基于便携式拉曼光谱的汽油快速识别模型
2021-11-18丁怡曼薛晓康董学胜舒耀皋
丁怡曼,薛晓康,范 宾,董学胜,舒耀皋,蒋 鑫
(上海化工研究院有限公司 上海化学品公共安全工程技术中心,上海 200062)
汽油是目前最常用的发动机燃料,与人们的日常生活密切相关[1]。而某些商家为了赚取更多利润,出现以低牌号汽油冒充高牌号汽油的不良行为,因而会伤害发动机,损害消费者的利益。因此,对市售汽油牌号及实际辛烷值进行检测十分必要。
标准汽油牌号的识别方法包括测定汽油的研究法辛烷值(RON)或马达法辛烷值(MON)[2],该方法准确度高,测试结果可靠,但需配备专用的汽油辛烷值试验机及标准燃料,费时且昂贵[3-4]。因此,科技人员在不断寻求能快速、准确识别汽油牌号和辛烷值的方法。张其可等[5]提出了基于近红外光谱的汽油牌号识别算法,具有较好的分类效果;姜黎等[6]基于近红外光谱波段选择,并结合主成分分析-马氏距离法(PCA-MD)对90号、93号、97号等不同牌号的汽油进行了分类。
研究发现,采用拉曼光谱能在短时间内获得汽油分子内部丰富的骨架振动信息[7];且对于不同牌号的汽油,拉曼光谱呈现出明显的区分性;同时,相比于近红外光谱仪,拉曼光谱仪的成本较低。因此,拉曼光谱法开始被用于汽油牌号的识别,如Li Sheng等[8]采用拉曼光谱仪,并结合局部加权-偏最小二乘支持向量机(LSSVM)成功对90号、93号和97号汽油进行了分类。
在已有研究的基础上,本研究采用小型便携式拉曼光谱仪,并结合主成分分析和最小二乘化学计量算法,建立汽油牌号模型和汽油RON预测模型,旨在提供一种汽油牌号和实际辛烷值的快速现场识别方法,以协助对汽油质量的现场检测工作。
1 实 验
1.1 样品和仪器
试验收集了113个成品汽油样品,由江苏省产品质量监督检验研究院、杭州市质量技术监督检测院提供,其中92号汽油样品67个,95号汽油样品46个,每个样品都有对应的RON数据。
拉曼光谱仪为美国必达泰克公司生产的BWS415-785S型i-Raman便携式拉曼光谱仪,主要由激发波长为785 nm的激光器、收集拉曼信号的光纤探头以及光谱仪组成,并配有拉曼光谱采集软件BWSpec,光谱测量范围为175~3 150 cm-1。
1.2 光谱采集
首先将拉曼光谱仪的光纤探头插入至样品池,然后将装有一定量汽油样品的比色皿放入样品池中,开启光纤探头的光源开关,打开BWSpec分析软件,将积分时间设置为4 000 ms,时间乘数设置为1,平均采集次数设置为3。调整激光强度为0,进行暗电流扫描,以消除背景干扰,并调整激光强度为90%。对113个汽油样品逐个进行光谱扫描,采集其拉曼光谱。
1.3 化学计量学算法
建模用算法的编写和操作均在MATLAB2016a软件上进行,程序在Window10系统环境下运行。
