基于粒度理论的高维数据流并行计算方法
2021-11-17胡顺仿
路 晶,胡顺仿
(1. 中国民用航空飞行学院,四川 广汉 618307;2. 云南民族大学,云南 昆明 650000)
1 引言
随着计算机网络、数据库、通信等技术的高速发展,导致了信息数量的爆炸性增长,许多领域出现了高速产生、动态变化的流式数据[1],如销售业务中的交易数据流、金融市场的交易数据流、环境监测的实时数据流都以高维属性发挥各自的作用,研究人员称这种类型的数据为高维数据流[2,3]。由于高维数据流的应用逐渐广泛,如何在具备关联性的高维数据流之间进行并行计算成为了目前研究的热点[4]。
许多相关学者对此进行了大量研究,目前,常用的数据流计算处理方法主要有基于GPU并行处理的大规模连续潮流批量计算方法和基于分治法求解对称三对角矩阵特征问题的MPI/Cilk混合并行方法,虽然都获得了一定的研究成果,但是上述方法主要面向传统类型的静态数据,数据只能匀速到达且到达次序不独立,还要受系统控制,当数据流数量以及类别增多时,存在计算精度低和计算效率慢的问题。在此背景下,研究效率更高的高维数据流并行计算方法显得尤为重要[5-7]。
因此,提出基于粒度理论的高维数据流并行计算方法,该方法主要包括四个部分,一是挖掘高维数据流,利用粒度理论可逐渐降低数据流环境的复杂性,可对数据进行更有效的分析处理。二是利用基于局部保持投影(LPP)原理和主成分分析(PCA)原理对数据噪声进行压制,使数据流可以进一步处理。三是利用皮尔逊积差系数及其数学特性中的皮尔逊积差相关系数使数据流之间进行关联。最后在数据流十字转门模型的基础上,定义适合高维数据流分析的滑动数据流窗口模式,使高维数据流能进行有效的并行计算。
2 基于粒度理论的高维数据流并行计算方法
2.1 基于动态粒度的数据流挖掘模型
基于动态粒度的数据流挖掘模型是结合粒度理论和数据流的特性组成的模型,如图1所示。第一部分是图中虚线框内部分表示在线挖掘数据流,第二部分是对在线部分的挖掘结果进行分析与更新维护,又称为离线分析[8]。
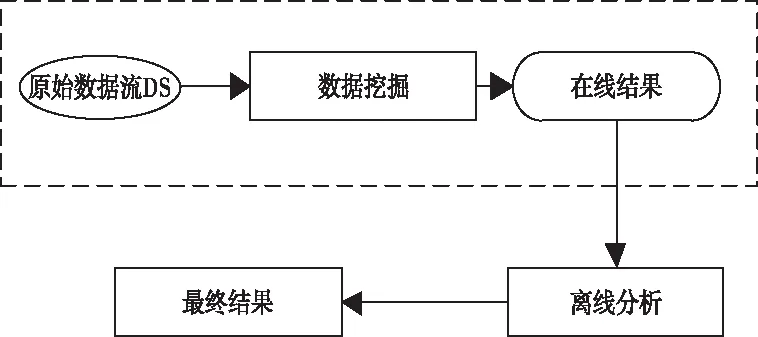
图1 基于动态粒度的数据流挖掘模型
原始数据流由DS(data Stream)描述[9],涵盖数据预处理,数据粒度塑造、详细挖掘任务的行动(如分类、聚类、关联规则等),整体称为数据挖掘过程,用Data Minging描述涵盖保存、修正以及检索在线结果,即修正、保存与检索中间结果集称为在线挖掘结果,用On-line Result指代[10]。持续解析和修订在线挖掘结果称为离线分析,用Off-line Analysis表示。修正、保存与检索最后结果集称为最终挖掘结果,用Final result描述。
形成新数据后,再次遍历检索全部数据,会耗费过多的资源与时间[11],这是由于数据流中数据量产生速度过快且数据量巨大,这并不符合数据流挖掘对速度和实用性的需求。为了高效率修正挖掘结果,利用增量式修正方法处理新加入的数据[12]。
2.2 基于LPP和PCA的数据噪声抑制
在数据流挖掘模型的基础上,提出基于局部保持投影(LPP)+主成分分析(PCA)方法,LPP(利用LPP重构特性,并非降维特性)对数据采样点进行重新构建,获取最佳重构权值矩阵,逐渐减小噪声隐患,实现涵盖非线性的弯曲或倾斜同相轴数据去噪处理。
依据PCA特性,使用PCA分解后的随机噪声拥有不相关性,数据有效信号分解后拥有较好的相关性,所以PCA分解特征值较小,数据有效信号分解后特征值很大。由上述可知,为完成抑制随机噪声的需求,PCA可依据该特征从大量数据之中查询同相轴,重新构建特征向量,获得主成分中最主要的部分,将小特征值的随机噪声数据删除。设置数据流的个数是D,采样点集合为X=[x1,x2,…xN]。数据流进行LPP重构和PCA特征值分解过程如下:
