不均衡样本下的低分辨雷达目标识别算法
2021-11-17朱克凡王杰贵叶文强
朱克凡,王杰贵,叶文强
(1.国防科技大学电子对抗学院,安徽 合肥 230037;2.中国人民解放军63768部队,陕西 西安 710000)
1 引言
雷达目标识别(Radar Target Recognition,RTR)是雷达研究的一个重要方向。由于高分辨雷达研究成本高、周期长、难以普及,现役雷达大部分是低分辨雷达,且随着脉冲压缩技术的普及,传统低分辨雷达也能拥有很高的径向分辨力,能够提取目标一维距离像等细微特征,基于低分辨雷达的目标识别技术研究仍然是雷达研究的一个重要热点[1-3]。
传统低分辨雷达目标识别是基于特征提取的目标识别,即首先基于回波起伏、极点分布以及调制谱特性等特征,对目标进行特征提取,然后采用贝叶斯、支持向量机(Support Vector Machine,SVM)、最近邻分类、隐马尔科夫模型等方法对目标进行分类识别。通过提取目标特征的方法可以实现对目标的分类识别,然而特征多为人工设计[4],属于浅层特征,具有不完备性,不利于目标识别率的进一步提高,且特征往往只针对特定目标设计,方法的泛化性也存在不足。
自Hinton等人提出深度学习理论后,卷积神经网络(Convolutional Neural Networks,CNN)作为该领域里的重要模型,由于能够自学习数据深层本质特征,应用在目标分类识别领域,识别准确度可以获得较大提升,较传统方法有明显优势[5-8]。但基于深度学习的低分辨雷达目标识别方法往往需要足够多且不同类别数量均衡的训练样本。在现代战争中,当雷达目标是先进的非合作目标或隐身目标时,对该目标通常难以获取足够多的训练样本,导致不同类别样本数是极端不平衡的,目标识别率较低。
针对样本不均衡问题,传统低分辨雷达目标识别技术采用改进的SVM算法,如加权SVM(weighted SVM,WSVM)[9],代价敏感SVM(Cost-sensitive SVM,CS-SVM)[10]等,基于提取的特征进行目标识别,但由于识别特征本身具有不完备性,识别效果欠佳。文献[11-13]利用合成少数类过采样技术(Synthetic Minority Oversampling Technique,SMOTE)扩充少数类样本数以平衡样本集,提高识别率,但由于SMOTE算法使用噪声合成新样本,数据集扩充效果不理想。