基于决策树算法的医疗大数据填补及分类仿真
2021-11-18岳根霞刘金花
岳根霞,刘金花,刘 峰
(山西医科大学汾阳学院,山西 汾阳 032200)
1 引言
医学界面临着海量、非结构化数据处理的严峻挑战,如何处理医疗海量数据成为研究热点。医疗大数据中涵盖了各类疾病的发病原因、发病历程、患病症状、治疗方案、实际案例等大量数据。由于医疗行业正在逐渐发展,医疗技术也在不断提高,因此治疗方案以及治疗结果产生的数据都不尽相同,而医疗大数据是按照时间顺序存储的,未经过整合处理的医疗大数据需要消耗大量的时间调取,为此提出医疗大数据的分类方法。医疗大数据分类方法的运行建立在数据完整的基础上,当医疗大数据不完整时极易出现数据分类偏差的情况,导致数据的分类结果混乱,失去了医疗大数据分类的意义。数据挖掘与处理的首要问题是数据缺失,数据集的完整是数据挖掘的成功与否的关键,通过填补缺失数据,得到一个完整的数据集。
在数据填补完成的基础上,利用数据分类方法处理大量混乱而复杂的医疗数据,可以提升数据的逻辑性,方便数据的查找。在数据分类计数发展历程中,使用范围较广的几个计数包括神经网络下的分类方法[1]和遗传算法下的分类方法[2]。在医疗大数据的分类过程中分别使用不同的技术可以针对不同的分类需求得到更加符合数据特点的分类结果,然而经过长时间的应用研究发现,现阶段使用的分类方法均存在迭代时间长的问题。为了解决上述问题,提出在决策树算法下的医疗大数据分类处理方法。这种算法通过构建决策树,利用已知各种情况的发生概率来求取净现值在有效范围内的期望值的概率,最后判断分类的可行性。决策树算法具有更高的分类精确度,因此将该技术应用到医疗数据的分类中,使其更好地服务于医疗大数据的处理,从患者数据中挖掘出有用的信息辅助医生为病人诊断。
2 初始医疗数据处理与大数据填补
医疗大数据填补与分类方法的设计目的是为了给医疗人员和医疗行业提供完整且准确的医疗数据,通过数据的分类可以实现指定数据的快速查找[3]。医疗大数据的填补与分类方法的实现,需要建立在大量的医疗数据的基础上,因此首先在医疗管理系统中挖掘需要的医疗数据,数据挖掘的具体流程如图1所示。
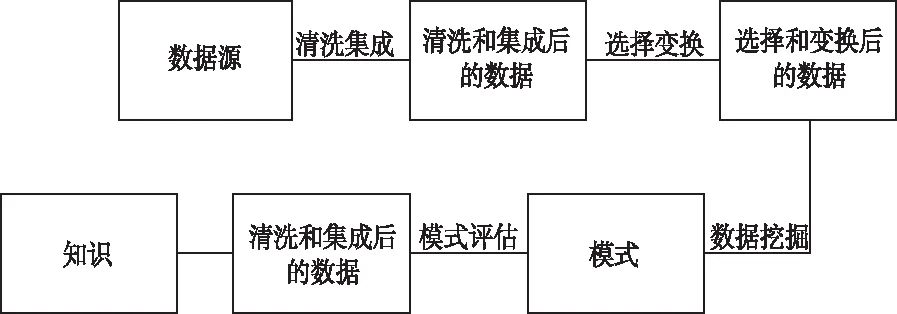
图1 数据挖掘流程图
图1的数据挖掘流程表明,数据挖掘的基本步骤是通过以下几个迭代组成的,其中包括数据的清理、数据集成、数据选择、数据变化、挖掘实现、模式评估以及知识表示。其中数据清洗的目的是过滤掉海量数据中的无效值和差异值,通过数据集成将不同来源、不同格式的数据整合,数据选择主要是按照数据的处理要求,选择数据挖掘范围与数据类型,知识表示是利用可视化技术将数据挖掘的结果显示到屏幕上[4]。另外数据挖掘的实现是在特定的挖掘算法和挖掘规则下进行的,在此次医疗大数据填补及分类方法设计中,为了保证分类结果的应用价值建立适用于医疗大数据的挖掘关联规则,选择适配度更强的数据挖掘方式。
2.1 建立关联规则
从海量的不完备医疗数据中检索满足最低支持度的项目数据集,定义初始海量医疗数据集为Dmis,定义任意一个项目数据集为Ijk[5]。项目数据集Ijk下搜索到的满足最低置信度要求的规则集表示为
Rj={Rj1,Rj2,…,Rjk,}
(1)
并记录相应的置信度C(Rj)。利用置信度建立关联规则,可以通过式(2)表示
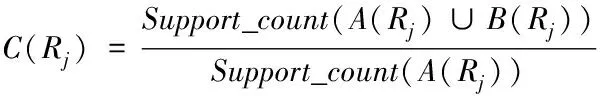
(2)
式(2)中A(Rj)和B(Rj)分别表示的是A和B两个数据包对应关联规则所包含的项目,变量Support_count(A(Rj))为海量数据项集中包含A的项数。那么假设T为医疗大数据的初始海量数据集,则可以得到关联规则的具体表达式为

