物联网数据接入最优分流算法设计与仿真
2021-11-18杨军
杨 军
(重庆师范大学涉外商贸学院,重庆 401520)
1 引言
互联网的快速发展推动了物联网的广泛应用。物联网是通过信息传感设施将实物和互联网联系在一起的,起到对实物进行识别、定位以及监督的作用。物联网的感知层作为数据接入的重要层级,由于数据量较大,在接入时容易出现标签信息错乱现象,而数据分流则是处理该问题的主要方法,并且其在情报搜索、故障检测等领域均体现出重要价值。现阶段的数据分流方法存在特征识别准确性低、分流效率差等缺陷。因此需要设计出最优的数据分流算法减少网络数据接入的负担。
相关研究人员做出如下解决方案:文献[1]为解决快速增长的数据流量而导致网络拥塞问题,提出基于自私性与中心性相结合的数据分流算法。将网络数据直接传送到种子节点,该节点根据移动发生的接触,将数据传送到其它节点,此时如果有节点在一定时间段内仍没有接收到数据,则该节点可以直接在网络中对此数据进行下载;再结合节点的自私性,挑选出尽可能包含更多数据的种子节点,通过这些种子节点协助数据分流过程。
文献[2]在混合式网络拥塞控制路由算法的基础上实现数据分流。首先构建网络拓扑关系模型,收集一定范围内的数据流量;其次对节点的负载状态进行评估,选取最优父节点,当出现网络拥塞现象时,将该消息广播给子节点或相邻节点,并判断告知节点的数据接收速度和传输速度;最后在混合式网络拥塞缓解方法的基础上,将节点的平均吞吐量进行比较,对当前数据传输通道进行子节点更换,实现数据的分流。
以上描述的两种方法,在一定程度上达到了数据分流的目的,但是,二者并没有对数据特征进行准确提取,导致网络拥塞率较高、网络平稳运行时间较短、最大上传带宽较低。因此,文本通过K均值聚类[3]的方式对物联网数据接入的最优分流算法进行设计与仿真。采用K均值计算的方法对数据进行特征提取,在提取过程中不断调节数据的聚类核心,以达到准确分流的目的。仿真表明,该方法与其它方法相比分流结果最优,可以有效缓解网络拥塞问题,提高了最大上传带宽,延长了网络平稳运行时间。
2 物联网数据接入分流基本原理
2.1 “流”的局部性定义
目前对“流”的定义为将具有同样目的地址的全部分组称为“流”。所以分流就是把存在相同目的的分组分成不同的流。
在现阶段的网络中,例如WEB界面和FTP文件等,被划分成单个数据后再进行传输,而这些数据存在相同的地址。按照“流”的定义,此数据包均属于相同的流。FTP文件的第一个数据包传输成功后,在一定时间内,相同流中的其它数据包传输成功的可能性较大。该现象被称为流的局部性特征[4],原理图如图1所示。

图1 流的局部性原理示意图
2.2 数据接入分流的约束条件
将物联网数据样本集合描述为{xi,yi},i=1,2…,n,表示节点;xi∈Rd,yi∈{1.-1}作为数据接入分流的标志,则分流的线性判断公式表示为
f(x)=w·x+b
(1)
式中,w表示数据大小;x表示节点通道,b表示最低嵌入维数。再将物联网接入数据分流做归一化处理[5],可以获得下述表达式
w·x+b=±1
(2)
将分流问题转化为具有约束特征的非线性问题进行描述
yi(w·xi)+b≥0
(3)
针对以上公式做计算,能够获取数据分流的对偶函数表达式为
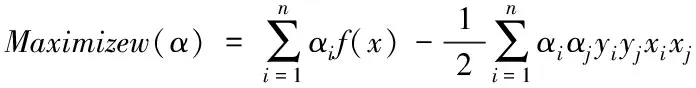
(4)
式中,α表示节点j的约束条件。则式(4)的约束特性可以表示为

(5)
利用对偶函数将支持向量机引入到非线性的数据分流中。此时,必须利用核函数在高维空间里变成具有约束性质的二次函数,其过程描述为
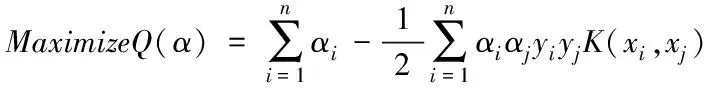
(6)
2.3 分流过程中的能量消耗模型
因为本文的传感器节点全部符合欧式空间的坐标关系,所以节点的分布情况满足欧式空间中的几何分布特征。假如传感器呈矩形分布,面积表示为L1×L2,并且该区域中节点分布的密度表示为μ,对于任何传感器来说,身份地址都没有重复现象,节点在原始时间点的能量表示为E0。另外,R表示传感器节点的最大半径,假设节点i在半径范围内的节点是S1(R),则下一个节点半径范围中节点表示为S2(R),因此,针对节点i来说,具有下述关系

