改进的YOLOV3 算法在小目标检测中的研究与应用*
2021-11-18杨立功苏维均
杨立功,郑 颖,苏维均,王 强
(北京工商大学人工智能学院,北京 100048)
0 引言
随着人工智能技术的不断发展,目标检测技术在战场监视、侦察、毁伤状态评估和火控系统研究等军事领域的作用日益显著,它是现代高科技战争中赢得胜利的关键因素[1]。然而,对于坦克装甲目标而言,由于地面战场环境的复杂性以及相对较远的观测距离,利用传统图像目标检测算法在大视场内难以实现对坦克装甲小目标的检测识别和精准定位,而利用深度学习网络解决复杂背景下的小目标检测问题取得了较好效果。
自从深度神经网络算法首次在ImageNet 数据集上大放异彩,目标检测领域开始逐渐利用深度学习进行研究工作。2014 年,Girshick 等人[2]首次提出基于深度学习的区域卷积神经网络(R-CNN)算法,开创了目标检测算法的新时代,可仍存在重复计算的弊端,为了解决R-CNN 冗余计算的问题,He等人[3]与Girshick 等人[4]分别基于R-CNN 提出了空间金字塔池化网络(SPP)和加速区域卷积神经网络(Fast R-CNN)算法,使特征提取器、分类器和边界框回归器在内的整个网络,能通过多任务损失函数进行端到端的训练,这种结合了分类损失和定位损失的方法,很大程度上提升了模型准确度。但由于Fast R-CNN 使用Selective Search 来生成目标候选框,其速度依然达不到实时的要求,于是Ren 等人[5]在Fast R-CNN 的基础上增加了区域建议网络(RPN)和“锚”框,提出了Faster R-CNN 算法,检测速度得到了很大提升。虽然基于目标候选框的检测算法在检测准确率和定位精度上占有优势,但检测速度却很慢,使算法的效率不高,并不适用于本文所提出的小目标检测算法。在2016 年,Redmon 等人[6]提出了基于回归的YOLO 算法,又将目标检测领域带到了一个新高度,但模型泛化能力不强的问题仍然存在,Liu 等人[7]提出的SSD 算法解决了YOLO 候选框尺度单一的问题,使模型的检测精度有了较大提升,但也仅能与Faster R-CNN 算法相媲美,尤其在小目标检测中依然存在检测精度不足的问题。随着Redmon 等人对YOLO 算法的不断改进,在2016 年和2018 年还分别提出了YOLOV2[8]和YOLOV3[9]版本,检测精度和速度都有了更大提升,YOLOV3 算法在小目标检测中效果尤为显著。
上述提到的部分目标检测算法在VOC2007 数据集和COCO 数据集上的检测性能如表1 和表2所示[10]。

表1 目标检测算法在VOC2007 数据集上的测试性能

表2 目标检测算法在COCO 数据集上的测试性能
1 YOLOV3 模型
YOLOV3 模型网络框架主要由两部分组成,第1 部分为特征提取层,是前75 层网络,由1×1 和3×3 的卷积层与残差模块组成。第2 部分为特征交互层,是75 层~105 层网络,主要由大中小3 种尺寸的预测层组成。YOLOV3 借鉴了残差网络(residual network)的做法,在一些层之间添加了快捷链路,其具体结构如图1 所示。
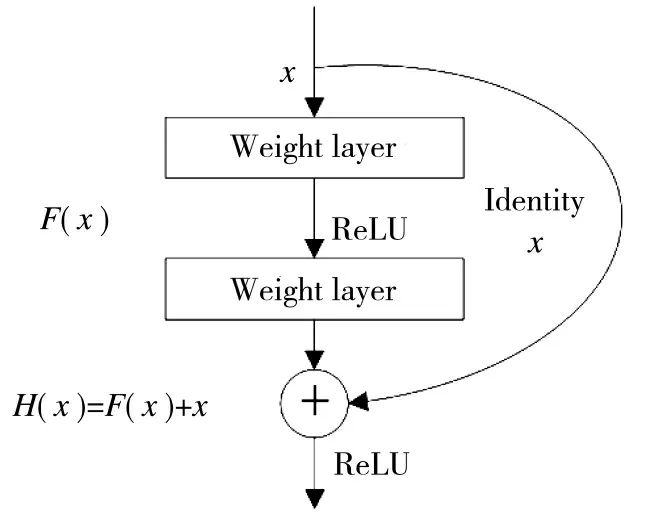
图1 残差组件结构
每一个残差组件由两层卷积层和一个快捷链路组成。其中,x 表示特征输入,经过两层卷积后,其生成的特征图与输入叠加,并将叠加后生成的特征图作为新的输入传递给下一层网络。YOLOV3 借鉴了Faster R-CNN 采用先验框(Anchor Boxes)的做法,在每个网格中预设一组不同大小的边框,覆盖整个图像的不同位置,这些先验框作为预定义的候选区在神经网络中检测其是否存在对象,并微调边框的位置。与Faster R-CNN 手动提取先验框不同,YOLOV3 采用K-means 聚类的方式提取先验框,提取效率大为提升。K-means 聚类方式计算边框之间的差异程度,如式(1)所示。
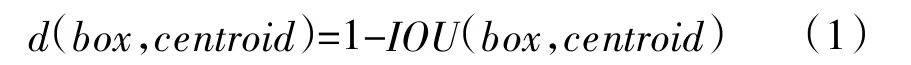
其中,d 为差异度,centroid 为聚类时被选作聚类中心的候选框,box 为其他候选框,IOU 为centroid 和box 两个目标框交集与并集的面积比值。IOU 的值越大,则边框差异度越小。
YOLOV3 的损失函数由预测框IOU 置信度误差、预测框先验框位置误差、预测框位置误差、预测框置信度误差和对象分类误差5 部分组成。

