基于Transformer的信用卡违约预测模型研究
2021-11-17姚汝婧
杨 磊,姚汝婧
(天津大学应用数学中心,天津 300072)
1 引言
随着经济和科技的进步,信用卡业务因其方便、利润高等特点在金融行业飞速发展,广泛受到金融机构以及用户们的喜爱。但是随着信用卡用户量的急剧提升,我国信用卡违约问题更加突出,2018年信用卡逾期总额也呈现爆发性增长,总额为2010年的10倍。若不及时采取相应措施加以控制,会给银行等金融机构造成严重损失。因此,对持有信用卡的用户的信用进行评分,提前预测出违约用户是十分有必要的,对银行等金融机构的长久发展具有重大意义。
目前对违约用户进行判定的方法大致分为三种:基于规则的方法、基于有监督学习的方法、基于无监督学习的方法。
基于规则的方法简单有效,可解释性强,但存在以下两点缺陷:一是太过依赖人的经验来判断,很容易出现由于人为错误而对用户是否违约误判的情况,二规则构建成本高,需要针对性的构造。
基于有监督的学习是目前国内外广泛使用的信用违约预测方法。王洪各[1]采用逻辑回归(Logistic Regression)进行信用卡欺诈检测,精度达到95%以上。张国庆[2]等人采用LightGBM模型研究信用卡违约,通过与逻辑回归、随机森林等几个常用模型的对比,表明LightGBM的预测效果较好。在国外,Florentin Butaru等人[3]通过对比逻辑回归、决策树和随机森林三种方法,得出不同的银行适用于不同的模型的结论。真实业务场景中标签数据获取难度大,且违约数据比例远小于正常数据导致样本数据极不均衡,导致有监督学习无法取得良好效果。
近年来,无监督学习因其无需含有带标签的数据训练模型等优势,逐步发展起来成为信用卡违约预测研究热点。例如陈栋栋[4]采用主成分分析法对信用卡客户进行风险预警。辜俊莹等人[5]采用K-means聚类算法建立模型对银行客户进行分类。但是无监督的方法由于缺乏人类先验经验的引导,模型的判别效果往往与人类预期相悖,难以实际应用。
与之前对于信用卡违约行为研究最大的不同是主要体现在以下两个方面:
1)本文采用无监督和有监督学习相结合的方法来解决之前研究方法的不足。利用自编码的方式进行无监督的学习,训练编码器,实现对大量无标签的数据去噪编码,避免了海量数据的标注,充分挖掘和建模用户数据的深层信息。接着将自编码得到的用户数据的高层表示送入到传统的分类算法中进行有监督的学习,充分发挥有监督训练的优势。
2)创新性引入自然语言处理(NLP)中具有强大的表征能力的Transformer作为用户数据的自编码器。信用卡用户数据是用户在较长一段时间内的行为数据,为时序序列。因此需要模型具有对长期记忆的建模能力,这与NLP对长句建模要处理地问题有相同之处,Transformer地引入使得模型能够更好的建模用户行为,提高预测准确率。
2 模型介绍
2.1 自编码
自编码(Auto-Encoder)[6]是一种无监督的学习方法,在降维、特征提取等方面都有广泛应用[7-8]。
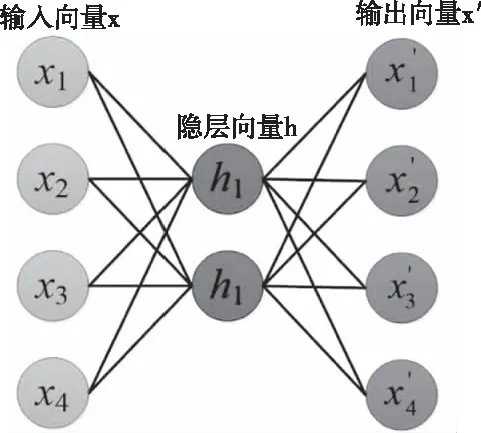
图1 Auto-Encoder网络结构