1.3.1 主成分分析法(PCA)主成分分析是将原变量进行变换,在只损失极少量信息的前提下,将多个指标转化为少数几个综合指标(主成分),以降低数据维度[9]。其基本思路是将样品的光谱矩阵X进行主成分分解,然后以主成分来解释原始变量,依据的是方差最大原则。本试验采用奇异值分解法对光谱矩阵X进行主成分分解,基本过程如式(1)和式(2)所示
X=U·S·Vt
(1)
T=U·S
(2)
式中:U为列正交矩阵,蕴含了样品的类别信息;Vt为行正交矩阵(t代表矩阵的转置运算);S为奇异值矩阵,反映每个主成分的特征值;T为矩阵X的得分矩阵,代表新变量,通过选择T的数量,可以实现对原始光谱数据的信息压缩,便于提取样品的类别信息。
1.3.2 偏最小二乘法判别分析法(PLS-DA)PLS-DA是基于偏最小二乘回归法(PLS)进行样本的分类识别[10],是一种有监督的模式识别方法[11],可用于汽油牌号的分类识别。具体思路为:以所有汽油样品的光谱数据组成自变量矩阵X,矩阵的行对应每个样品,列对应特征变量(即拉曼谱峰强度),见式(3);以样品类别信息构成因变量矩阵Y,其中行对应每个样品,列对应样品的牌号;Y是一个以0和1为元素的矩阵,若样本属于同一类,则该样本在Y中对应列的元素为1,见式(4)。然后,将X、Y的每一列分别进行PLS回归分析建模,并计算得到各样品对应的回归预测值yp。PLS-DA模型的识别规则为:若样品对应列的预测值yp>0.5,则可判定该汽油样品属于同类,否则不属于同类。
(3)
(4)
1.3.3 偏最小二乘法(PLS)偏最小二乘法也是通过原始变量的线性组合,产生新变量(PLS因子),然后将PLS因子进行多元线性回归。与主成分分析不同的是,偏最小二乘法在计算主成分时,除考虑计算的主成分方差最大外,还要求主成分与因变量矩阵Y相关程度最大[12]。PLS算法的基本过程如下:
①按照式(5)和式(6)对X、Y矩阵进行分解。
X=TP+E
(5)
Y=MQ+F
(6)
式中:M为矩阵Y的得分矩阵;P和Q分别为矩阵X和Y的主成分矩阵;E和F分别为PLS算法对矩阵X、Y引入的误差。
②将T、M进行线性回归,按照式(7)和式(8)计算系数矩阵B,即:
由M=TB
(7)
可得B=TtM(TtT)-1
(8)
③根据①中所得的主成分矩阵P和未知样品的光谱矩阵X,求出未知样品的得分矩阵T,然后,根据式(7)可求出因变量Y对应的得分矩阵M,最后,由式(9)可得到未知样品的预测值yp。
yp=TBQ
(9)
2 结果与讨论
2.1 光谱预处理
拉曼光谱仪在采集光谱信号的过程中可能存在激光强度不稳定和噪声干扰,造成荧光信号较强而样品光谱信号较弱的问题,使拉曼谱峰产生荧光干扰、噪声干扰和基线漂移、光谱重叠等现象,从而对光谱特征的提取产生不利的影响[13-14]。
因此,需要用BWSpec分析软件校正基线,具体过程为:首先,根据原始光谱自动拟合对应的背景曲线;然后,调节lambda因子,使自动拟合的背景区域最大化的位于基线漂移的区域;最后,对原始光谱进行背景扣除,使漂移的基线回正。汽油样品基线校正后的拉曼光谱如图1所示。

