热图引导连接的人体姿态估计方法
2021-11-16王仓龙刘沫萌
王 伟,王仓龙,裴 哲,刘沫萌
(西安工程大学 计算机科学学院,陕西 西安710048)
0 引 言
人体姿态估计旨在根据图像预测每个人的关键点位置。实际应用十分广泛,包括动作识别[1]、行人重识别[2]及人机交互[3]等。随着深度学习的发展,卷积神经网络在人体姿态估计领域所表现出的性能远高于其他传统方法,例如概率图模型[4]或图结构模型[5],并且近年来的研究表明,基于热图引导来预测关键点的方法[6-8],预测的精度远优于直接对关键点位置的预测[9-10],而获得关键点位置后,更重要的是如何将关键点连接为人体姿态数据。
目前人体姿态估计方法主要分为:自上而下(Top-down)和自下而上(Bottom-up)。Top-down首先检测人体,使用前置的目标检测网络标识出画面中人体的边界框(bounding-box,b-box)[11],该方法将多人人体姿态估计问题转化为单人人体姿态估计[12-15]。文献[16-17]提出的HRNet通过多分辨率融合以及保持高分辨率的方法极大的提高了关键点的预测精度。由于Top-down在目标检测阶段就消除了大部分背景,因此很少有背景噪点或者其他人体的关键点,简化了关键点热图估计,但是在人体目标检测阶段会消耗大量的计算成本,并且不是端到端的算法。
与之相反,Bottom-up首先预测图像中所有人体关键点位置,然后将关键点链接为不同的人体实例。代表性工作有:DeepCut方法和DeeperCut方法开创性地将关键点关联问题表示为整数线性规划问题[18-19],可以有效求解,但处理时间长达数小时。而Openpose方法基本可以做到实时检测,其中的PAF组件用来预测人体部件,连接可能属于同一人体的关键点[20],并且PifPaf方法对该方法进一步拓展,提高了连接的准确度[11]。Associative embedding方法将每个关键点映射一个识别对象所属组的“标签”,标签将每个预测的关键点与同一组中的其他关键点直接关联,从而得到预测的人体姿态[21]。PersonLab方法采用短距偏移提高关键点预测的精度,再通过贪婪解码和霍夫投票方法的分组,将预测的关键点联合为一个姿态估计实例[22]。Bottom-up普遍比Top-down算法复杂度低、速度更快,并且这是端到端的算法,本文所使用的方法属于此类。此外热图回归广泛应用于语义标注的关键点定位,例如:人脸[23]、手部[24]、人体[25]或者日常物品[26]的关键点,目前高斯核覆盖所有的关键点使用固定标准差,然而在Bottom-up方法中,图像中的人体尺度普遍存在多样性,若可根据不同人体尺度调整每个关键点的标准差,可以取得更好的回归效果。
