书目推荐结果的实用性上,其推荐结果也更具有实际使用价值。
4 结语
相较于基于豆瓣读书、微博等引入外部书目评论数据进行的书目推荐,高校图书馆阅读推广活动中的读者评论在内容的精炼程度与相关性上更贴近图书馆读者的真实情况,其推荐效率与推荐效果更加实用。同时与基于读者借阅数据进行的书目推荐相比,结合书目内容的推荐方法能够准确与更深层次地挖掘读者特点,依据内容对读者进行用户画像,进行推荐的质量也更高。但另一方面,受制于图书馆阅读推广活动的规模与参与度,面向阅读推广进行的书目推荐范围较小,无法满足图书馆读者的全部阅读需求。在未来的研究中,本研究将进一步扩大阅读推广活动数据采集的规模,同时根据累积的历史数据对书目推荐效果进行评价,从而更加深入地挖掘阅读推广活动中读者有关数据的价值。
参考文献:
范并思.阅读推广与图书馆学:基础理论问题分析[J].中国图书馆学报,2014,40(5):4-13.
李武,杨飞,毛远逸,等.图书馆阅读推广人角色研究:类型构成、前置因素和后续影响[J].中国图书馆学报,2020,46(3):73-87.
于良芝,于斌斌.图书馆阅读推广:循证图书馆学(EBL)的典型领域[J].国家图书馆学刊,2014,23(6):9-16.
ELLIOTT J. Academic libraries and extracurricular reading promotion[J].Reference & User Services Quarterly,2007,46(3):34-43.
张伟.公共图书馆阅读推广管理制度建设[J/OL].图书馆建设,2020(5):64-70,99[2020-08-22].http://kns.cnki.
net/kcms/detail/23.1331.G2.20200612.1150.004.html.
谢蓉,刘炜,赵珊珊.试论图书馆阅读推广理论的构建[J].中国图书馆学报,2015,41(5):87-98.
TILLEY C L.“Superman Says,‘Read!”National comics and reading promotion[J].Childrens Literature in Education,2013,44(3):251-263.
耿寒冰,马捷,赵天缘.“阅读循环圈”理论框架下的弱势群体阅读服务模式与策略:以吉林省青少年孤儿为例[J].图书情报工作,2020,64(4):24-33.
孙媛媛,张玲,于静,等.高校图书馆中华传统文化立体阅读推广探究:以北京师范大学图书馆“二十四节气”阅读推广为例[J].图书情报工作,2020,64(9):57-64.
岳修志.阅读推广活动评价指标体系构建[J].图书情报工作,2019,63(5):42-50.
刘一鸣,谢泽杭,汪全莉.基于绩效评价的传统文化类有声书阅读推广研究[J].图书情报工作,2020,64(4):15-23.
TEWARI A S,KUMAR A,BARMAN A G.Book recommendation system based on combine features of content based filtering,collaborative filtering and association rule mining[C]//2014 IEEE International Advance Computing Conference (IACC).IEEE,2014:500-503.
田野,祝忠明.关联数据驱动的数字图书推荐模型[J].图书情报工作,2013,57(17):34-38,52.
VAZ P C, MARTINS, MATOS D, MARTINS B, et al. Improving a hybrid literary book recommendation system through author ranking[C]//Proceedings of the 12th ACM/IEEE-CS joint conference on Digital Libraries. 2012: 387-388.
SOHAIL S S, SIDDIQUI J, ALI R.Book recommendation
system using opinion mining technique[C]//2013
international conference on advances in computing,
communications and informatics (ICACCI).IEEE,2013:1609-1614.
彭博.面向用户属性的个性化图书推荐方法探究[J].图书馆工作与研究,2017(10):118-123.
BLEI D M,Ng A Y,JORDAN M I.Latent dirichlet allocation [J].Journal of Machine learning research,2003(3):993-1022.
劉雅姝,张海涛,徐海玲,等.多维特征融合的网络舆情突发事件演化话题图谱研究[J].情报学报,2019,38(8):798-806.
THORNDIKE R L.Who belongs in the family?[J].
Psychometrika,1953,18(4):267-276.
吴江,侯绍新,靳萌萌,等.基于LDA模型特征选择的在线医疗社区文本分类及用户聚类研究[J].情报学报,2017(11):1183-1191.
叶 颖 中南财经政法大学图书馆馆员。 湖北武汉,430073。
(收稿日期:2020-12-02 编校:左静远,刘 明)
