融合文本信息的多模态深度自编码器推荐模型
2021-11-16陈金广徐心仪范刚龙
陈金广,徐心仪,范刚龙
(1.西安工程大学 计算机科学学院,陕西 西安 710048;2.河南省电子商务大数据处理与分析重点实验室, 河南 洛阳 471934;3.洛阳师范学院 电子商务学院,河南 洛阳 471934)
0 引 言
随着大数据时代的到来,推荐系统作为缓解信息过载的重要技术,已经在电子商务[1]领域广泛应用。为了提供更好的个性化推荐服务,准确地预测用户对商品的评分是推荐系统需要解决的关键问题。目前推荐系统领域的研究方向主要分为基于内容[2]的推荐、基于协同过滤[3-4]的推荐和混合推荐[5-6]3种。但是,传统矩阵分解算法[7]难以适应当前复杂的环境。近年来,深度学习技术飞速发展并在图像等领域取得巨大的突破,越来越多的学者将深度学习技术应用到推荐系统中[8]。
在基于深度学习并结合文本信息的推荐方法中,关键是获取文本信息的上下文。在提取上下文特征方面,KIM等提出一种上下文感知的卷积矩阵分解模型[9],该模型将卷积神经网络融入概率矩阵分解模型中,提高了预测评分的准确性,但在感知上下文方面存在较大欠缺。LIU等提出了基于循环神经网络(RNN)的CA-RNN模型[10],该模型引入了具有上下文感知的输入矩阵和具有上下文感知的转移矩阵,能够较好地感知上下文,但是在联系双向上下文信息方面效果并不显著。DEVLIN等提出BERT(bidirectional encoder representation from transformers)模型[11],该模型可以融合双向上下文信息,进一步地融合句中语义信息,从而更好地提取含有上下文信息的特征表示;在学习上下文特征方面,HOCHREITER等提出了长短时记忆网络模型(long short-term memor,LSTM)[12],该模型只能获得与前词相关的前文信息,无法获得上下文相关信息。ZHENG等在LSTM的基础上提出双向长短期记忆网络模型(bidirectional long short-term memory,BiLSTM)[13],该模型通过设计前后2个方向的LSTM,分别获得当前词与上下文的关系。现有的推荐算法大多利用显式的评级信息进行推荐[14],但大部分平台上的用户只产生用户浏览和点击等隐式的交互信息[15],这使得传统的基于评分预测的推荐算法不能满足相关平台的需要[16]。近年来,基于用户隐式历史反馈信息的推荐算法受到了学术界的广泛关注,研究发现,隐式反馈在交互环境中可以成为显式反馈的替代[17],这就为本文利用隐式反馈矩阵作为输入进行电影推荐提供了可能性。目前,主流的结合隐式反馈的推荐模型大多基于贝叶斯个性化排名框架[18]。DU等通过增加1个社会正则化项来扩展贝叶斯个性化排名,算法同时针对用户对商品的偏好及其社会关系进行建模[19],虽然获得了比BPR更好的推荐质量,但存在建模的不确定性。PAN等在此基础上进一步提出了GBPR(group-based BPR)模型[20],这是一种将用户对项目的偏好分组进行聚合的方法,以减少建模的不确定性,提高推荐的准确性。随着深度学习的广泛应用,WU等提出协同降噪的自动编码器(denoising auto-encoders)[21],利用自动编码器技术结合隐式反馈,获得了更好的推荐效果。
本文通过BERT+BiLSTM结构提取和学习电影标题中短文本信息的上下文特征,融合文本信息做辅助推荐,解决了梯度消失和梯度爆炸的问题。隐式反馈与深度自编码器结合,通过矩阵分解,实现数据降维和特征抽取,解决了推荐过程中数据的稀疏问题。在经典数据集Movielens 100k和Movielens 1M上进行实验,平均绝对误差损失值分别降低到0.045 8和0.046 0,均方误差损失值分别降低到0.027 3和0.039 0。
1 模型构建技术
1.1 隐式反馈
在显式反馈推荐中,用户对电影的评分范围为1~5,表示用户对电影的倾向程度,分数越高,倾向程度越大。而在隐式反馈推荐中,只包括了用户对电影有评分和没有评分2种情况,反映用户对电影有倾向和暂时没有倾向。显式评分矩阵转换为隐式评分矩阵如图1所示。图1中的空白部分表示用户对电影没有评分记录。

图1 显式评分矩阵转换为隐式评分矩阵Fig.1 Explicit scoring matrix converted to implicit scoring matrix
假设m和n分别表示用户和电影的集合。定义用户电影隐式评分矩阵:
Rm×n=[rui|u∈m,i∈n]
(1)
(2)
式中:Rm×n为使用隐式评分填充的矩阵;rui表示在Rm×n中用户u对电影i的隐式评分,rui值为1,表示用户对该电影有倾向,否则没有。
1.2 深度自编码器
对于深度自编码器模型[22-23],网络结构如图2所示。

