大规模类脑计算系统BiCoSS:架构、实现及应用
2021-11-13杨双鸣郝新宇李会艳魏熙乐于海涛
杨双鸣 郝新宇 王 江 李会艳 魏熙乐 于海涛 邓 斌
1.天津大学电气自动化与信息工程学院 天津 300072 2.天津职业技术师范大学自动化与电气工程学院 天津 300222
人脑是一个由数百种不同类型的上千亿个神经元组成的极为复杂的生物组织,可处理视觉、听觉、语言、学习、推理、决策、规划等各类问题,然而,我们对脑功能相关的神经元网络结构和神经信息处理机制的解析仍极不清楚[1-4].因此,需要构建接近人脑计算能力与智能水平的类脑计算系统,从而理解人脑的结构和功能,理解认知、思维、意识和语言,探索脑疾病的发病机制与治疗方案,推动新一代类脑智能技术的发展.近年来,高性能类脑计算已经成为研究脑科学的必要手段,为脑研究开启了全新的研究视角和研究模式[5-10];反过来脑科学的研究为高性能计算提供新思路、提出新要求,催生新型计算模式的出现[11-13].人脑最简单的认知行为需要上百万个神经元的共同活动[5-7],大规模类脑计算能够将神经元电生理活动机制与认知行为联系起来,从而理解人脑认知行为的信息处理机制[14-17].总体而言,现有的大规模类脑计算与仿真研究包含三个关键问题:
1)冯·诺依曼计算架构存在计算瓶颈,与人脑计算模式存在本质区别,不能实现真正意义上的类脑.首先,冯·诺依曼计算架构将高维信息转换成纯时间维度的一维信息进行处理,无法满足处理实时复杂智能问题的需求;其次,其信息处理过程在物理分离的存储器和中央处理器内完成,造成大量的能耗损失,往复传输速率与信息处理速率的不匹配导致严重的存储墙效应,限制了类脑智能的研究与开发.
2)现有的类脑计算平台由于自身计算能力的限制,尚未解决神经元模型复杂度与神经元网络规模之间的矛盾,由具备非线性动力学特性的生物神经元组成的大规模脑功能神经元网络需要更强的并行计算能力.
3)当前的类脑计算工作忽视了神经元的动力学行为与人脑认知功能之间的联系,导致理解人脑信息处理机制的从细胞层次到认知层次信息的研究鸿沟.
近年来,各国政府、高校以及研究机构均密切关注着类脑计算这一全新领域,并从国家层面提出了一批重大研究项目.瑞士洛桑联邦理工学院和IBM联合支持了“蓝脑计划”(Blue brain project),该项目旨在通过超级计算机Blue Gene 模拟大规模神经元网络活动[18].2013年欧盟再次提出“人类大脑工程”(Human brain project,HBP),其中包括神经科学、医学与类脑计算等领域,涵盖了计算神经科学、神经信息学、人脑战略数据、高性能计算平台、大脑模拟并计算及神经机器人平台等子项目[19].同时,美国政府提出了“脑创新计划”(Brain initiative),重点从微观层面探索神经元、神经回路与大脑功能之间的关系[20].我国政府提出了“一体两翼”的脑科学战略布局,将促进中国的信息产业与工业、金融、国防等方面的迅猛发展[1-3].要实现真正、彻底的类脑智能还需要研发全新的、打破冯·诺依曼架构的计算系统[21-22].人脑智能来自于其超大规模、复杂互联的神经元网络,对与人脑大规模神经元网络的并行计算是实现类脑智能的关键[6],目前欧美等国均开展了该领域的深入研究.