文献[14]提出了焦点损失函数,通过大幅度降低简单样本的权重使网络训练侧重于对困难样本的识别,提高目标识别率。但由于训练初期的网络对不同类别样本没有识别能力,无难易之分,初期训练过程受同类数量多的样本主导,训练缓慢且容易陷入倾向于将目标识别为样本数多的类别的局部极值点。文献[15]使用类别均衡交叉熵损失函数来自动平衡正负样本产生的损失。但由于在交叉熵损失函数中添加类别均衡权重,相当于改变了原始数据分布,所以CNN拟合的分布较原始数据分布有偏差,识别效果提升有限。
针对以上问题,在样本不均衡条件下,本文提出了基于分段损失函数的卷积神经网络低分辨雷达目标识别算法,该算法首先通过CNN自动提取数据深层本质特征,然后使用分段损失函数计算误差,最后将误差反向传播优化权值以提高识别效果。仿真结果验证了本文算法的有效性和较传统识别方法的优越性。
2 基于分段损失函数的卷积神经网络低分辨雷达目标识别算法
2.1 CNN
CNN是一种深度前馈人工神经网络,包括卷积层、池化层及全连接层,结构如图1所示。卷积层采用不同的卷积核,在隐式地提取数据特征的同时减少了训练参数;池化层对卷积层提取的特征进行降采样,进一步减少训练的数据量。全连接层将特征进行综合,并可与Softmax分类器结合,在模式分类领域具有明显优势。
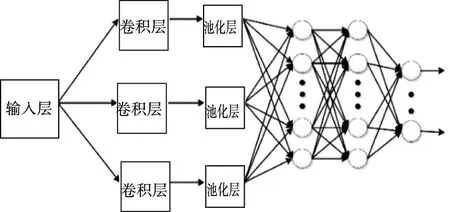
图1 卷积神经网络基本结构
2.2 分段损失函数
分类问题中常用的损失函数是交叉熵损失函数
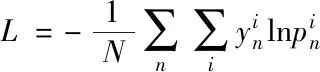
(1)
由于交叉熵损失函数平等累加每一个样本损失,当某一类样本数较多时,就会在误差反向传播过程中起主要作用,不利于网络的训练。针对样本不均衡问题,有两种改进的交叉熵损失函数。
一是类别均衡交叉熵损失函数[15]
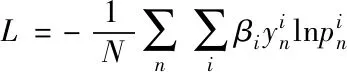
(2)
式中:βi表示类别i的均衡权重。
二是焦点损失函数[14]
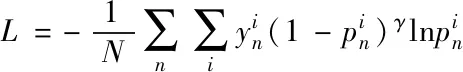
(3)
式中:γ是焦点参数,γ≥0。