基于此,本文提出了一种基于热图引导的人体姿态估计方法,其中主要创新点:①将预测的关键点热图和特征表示相结合,使用热图引导像素级关键点回归,从而获取更高的回归质量;②其中在热图回归阶段,受Focal loss方法的启发[27],提出一种尺度自适应热图估计,用来自适应学习处理局部特征的尺度多样性;③在关键点分组之后,提出一种基于姿态结构和关键点热值评分网络,预测每个估计的姿势与真实姿态数据拟合的程度,用来提高姿态的预测精度;④考虑到热图的背景噪点问题,重新设计了相关的热图估计损失函数,从而进一步提高热图估计质量。
1 HGC人体姿态估计方法
基于当前的研究,与主流的Bottom-up方法相同,先检测关键点再给关键点分组。在获取到一张图片之后,多人人体姿态识别估计旨在预测出图像中的一组人体姿态实例:{P1,P2,…,Pn,…,PN},共N个人体实例,Pn为第n个人体实例,其中每个人体姿态Pn={pn1,pn2,…,pnk,…,pnK}由K个关键点组成,方法框架如图1所示。
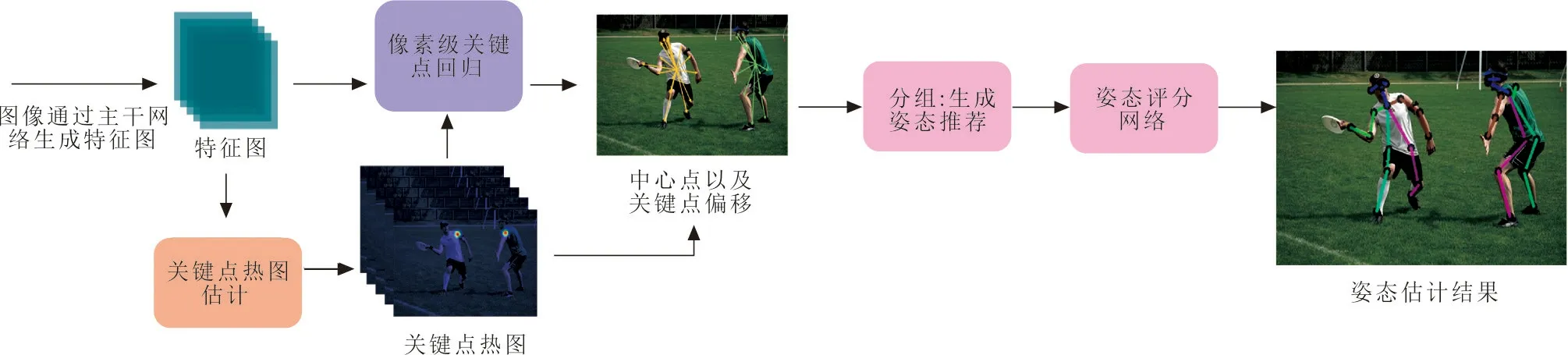
图1 基于HGC的人体姿态估计方法框架Fig.1 The framework of human posture estimation based on heatmap-guided connection
在获取到图像之后,首先通过主干网络提取出图像的特征图,神经网络所提出的特征图无法直接读取图像中的语义信息,因此使用关键点识别头提取特征图中的关键点热图信息,其中关键性的技术为尺度自适应热图估计和遮罩损失。然后在热图的监督下,再使用像素级关键点回归头提取出特征图中,图像里各个实例的中心点,以及中心点到各个关键点的偏移,此处的偏移到真实关键点的误差较大,仅作为后续关键点分组的依据。
对于同一个人体实例,HGC方法用分组依据以及关键点热图,预测出多个人体姿态数据,将其作为姿态推荐,然后通过学习出的姿态评分网络对姿态推荐进行评估,最终在姿态推荐中选取得分最高,也就是最拟合真实姿态的人体姿态数据,作为最终预测结果。