英国曼彻斯特大学的SpiNNaker 系统基于ARM(Advanced RISC machine)芯片构建了大规模类脑计算系统,该系统借鉴了神经元脉冲放电模式,以较少的物理连接快速传递尖峰脉冲[21],该项目目前已成为欧盟脑计划的重要组成部分.目前,IBM 公司开发出新型类脑计算系统,它采用16 颗TrueNorth芯片,TrueNorth芯片借鉴了神经元的脉冲放电原理及其信息传递机制,实现了计算存储融合的非冯·诺依曼计算架构,可执行低功耗的多目标学习任务与实时视频处理任务[6].高通公司也推出了类脑计算系统NPU,并应用于行为学习与机器人研发等领域[23].此外,德国海德堡大学作为欧盟脑计划的核心成员之一,提出了BrainScaleS 类脑计算系统,在类脑机制与高性能计算方面取得了重大的突破[24].国内在大规模类脑计算的研究领域仍处于萌芽期,中国科学院提出的深度学习系统与寒武纪系统均面向人工神经网络[25-26],这些研究均极大地提升了人工神经网络与深度学习的计算效率,降低计算功耗,然而这些计算模式仍然基于人工神经元的频率编码,网络节点无法模拟人脑神经元的复杂动力学行为,无法从人脑神经元脉冲编码的放电模式上进行更深层次的类脑智能.因此,如何借鉴人脑神经元网络的放电机制与动力学行为,克服大规模类脑计算的上述三个关键问题,提出脑启发的新型计算架构与计算模式,实现脑启发的大规模实时计算平台,是开发类脑智能、理解人类认知与实现类脑智能应用的重要手段.
本文从人脑神经系统信息处理机制出发,采用并行计算的现场可编程门阵列(Field programmable gate array,FPGA)构建了基于神经认知计算架构的众核类脑计算系统BiCoSS,实现了四百万数量级神经元的大规模类脑计算,从而更好地理解人脑工作机制与疾病机制,开发新一代类脑智能.本文的结构组织如下:第1 节总述本文所构建的系统架构及需要解决的关键问题;第2 节阐述系统计算使用的相关模型;第3 节和第4 节阐述关键技术问题的具体解决方案;第5 节展示了系统的性能;第6 节讨论了BiCoSS 系统的特色;第7 节是结论及展望.
1 系统架构
BiCoSS 系统包含7 个子系统,采用片上网络结构的改进树形结构连接,极大地增强了系统的可扩展性.以神经元为基本计算核,以神经元网络为基本计算单元,每个计算单元中包含若干计算核,计算核的数量取决于计算单元的最大计算能力.如图1所示,每个子系统包含4 个神经元网络单元和一个路由单元,每个神经元网络单元与路由单元均由FPGA实现.改进树形结构的每个节点均采用四个计算单元通过混合互联结构实现,避免了单纯使用树形拓扑结构造成的频繁的计算单元跨层级通信,减少了不必要的传播延迟和资源消耗.树形结构中每个节点的四个计算单元采用混合互连结构,四个计算单元通过路由单元与改进树形结构中其他节点相连,非顶层节点中每个计算单元可以与其余15 个计算单元通过1 个路由单元进行直接通信,顶层与底层节点中每个计算单元可以与其他7 个计算单元进行直接通信.相比较之前工作的拓扑结构,本结构更有利于进行众核并行计算系统的扩展.