由于类别均衡交叉熵损失函数改变了原始样本分布,使CNN拟合的分布较原始数据分布有偏差;而焦点损失函数,使CNN在初期训练较慢且容易陷入倾向于将目标识别为样本数多的类别的局部极值点。基于此,本文提出了分段损失函数,在焦点损失函数的基础上,训练初期引入类别均衡交叉熵损失函数,类别均衡交叉熵损失函数的加入使初期网络训练较快,且对多类目标都有一定的识别效果,在分段点,结合类别均衡交叉熵损失函数训练后的权重优于随机初始化训练后的权重,更容易避开倾向于将目标识别为样本数多的类别的局部极值点;后期只使用焦点损失函数,专注于困难样本,提高网络的识别性能。同时,为了防止在分段点,由于损失函数的突变而过快或过多的扭曲权重,借鉴模拟退火思想,采用线性衰减的方式,引入衰减参数。
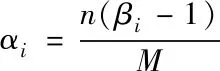
(4)
式中:αi是类别i的衰减参数,βi表示类别i的权重,M表示分段的迭代次数,n表示当前的迭代次数。则分段损失函数可以表示为
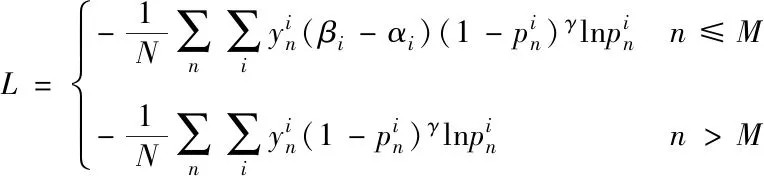
(5)
2.3 基于分段损失函数的CNN低分辨雷达目标识别算法
2.3.1 CNN结构
CNN最初是针对图像数据设计,更适合于处理二维图像。由于低分辨雷达目标信号是一维时序信号,无法直接将目标信号的采样数据输入CNN,常见方式是对数据进行时频变换,将时序信号转换为时频图像,文献[16]提取信号全双谱特征输入CNN,文献[17]提取信号时频特性作为CNN的输入。由于人工提取特征会损失数据信息,为保留目标全部差异信息,尽可能提高目标识别率,本文采取调整CNN结构的方式,设计了一维CNN结构,网络结构如表1所示。

表1 一维CNN网络模型结构
2.3.2 算法步骤
1)取大量雷达目标信号采样数据作为训练样本输入卷积层,使用多个初始权值不同的卷积核对输入数据进行卷积,获得数据的特征映射向量并输入池化层;
2)池化层通过一维窗口,采用不重叠的步进方式,对特征向量进行下采样处理,有效降低数据维度;
3)Dropout层按照设置的概率随机地将输入神经元置零以缓解过拟合现象;
4)根据网络卷积层、池化层和Dropout层数量,重复步骤1)-3),对输入数据进行多层卷积、池化和Dropout操作,并将第3次Dropout后的数据输入到全连接层;
5)全连接层将输入的多个特征整合成一维特征向量,并通过Softmax函数,输出各类识别概率组成向量,取概率向量中值最大的作为本次识别结果;
6)将当前迭代次数 与分段迭代次数M比较,选取合适的损失函数,根据预测结果和真实标签计算损失并反向传递;