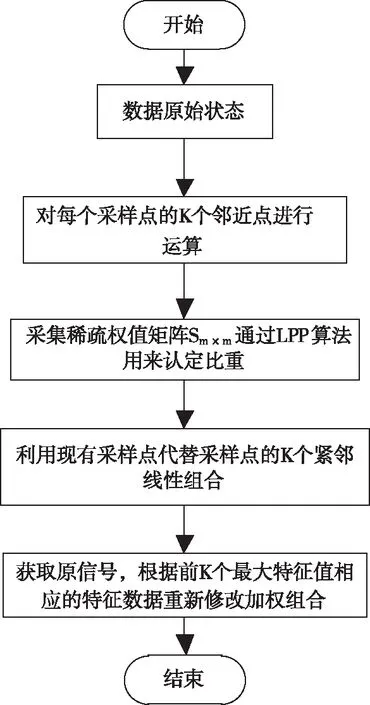
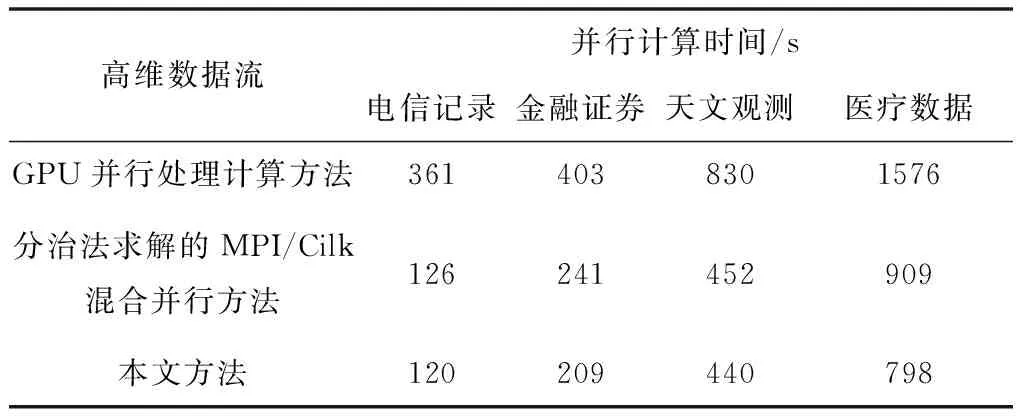
1)用以下公式计算每个采样点xi的k(k (1) 2)依据LPP算法确认权重,与数据集X相应的对称稀疏权值矩阵为Sm×m,其通过xi到xj的权值Sij=e-‖xi-xj‖2/t计算得出。 4)基于数据X*进行PCA线性变换,用线性正交变换矩阵W描述Y的线性组合,即重构结果X′ (2) 式中,ui表示矩阵U的列;yi表示矩阵Y的行,特征数据与特征值λi相对应。基于特征数据的加权组合重构获得原信号,进而通过式(2)获取随机噪声的抑制结果。 LPP向线性化处理变化是因k值过高,LPP原高维空间中的分布结构特性难以保证是由于k值较低,因此,选取采样点最邻k值在LPP重构流程中十分重要。把PCA的前K个最大特征值(根据特征值解析算出)固定在90%能量采集范围内,以确保有效信号尽可能完整。为不影响提取维度,LPP算法只在LPP+PCA算法重新构造过程中使用。LPP+PCA方法去噪流程见图2。 图2 基于LPP+PCA的数据去噪处理流程图 2.3.1 皮尔逊积差系数及其数学特性 表达两个随机变量之间线性关系的强度和方向称为相关系数(correlation,或称关联系数),其属于概率论和统计学内容。衡量数据的相关系数大部分要依据数据的特性,利用皮尔逊积差相关系数研究数据特性。统计意义上两组数据的关联性,若n维(n≥1)元素是xi,n维元素映射的数据函数是F(xi)、G(xi) (3) (4) 两组n维变化数据的关联性可由上述式(5)获得 (5) 通过柯西-施瓦茨不等式可知,相关系数的绝对值低于1,实时比较过程中,即当τ=0时,相关系数接近1或-1,因两个变量的线性关系增高而发生,相关系数大于0是由一个变量增加而另一变量也增加的原因导致,相关系数小于0是由一个变量增加而另一变量减少的原因导致,相关系数为0因两个变量独立而发生,如果两个变量不独立,相关系数则不为0,这些判定都由柯西-施瓦茨不等式得到。解析单条数据流自身的属相相关性和其变化周期性可在F=G的条件下完成。 2.3.2 高维数据流并行计算的实现 定义适应高维数据流分析的滑动数据流窗口模式需依据数据流十字转门模型,高维信号X到实数集上的一个映射X[1,2,…,N]→Rp是高维数据流a1,a2,…,ai,即向一个列向量中映射一条高维数据。差异时刻的数据流内某一个属于值X[j]的修正值用单个ai描述,一个修正元祖用ai=(j,Δi)描述,它的意义为xi[j]=Xi-1[j]+Δi,说明时刻t的p维修正向量满足十字转门模型。根据时间戳i的增高流入,仅可读取1次向量Δi,涵盖最近n项元素的序列ai-n-1…ai利用高维数据流的滑动窗口模式描述高维数据流X与Y之中典型相关性分析的根本线索:从X和Y中分别获得组合变量U、组合变量V,通过式(6)得到高维数据流的并行计算结果 Un+1=Xp+nAn+1,Vn+1=Yq+nBn+1 (6) 式中,A、B代表线性变换,又叫空间特征向量。通过定义高维数据流的滑动数据流窗口模式,实现对高维数据流的并行计算。 将本文研究的基于粒度理论的高维数据流并行计算方法应用到某高维数据集中,对该数据集中的高维数据流进行计算。该数据集中包含电信记录、金融证券、天文观测、医疗数据等共计40种类别的数据流,数据数量共计108个。其中电信记录、金融证券、天文观测、医疗数据四种类别数据的数据情况如表1所示。