(7)

(8)
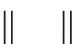
针对物联网中任何一个节点i,它的影响范围可能会出现和节点j的影响范围发生互相影响的现象,因此互相影响的重叠部分系数ω可以表示为

(9)
式中,Li代表节点i的最大可能覆盖区域。
假设节点i和j可以相互影响,则这两个节点的射频范围互相关因子γ(i,j)必须符合下述条件

(10)
如果节点i的附近具有n个相互关联的节点时,通过式(10)可知,节点i和这些关联节点的射频范围互相关因子γ(i)符合如下要求
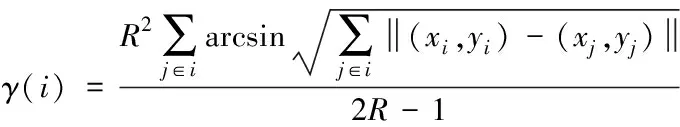
(11)
根据式(11)可以看出,γ(i)的取值越大,节点i对关联节点的影响尺度就越高,如果节点i失效,则数据接入中断,使网络发生传输抖动情况。
因为传感器节点利用信号的收发达到数据的汇集与路径控制目的,所以i节点在B带宽情况下,根据数据接入分流的约束条件,将数据接入到j节点时,此时分流过程中能量消耗模型的表达式为
Esend(i)=Bl+P0l3
(12)
Erev(j)=BP0l2
(13)
式中,P0为现阶段节点发射功率。因为耗能情况和l存在正相关关系,并且l又为节点i、j在欧式空间中最小距离,所以对上述能量消耗模型进行优化,可以避免物联网数据在接入分流时出现传输受阻的状况。
3 基于K均值聚类算法的物联网数据分流算法设计
3.1 物联网数据特征提取
完成能量消耗模型的优化后,在空间重构基础上对物联网做非线性映射处理[7],获取数据时间序列在分流操作中的信息模型。根据指标数据映射获取非线性数据的高维映射向量,建立数据聚类查找的目标函数,并对该函数进行求解计算获取极值,同时得到物联网数据的时延特征,实现数据特征提取。
假设{xn}表示单变量的物联网数据时间序列,根据采样结果可以得出,采样数据的时间序列{xn}的长度是N。样本数据在采样时间范围中称为标量序列,如果X与Y表示数据分流系统中的聚类特点,利用空间重构实现数据的非线性处理,得到最优时延τ与最低嵌入维数b。假设ε为平均数据特点的尺度,xn为数据时间序列的信息模型,在2-λ<ε(λ>0)时,xn可以表示为

(14)
式中,t0表示数据采样的原始时间点,Δt为采样的间隔时间段,h[z(t0+Δt)]为任意数据样本在序列中具有的相似性特征度,ωn表示相关性系数。利用指标数据映射方式取得非线性数据在分流时的模型{x(t0+iΔt)}。模型中,i=0,1,…,N-1,如果利用Xg表示高维映射向量,其表达式可以描述为
Xg=[si,…,sk]n=(xn,xn-1…xn-(b-1)τ)
(15)
式(15)中,si表示映射向量的分量,k为时间序列在分流过程中的相关系数。通过映射向量Xg建立目标查找函数,假设R表示物联网数据特征矢量在分流过程中的关联函数,xa为交叉分布模型[8],其可以描述为
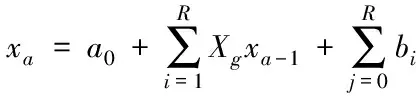
(16)
式(16)中,a0为原始采样幅值,xa-1表示物联网数据方差与均值相等的标量序列,bi描述最优分裂属性。在此基础上利用C均值聚类方法对目标函数进行计算,假设μik表示聚类目标函数的最大值,其计算表达式为