7)根据预设的最大迭代次数循环步骤1)—6)将网络训练完毕。
3 实验结果与分析
3.1 实验数据集
3.1.1 低分辨雷达目标回波建模
现代雷达辐射源信号常采用脉冲压缩信号,如相位编码信号、线性调频(Linear Frequency Modulation,LFM)信号等,使用脉冲压缩技术可使雷达具有很高的径向分辨力,当雷达目标的尺寸大于径向分辨力时,运动目标占据多个距离单元,此时可以使用多散射点模型来模拟目标回波信号。
当雷达发射信号是LFM信号时,将与发射信号斜率相同的LFM参考信号作为本振信号,对接收到的回波信号进行变频、采样和幅度归一化处理后,获得的回波采样数据为
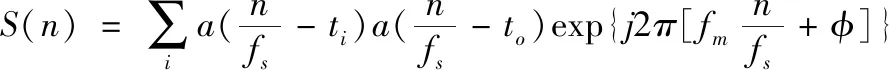
(6)
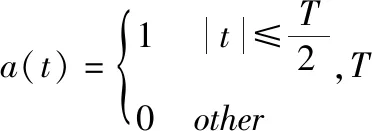
3.1.2 数据集参数设置
实验数据集由python编程软件生成,仿真参数设置:LFM信号载频为3 GHz,调频周期为0.1 ms,调频带宽为100 MHz,中频采样频率为5 MHz。数值仿真对地面目标进行目标识别,分别为卡车、摩托车和人。取1个调频周期内的采样数据作为1个样本,通过计算可知样本大小为1×500,类别标签采用独热码方式表示,维度是1×3。训练样本集与测试样本集分别独立产生,其中,训练集卡车样本数为30,摩托车为300,人为3000,共3330个样本,测试集卡车样本数为200,摩托车为200,人为200,共600个样本。
3.2 分段损失函数参数选择
分段损失函数中存在可变的类别均衡权重,焦点参数和衰减参数,在本文算法中,对类别均衡权重,焦点参数和衰减参数做如下选择。
3.2.1 类别均衡权重
在类别均衡交叉熵损失函数中,设置类别均衡权重的目的是平衡各类目标数量差异对损失反向传播的影响,所以权重值与各类别数目比例有关,常见的设置方式如下[15]
βiNi=βjNj
(7)
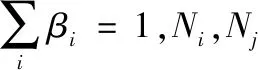
3.2.2 焦点参数
焦点参数的作用是大幅度减少样本集中简单样本的权重,使CNN侧重于对困难样本的训练。不同γ下的焦点损失值如图2所示,其中预测概率指的是CNN将目标预测为真实标签的概率。
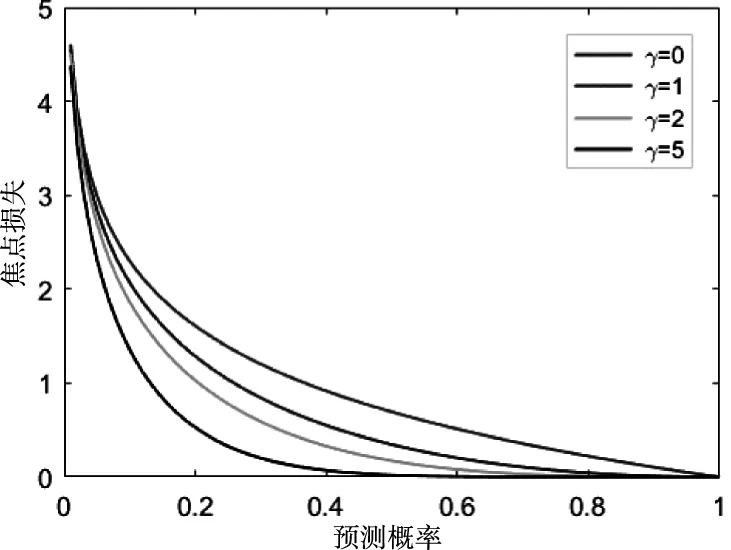
图2 不同γ下的焦点损失值