式(2)中的第1 项为预测框IOU 置信度误差,表示预测框内没有检测目标但IOU 值最大的情况下所出现的误差。在预测框中与目标真实边框IOU最大但小于阈值时,此系数为1,计入误差,否则为0,不计入误差。式(2)中第2 项为预测框与先验框的位置误差,1t<12800指此项只计算前12 800 次迭代的误差,如此设置能使模型在早期训练中更方便预测先验框位置。式(2)第3 项到第5 项指在预测框内存在检测目标时,计算预测框与目标真实边框的位置、置信度、分类误差。
2 基于多尺度特征增强的YOLOV3 模型
YOLOV3 自带的多尺度特征检测模块,采用上采样卷积加拼接的方式生成13*13、26*26、52*52 三种尺度的特征图并对其进行预测,但由于复杂地面战场环境中干扰信息多,特征信息不突出,YOLOV3中单纯使用多尺度特征检测无法很好地学习目标特征,以至于坦克装甲目标的重要位置信息不能被很好地检测出来。因此,本文采用基于PANet[11](Path Aggregation Network)网络中的多尺度特征增强方式,对YOLOV3 模型进行改进,使模型更加适用于复杂地面战场环境下小目标的检测识别。
2.1 基于PANet 的多尺度特征融合
PANet 的多尺度特征融合方法,是一种基于FPN(Feature Pyramid Network)特征金字塔的改进方法。图2 为FPN 金字塔融合方式[12],也是未经改进YOLOV3 模型的特征融合方式。采用高层特征图与底层特征图融合的自上而下的特征融合方式,在增加特征图多样性的同时,实现多尺度检测,增加模型检测识别精度。

图2 FPN 特征融合图
FPN 是自上而下,将高层的强分类特征信息向下传递,对整个特征金字塔进行增强,但是此过程仅仅增强了目标类型特征,对目标的位置特征没有传递。而PANet 如图3 所示,在FPN 自上而下的特征金字塔基础上,又添加一个特征信息传递方向为自下而上的特征金字塔,进一步增强特征多样性的同时,还对处于底层特征图的位置特征信息进行了传递,如图3(a)、图3(b)所示[11]。

图3 PANet 特征融合图
图3(a)、图3(b)是PANet 的第1 处改进,即自下而上的特征增强。图3(c)为PANet 的第2 处改进,为动态特征池化。图4 为图3 中(c)的详细展开图[11]。图中的4 个特征图分别进行全连接,然后采用取最大值或者加和的方式进行特征融合,该层特征池化层能够聚合多层特征图的特征信息,对提升模型检测和识别的精度更加有利。