(3)
式(3)中σai表示医疗大数据集的标准差,γmin为最小置信度[6]。上述三个变量的计算方法如式(4)所示

(4)
式(4)中ai表示大数据基本属性,aik为第k个数据属性值[7]。当ai在类xi中存在不同于其它类的行为,且具有统一行为时,将式(4)的变量求解结果代入到式(3)当中,便可以得出数据挖掘关联规则。
2.2 选择数据挖掘方式
在关联规则的约束下,选择符合医疗大数据的数据挖掘方式。现阶段数据挖掘算法包括Apriori和FP-Growth两种,通过两种关联规则算法来挖掘数据中药品和疾病、疾病和症状的相关对,进而得出医疗数据的挖掘结果。
2.2.1 Apriori算法挖掘数据
Apriori数据挖掘算法的应用原理是基于广度优先搜索的方式,也就是逐层扫描医疗大数据,通过层层迭代统计出各个候选项集的支持度与最小支持度,再根据建立的关联规则,找出符合要求的医疗挖掘数据[8]。一般来讲Apriori算法的实现分为两个阶段,首先生成待挖掘数据的频繁项集,并通过不断的循环迭代确定候选项集的统计数量,进而得出医疗数据挖掘的频繁项集[9]。接着在关联规则的约束下分别计算两个关联规则之间的支持度和置信度,并根据计算结果调整频繁项集。
2.2.2 FP-Growth算法挖掘数据
使用FP-Growth算法进行数据挖掘。
过程为:首先遍历海量医疗数据库,统计其中所有数据的频数,选择符合最小支持度计数的数据项,接着按照递减的顺序排列符合要求的数据项,得到频繁项列表,即为FList。以空节点为根节点创建FP-tree,按照得出的FList的顺序将数据插入到每一个节点上[10]。需要注意的是在数据对应的过程中,要保证FList中的数据项在FP-tree中有且仅有一次出现在节点上。设置数据挖掘的初始值为空,调用FP-Growth算法中搭建完成的FP-tree,便可以获得对应数据全部挖掘结果。
2.2.3 对比两种算法挖掘结果
Apriori算法和FP-Growth算法都可以在医疗大数据库中挖掘到满足要求的数据。然而Apriori算法需要多次扫描数据库,因此会花费大量的挖掘时间,导致算法的整体性能降低。而FP-Growth算法在挖掘大规模数据集时会出现无法构造FP-tree的情况,导致数据挖掘失败。为了解决两个传统算法存在的问题,以FP-Growth算法的运行原理为基础,采用Apriori算法来代替FP-tree的构建与迭代,实现数据挖掘算法的改进优化,同时也获取到整体性更强的医疗初始数据。
2.3 医疗大数据填补
对于一条记录中包含一个缺失值,可以按照单一缺失值的方式来处理,选择贡献度最大的缺失属性值作为医疗大数据的填补值。提取搭建完成的关联规则集,求出每一个缺失属性值di的贡献度,计算公式为