图2 深度自编码器模型网络结构Fig.2 Network structure of deep auto-encoder model
输入层为具有独热编码的稀疏二进制向量,向量传入嵌入层进行编码和特征学习。嵌入层由编码器和解码器组成,用于映射向量。其中,编码器的256维全连接层用于将高维原始数据转换到低维空间,解码器则为编码器的逆过程,将低维数据转换到高维原始空间。
在编码器和解码器之间存在隐藏层,隐藏层中使用Relu作为激活函数,其表达式为
R(e)=max(e,0)
(3)
同时,为了防止过拟合,还加入了dropout层。dropout率设置为0.1。
输出层的输出由模型的具体功能决定。本文模型中,深度自编码器的输出为用户对电影的预测评分。
1.3BERT+BiLSTM
BERT+BiLSTM结构由BERT、BiLSTM模块组成,BERT+BiLSTM结构如图3所示。图3中,BERT模型是基于多层双向Transformer的预训练语言理解模型[11],该模型由输入层、编码层和输出层3部分构成。本文利用其编码层进行字向量的特征提取,编码层是Transformer[24],即“Trm”层。“Trm”层是由多个重叠的单元组成,并且每个单元由多头注意力机制和前馈神经网络组成,单元内部的子层之间设计了残差连接,可以将上一层的信息完整地传到下一层,从而计算词语之间的相互关系, 并利用所计算的关系调节权重,提取文本中的重要特征。

图3 BERT+BiLSTM结构图Fig.3 Structure of BERT+BiLSTM
BiLSTM即双向长短期记忆网络的出现是为了解决LSTM在单向的处理中模型只分析到文本的“上文”信息,而忽略可能存在联系的“下文”信息[25]。本文使用的BiLSTM结构是由向前LSTM和向后LSTM组合而成,较单向的LSTM能够学习到上下文特征信息,更好地捕捉双向语义依赖。
2 多模态深度自编码器模型
融合文本信息的多模态深度自编码器模型结构如图4所示。

图4 模型结构图Fig.4 Model structure diagram
2.1 数据预处理
根据n个用户对m部电影的评分生成隐式反馈评分矩阵Rm×n,根据电影类型文本信息和电影标题文本信息分别生成用户-电影类型矩阵Ru×g和用户-电影标题矩阵Ru×t,3个矩阵均为由one-hot向量组成的矩阵。
2.2 模型输入
将Rm×n作为深度自编码器的原始输入,Ru×g作为模型中嵌入层的输入,将Ru×t作为BERT+BiLSTM结构的输入。
2.3 特征学习
深度自编码器对Rm×n进行1次编码解码得到评分特征Tm×n。Ru×g经过嵌入层、平滑层和全连接层进行特征学习,得到电影类型文本特征Tu×g;在BERT+BiLSTM结构中,BERT部分实现对Ru×t进行文本数据向量化和特征提取,BiLSTM部分则实现向量化特征学习,得到电影标题的上下文特征Tu×t。
2.4 特征融合
获取学习到的特征Tm×n、Tu×g和Tu×t,假设T为融合后的特征,使用函数Concatenate(简记为C)对3个特征实现特征融合,即
T=C(Tm×n,Tu×g,Tu×t)
(4)
将T再次输入深度自编码器中,对T实现二次编码解码,得到预测评分矩阵R′m×n。
2.5 模型输出
输出预测评分矩阵R′m×n,用于后续电影推荐。
3 结果与分析
3.1 数据集
为了验证本文模型的有效性,采用Movielens 100k和Movielens 1M电影评分数据集。它由明尼苏达大学的Lens研究小组提供,用于测试和验证所提出的模型和其他用于比较的模型的性能。
在读取数据后,用评分数据填充评分矩阵,以用户为行,项目为列,分别构成Movielens 100k和Movielens 1M的矩阵。Movielens 1M和Movielens 100k数据集描述信息见表1。
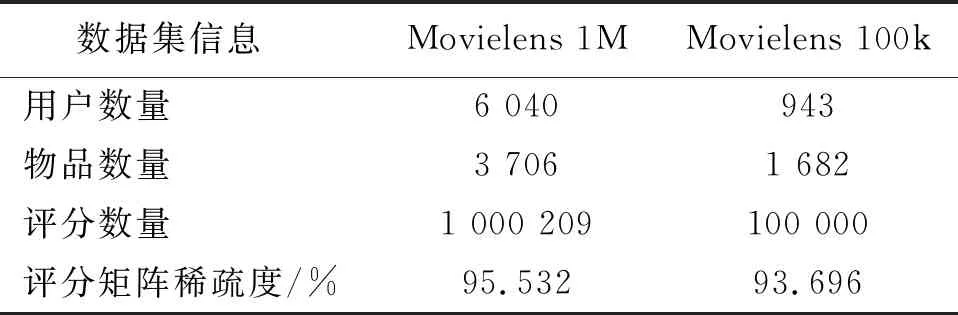
表1 Movielens 1M和Movielens 100k数据集描述信息Tab.1 Movielens 1M and Movielens 100k datasets description information
3.2 评价指标
采用均方误差(MSE,简记为EMS)和平均绝对误差(MAE,简记为EMA)评价模型的预测性能,即
(5)
(6)
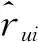
3.3 模型设置
本文模型的整体实现环境为Keras=2.2.4,Tensorflow-gpu=1.12.0。在优化器选取中,分别采用Adadelta、Adagrad、Adam、Adamax、RMSprop以及SGD等6个主流优化器进行对比实验,在不同优化器下取得的均方误差见表2。