图4 PANet 的动态特征池化图
2.2 引入PANet 多尺度特征增强结构的YOLOV3模型改进
未经改进的YOLOV3 模型中,采用上采样卷积加拼接方式,生成13*13、26*26、52*52 三种尺度的特征图,其预测的机制借鉴了FPN 的金字塔特征融合方式,本文采用PANet 改进FPN 的思想对YOLOV3 中的3 种尺度特征图融合方法进行改进,在模型中引入PANet 多尺度特征增强结构,使特征图能够综合更多特征信息,进而使YOLOV3 模型对于目标特征具有更强的敏感度,增强模型的检测识别精度。
YOLOV3 模型的网络结构中前75 层为特征提取层,该层形成13*13 特征图。对第79 层特征图上采样,再与第61 层特征图融合,形成26*26 特征图。对79 层特征图上采样,再与第36 层特征图融合,形成52*52 的特征图,随后将这3 种不同尺度的特征图带入后续网络进行检测识别。本文在未经改进YOLOV3 模型自上而下生成的3 种尺寸特征图的基础上,增加了3 个自下而上生成的特征图,并对两种特征图进行同尺寸融合处理。其具体结构内容如图5 所示。
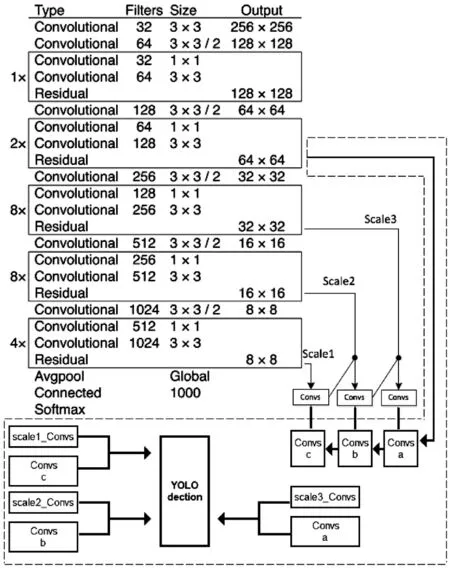
图5 多尺度特征增强结构图
图中被虚线框圈出的内容为多尺度特征增强结构的具体嵌入情况。图中scale3_Convs、scale2_Convs、scale1_Convs 分别代表未经改进YOLOV3 模型中3 种被用于检测的不同尺寸(52*52、26*26、13*13)特征图。取底层特征图经过下采样并与scale3_Convs 拼接,生成尺寸同样为52*52 的特征图Convs_a,对其进行下采样并与scale2_Convs 拼接,以此类推,生成尺寸为26*26 的特征图Convs_b和尺寸为13*13 的特征图Convs_c,最后采用全连接的方式对尺寸相同的特征图进行融合,生成3 个新的特征图用于检测识别。
增强多尺度特征融合结构代码主要加载到多尺度特征融合过程中,其具体的伪码如下所述。


上述伪码中x 为特征张量,将特征张量导入make_last_layers()函数,可以得出预测图张量y。其中,x1、x2、x3指未经改进YOLOV3 模型中的特征张量,全连接操作用参数不共享的1*1 卷积来实现。y1、y2、y3为生成的3 个预测图张量。y 的维度为a*a*3*(b+1+4),其中,a 为特征图尺寸,y1、y2、y3的特征图尺寸分别为13、26、52,3 代表产生3 个预测框,括号中的b 为待测目标类别数,占b 个维度,预测框置信度占1 个维度,预测框坐标x、y、w、h 占4 个维度。
3 实验结果与分析
3.1 数据集与数据预处理
本文所用训练和测试数据集为自行制作的坦克装甲目标数据集,其中坦克装甲目标数据总量为3 696 张图像,识别目标包括A、B、C、D 4 种类型坦克。具体图像示例如图6 所示。

图6 坦克图像数据集示例
上述数据集在代入网络进行训练时,训练数据与检验数据比例分别采取9∶1、8∶2、7∶3 三种,每种比例单独进行训练,生成的模型指标参数取三者均值。对于用于训练和检测的数据集来说,不仅需要单纯的图像数据,还需要监督信号(目标的位置和类别信息),因此,需要对数据进行预处理,采用可扩展标记语言对图像数据上待检测识别目标进行标注,结果如下页图7 所示。

图7 图像预处理
因YOLOV3 模型无法识别字符型的目标类别标签,且导入模型进行训练的图像需要提供目录信息以便模型导入,因此,在将数据导入YOLOV3 模型训练前需要进行两项工作:一是将字符类型的标签信息转化为数值类别的标签信息;二是将训练图像所在地址生成目录,方便模型导入。
将数据经过上述处理后,会生成一个TXT 文件,该文件即为图像目录文件。其中包含图像路径信息,图像中所含物体坐标信息以及目标类别信息。具体内容如图8 所示。