(5)
式(5)中参量Match(xi,Rjk)表示的是关联规则的匹配度。最后选择最大贡献度的di作为填补值[11]。
3 决策树算法处理医疗数据
决策树算法是典型的分类算法,在医疗大数据填补完成的基础上,构建决策树,并根据决策树思想采用自顶向下递归的方式处理医疗数据训练集。决策树算法的基本实现流程如图2所示。

图2 决策树算法基本实现步骤图
按照图2中的算法实现流程,以医疗数据填补处理结果为基础,由数据训练集及相关类标号生成可读规则和决策树。数据训练集在决策树的算法下,递归成多个较小的子集。由于医疗数据类型复杂且数据量较多,因此在此次数据分类的过程中建立多个决策树同步实现算法分类,在保证分类结果的同时提高算法的分类速度[12]。一般来讲构建决策树可以分为五个步骤,首先将医疗大数据的处理结果作为采集数据,并平均分为i个组别,形成数据集,用于建立决策树分类器。以数据记录作为决策树节点,分析变量的全部分割方式,确定其中的最优分割点。若确定的样本数据为同一类别,则该节点为决策树中的树叶节点,反之当前决策树的节点为最优分类能力的属性。计算属性增益率,并将最大增益率属性进行分裂处理。经过属性的分裂将单一节点分割成了两个节点,再按照上述步骤继续分裂和分割,当决策树的分裂过程满足停止条件时,则决策树停止分类。
3.1 递归创建单个决策树
由于此次医疗数据的分类项目需要处理和分类的数量较为庞大,因此在分类过程中首先建立多个单一的决策树,融合多个单一决策树的处理结果,便得出了决策树算法对医疗数据的处理结果。假设经过数据填补处理后得出的医疗数据结果中包含n个样本,且样本中的医疗数据分别属于x个不同的数据类别。定义属性F为测试属性,F具有v个不同的离散值,将E划分为v个子集,Ei中包括第j类样本的个数为Pij,则E的信息熵可以用式(6)来计算

(6)
以D为根节点的决策树信息增益可以表示为
gain(D)=I(E)-E(D)
(7)
式(7)中参量E(D)表示的是属性D对应的期望信息熵,其计算公式为

(8)
将式(6)、式(7)和式(8)联立求解,得出单个决策树信息的增益率函数为

(9)
并测试最大信息增益率的属性。
3.2 构建适应度函数
构建适应度函数的目的分为两个方面,一个是可以将创建的单个决策树与医疗大数据结合在一起,保证创建的决策树可以适用于处理医疗数据,另一个方面就是利用适应度函数来衡量决策树的分类性能,保证分类结果的精度。适应度函数的具体表达式如式(10)所示
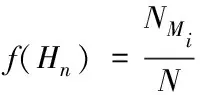
(10)
式(10)中变量N为测试医疗数据集上的用例总数,NMi和Mi分别表示的决策树正确分类测试用例的总数和正确分类数量与总分类数量的比值。
3.3 ID3/C4.5算法合并多个决策树
在适应度函数的控制约束下,分别利用ID3和C4.5的交叉变异运算合并多个决策树。ID3算法通过一系列测试将数据训练集迭代划分为多个子集,并尽量使每个子集中为同一类别的对象。而C4.5算法在ID3的基础上使连续型属性、属性值空缺的处理更加完善,同时也对单一决策树进行剪枝处理,实现信息量的分割,总而得到医疗数据的分类结果。融合ID3算法与C4.5算法,并使用交叉变异的运算方法将创建的多个单一决策树合并在一起,保证多个决策树可以协同运行。最终合并决策树在医疗大数据的分类处理中的应用运行原理如图3所示。