图1 汽油样品基线校正后的拉曼光谱
2.2 汽油牌号模型建模分析
2.2.1 主成分分析法将汽油样品基线校正后的光谱数据进行主成分分析,得到蕴含汽油牌号类别的得分矩阵T,选取T的前3个主成分PC1,PC2,PC3,得到汽油样品的PCA分类散点图,分别计算每个汽油样品到其他样品的欧氏距离,以每个样品距离最近的样品种类的作为汽油牌号分类的判据,计算所有样品分类正确率。结果表明:在113个样品中,此模型计算分类正确的样品数目为84个,分类正确率为74.34%。
为提高汽油牌号识别模型的分类正确率,对基线校正后的光谱数据分别进行一阶求导或二阶求导处理,并设置不同求导点数p,计算汽油样品牌号的分类正确率,结果如表1所示。从表1可以看到,经求导处理后,样品牌号的分类正确率明显提高,其中经二阶求导(p=11)处理后,分类正确率可达92.92%。此时,汽油样品的PCA分布散点如图2所示。由图2可以看到,92号、95号汽油可基本实现区分。
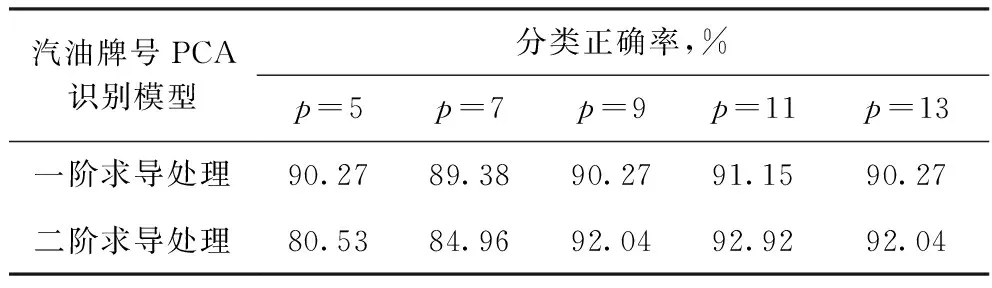
表1 不同求导点数p下的汽油牌号PCA分类正确率

图2 求导处理后汽油样品的PCA分类分布
2.2.2 偏最小二乘判别分析法采用基线校正后的光谱数据进行偏最小二乘判别分析,建模前首先将113个92号汽油和95号汽油样本集随机划分为校正集(86个样本)和预测集(27个样本)。
(1)潜变量数的选择
试验通过五折交互检验法来确定潜变量的数目[15],即将校正集随机分为5组,其中一组用于模型预测,也称交互检验集,其他组用于模型建立,计算不同潜变量下交互检验集的平均正判率,结果如图3所示。由图3可知,当潜变量数为7时,平均正判率达到最大值。图4为交互检验过程中校正集均方根误差和交互检验集均方根误差的变化情况。从图4可以看到,随着潜变量数的增加,校正集的均方根误差始终小于交互检验集,符合数据建模规律。因此选取建模的最佳潜变量数为7。
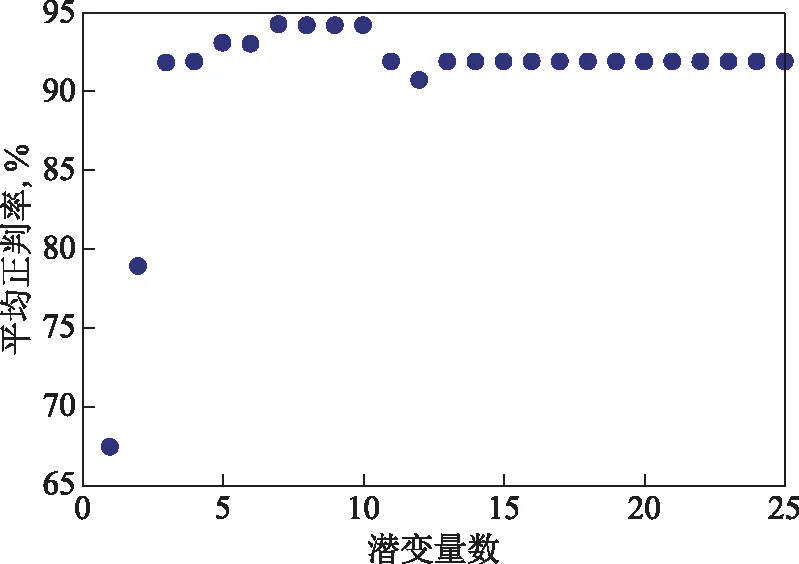
图3 交互检验集正判率变化

图4 校正集和交互检验集的均方根误差随潜变量数的变化
(2)PLS-DA模型判别结果
选定最佳潜变量数后,以校正集汽油样品建立汽油牌号PLS-DA模型,然后再以此模型分别对校正集、预测集的汽油牌号进行预测,结果如表2所示。从表2可以看到,所建的汽油牌号PLS-DA模型对校正集和预测集汽油牌号的正判率分别为97.67%和96.30%,分类错误个数分别为2和1。

表2 PLS-DA模型判别结果
为了更加直观地反映汽油牌号PLS-DA模型的预测效果,分别对校正集、预测集的汽油牌号分类结果作图,结果如图5所示。由图5(a)可知,校正集中除编号为64、81的两个95号汽油样品识别错误外,其他牌号汽油样品均正确识别;由图5(b)可知,预测集中仅编号为6的92号汽油样品识别错误,因而具有较好的预测效果。总体来看,相比于主成分分析建模92.92%的正确率,采用PLS-DA建立的汽油牌号模型对于92号、95号汽油的分类识别具有更好的效果,其正判率均在95%以上。