图8 图像信息转化结果
3.2 实验评估方法与实验环境
本实验采用了精度均值AP 和平均精度均值mAP 两个评价指标。因为本文研究的检测目标类型为4 类坦克,所以对各类平均精度分别计为:APA、APB、APC、APD。平均精度均值(mean Average Precision,mAP)是衡量模型在所有类别上的好坏程度,本文mAP 的计算就是取APA、APB、APC、APD的平均值。
实验环境具体设置如表3 所示。
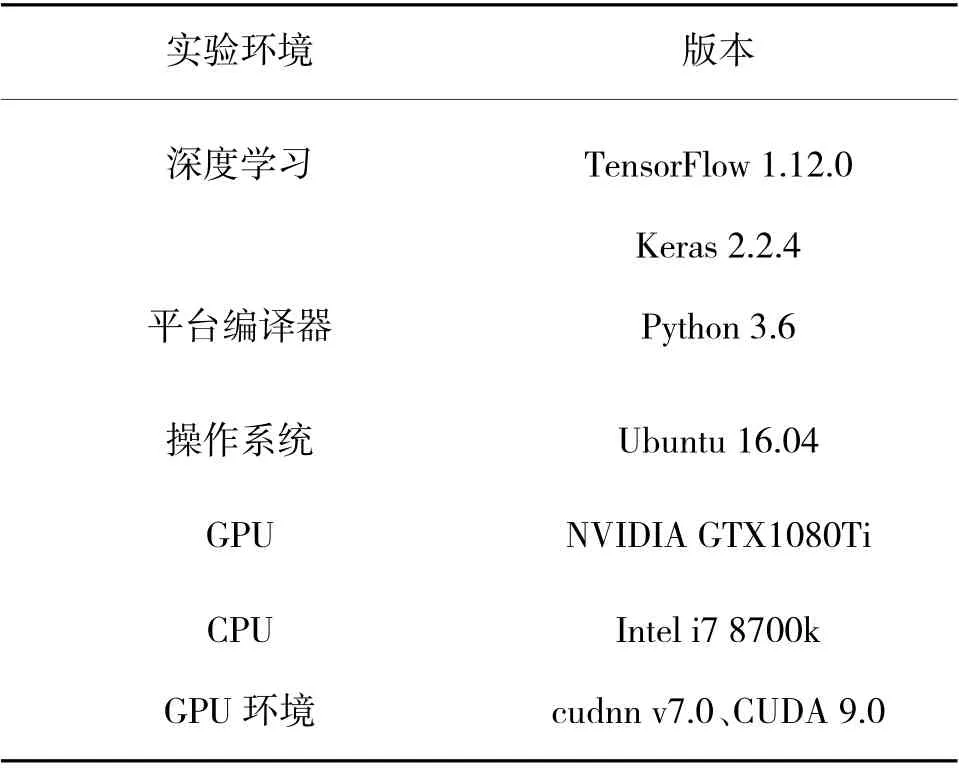
表3 实验环境设置
实验中的参数设置如表4 所示。
表4 训练参数设置
3.3 实验结果与分析
实验结果如表5 所示。

表5 改进前、后两种YOLOV3 模型的检测对比结果
对于引入多尺度增强结构的YOLOV3 模型,A类坦克、B 类坦克、D 类坦克的识别精度均有较大幅度上升,mAP 值从85.1%提高到了85.8%。这是由于引入的多尺度增强结构,在YOLOV3 模型原有高层特征向下层传递的基础上,增加了低层特征向高层传递的通道,增加了特征图多样性同时还增强了位置特征信息的传递。此外,多尺度增强结构还使用了全连接融合的方式,能够聚合更多层的特征信息。因此,在YOLOV3 模型中加入多尺度特征增强结构,能有效提高模型的检测识别精度。
改进前、后的YOLOV3 模型在训练坦克图像数据集过程中的Loss 值变化图像,如图9 所示。

图9 Loss 数值变化图

图10 坦克图像数据集待测目标检测识别效果图
4 结论
本文以复杂战场环境下的坦克装甲目标为研究对象,针对图像目标小、特征信息少、内容复杂等影响因素,引入多尺度特征增强结构的方法对YOLOV3 模型进行改进,以解决坦克装甲小目标的检测识别和精准定位的问题。实验结果表明:通过多尺度特征增强结构的方法,使YOLOV3 算法在坦克装甲目标数据集上取得了优异的检测效果,对于目标特征识别具有更高的灵敏性,mAP 值也有了较大幅度的提升。在今后军事领域的地面复杂战场中,应用该目标检测方法可以取得较好的效果。