1.1 关键点生成
输入图像首先通过主干网络(如HRNet-W32)生成特征图F,通过F得到关键点热图及像素级关键点回归,其中关键点热图H={h1,h2,…,hk,…,hK}由K个局部热图组成,其中hk为第k类关键点的单类热图,每次只识别一类关键点,通过多次识别之后,将识别结果汇总重合就得到一张检测关键点热图H。
像素级关键点回归由2部分组成:中心热图C和关键点偏移图O。C的每个点是当前人体n整体中心点的置信度。O中包含2K个子图,显示为关键点k到姿态中心c的偏移量o。
1.1.1 热图引导的像素级关键点回归 得到特征图F之后,通过关键点识别头处理后生成关键点热图H。在以往对关键点偏移的研究中[28-29],预测中心热图C和关键点偏移图O仅使用主干网络生成的特征图F,设计了一种新的像素级关键点回归头,将上一步生成的关键点热图H用来引导中心热图C和偏移图O的生成。
HGC方法的优势是通过关键点热图的引导,将像素级关键点回归中关键点偏移图的误差,从一个人体实例整体的尺度,降低到了一个关键点热图局部的尺度,对偏移图精度的提升显著。
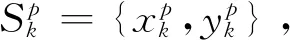
(1)
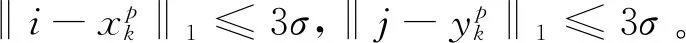
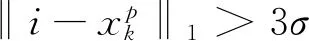
(2)
式中:‖·‖2为L2-范数;M为对应着K个关键点遮罩上的权值。
1.1.3 尺度自适应热图估计 在以往的研究中,对所有的关键点构造热图时,高斯核函数一般会用固定的标准差σ0,用来生成真实热图Hσ0。然而不同尺度的关键点也应该具有不同尺度的语义信息,因此文中希望将高斯核函数设置为具有异化的标准差,以在不同尺度关键点的情况下去覆盖其中尺度的语义信息,然而对数据集上不同尺度的关键点手动标注尺度信息是几乎不可能的,因此希望模型可以自适应调整σ以应对不同尺度的关键点。
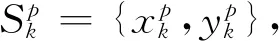
(3)
(4)
Hσ0·d就是尺度自适应的热图估计,通过对原始热图进行元素乘积操作获得,实现难度较低。对于缩放因子大于1的关键点,自适应标准差将大于σ0,该高斯核函数覆盖的区域也将变大,否则将变小。因此,在某种程度上,尺度因子也反映了相应人体实例的尺度。
