多级特征融合下的高精度语义分割方法
2021-11-16王晓华叶振兴王文杰
王晓华,叶振兴,王文杰,张 蕾
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
图像语义分割是图像理解中的一项基本任务,其目标是为输入图像中的每个像素分配一个类别标签,对图像进行像素级分类。因而在图像场景理解[1]、弱监督语义分割[2]、视觉跟踪、场景分析[3]、视频处理和医学图像分析[4]等领域都得到了广泛应用。
近年来,卷积神经网络(convolutional neural networks,CNN)极大地增强了图像的理解能力,基于深度学习的语义分割方法受到国内外学者的广泛关注。研究者在CNN的基础上丢弃全链接层,提出了全卷积网络(fully convolutional network, FCN)[5]。FCN可以处理任意分辨率的图像,成为最流行的语义分割网络结构;文献[6-7]在FCN中采用扩张的卷积层,来增加特征提取网络中的感受野;文献[8-10]在FCN的基础上设计了基于编码器-解码器的网络结构,编码器用以降低特征映射的分辨率,解码器用来提高特征映射的采样以恢复分辨率;文献[11]提出在实际应用中,编码器的下采样容易丢失高分辨率特征;为了获取高分辨率特征,文献[12]中U-Net为解码器提供了具有相同分辨率的编码器特征图;文献[13-14]中HR-Net通过简单的卷积网络来维护高分辨率的特征图,并通过拼接来融合不同分辨率的特征图;DeeplabV3+[15]中采用跨层融合的思想,将浅层细节特征与深层抽象特征结合起来,提高高分辨率细节信息的分割精度;PSP-Net[16]引入了金字塔池化模块(pyramid pooling module,PPM),能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。虽然上述方法增强了特征的表现力,但是在小目标物体分割和物体边缘分割精度上仍有待提升。
针对小目标物体分割不精细和物体边缘分割模糊的问题,本文提出了一种基于多级特征融合的高精度语义分割方法。该方法采用编码器-解码器网络结构,编码器采用MobileNetV3[17]网络,利用MobileNetV3中的深度可分离卷积的结构和非线性h-swish激活函数,可以提取多级浅层级轮廓特征和深层级语义特征的能力;解码器采用PSP-Net模型的解码网络,该解码网络中的金字塔池化模块有较好的全局特征提取能力。该方法通过跳接的方式将编码器提取到的多级特征输入到PSP-Net模型的解码器中,利用级联融合的方式[12]将输入特征进行金字塔池化和多级特征融合,最终得到更精细的语义分割结果。
1 PSP-Net模型
图1所示为PSP-Net模型结构,其中编码器是由带空洞卷积的Res-Net101网络[16]构成,输出Res-Net101的最后一层特征图;解码器前端为PSP-Net模型的核心部分PPM,其具有4个不同尺度的特征提取器,它能够聚合不同区域的上下文信息,有效获取全局特征信息;解码器后端通过1×1卷积调整通道,最终输出语义分割图。

图1 PSP-Net模型的结构Fig.1 Structure of the PSP-Net model
因PSP-Net的解码器输入的特征层仅为编码器输出的最后一层特征图,这样会产生输入到解码器网络中的特征信息不充分、小目标物体在分割时易丢失的问题。所以要重新选择或设计编码器网络来解决此问题。
2 MobileNetV3网络
MobileNetV3网络在MobileNetV2网络上进一步改进,在BottleNeck[17]模块的深度卷积操作后增加了Squeezing和Excite模块[18],同时引入了轻量级注意力模型,用来调整每个通道的权重。
Benck是MobileNetV3网络中特征提取的基本残差结构,实现了通道可分离卷积加SE通道注意力机制与残差连接[19]等功能,MobileNetV3独特的Benck结构如图2所示。
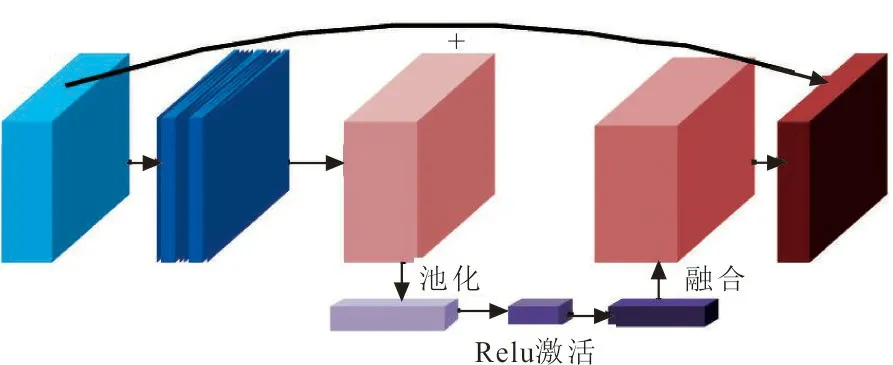
图2 MobileNetV3网络的Benck模块Fig.2 Benck module of MobileNetV3 network
在MobileNetV3网络中,当输入特征和输出特征的维度不同时,需要通过1×1卷积调整输入特征的维度,然后与Benck模块的输出特征相融合,得到融合的特征图。Benck模块中的残差学习单元主要作用是在训练过程中不断进行前向传播,加深网络层次,提取网络中的浅层轮廓特征信息,同时避免梯度爆炸。此外,还利用可以跳接的方式获取其他Benck的更多细节的深层语义特征信息。
由于MobileNetV3网络可以提取多级浅层轮廓特征和深层语义特征,获取的特征信息丰富,所以可以作为语义分割网络的编码器。
3 多级特征融合语义分割算法
3.1 编码器网络
本文方法的编码器采用MobileNetV3网络,主要提取多级特征信息,其结构如图3所示。