表2 不同优化器下取得的均方误差Tab.2 MSE obtained under different optimizers
从表2可以看出,在Movielens 1M数据集下,Adam优化器取得了最低损失值;在Movielens 100k数据集下,Adagrad优化器取得了最低损失值,而Adam优化器的损失值与Adagrad优化器相差0.003 6,均方误差结果处于中等。究其原因可知,通过与Movielens 1M对比,Movielens 100k数据集的数据量过小,易造成精度过低和损失率升高,所以求取在2个数据集下MSE的平均值,以平均值作为衡量标准,得到Adam优化器明显优于其他优化器。
因此,本文模型采用Adam优化器,设置初始学习率为0.000 1,batch-size为64,在数据集MovieLens 1M和Movielens 100k的基础下训练模型。
3.4 对比实验
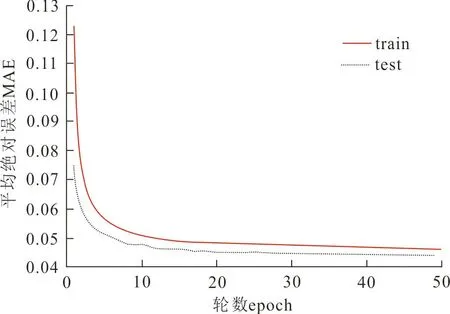
图5~6分别为基于Movielens 1M和Movielens 100k数据集,MAE和MSE在训练数据和测试数据上随训练轮数增加的变化情况。
(a) Movielens 1M
从图5~6可以看出,在Movielens 1M和Movielens 100k数据集上,随着训练轮数的增加,MAE和MSE损失值先迅速下降然后趋于平稳。究其原因可知,随着训练数据集的增加及训练轮数的增长,模型能够学习到的用户和电影的特征增多,使模型预测更准确,因此损失下降。而当模型能够学习到的特征趋于饱和时,随着轮数的增长,损失值则趋于平稳。

(a) Movielens 1M
因为SVD和PMF是依照矩阵分解原理实现推荐的传统算法以及实验条件的限制,所以选取这2种算法与本文模型进行实验对比,以MAE作为评价指标。不同模型在不同数据集上的MAE损失见表3。

表3 不同模型在不同数据集上的MAE损失Tab.3 MAE loss of different models on different datasets
从表3可以看出,在2个不同的数据集上,本文模型的结果明显优于所比较的传统算法。在本文模型中,对不同矩阵实现了针对性处理,因此在训练模型的过程中,提升了矩阵分解的效率和模型的预测效果,从而使损失值降低。但是,在Movielens 1M数据集和Movielens 100k数据集上,单个模型的MAE值差别不大,针对本文模型而言,仅相差0.000 2。原因可能在于MAE评价指标对数据集中的异常点有更好的鲁棒性,而且使用固定学习率训练模型时,更新的梯度始终相同,不利于MAE值的收敛以及模型的学习。
由于数据集较为稳定,并且MSE在固定的学习率下可以实现有效收敛,因此在MSE评价指标下,进行了更为详细的对比实验。
表4给出了本文模型、SVD、PMF、PMMMF、SCC、RMbDn及Hern的MSE损失值。

表4 不同模型在不同数据集上的平均绝对误差损失Tab.4 MSE loss of different models on different datasets
从表4可以看出,本文模型在Movielens 1M数据集的基础上进行实验时,损失值降低到0.027 3,明显低于其他对比模型的损失值。而在Movielens 100k上进行实验时,得到的损失值与RMbDn模型以0.039 0并列第一。分析原因可知,RMbDn和本文模型均使用深度学习进行推荐,能够更好地捕捉到深层次的语义信息,因此对比其他模型,取得了更好的效果;同时观察表4,发现本文模型在Movielens 100k上的损失相较在Movielens 1M上增加了0.011 7,存在较大差异。分析原因可知,Movielens 100k相较于Movielens 1M数据量小,因此在小样本下使用深度学习网络对标题、类型等文本数据的语义信息进行理解时,可能较难学习到语义信息对用户兴趣迁移的影响,从而使相同模型在不同数据集上的损失值升高。因此本文提出的模型更适合在数据量较大的情况下使用。
综上所述,与已有的主流模型相比,本文模型具有更低的损失值,说明将文本信息融合在深度自编码器中可获得更多评分预测的信息,提高个性化推荐效率。
4 结 论
1) 提出了融合文本信息的多模态深度自编码器推荐模型,在2个公开数据集上进行实验,验证了模型的有效性,达到了性能提升的效果。
2) 该模型将隐式反馈评分矩阵作为基础,使用BERT+BiLSTM结构和模型的嵌入层,实现不同文本信息的特征学习,在深度自编码器中完成不同特征的深层次融合,可明显降低推荐过程中的损失。
3) 由于显式反馈仍存在研究的价值,应考虑结合显式反馈信息进行混合推荐。