此外,在训练尺度预测网络时,同样需要考虑背景噪点的影响,所以同样对损失函数进行遮罩操作,则尺度自适应损失函数Ls为
(5)
最终得到总热图损失函数LH为
LH=Lm+λ1Ls
(6)
式中:λ1为尺度自适应热图的权重,在训练中,λ1=1。
尺度自适应热图与固定标准差热图的对比如图2所示。
在图2(a)中,预测人体实例的右肩点时,高斯核函数使用的标准差是固定的,即便是图像中人体实例尺度相差较大,所回归出的关键点热图是固定的,而在图2(b)中,人体实例由于距离的不同导致其在尺度上也存在较大的差别,在回归左肩关键点的热图时,根据尺度自适应调整高斯核函数的标准差,显然尺度较小的人体实例热图精度得到了提升,因此提高整体的关键点回归精度。

(a) 固定标准差
1.1.4 像素级回归损失 在像素级关键点回归损失LP中采用归一化的平滑L1损失:
(7)
(8)
将像素级关键点回归损失和热图损失汇总后,得到最终损失函数为
L=LH+λ2LP
(9)
式中:λ2为像素级回归损失权重,考虑到像素级关键点回归仅作为后期的分组提示,因此令λ2=0.01。
1.2 最终姿态生成
1.2.1 分组 输入所需要预测人体姿态图像,首先计算关键点热图H,以及像素级关键点回归结果(C,O)。然后使用非最大抑制找到一组30个关键点推荐集S={S1,S2,…,Sk,…,SK},其中每个Sk由关键点热图H中选取的第k个关键点的推荐组组成,同时删除其中热值太小(小于0.01)的点。同样,HGC方法也通过非极大抑制在中心热图C中筛选出像素级关键点回归的结果,从而得到M组(M=30)回归结果:{G1,G2,…,Gm,…,GM},其中每个Gm含有K个关键点。
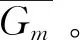
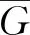
2 实验结果与分析
2.1 数据集和实验环境
COCO数据集是微软发布的大型图像数据集[31],专为对象检测、分割、人体关键点检测、语义分割和字幕生成而设计,本文研究基于COCO数据集中目标关键点集进行训练和测试。COCO数据集包含超过2×105幅图像和2.5×105个带有17个关键点的人体实例。本文在COCO Train2017数据集上训练模型,包括5.7×104个图像和1.5×105个人体实例。Val2017集包含5 000幅图,test-dev2017集则包含2×104幅图像,并在Val2017和test-dev2017上进行评估。