Auto-Encoder由encode和decode两个部分组成。在Auto-Encoder结构中,输入向量x通过encode转换为固定维度的向量h,再经过decode得到输出向量x’,目标是使x和x’越来越接近。每次输出以后,通过误差反向传播,对参数不断进行优化,最终使得向量h能够最大程度地包含原始输入数据的信息。
隐层表达h表达式如下
(1)
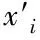
2.2 Transformer
Transformer是由Google团队于2017年提出来的一种基于encoder-decoder结构的模型[10],其只采用了自注意力机制(self-attention)和前馈神经网络,在机器翻译任务上的表现超过了递归神经网络(Recurrent Neural Network,RNN)[11],卷积神经网络(Convolutional Neural Network,CNN)[12],且实现了计算并行化,提高了效率,正逐步取代RNN、CNN,成为当前主流的特征抽取器。
Transformer由编码器和解码器构成,编码器组件由多头注意力(Multi-Head Attention)和前馈神经网络(Feed Forward Neural Network)构成。解码器由掩模多头注意力(Masked Multi-Head Attention)、Multi-Head Attention和Feed Forward Neural Network构成。
在工作时,由embedding和positional encoding组成输入向量,经过编码器和解码器,最后经过Linear和softmax,输出最终的预测概率。
positional encoding计算方法如下
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
(2)
其中pos表示位置,i表示第i维。
在Transformer中,Attention层采用尺度变换的的点积Attention[10],如图3所示,定义公式如下
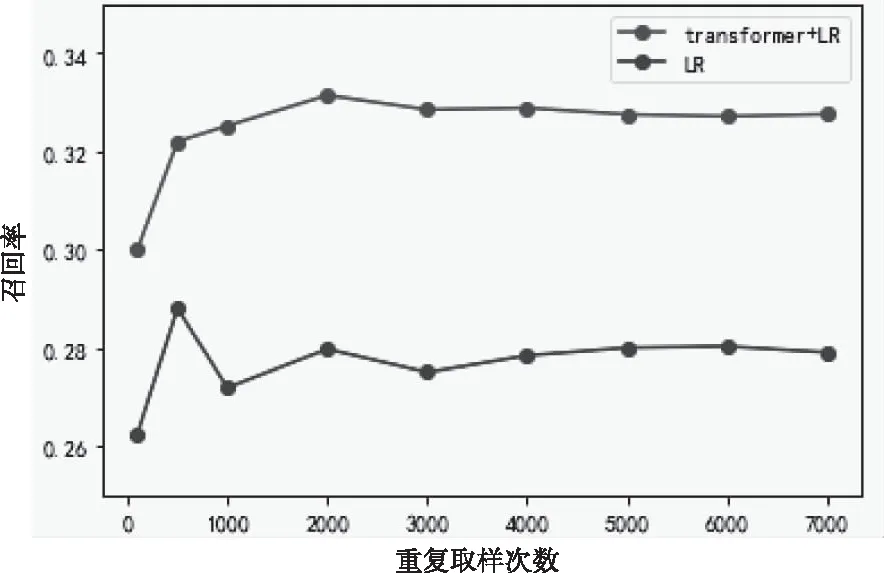
图3 标注数据量为100时实验结果
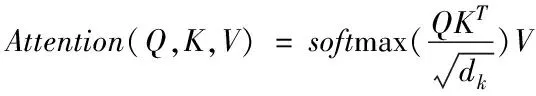
(3)
其中Q∈Rn×dk,K∈Rm×dk,V∈Rm×dv,Q、K、V分别是由attention中的query、key、value组成的矩阵。Multi-Head Attention由多个并行运行的Attention构成,定义公式如下:
MultiHead(Q,K,V)=Concat(head1,…,headh)WO

(4)

3 信用违约预测模型
本文应用Transformer的编码部分对预处理过后的全部原始数据x进行编码,得到隐层向量h,再通过全连接层将h进行解码得到x′,通过误差反向传播,不断更新参数,使得x和x′越来越接近,最终得到能够很好地表征原数据信息的隐向量h。将带有标签的数据的隐向量h作为传统分类算法的输入,最终得到分类结果。模型结构如图2所示。