图3 决策树工作原理图
运用决策树算法及其工作原理,遵循医疗大数据的分类方法与关联规范,实现数据的合理分类。
4 仿真研究
为了验证基于决策树算法的医疗大数据填补及分类方法的性能,并比较决策树算法在医疗大数据处理方面的应用效果,将算法应用到一个医疗实例中,构造一个基于大数据的医疗决策模型,并对其进行分析。
4.1 配置仿真环境
在开始实验之前首先搭建并配置仿真环境,为了给设计的填补与分类方法提供充足的医疗数据,选择医疗大数据平台作为仿真环境,将基于决策树算法的医疗大数据填补及分类方法对应的程序代码输入到仿真环境的主控计算机中,并与医疗大数据平台形成后台链路,保证大数据平台采集到的数据可以实时传输到医疗决策模型当中。此外,为了验证决策树算法在处理医疗大数据的有效性,设置神经网络算法作为仿真的对比方法,以相对独立的方式在相同的实验环境下运行,以保证实验结果的真实性。
4.2 准备医疗案例实验数据
选择医疗大数据平台中的脑卒中相关案例作为仿真数据。从数据平台中提取相关诊治完整数据共计5000条记录。其中案例初始数据包括性别,现病史,既往史,入院查体,辅助检查,入院诊断,治疗用药等属性。每一个案例对应的数据量约为49MB,其中部分案例存在数据缺失的状况。
4.3 实验指标
1)医疗大数据的填补效果
在医疗大数据的处理过程中,为了保证处理效果的完整性和连续性,必须对全部数据进行缺失填补,实验选择对基于神经网络算法和基于决策树算法的医疗大数据填补效果进行对比分析。以填补后的容量大小与案例原始容量大小做对比,分析其填补效果差异。
2)医疗大数据的分类效果
医疗大数据的填补是为了更有效的进行分类,分类方法的精准度也是医疗大数据处理的一个重要的指标,分析分类精准度以判断分类方法的合理性,其计算公式为

(11)
式(11)中VA表示经过分类处理的类别频数。V0表示未经处理的类别数量。
4.4 实验结果分析
4.4.1 医疗大数据填补效果对比
通过对案例数据进行填补处理,不同方法下其填补率对比如表1所示。

表1 填补效果对比/MB
初始测试样本的初始数据量为190MB。经过基于神经网络算法和决策树的医疗大数据填补及分类方法的填补,样本数据量填补至217MB、221MB和244MB,即填补量分别为14%、16%和28%,本文方法将缺失数据全部补充完整,比另两种方法提高了50%左右。
4.4.2 医疗大数据分类精度对比
将原始数据使用三种方法进行重新分类,得出分类精度,三种分类精度对比情况如图4。传统数据处理方法的平均分类精度为83.92%、80.52%,而设计方法的平均分类精度为95.32%,相比之下提高了11.40%、14.80%,本文方法的分类精度最高。
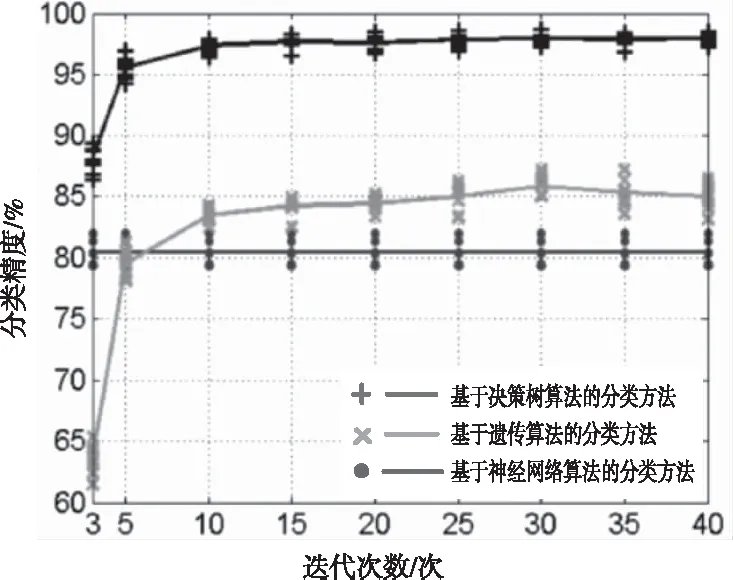
图4 三种分类精度对比图
5 结束语
通过本文的设计方法,可以从医院现有的病人数据中挖掘出有用的信息辅助医生为病人诊断。综合来看,提出的决策树算法在处理医疗大数据中具有较好的填补效果,可根据不同的数据选择不同设置来提高填补正确率,在数据的分类方面也具有较高的应用性能。