图3 编码器网络结构Fig.3 The network structure of the encoder
图3中,各个颜色层皆为不同尺度大小的Benck模块,模型的输入图像的像素大小为S;f1、f2、f3、f4和f5层分别表示大小为原图1/2、1/4、1/8、1/16和1/32的特征图层。在CNN中,随着网络的不断深入,特征表示的兴趣点逐渐从局部特征转向全局特征[20]。因此,对于一些中间网络层,它是局部轮廓特征和全局语义特征之间的最佳转折点。为了防止输入特征图的信息落入局部最优的情况,将f1层和f2层舍弃。最后,选择f3、f4和f5层作为编码器的多级输出特征图层,即为解码器的输入,通过跳转连接到解码网络。
3.2 解码器网络
解码器网络的主要任务是通过上采样操作对未放大的特征图进行大小调整,然后利用PPM对编码器网络中的特征图进行融合,文中方法的解码网络如图4所示。主要的操作过程是调整f3、f4、f5特征图的大小,并进行特征融合。

图4 解码器网络结构Fig.4 The network structure of the decoder

3.3 模型算法描述
通过上述对编码器-解码器的改进与设计,最终得到的模型结构如图5所示。

图5 模型的整体结构Fig.5 The overall structure of the model
在编码阶段,模型采用MobileNetV3网络对特征进行提取,计算公式为
fn=Cn(fn-1)=Cn(Cn-1(...C1(I)))
(1)
式中:输入的图像为I;Cn为编码器MobileNetV3中的第n个Bneck模块;fn为第n层的特征图。
在解码器阶段,进行特征融合迭代,融合迭代的过程可表示为
(2)
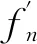
在特征融合后,解码器将得到的特征图计算各个部分的概率,计算公式为
(3)
式中:Pn~Pn-k为中间层的细化操作;D为将所有的特征图像融合在一起,得到最终的分割结果。
4 实验与分析
该实验基于Tensorflow-GPU框架,操作系统为Windows10环境,GPU是NVIDIA RTX 2 080 Ti。并在Pascal-VOC2012数据集和Nyu-V2数据集上进行实验,验证文中方法的合理性。
4.1 数据集及评价指标
Pascal-VOC2012数据集中训练集包含1 464幅图像,验证集包含1 449幅图像,测试集包含1 456幅图像。数据集包含20个对象类和一个背景。同时,使用图像增强的方法对数据集进行扩展[8],得到10 582张训练集图像。
NYU-V2数据集中包含精确分割的1 449张室内图像,以及407 024张未标记的图像,共849个分类。对于分割任务来说,849个类太多,不利于算法效果的验证和比较,通用的处理方法将894个小类变化为40个大类[22]。随机选择795张图像作为训练集,其余654张图像作为测试集。
本文使用平均交并比(mean intersection over union, MIOU)和平均精度(mean pixel accuracy, MPA)来评估模型的效能,MIOU和MPA分别反映语义分割精度和精度的鲁棒性。MIOU用于评价算法精度,可表示为
(4)
式中:U为MIOU的计算结果;k为前景对象的个数;pii为第i类预测为第i类像素量;pij为原本属于第i类却被分类到第j类的像素量。
MPA用于评价各个类别的像素准确率的平均值,可表示为
(5)
式中:A为MPA的计算结果。
4.2 模型训练
模型采用编码器-解码器结构,且涉及图像语义分割,所以模型的损失函数包括3部分:编码器类别损失函数LE,1,解码器融合损失函数LE,2,语义分割置信度损失函数LDice。