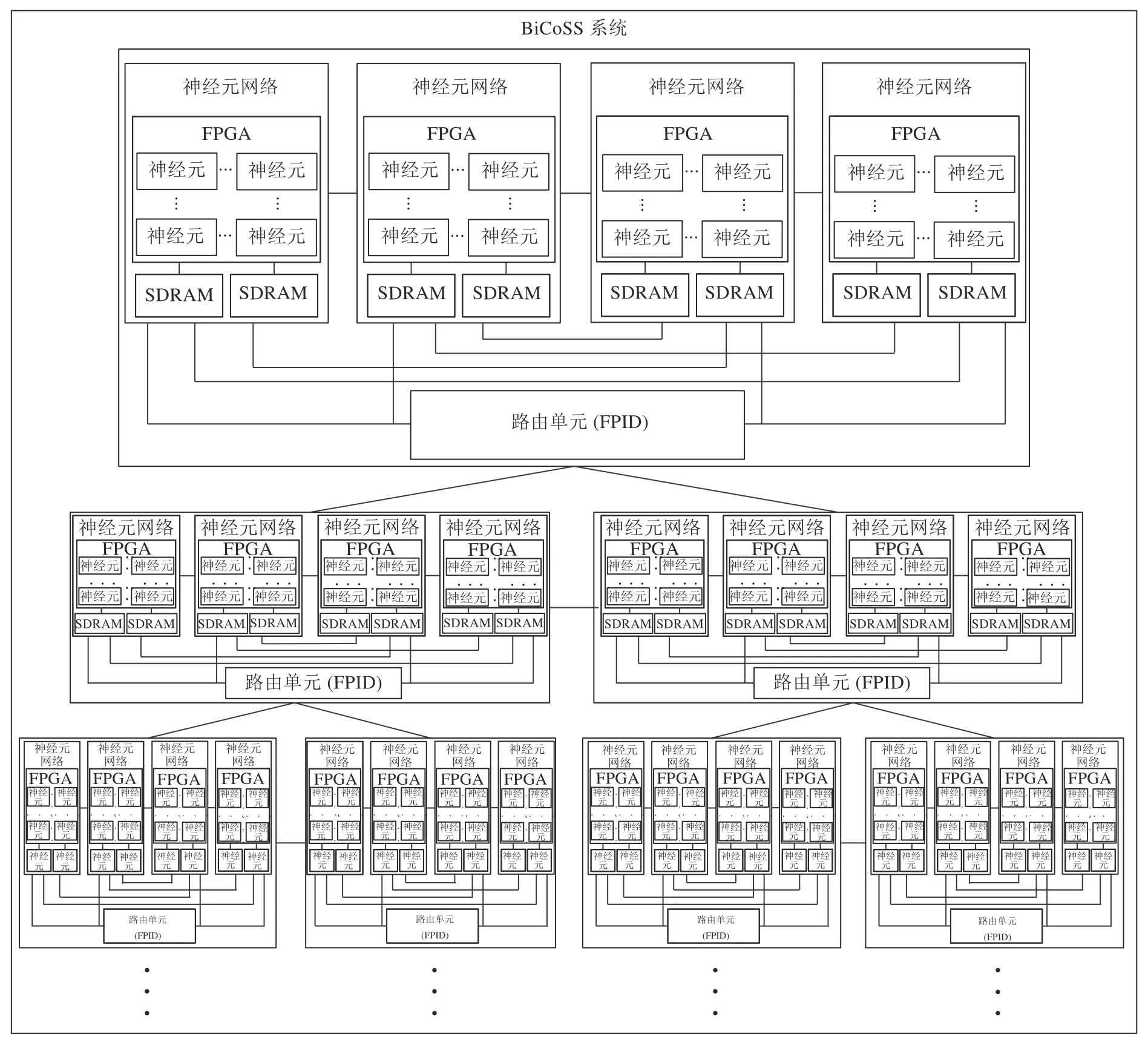
图1 BiCoSS 系统架构Fig.1 System architecture of BiCoSS
BiCoSS 系统实物图见图2,在BiCoSS 系统中,每个计算单元上包含一 片FPGA、两片SDRAM(Synchronous dynamic random-access memory)和一个用于程序存储的串行配置芯片EPCS128,SDRAM 用于存储网络计算的中间变量与网络参数,串行配置芯片EPCS128 用于在电源关闭时存储程序.并行计算的多个计算核,对于LIF(Leaky integrate and fire)或Izhikevich 神经元模型,每个神经元网络单元使用包含16 节点的蝴蝶胖树(Butterfly fat tree,BFT)片上网络结构,采用片上网络技术增强了每个计算单元上众核系统的通信效率、系统可扩展性与灵活性.此外,系统留有GPIO(General-purpose input/output)通信端口用于外接摄像头、机械臂、数模转换模块、模数转换模块等输入输出设备与外界进行数据交互.当外部输入模拟信号时,通过模数转换模块将其转化为数字信号,再通过通信端口传输到FPGA 芯片的通用IO(Input/output)引脚上,从而完成对外部信号的接收和处理;外部数字信号则可直接通过通信端口传递.同样,如果需要输出模拟信号,FPGA 的输出信号可通过通用IO 引脚传输到连接在通信端口的数模转换模块上,转化为模拟信号进行输出;数字信号可直接通过通信端口输出.利用通信端口,可以完成类脑感知与决策等实时应用开发.