为证实本文方法的应用效果,选取基于GPU并行处理的计算方法和分治法求解的MPI/Cilk混合并行方法为对比方法,从高维数据流挖掘、数据去噪以及并行计算的角度验证本文方法的应用效果。 表1 四种类别数据情况 为测试数据流挖掘对内存消耗的影响,对电信记录、金融证券、天文观测、医疗数据四种类别数据进行测试,测试三种方法对四种类别数据流进行挖掘的内存消耗,实验结果由表2表示。 表2 不同方法挖掘的内存消耗(%) 根据表2可知,不同类别数据流下,三种方法的数据流挖掘对内存消耗的影响不同,其中高维数据流规模越大,内存消耗也随之增加。但本文方法对不同类别数据流挖掘的内存消耗始终小于两种对比方法,说明本文方法在不同类别高维数据流挖掘时内存消耗较小,高维数据流挖掘性能较好。 为完善高维数据流的计算,还需进行数据去噪实验,测试三种方法对不同类型数据进行去噪时去除的噪声点数,实验结果由表3表示。 表3 不同方法数据去噪能力 根据表3可知,三种方法对不同类别高维数据流的删除噪声点数能力不同,本文方法删除噪声点数始终高于其它两种算法,说明本文方法具有较强的数据去噪能力。 通过对比不同滑动窗口长度下,三种方法的并行计算精度,分析不同方法的高维数据流并行计算能力。实验结果由图3表示。 图3 不同滑动窗口长度计算精度 分析图3得知,随着滑动窗口长度的增加,三种方法的并行计算精度均呈现上升趋势,其中,GPU并行处理计算方法的最高并行计算精度只能达到0.881,分治法求解的MPI/Cilk混合并行方法的最高并行计算精度只能达到0.884,而本文方法的最高精度能达到0.887,始终高于另外两种方法,因此本文方法具有较高的高维数据流并行计算精度。 为进一步验证本文方法的并行计算能力,测试三种方法计算不同类别高维数据流所需时间,对比结果由表4表示。 表4 不同方法并行计算时间 根据表4可知,由于电信记录、金融证券、天文观测、医疗数据四种类别数据流的边数和数据条数逐渐增加,所以三种方法的并行计算时间也随之增加,但本文方法计算时间始终小于其它三种方法。说明本文方法可在极大程度上缩短高维数据流的并行计算时间,并行计算效率较高。 三种方法并行计算四种数据流类别时的时间差和加速比对比结果由图4、图5表示。 图4 三种方法并行计算时间差 图5 三种方法并行计算时间差 根据图4、图5可知,随着高维数据流规模的增加,三种方法的并行计算时间差随之升高,加速比逐渐减小,说明高维数据流规模的增加,高维数据流并行计算时间增加显著,但本文方法的并行计算时间差始终比GPU并行处理计算方法、分治法求解的MPI/Cilk混合并行方法小,加速比降低情况也优于两种对比方法。实验结果表明本文方法的高维数据并行计算能力优势显著。 本文研究基于粒度理论的高维数据流并行计算方法,借助粒度理论对高维数据流的并行处理展开进一步研究,粒度理论是数据并行处理的新理念和计算模式,它包含了所有关于粒度的方法研究,这种计算理论符合人类思维处理问题的方式。经实验验证,该方法具备较高的高维数据流挖掘、去噪能力,并且拥有较好的并行计算效果。今后可在现有研究基础上继续加深研究,以期进一步改进高维数据流并行计算效果,未来工作包括对高维数据流挖掘、去噪的修改以及对并行计算的增进。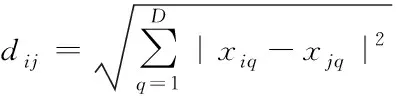
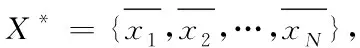
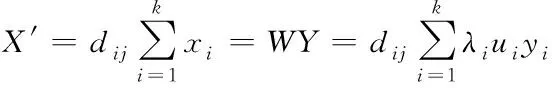
2.3 高维数据流相关性并行计算方法



3 实验分析

3.1 挖掘性能分析

3.2 数据去噪分析

3.3 并行计算分析



4 结论
