神经网络技术下多尺度时序数据离群点挖掘
2021-11-18罗晓媛赵丽艳
罗晓媛,赵丽艳,刘 君,邹 栋
(1. 黑河学院理学院,黑龙江 黑河 164300;2. 哈尔滨理工大学,黑龙江 哈尔滨 150000)
1 引言
在实际的学习过程中,不同的学习者在学习水平和学习效果上存在着差异。一部分学习者对网络学习表现出较高的热情和参与度,能够取得较好的学习效果;另一部分学习者缺乏参与深度学习的积极性,甚至偏离了学习的目标。这一分化现象十分突出,在一定程度上影响了网络教学的整体质量和效果。近几年来,在线教育数据呈现出爆炸式的增长,数据挖掘技术在教育领域的应用越来越受到重视,数据采集器能为学生提供建议,为教师提供反馈,预测学生的表现,发现不良行为,将学生分组,编制课程,计划和进度,数据分析和可视化等。
当前已有较多学者开展了关于时序数据挖掘的研究,赵晓永, 王宁宁, 王磊研究了基于主动学习的离群点集成挖掘方法[1],该方法主要根据各种基学习器的对比分析, 从标注的数据集和各基学习器投票产生的数据集中抽样, 得出最终的挖掘结果;张琳, 李小平, 来林静,等人研究了基于游戏教学的分层数据挖掘方法[2],该方法提出了游戏教学的数据框架, 构建了分层数据挖掘模型,以对数据进行了挖掘。但是存在的离群点挖掘准确度低的问题。
人工神经网络是基于一组被称为人工神经元的连接单元或节点,不同的细胞层可对其输入进行不同类型的转换,已广泛应用于计算机视觉、语音识别、社交网络过滤领域中。为此设计一个神经网络技术下多尺度时序数据离群点挖掘方法。
2 神经网络技术下多尺度时序数据离群点挖掘方法设计
此次研究的神经网络技术下多尺度时序数据离群点挖掘方法在教育应用中的流程如图1所示。

图1 神经网络技术下多尺度时序数据离群点挖掘流程
如上图所示为此次研究方法的离群点数据挖掘流程,首先确定分析对象[3],然后明确分析目的,主要对翻转课堂教学活动进行评价。现实教育教学环境中,涉及的教育教学数据量大、种类复杂,并随时间推移不断地动态生成。在以教育因素为研究对象的异常检测中,需要考虑异常的范围和数量等重要因素,以下为具体处理过程。
2.1 时序数据聚类处理
在检测对象确定之后,将被检测对象的数据聚类,以去除相对相似的数据。对象属于聚类的程度, 可以通过对象与聚类中心之间的相似度进行测量,与平均相似度进行比较,若较小,则表示数据点属于离群状态,收集该部分离群点,统一构成异常点集合,基于聚类算法的流程图如图2所示。
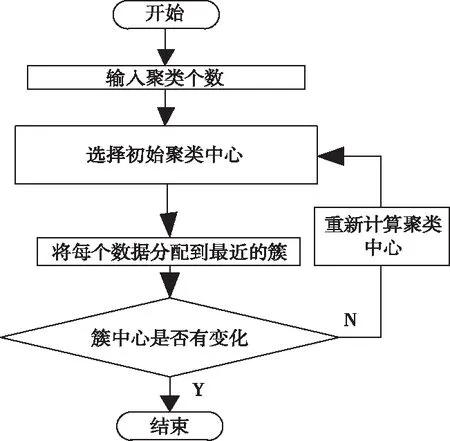
图2 聚类流程
假设Aj是教学评价数据中的一个属性[4],x、y分别是Aj的两个取值,Ai代表数据集中的另一个属性,m代表Ai范围中的一个子集。~w是w的补集,Pi(w∣x)代表属性Aj取值为x时,Ai取值属于w集合的条件概率。将Aj属性下两个取值x、y相对于属性Ai的距离表示为
δij(x,y)=Pi(w∣x)+Pi(~w∣y)
(1)
在此基础上,对两个属性值的距离进行度量,通过其度量能够为判断数据对象之间相似度提供基础依据。假设数据集的属性个数为m,对于数据集中任意 属性的两个取值x、y之间的距离[5]表示为
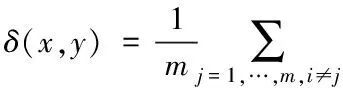
(2)
在计算过程中,每个属性在计算两个对象之间的距离时,权重都是相等的。
基于上述计算获得数据可达距离,在此基础上对局部可达密度进行计算,计算公式如下所示