(6)
式中:l为类数;0≤j≤l-1;β为L2范数的增益系数。
β∑‖ω‖2
(7)
式中:l为分类数;0≤j≤l-1;β为L2范数的增益系数。
采用Dice-Loss函数作为语义分割损失函数,表示为
(8)

选用Pascal-VOC2012和NYU-V2数据集进行模型训练,设置优化器为Adam优化器;学习率采用指数衰减,设置不同的迭代的学习率:在0~30代阶段,学习率设置为10-4,31~60代阶段,学习率设置为10-5;L2范数增益参数设置为10-4;平滑因子ε设置为10-5。其训练过程如图6所示。

图6 模型训练损失值的变化Fig.6 The loss of value during the model training
从图6可以看出,在30代后,总损失值下降更快,训练到50代时,模型达到收敛。
4.3 结果与分析
将文中方法模型与SEG-Net模型、PSP-Net模型、DeeplabV3+模型进行性能比较,并在Pascal-VOC2012数据集和Nyu-V2数据集上进行验证。
4.3.1 Pascal-VOC2012数据集 表1给出了在Pascal-VOC2012数据集上的实验对比结果。

表1 不同模型在Pascal-VOC2012数据集的对比Tab.1 Comparison of different models in Pascal- VOC2012 dataset 单位:%
从表1可以看出,本文方法模型在MIOU上较DeepLabV3+性能提高了2.1%,较PSP-Net模型提高了5.1%,较SEG-Net模型提高了10.9%。这是因为该模型采用多级的特征信息,网络被利用的信息更加丰富,特征更好地被保留,使得分割精度结果更高。
为了更加直观地体现本文、方法模型性能的提升,从验证集中选取具有代表性的6幅图像(飞机、牛、鸟、人与马、汽车、多人)进行可视化结果分析,图7给出了不同模型分割结果的对比。图7(a)为输入图像、图7(b)中,目标分割的效果不好,边缘轮廓信息存在丢失和重叠的问题;图7(c)中,对光照复杂场景的分割效果不理想;在图7(d)中,分割效果比较完整,但对一些小目标物体的边缘信息存在部分丢失的问题;在图7(e)中,对于每个对象的分割都有完整的轮廓,边缘细节更清晰。

图7 不同模型在Pascal-VOC2012数据集的分割效果Fig.7 Segmentation effect of different models in Pascal-VOC2012 dataset
4.3.2 Nyu-V2数据集 表2给出了在Nyu-V2数据集上的实验对比结果。

表2 不同模型在Nyu-V2数据集的对比Tab.2 Comparison of different models in Nyu-V2 dataset 单位:%
从表2可以看出,本文的方法模型的MPA达到了74.91%,MIOU达到74.20%。这是由于该模型在编码器端引入级联的结构,将浅层的轮廓特征信息与深层的语义特征进行融合,使得结果更加精细、轮廓更加清晰。
同样,在Nyu-V2数据集中选取具有代表性的6幅图像(厨房、灶台、客厅、柜子、卧室、电视柜)进行可视化分析,图8给出了不同模型分割结果的对比。
从图8可以看出,在“灶台”图像中,文中方法模型相较于其他模型可以更清晰地分割出原图中的香料瓶等小目标物体,小目标物体分割更加精细;“客厅”图像中,图8(e)中灯的边缘更加连续清晰,同时受光照影响较小;在“柜子”“卧室”和“电视柜”图像的结果可以看出,图8(e)的物体边缘分割更流畅、更精细。由上述实验结果可知,文中方法模型性能指标更好,在物体边缘分割精度和小目标物体识别分割性能方面有很大提升。

图8 不同模型在Nyu-V2数据集的分割效果Fig.8 Segmentation effect of different models in Nyu-V2 dataset
5 结 语
为解决语义分割中小目标模糊和边缘特征不连续性的问题,本文提出了一种基于多级特征融合的高精度语义分割方法。该方法利用MobileNetV3网络构建了编码器结构,使得该方法提取了多级特征,有效地丰富特征信息。采用PSP-Net网络中的空间金字塔池化结构来有效地解决边缘不连续问题。在编码器端,构建多级的特征提取通道,保持了网络的高分辨率,增强细节特征的表达;在解码器端,将多级的浅层的轮廓特征信息与深层的语义特征进行融合,获得高质量的特征信息,从而构建适合小尺度目标分割的高分辨率语义分割方法。实验结果表明,该算法不仅对小目标分割有显著效果,而且被分割的物体边缘更加的精细。此外,中间层的特征信息对分割结果的影响程度仍是一个有待讨论的问题,这将在今后的工作中进一步讨论。