图2 BiCoSS 系统实物图Fig.2 Physical map of BiCoSS
BiCoSS 神经元网络的详细计算架构如图3所示.在神经元网络计算中,BiCoSS 使用了神经元计算单元,其中包括神经元计算模块、突触计算模块、配置单元模块、路由模块,如图3(a)所示.神经元计算模块输出突触变量到路由模块,从而将突触变量信息传输到其他神经元网络单元中;输出膜电位变量到突触计算模块中进行突触计算,配置单元模块用于配置路由模块的参数,路由模块从片上网络临近节点接收外部地址事件表达(Address event representation,AER)脉冲数据包,并且根据配置单元中的可编程路由表决定数据传输方向.如图3(b)所示为神经元计算单元的详细计算架构.对于神经元模型的变量V,Xi,i=1,2,···,n,构建相应的神经元模型流水线计算模块以及随机存取存储器(Random access memory,RAM)存储阵列,流水线计算模块实时更新神经元状态,RAM 阵列对神经元计算中间变量进行存储,从而对神经元网络进行时分复用操作,在BiCoSS 中对神经元计算模块进行9 000 次时分复用处理.STDP(Spike-timingdependent plasticity)计算单元将突触权重实时更新输出给突触计算单元中,突触计算单元接收AER脉冲数据包与膜电位变量V进行计算,神经元计算单元最终计算输出膜电位变量与突触变量.
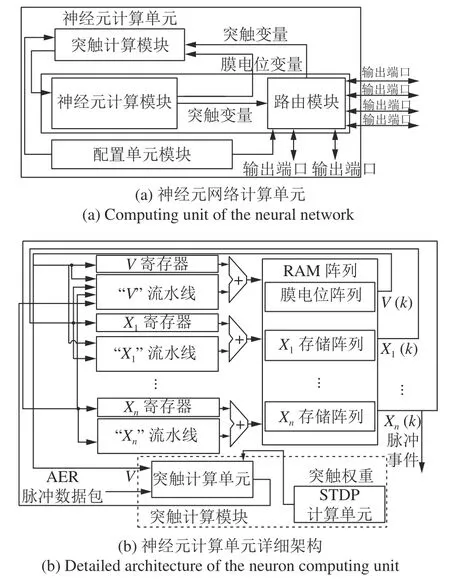
图3 BiCoSS 系统神经元网络计算架构Fig.3 Neural network computing architecture ofBiCoSS system
图4所示为BiCoSS 系统的神经元与神经突触
计算模块详细架构.图4(a)所示为以LIF 神经元模型为例的小脑神经元计算模块架构,为了节约乘法器资源,通过移位器实现常数乘法,通过逻辑单元实现变量乘法.如图4(b)所示为突触计算单元的详细计算架构,其中包括n个平行突触计算子模块,rea表示缓存器的读地址,其余变量与参数均在式(1)中定义.AER 脉冲数据包输入到复用器中,通过常规计数器进行顺序选择.解码器解码出AER脉冲数据包的突触变量信息si和时间标记信息,时间标记信息用作缓存器的写地址wri.在每个平行突触计算模块中,网络连接矩阵被存储在只读存储器(Read-only memory,ROM)中,并行加法器将n个平行突触计算模块的输出相加,并将更新后的结果 输出到神经元计算模块中进行计算.