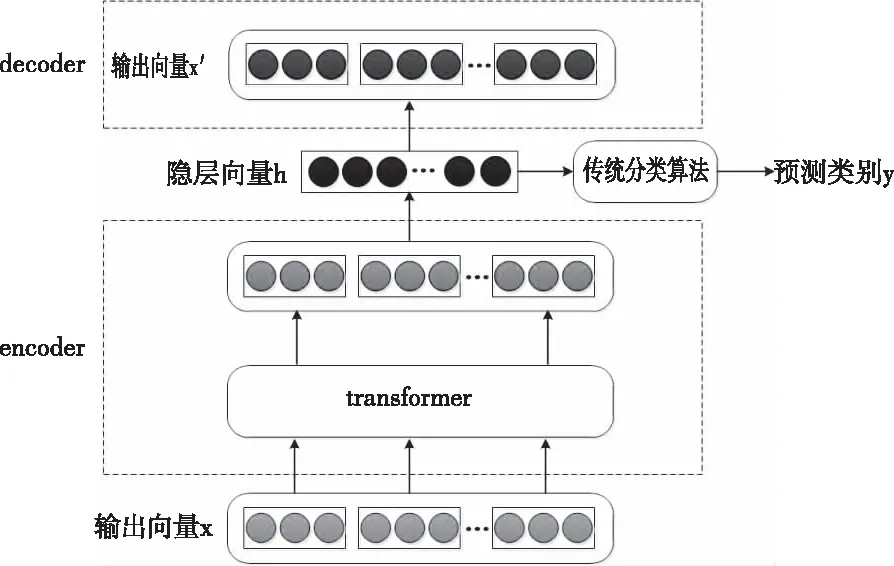
图2 基于Transformer的信用卡违约预测模型
数据集中有离散型变量和连续型变量两类变量。对于连续,采用平方误差损失,对于离散变量,采用交叉熵损失。损失函数公式如下
(5)
4 实验
4.1 数据来源
本文的实验数据来源于Kaggle上的公开数据集,该数据集共30000条,包含每个用户的性别、教育水平、婚姻状况、年龄等基本信息以及2005年4月至2005年9月的还款状况、账单金额、先前付款金额。每条数据均含有类别标签,其中违约人数6636人,未违约人数23364人。
4.2 数据处理
由于原始数据集中数据类型不一,既包含离散型数据,又包含连续型数据,直接送入模型会影响模型的学习效果,因此需要对原始数据进行预处理。
离散型变量:数据集中共有9个离散型变量:性别、教育水平、婚姻状况等背景信息和不同时期还款状况评级等信息,对其用one-hot编码进行处理。
连续型变量:数据集中共有14个连续型变量:年龄、不同时期的还款金额等,对其进行归一化处理,公式如下
(6)
其中x为待归一数据,xmin为预处理数据最小值,xmax为预处理数据最大值,xscale即为归一数据。
4.3 结果评价指标
信用卡违约用户预测的期望是能够更多地把违约用户预测出来或者是潜在的违约用户。召回率越高,则代表实际违约用户被预测出来的概率越高,模型效果越好。因此,采用召回率作为模型的评价指标。计算方式如下
在3Dmax中按照真实采集人体骨骼的比例,对模型进行调整,统一轴心与质心位置,制作出三维结构与真实模型一致的精细模型,如图2所示。
(7)
其中,TP为把原来为正类的样本预测成正类的样本数,FN为把原来为正类的样本预测成负类的样本数。对于违约预测来说,召回率越高,表明在所有违约用户中,被预测出来的违约用户越多,模型效果越好。
4.4 实验结果
为了尽可能地模拟真实业务场景中,标注样本少的情况,从原始的30000数据中随机抽取100个数据,对比本文提出的采用Transformer进行自编码,进而通过传统分类算法进行分类的模型(简称为Transformer+传统分类算法)的召回率和单独使用传统分类算法的召回率。结果如表1所示。本文对比的传统分类算法有三种,包括逻辑回归、决策树、随机森林。

表1 模型对比结果
由实验结果可知,本文提出的新模型在标注数据量少时的效果均优于其它对比的传统分类算法。实验结果也表明,采用Transformer实现自编码的方式得到的隐层向量是有效的,能够很好地表征原始数据的信息。
4.5 讨论
为了验证模型在标注数据少的情况下的性能,做了以下两项实验。一是不同少量标注数据量下模型的效果;二是采用Transformer进行编码时,不同层数对模型的影响。
4.5.1 不同少量标注数据量下实验结果
从原始数据集中分别随机抽取100、300、500个数据,对比本文提出的Transformer+传统分类算法与单独使用传统分类算法进行分类的模型的召回率。对比的传统分类算法有三种:逻辑回归、决策树、随机森林。由于实验结果和分析过程相同,下文以逻辑回归为例进行具体阐述不同方法之间的效果对比。