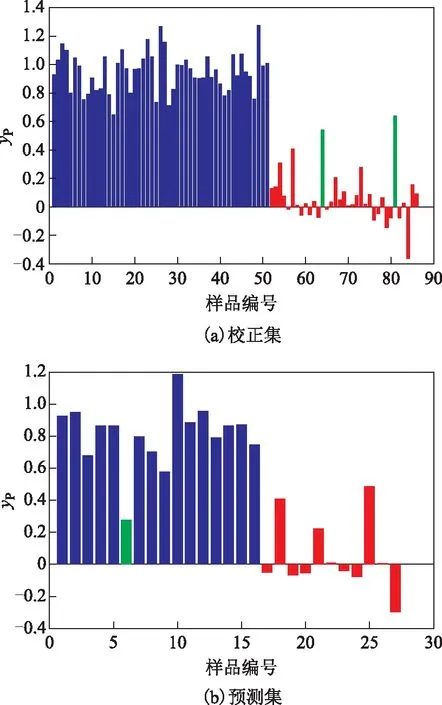
图5 校正集和预测集的PLS-DA分类
2.3 汽油RON建模分析
在基线校正后的汽油样品光谱数据矩阵X、样品RON数据矩阵Y的基础上,采用偏最小二乘法(PLS)建立汽油RON定量预测模型。建模前,将113个汽油样品随机划分为校正集(70个样本)、交互检验集(23个样本)、预测集(20个样本)。
2.3.1 PLS因子数的确定PLS因子数以交互检验集的预测残差平方和(PRESS)来确定,如图6所示。由图6可知:当PLS因子数小于8时,随着PLS因子数增加,交互检验集的PRESS快速减小;当PLS因子数为8时,交互检验集的PRESS最小;当PLS因子数超过8后,PRESS逐渐增加,出现过拟合的现象。因此,选取最佳PLS因子数为8,建立汽油RON预测模型。
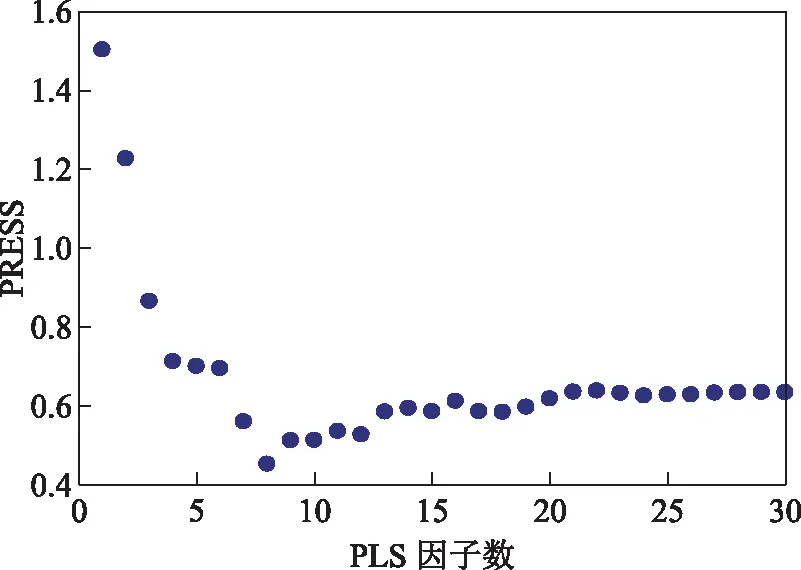
图6 不同PLS因子数对应的交互检验集PRESS
2.3.2 模型预测以建立的PLS汽油辛烷值模型对校正集、预测集进行预测,并分别计算其相关系数及均方根误差,结果如表3所示。由表3可知:校正集实际辛烷值与预测辛烷值的相关系数为0.944 8,均方根误差为0.512 6;预测集实际辛烷值与预测辛烷值的相关系数为0.892 7,均方根误差为0.609 6,它们的相关系数均接近于1,说明模型预测辛烷值与实际辛烷值相比偏差较小。
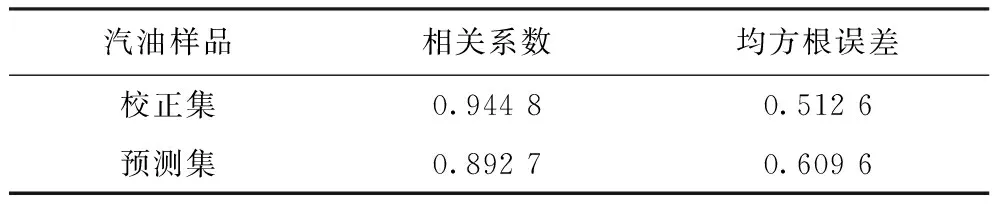
表3 PLS辛烷值模型预测结果
图7为校正集和预测集汽油样品RON实际值与预测值的相关图。由图7可以看到,汽油样品靠近于对角线两侧,说明汽油样品RON实际值与模型预测值具有很好的相关性。这表明,建立的PLS汽油辛烷值预测模型能够对汽油样品的RON进行精确预测。

图7 校正集和预测集汽油样品RON实际值与预测值的相关性
3 结 论
基于汽油样品的拉曼光谱数据,结合相应的化学计量学算法,建立了汽油牌号识别模型及汽油RON预测模型。对基线校正后的光谱数据进行主成分分析建模后,汽油牌号的分类正确率仅为74.34%;对其进行求导处理后,样品分类的正确率明显提升,最高可达92.92%。
采用PLS-DA有监督的模式识别方法建立的汽油牌号模型,样品分类的正判率均在95%以上,对于区分92号、95号汽油的分类效果好。
采用偏最小二乘法建立汽油RON预测模型,其预测集相关系数为0.892 7,均方根误差为0.609 6,说明此模型预测值与汽油RON实际值具有较好的相关性,且偏差较小,此模型对汽油的RON具有较好的预测效果。