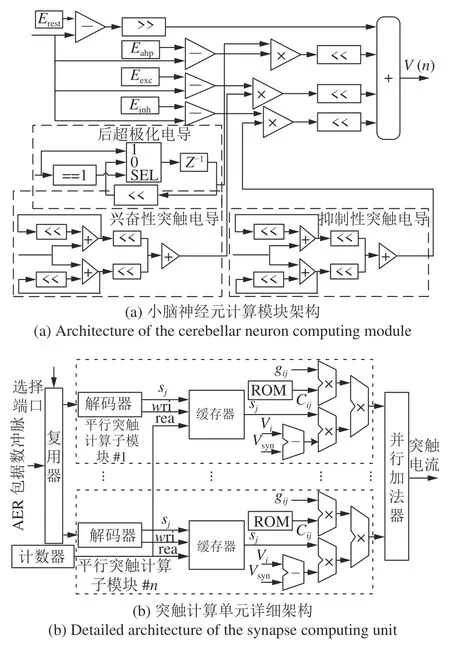
图4 BiCoSS 系统神经元与突触计算模块架构Fig.4 Neuron and synapse computing architecture of BiCoSS system
2 类脑计算模型
大规模类脑计算的关键问题之一是选用哪种神经元网络模型,神经元网络模型决定了网络的组成部分、各部分如何运行、这些部分之间如何相互作用.受生物神经网络的启发,神经元网络的常见组成部分是神经元和神经突触,如果大规模类脑计算的目的是利用类脑计算系统模拟人类大脑,从而产生更高级的类脑智能,同时理解人脑的工作机制,那么生物学现实和合理的模型是必要的.
2.1 神经元网络与神经突触模型
人脑的信息处理过程中,神经元网络模型描述了不同神经元和突触如何相互连接以及相互作用.BiCoSS 系统根据人脑认知的具体计算任务,如图5(a)所示为神经元网络放电栅图,其中横坐标为神经元网络放电时间,纵轴为神经元网络中产生放电行为的神经元序号,神经元网络通过每个神经元的时间序列进行信息的传递与处理工作,从而构成人脑的认知行为.在突触模型方面,BiCoSS 系统采用针对人脑神经元网络的生物启发突触,其表达式为
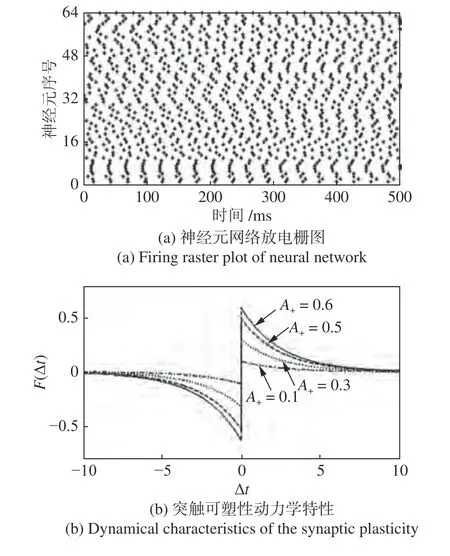
图5 生物启发的神经元网络放电行为与突触可塑性Fig.5 Spiking activities of biologically inspired neuron model and STDP characteristics

其中,Cij表示连接矩阵,gij表示耦合强度.Vi表示突触前神经元和突触后神经元的膜电位,Vsyn表示突 触的反转电势,sj为突触变量.