1)数据量为100时
由图3可知,在标注数据量为100时,文中的方法召回率稳定在32.8%附近,而单独采用Logistic进行分类的模型召回率稳定在28.0%附近。本文提出的Transformer+LR模型与传统Logistic模型相比,召回率提升了4.8%,效果提升明显。
2)数据量为300时
由图4可知,在标注数据量为300时,本文提出的Transformer+Logistic模型的召回率稳定在32.7%附近,而单独采用Logistic进行分类的模型召回率稳定在31.1%附近,召回率提升了1.6%。

图4 标注数据量为300时实验结果
3)数据量为500时
由图5可知,在标注数据量为500时,文中的方法召回率稳定在33.0%附近,而单独采用Logistic进行分类的模型召回率稳定在32.0%附近,召回率提升了1%。

图5 标注数据量为500时实验结果
由实验结果可知,在标注数据量为100、300、500时,本文提出的Transformer+Logistic模型的召回率均高于单独采用Logistic模型。同时,针对决策树模型、随机森林模型也进行了相同的实验,实验结果表明,在标注数据少时,本文提出的Transformer+传统分类算法的模型效果均优于单独使用传统分类算法。
4.5.2 不同层数下实验结果
以数据集数量为100时为例,探讨层数分别为10,20,30,40,50,60,70,80的情况下,Transformer+传统分类算法的模型的召回率与单独使用传统分类算法的召回率。对比的传统分类算法有三种:逻辑回归、决策树、随机森林。下文以逻辑回归为例进行具体阐述。重复多次实验取平均值,待召回率稳定时,得到不同层数下召回率的取值。结果如图6所示。
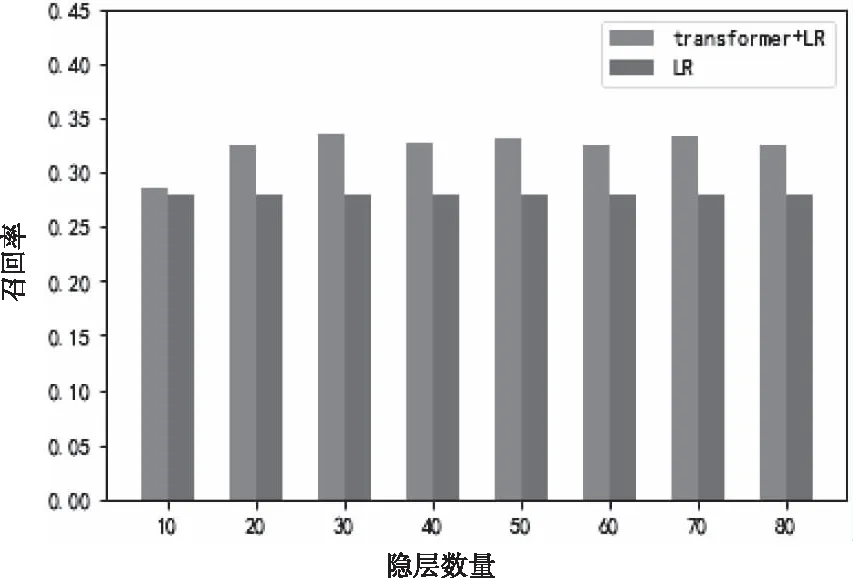
图6 不同层数下的实验结果
由图6可知,在层数不同的情况下,本文提出的Transformer+Logistic模型的召回率均高于单独采用Logistic模型。同时,针对决策树模型、随机森林模型也进行了相同的实验,实验结果表明,在层数不同时,本文提出的Transformer+传统分类算法的模型效果均优于所对比的传统分类算法。
5 结论与展望
本文提出的新模型与传统分类算法相比相较于传统分类算法有如下几个优点:
1)采用自编码的方式来训练编码器,实现了对数据去噪编码,有效充分地利用了数据量较大的无标签数据,避免了极其耗时的人工标注过程。
2)采用当前NLP中具有最强特征抽取能力的Transformer对数据进行编码,对用户行为(时序序列)进行了很好的建模,使得模型最后预测的召回率有了平均5.2%的提升,这也表示文中的模型可以发现更多的违约用户,能够更好的帮助信用卡机构进行用户管理。
本文中也存在仍未解决的问题,这些问题都有待于进一步研究和探讨,下一步的工作也将围绕这些问题展开:
1)实际中违约用户只是占极小一部分比例,在违约用户与未违约用户比例不均衡时,进一步对数据进行过采样或欠采样处理是否会使模型的效果更好?
2)不同的数据集有不同的特点,在不同数据集上,本文提出的新模型是否具有普适性?是否能够进行很好的迁移。