文献[14]将预测概率高于0.6的样本看作简单样本,从图2可以看出,引入γ可以有效减少简单样本的损失,使CNN在训练时侧重于对困难样本的识别,本文选择γ=2作为焦点参数值。
3.2.3 衰减参数
衰减参数主要由分段的迭代次数M决定,M的不同会影响目标识别效果,当M=0时,分段损失函数退化为焦点损失函数。在同样条件下对不同的分段迭代次数M进行对比实验,识别效果如表2所示。

表2 不同分段迭代次数M下的识别效果
通过对比实验,本文选择M=100作为分段的迭代次数。
3.3 不同损失函数对识别效果的影响
为了验证本文所提分段损失函数的有效性,对使用不同损失函数的CNN进行识别实验。用添加高斯白噪声的方法对数据进行加噪处理,实验采用SNR=-4dB的仿真目标回波采样数据作为网络输入,使用设计的一维CNN结构作为识别网络。图3是使用四种损失函数的CNN在不同迭代次数下的测试集识别率。
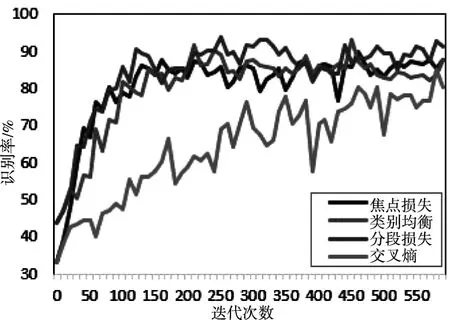
图3 使用四种损失函数的CNN识别率
从图3可以看出,分段损失函数结合了类别均衡交叉熵损失函数和焦点损失函数的优点,初期训练速度较快,获得较好的训练权值,后期挖掘困难样本,较焦点损失函数和类别均衡损失函数识别率有所提高,四种损失函数的平均识别率如表3所示。

表3 四种损失函数的平均识别率
为了更加直观的展示不同损失函数的识别效果,各损失函数的混淆矩阵如图4所示,图5~图8是接收者操作特征曲线(receiver operating characteristic curve,ROC)曲线和ROC曲线下方的面积(Area under the Curve of ROC,AUC)。其中混淆矩阵中每一列表示目标所属的真实类别,每一行表示一维CNN的识别结果,标签从上至下,从左至右依次为卡车,摩托车和人。
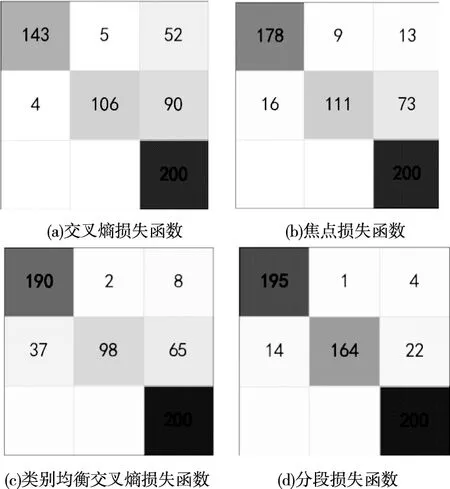
图4 混淆矩阵
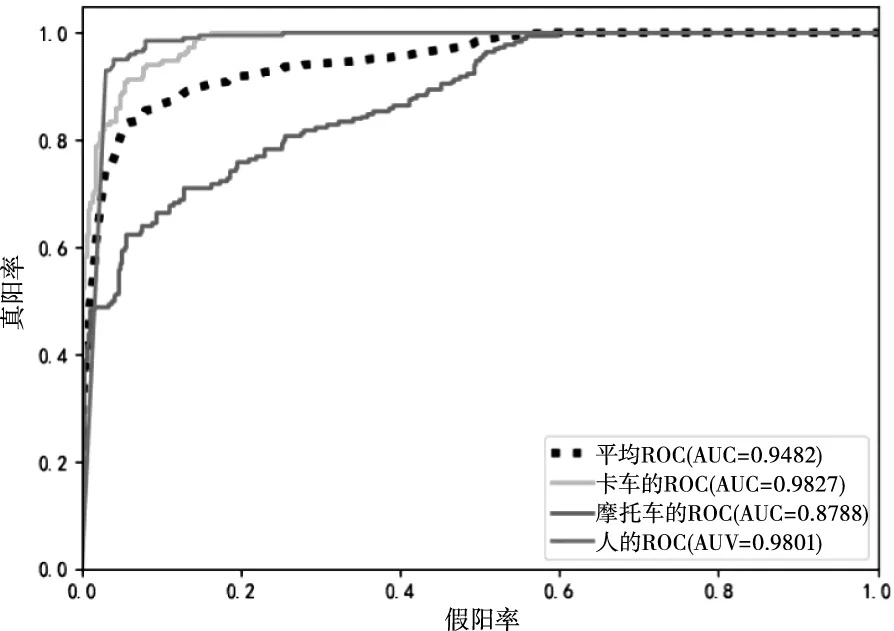
图5 使用交叉熵损失函数的ROC曲线和AUC值
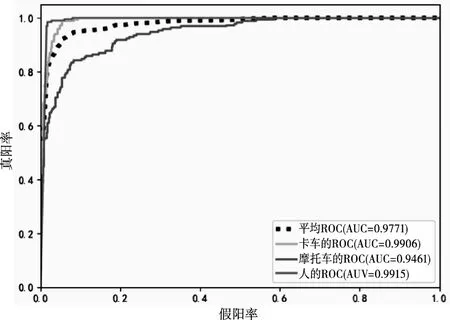
图6 使用类别均衡交叉熵损失函数的ROC曲线和AUC值
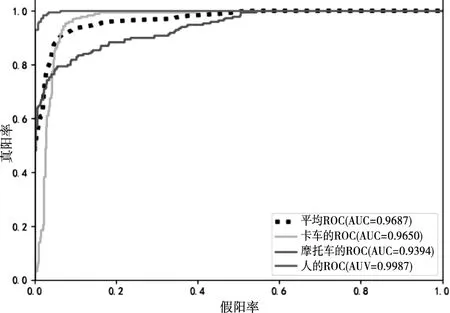