(3)
式(3)中,Nk(q)代表距离数据点q最近的数据点的集合,q代表离群点,lrd代表局部可达密度[6]。
通过上述计算能够将评价数据区别与同一属性下不同属性的差异。依据上述聚类处理[7]过程,能够确定比较对象,针对教育平台数据集中所有对象进行比较,可以将不同的数据对象划分到相应的子类中,从而确定检测对象的邻域,将邻域范围内的对象作为比较的对象,为时序数据离群点挖掘提供基础。
2.2 基于神经网络技术的时序数据离群点挖掘实现
在上述检测对象邻域确定完成的基础上,对离群点挖掘,由于它的规模很小,范围很广,在分析时非常容易将异常值视为错误或无效数据,也会影响研究对象的总体准确度,引起误解,增加分析难度。为此采用神经网络技术对时序数据离群点挖掘[8]。神经元模型如图3所示。

图3 神经元模型
神经元模型如图3所示[9],通过上图可以发现神经元模型的组成主要包括输入以及输出值、权值以及输出函数,不同组成部分之间的基本关系如下式所示
y=f(wx+θ)
(4)
式(4)中,y代表输出值,f代表传输函数,θ代表偏置,w代表权值,x代表输入值。
基于神经网络的离群点挖掘流程如下所示:
第一步:初始化BP神经网络,对各层的权值和偏差进行随机初始化,输入层的神经元个数由数据集中数据属性个数决定。通过上述过程已经获得检测对象的邻域范围,假设邻域范围内数据集中有m个属性,则将输入层的神经元个数设置为m;
第二步,通过给定训练集,获取输入以及输出向量,分别设定为向量x和向量y;
第三步,明确节点数量[10],对节点数量进行隐藏以及输出处理;
第四步,依据给定数据转发输出数据,获取神经网络实际输出值。
第五步,对输出值进行处理,该值可以对数据集中分布情况进行充分反映,根据神经网络输出值,异常数据可以通过熵值结果加以判定,熵值表示样本在某种范畴内的不确定性。熵[11]越大,样本的不确定度也就越高,样本更可能出现异常。提出当熵值超过某一阈值时,样本即为异常点。当阈值较小时,设置一个阈值为E,其范围为0-1之间。
由此,给出评价函数E,其与得到的两种类别样例个数相关,即:
E=E(aPr,bPw)
(5)
式(5)中,a、b分别代表权值,P代表分类为正确的样例,Pw代表分类为错误的样例,E表示用某一阈值来做异常点判断的有效性。
E值的大小与异常点碗蕨的效果好坏优密切关联,该值越大,挖掘效果越好,反之,挖掘效果越差。
E值的大小与分类正确的样例个数成反比,即分类错误的样例个数与E值成正比。所以给出的评价函数E的公式如下:
E=-aPr+bPw
(6)
为提高挖掘准确性,采用下述公式减小E误差,其表达式为:

(7)
式(7)中,η代表系数,该系数为神经网络训练过程中学习的速度,即学习率。
并假设fr(φ)代表数据集中分类正确的样例的密度函数,fw(φ)为数据集中分类错误的样例的密度函数,如图4所示。
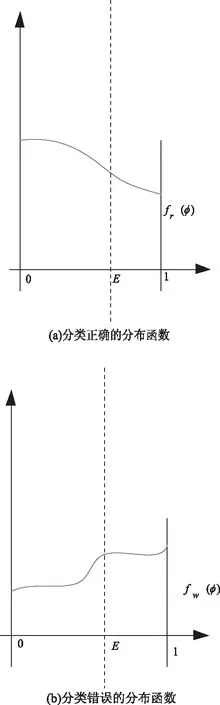
图4 分类正确与分类错误数据的分布函数
这样就有如下表示
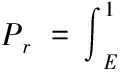
(8)
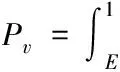
(9)
从而得到
P(E)=-aPr+bPw
(10)
综上所述,通过P(E)对异常点挖掘的效率进行判断,该值的大小与挖掘效率呈现正比,该值越大,证明挖掘效率越高,反之,挖掘效果越差[12]。所以P(E)取极大值时,熵的取值最佳。
第六步,根据神经网络的实际输出与期望输出,对网络的输出误差进行计算,判断网络的停止条件。若符合,则停止训练并退出神经网络对离群点评价,若不符合,则返回步骤二。
第七步,离群点评价,对检测出得离群点进行评价,弄清数据离群的原因。
异常值经过识别和验证后,需要对异常值进行后处理,才能准确为教育决策服务。第一,从技术角度分析了离群值的成因;若因技术原因或人为输入错误,则需剔除这类异常数据,以减少后期处理难度,提高数据的准确性。第二,主观臆断的影响消除技术误差因素,采用适当的智能挖掘算法对异常点进行挖掘,建立分析模型,确定适当的异常范围,以减少异常点的主观性,降低异常点相关性带来的误差影响。第三,将异常现象的分析结果以直观的形式呈现出来,以便能够结合具体的教育教学情况,详细分析异常现象产生的原因,有针对性地提出相应的措施和方案,使离群点检测算法发挥更大的实用价值。
不断迭代上述基于神经网络的计算过程,直至所有的离群点挖掘完毕,才停止此次设计的算法,以此通过上述过程完成基于神经网络技术下多尺度时序数据离群点挖掘。
3 实验
此次实验的硬件环境如下:Intel 处理器 2.40GHz,6GB 内存。所用的实验数据来自于翻转课堂教学数据库。由于原始数据量较多,为节省实验时间,随机抽取一定的实验数据,抽取规则如下所示:对样本数量较少的类别,抽取全部样本;对样本数量大的类别,随机抽取10%样本;对样本数量大的类别,抽取1%样本。根据上述抽取规则,得到样本数据集总数为7000条,共有7项数据。