在Ubuntu 18.04上使用Python 3.6开发,基于Tensorflow平台实现,使用1个NVIDIA GPU。
2.2 评价指标
标准的评估指标是基于图像关键点的相似性OKS评分,核心指标是关键点的预测精度和召回率,设关键点相似评分为KOS,其公式为
(10)
式中:di为检测到的关键点和相应的关键点真值之间的欧式距离;vi为真实值的可见性;s为物体的尺寸;ki为每个关键点控制衰减的常量。
评价指标主要为标准平均精度(average precision,AP)和平均召回率(average recall,AR)。本文主要采用以下指标,AP (KOS=0.50,0.55,…,0.90,0.95的平均精度),AP50(KOS=0.50的精度),AP75(KOS=0.75的精度),APM表示中等尺度目标的精度,APL表示大尺度目标的精度,AR(KOS=0.50,0.55,…,0.90,0.95的平均召回率)。
2.3 训练过程
在文献[21]的实验中,使用随机旋转平移等的优化方法,使AP从0.566提高到了0.628,增加了多尺度测试后AP更是提高到了0.655,故数据增强遵循文献[21]中的方法,包括随机旋转([-30°,30°]),随机缩放([0.75,1.5]),随机平移([-40,40]),将图像裁切到512×512(对于HRNet-W32)和640×640(对于HRNet-W48和HrHRNet-W48),同时设置随机翻转。
训练时使用Adam优化器[32],基础学习率设置为10-3,随后在90次和120次的时候将学习率设置为10-4和10-5,总共训练140次。
2.4 实验结果
2.4.1 Val2017结果 表1展示了HGC方法与其他比较具有代表性方法的参数值和计算复杂度,使用HRNet-W32等作为主干网络,其中复杂度计算单位为每秒109次的浮点运算数(giga floating-point operations per second,GFLOPs)。

表1 参数量、复杂度对比Tab.1 Comparison of parameters and complexity
从表1中可以看出,HGC的参数量和复杂度都保持在低水平,在主干网络为HRNet-W32时,与目前最先进的算法HrHRNet[33]的相比,参数量为其51%,复杂度仅有42%,即便是在主干网络为HrHRNet-W48时,参数量和复杂度也保持在与HrHRNet[33]相似的水平,但在表2中相对的准确度有了显著提升。