图7 使用焦点损失函数的ROC曲线和AUC值
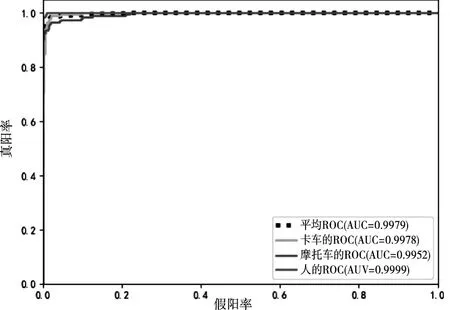
图8 使用分段损失函数的ROC曲线和AUC值
从图4的混淆矩阵和图5~图8的ROC曲线和AUC值可以看出,基于交叉熵损失函数的CNN识别算法对卡车和摩托车的识别效果较差,通过使用类别均衡交叉熵损失函数或焦点损失函数,可以提高算法对卡车的识别效果,但仍然无法有效识别摩托车,且焦点损失函数更倾向于将分类错误的摩托车样本识别为样本数较多的人,而基于分段损失函数的CNN识别算法能够有效识别三类目标,且在识别性能方面明显优于其它算法,充分说明了本文所提分段损失函数的有效性。
3.4 基于分段损失函数的卷积神经网络低分辨雷达目标识别算法的识别效果
为了进一步说明本文所提基于分段损失函数的CNN低分辨雷达目标识别算法的有效性和较传统方法的优越性,将本文方法与其它五种方法进行比较,方法一是使用文献[9]所提WSVM算法的传统识别方法,其中WSVM算法基于目标的雷达散射截面积和一维距离像的中心矩特征进行识别,方法二是使用交叉熵损失函数的CNN低分辨雷达目标识别算法,方法三是使用类别均衡交叉熵损失函数的CNN识别算法,方法四是使用焦点损失函数的CNN识别算法,方法五是文献[12]所提基于SMOTE和CNN的识别算法。同时为了验证本文方法的鲁棒性,通过添加高斯白噪声的方法在不同信噪比条件下进行识别实验,不同方法的识别效果如表4所示。
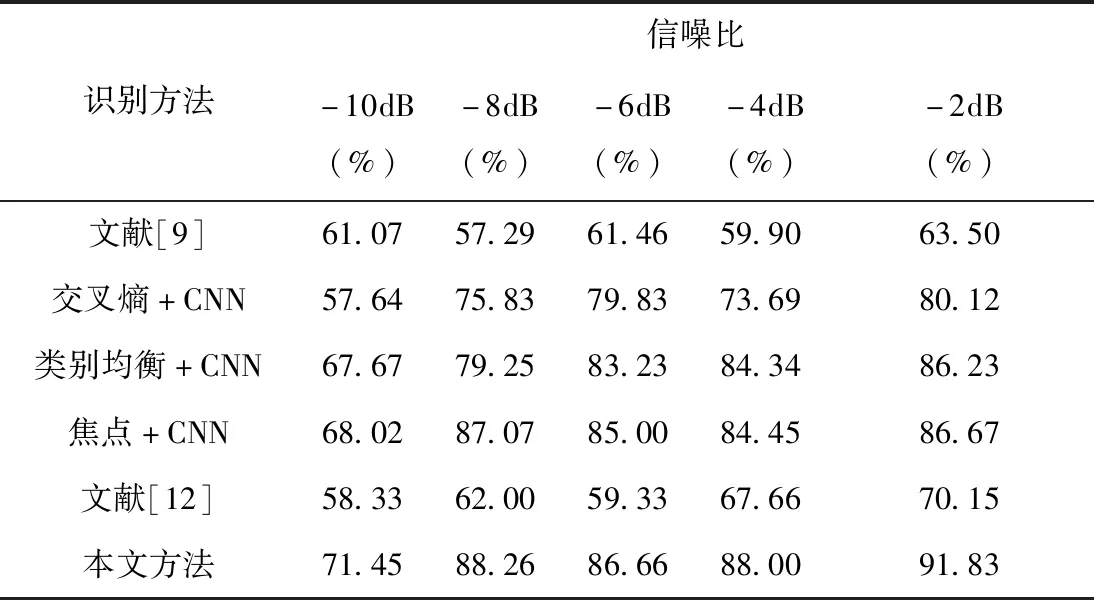
表4 不同方法的识别效果
从表4可以看出,本文方法在不同信噪比条件下的识别率最高,较传统基于WSVM的识别算法识别率至少提高了10.38%,较基于交叉熵损失函数的CNN识别算法识别率至少提高了6.37%。
4 结论
针对样本不均衡条件下,传统低分辨雷达目标识别方法识别率较低的问题,本文提出了基于分段损失函数的卷积神经网络低分辨雷达目标识别算法。首先通过CNN获取数据深层本质特征,然后使用分段损失函数,使CNN在初期能够更快训练,获得更好的权值,避开倾向于将目标识别为样本数多的类别的局部极值点,在后期则侧重于对困难样本的训练,最后将损失反向传播,提高网络识别性能。仿真结果表明本文所提算法较传统识别方法有明显优势,使用分段损失函数能够有效提高CNN在样本不均衡条件下对低分辨雷达目标的识别效果。