表1 实验环境
在上述实验数据准备完成的基础上,从准确性和效率两个方面,分析此次设计的神经网络技术下多尺度时序数据离群点挖掘方法的性能,并为了保证实验严谨性,将文献[1]中基于主动学习的离群点集成挖掘方法与文献[2]中基于游戏教学的分层数据挖掘方法与此次研究的方法对比。
3.1 准确性对比分析
采用此次研究的挖掘方法与传统两种挖掘方法对实验数据的离散群点数据发掘,对比两种挖掘方法的挖掘准确性,对比结果如图5所示。
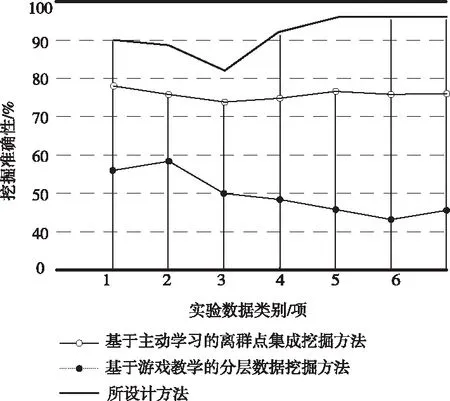
图5 挖掘准确性对比
由上述对比结果能够看出,由此次提出的挖掘算法能够准确检测出离群点,较传统两种检测算法检测准确性高。
3.2 挖掘效率对比分析
传统的基于主动学习的离群点集成挖掘方法、基于游戏教学的分层数据挖掘方法与此次研究方法的挖掘效率对比结果如图6所示。
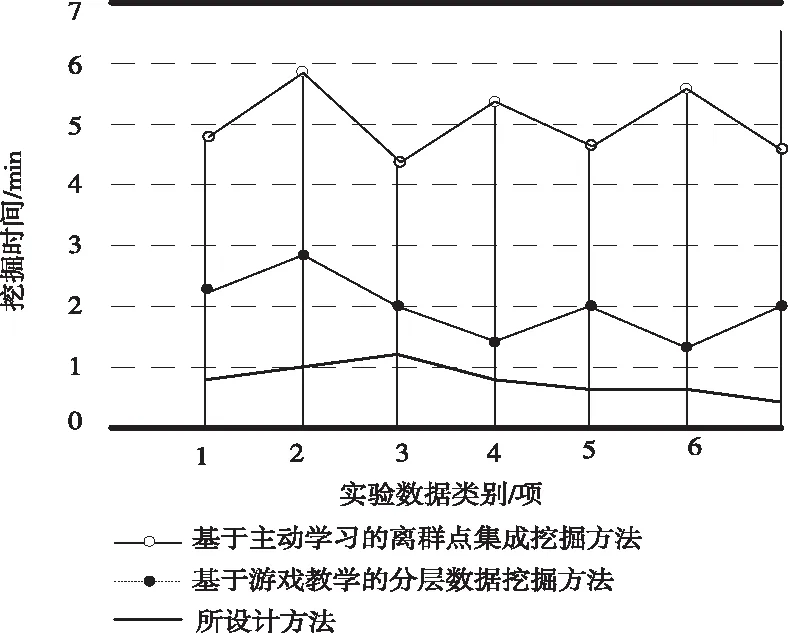
图6 挖掘效率对比
通过上图能够看出,三个方法中,执行时间最短的是此次研究的算法,基于主动学习的离群点集成挖掘方法执行时间最长,由此能够证明此次研究的方法的有效性。
综上所述,此次研究的神经网络技术下多尺度时序数据离群点挖掘方法较传统方法的挖掘准确性高,挖掘效率高。原因是,此次研究的挖掘方法能够预先对评价数据进行聚类,有利用了神经网络技术对候选离群项集进行了检测,得到最后的离群点,从而提高了离群点挖掘算法的有效性。
4 结束语
针对高校教学平台的需求,设计了基于神经网络技术的离群点挖掘算法,对多尺度时间序列数据进行离群点挖掘,并进行了实验验证。利用该方法,可以对教学评价数据进行基于现实的挖掘,将已有的管理数据转化为可利用的知识,从而使教师更好地开展教学活动。
接下来,将所提出的算法应用到某教学平台的所有教学评估数据中,探讨教学评估数据中的全局异常值、情景异常值和集体异常值,并结合其它数据对异常值进行解释,从而为学校的教学工作提供参考。