本文HGC方法与其他方法的AP/AR指标比较如表2所示,其中缺失值使用“—”填充。
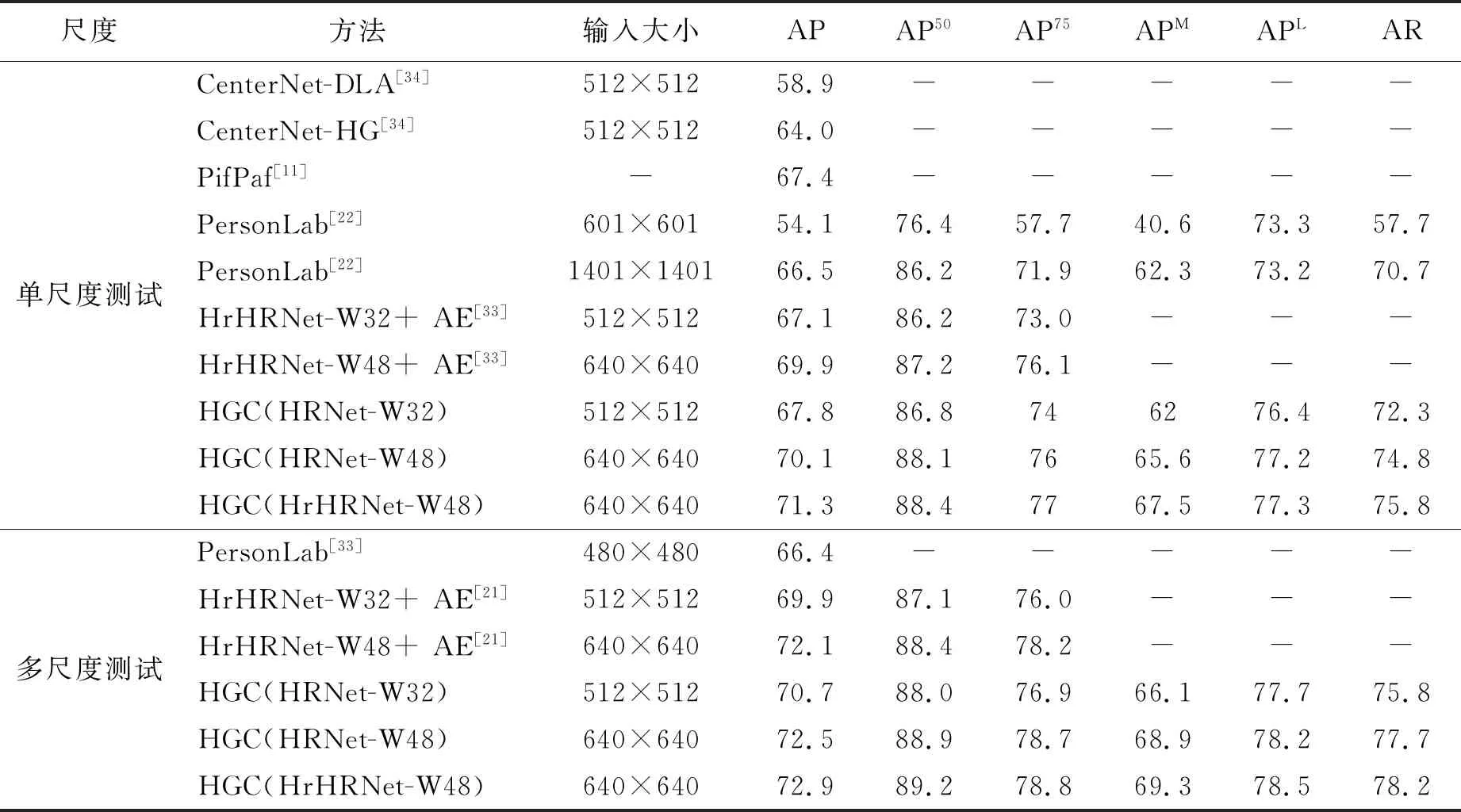
表2 在COCO Val2017上的实验对比Tab.2 Comparison on the COCO Val2017 dataset
从表2可以看出,单尺度测试中,HGC方法在主干网络为HRNet-W32时,AP达到了67.8,与HGC复杂度相近的方法对比,如CenterNet-DLA方法和低分辨率PersonLab方法,AP提高了8.9。而对于模型参数量远大于HGC(主干网络HRNet-W32)的方法,如CenterNet-HG方法,依旧提高了3.8。在HGC方法中,更高分辨率的图像输入、更高的模型参数和更高的分辨率特征有助于获取更好的表现,当主干网络为HRNet-W48,并且将输入尺寸提高到640×640, AP达到了70.1,比主干网络HRNet-W32高出2.3。与其他表现优秀的方法相比,如CenterNet-HG方法,高出6.1,比高分辨率PersonLab方法高出3.6,并且与PifPaf方法相比,在复杂度指标GFLOPs仅为其一半不到的情况下,AP值高出了2.7。另外训练了在高分辨率输入下(主干网络HrHRNet-W48)的模型,比主干网络HRNet-W48提高了1.2。同样,实验验证了HGC方法在多尺度测试中的表现,与单尺度测试相比,AP在HRNet-W32中提高了2.9,HRNet-W48提高了2.4,在HrHRNet-W48中提高了1.6了,此外姿态估计效果如图3所示。

图3 HGC方法人体姿态估计定性结果Fig.3 Qualitative results of human pose estimation by HGC mthod
图3中的图像选自Val2017,用HGC预测其姿态,其中涵盖了黑白、彩色、单人、多人、多尺度和遮挡等多种在现实中具有代表性的常见情况。可以看出HGC方法在实际应用中表现出了良好的鲁棒性和准确性,可以准确地分辨出不同人体实例的关键点,并且关键点的位置基本符合先验的常识。
2.4.2 test-dev2017结果 在test-dev2017数据集AP/AR指标对比如表3所示,缺失值使用“-”填充。