(17)
根据目标函数的最大值,获取数据时延特征ςi,从而完成物联网数据的特征提取,其表达式为
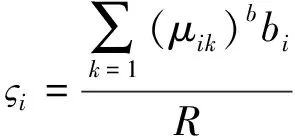
(18)
3.2 物联网数据接入最优分流算法的实现
K均值聚类方法作为有效处理数据分流的方式,能够准确的对物联网环境下的数据进行分流。通过上述对数据特征的精准划分,按照自身特性分成不同种类,实现海量数据的高效分流。
使用该方法实现数据分流,首先必须获得数据的原始聚类中心,并在分流过程中更新该中心内容,以便适应物联网环境下的数据高度动态变化特征。详细分流步骤如下所示:
假设物联网环境下数据特性组成的聚类中心用l进行表示,特征数量为p,在这些特征中挑选l个特点当做初始聚类核心,任何一个聚类核心均表示一类数据。经过计算可以获得其它p-l个数据特点离原始聚类核心的目标距离,并且把这些数据特点分布到相邻的聚类核心中,从而实现所有数据特点的匹配。
通过以下供述可以将数据特性区分为L个不同种类

(19)
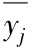
按照上述方式,可以将物联网数据特性区分成L个形式,Tj(j=1,2,…,l),聚类核心Dj可以表示数据特性组成的集合Tj,该集合可以利用T={Y}代表。假设,现有两个数据特性Y与Z,因此它们之际存在的欧式距离表示为e(Y,Z)。
根据迭代处理,对物联网数据接入进行准确分流,详细分流步骤如下所示:
步骤一:假设物联网下数据原始聚类中心表示为TDq={Dj},对数据做聚类处理,将其分成l个聚类中心,则计算过程必须符合下述要求
Tk{Y|e(Y,Dk)≤e(Y,Dj),j≠k}
(20)
步骤二:针对数据特征做迭代处理[10],从而得到新的特征集合TDq+1;
步骤三:如果q=0,则聚类中心是TD0;
步骤四:通过计算得到数据分流时的误差方差,假设该方差足够小,则分流停止,此时能够得到最优的分流结果;反之,q+1->q,此时回到步骤二,重新进行数据分流。
通过上述描述的算法,利用物联网数据的特性,构建集合,采用K均值聚类方法对其进行聚类处理,在持续的迭代过程中确保聚类中心不断更换,可以较好的适应物联网环境下数据动态特性,获取最优的分流函数
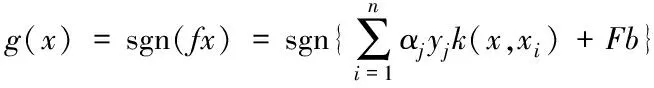
(21)
4 实验结果与分析
为证明本文所提物联网数据接入分流算法的可行性进行一次仿真。由于传感器的路径属于无线信道路径,并且必须利用簇头节点才可以实现数据接入,在簇头节点不能实现数据的直接传输时,还需利用其它节点才能完成数据接入。图2为物联网数据传输平台。

图2 物联网数据传输平台
实验在NS2仿真环境下,通过物联网数据传输平台,对本文分流算法与文献[1]算法和文献[2]算法分别进行对比实验。仿真参数如表1所示。

表1 实验参数设置表
4.1 网络拥塞率
为了验证本文算法的有效性,对本文算法、文献[1]算法和文献[2]算法出现的网络拥塞率进行对比分析,对比结果如图3所示。

图3 不同算法的网络拥塞率对比图
通过对比图能够看出,随着实验时间的不断流逝,三种算法都会出现一定波动,本文算法的网络拥塞率一直处于较低水平,并且网络拥塞率自始至终低于文献算法。这是因为所提算法的分流机制将一定范围内的接入数据划分成最优的结果后,再进行数据传输,一定程度上减少了拥塞现象。
4.2 网络平稳运行时间
下图描述的是本文算法、文献[1]算法和文献[2]算法的网络平稳运行时间的对比结果。

图4 不同算法的网络平稳运行时间对比图
通过图4能够看出,本文算法的网络平稳运行时间比文献[1]算法和文献[2]算法的网络平稳运行时间长。是因为本文算法对能量消耗模型进行了优化,可以避免物联网数据在接入分流时出现传输受阻的状况,从而延长网络平稳运行时间。
4.3 最大上传带宽
为了进一步验证本文算法的有效性,对本文算法、文献[1]算法和文献[2]算法的最大上传带宽进行对比分析,对比结果如图5所示。
根据图5显示结果可以总结出,随着数据传输量的不断增加,本文算法的最大上传带宽比文献[1]算法和文献[2]算法的最大上传带宽多。
5 结论
针对数据接入时会产生的死链现象,本文提出一种物联网数据接入最优分流算法。通过对物联网数据的特征提取与准确分类,在K均值聚类的基础上,利用迭代算法对数据做聚类处理,计算数据分流的误差方差,在得到最小方差时,获取数据分流的最优结果。最后分别在网络拥塞情况、平稳运行时间以及最大带宽方面进行实验对比分析,结果表明所提算法具有优越性,可以改善网络死链现象,具有较好的实践意义。