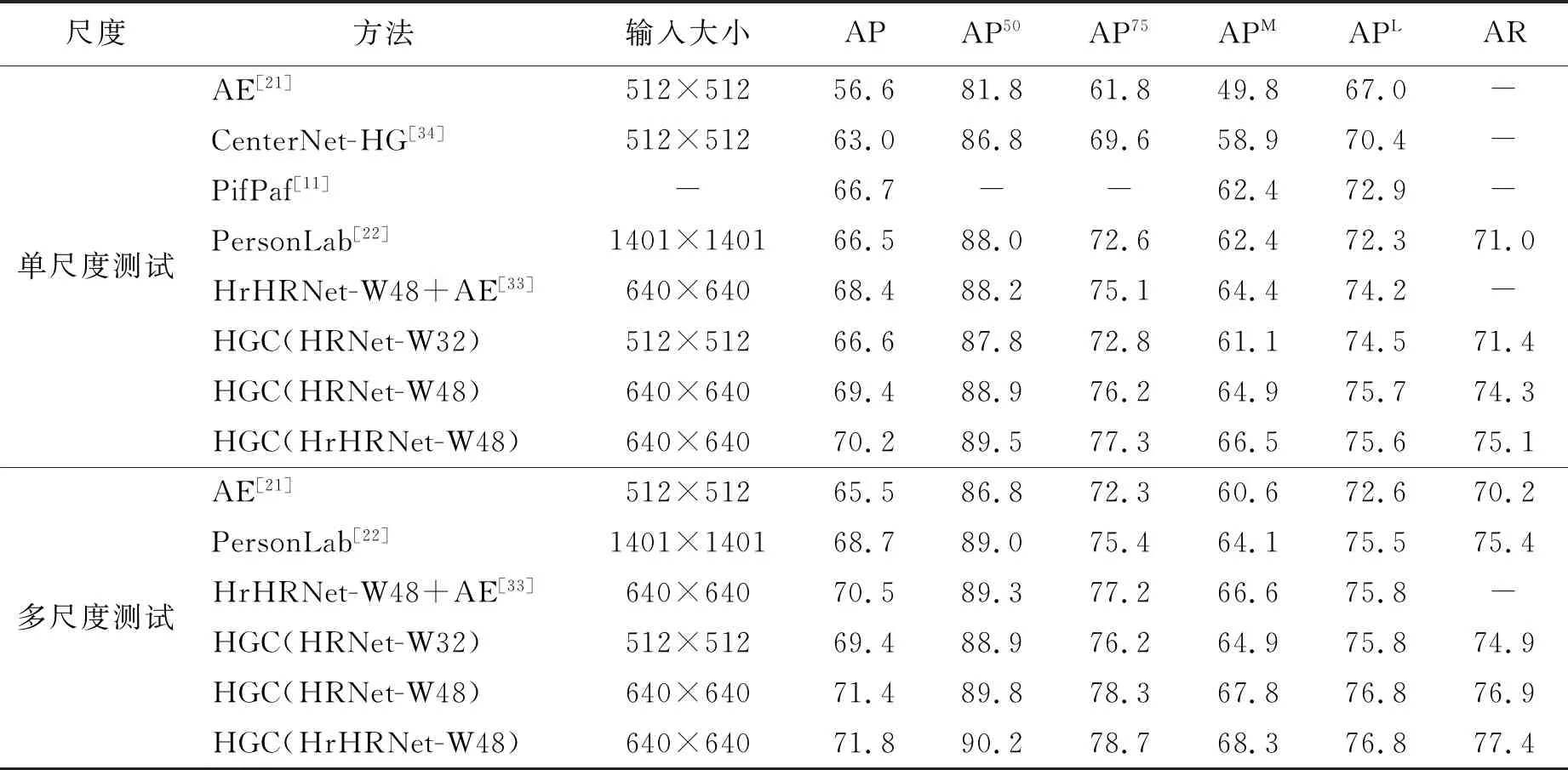
表3 在COCO test-dev 2017上的实验对比Tab.3 Comparison on the COCO test-dev 2017 dataset
从表3可以看出,单尺度测试中,在主干网络HRNet-W32中AP达到了66.6,显著优于复杂度类似的方法。在主干网络HrHRNet-W48中达到了最优AP,为70.2,比Personlab方法高出3.7,比PifPaf方法高出3.5,并且比HrHRNet方法高出1.8分。在多尺度测试中,即便是主干网络HRNet-W32的AP也高达69.4,优于Personlab方法的大分辨率模型,在主干网络HrHRNet-W48中达到了最高AP,为71.8,比AE方法高出6.3,比PersonLab放啊高出3.1,比HrHRNet方法高出1.3。
2.4.3 消融学习 本文研究了各个组件对于HGC的影响:①热图引导像素级关键点回归;②遮罩损失;③热图尺度自适应;④姿态推荐评分网络。本文选取了3个指标分析以上组件对整体的影响:像素级关键点回归质量、热图估计质量以及最终的姿态估计质量。像素级关键点回归质量是直接使用回归结果并对其AP分数进行评估所得。热图估计质量通过以真实姿态作为分组依据,对热图所检测到的关键点分组所得姿态评估,即用真实姿态替换回归姿势,最终质量是HGC方法整体的质量。消融学习结果列于表4,表中标注为“使用”则表示为使用了该组件的评估结果,“-”为未使用。
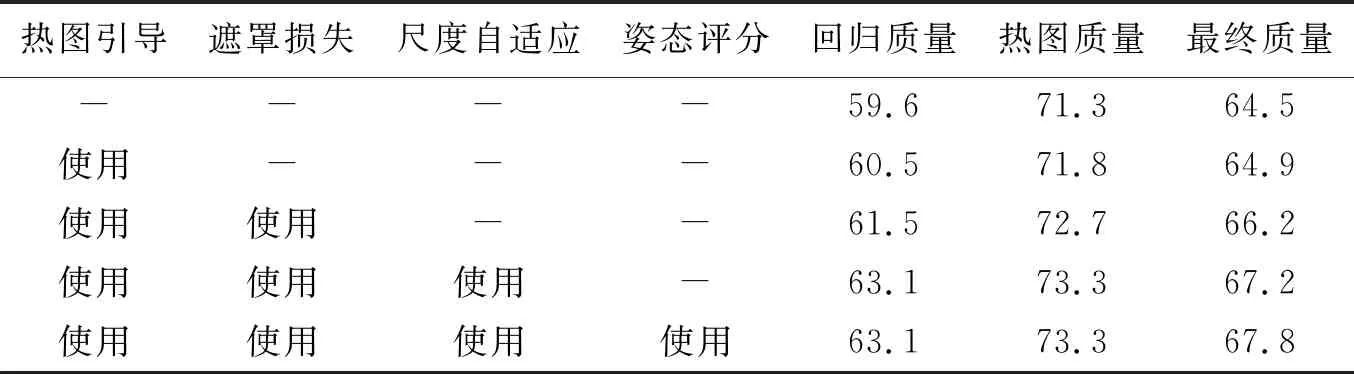
表4 消融学习Tab.4 Ablation study
表4中,热图引导确实促进了像素级关键点回归的精度,回归质量提高了0.9,并且使最终质量提高了0.4;遮罩损失对热图质量的提升显著,高达0.9;热图尺度自适应对热图质量也提高了0.6,并且对最终质量也提升了1.0;姿态推荐评分网络通过对预测出的姿态推荐进行评分排序,选出最优的姿态估计,最终估计质量因此也获得了0.6的增益。
3 结 论
1) 本文给出一种基于热图引导像素级关键点回归。
2) 用遮罩损失对热图损失加权,提高了热图估计的精度。
3) 进一步提出的尺度自适应热图估计可以很好地处理图像中人体的尺度上的多样性。
4) 得出一个评分网络来促进在姿态推荐中选取更加贴近图像中真实的姿态。