2.2 自学习算法
人脑的可塑性机制与大脑的学习有关,使神经
元网络具有学习功能,即神经元网络的突触权重随着时间变化.BiCoSS 系统采用在线的无监督学习,采用具有高度生物合理性的突触可塑性(STDP)的学习规则[27],其表达式为
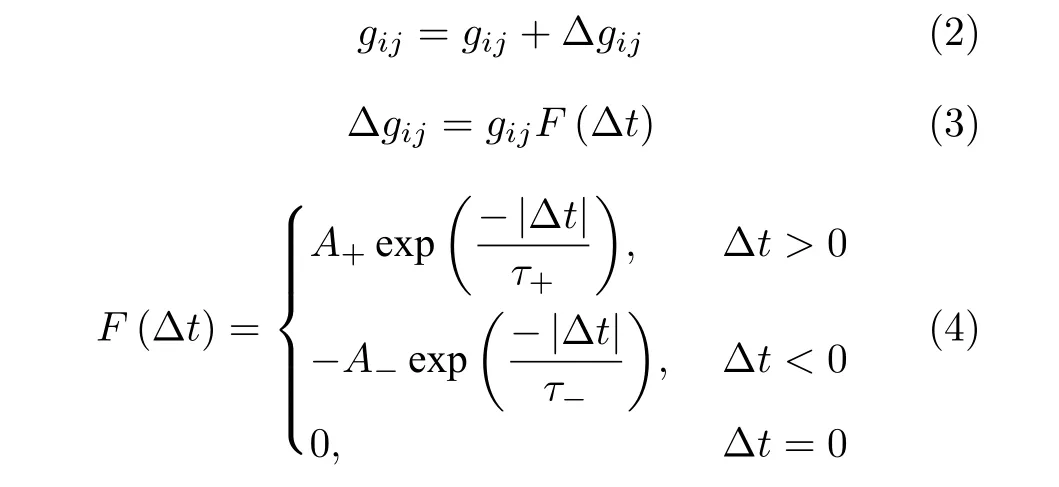
其中,gij和 Δgij分别表示某两个神经元之间的突触强度和突触强度变化值,Δt=ti-tj表示突触前后神经元放电的时间差,A+和A-限制了突触修正的最大值,τ+和τ-表示突触强度增强和减弱过程中的时间窗参数.图5(b)所示为突触可塑性的动力学特性,当突触前神经元的放电活动先于突触后神经元时,所得曲线位于第1 象限,表明突触耦合强度增加;反之,当突触前神经元后于突触后神经元放电时,所得曲线位于第3 象限,表明突触耦合强度减弱.不同的STDP 调节率会影响F函数的变化速 度,调节率升高时F函数的变化趋势明显增加.
3 神经信息路由
人脑中神经元网络信息的传递载体是神经元放电行为,基于AER 的神经信息处理方式来自生物神经网络进行信息加工的灵感[28],即神经元在产生动作电位后,输出放电信号,放电信号触发地址编码电路编码事件发生地址,通过神经放电的峰-峰间期或放电频率来定义神经信号属性,由放电事件主动触发,未产生放电事件的神经元无输出,从本质上避免了信息传递的冗余,减少放电数据量,减少系统开销与功耗,提升系统计算效率.在不发生严重竞争的条件下可以实时地输出放电事件,从而实现实时计算系统.对于同时发生的神经放电传递现象,会引发数据传输冲突,需要实现控制模块进行通信仲裁.
如图6(a)所示,BiCoSS 系统传输的放电信息使用28 位数据包,其中包含8 位AER 数据,5 位芯片地址数据,3 位层地址数据,6 位节点地址以及6 位时间标记.5 位芯片地址用于编码28 片负责计算神经元网络的FPGA 芯片,3 位层地址(包含000,001,010,011)用于标记BFT 结构的当前层数,6 位节点地址(包含000000 ~ 001111)用于表示编码0 ~ 15 的神经元计算节点,并可进一步扩展为64 个神经元计算节点.6 位时间标记用于决定AER 数据包进行计算的时间,其中,6 bit 时间标记能够使AER 数据延迟0 ~ 63 个时钟周期进行计算.该数据包表示方法可以实现114 688 个神经元之间的任意连接.如图6(b)所示,BiCoSS 系统的路由器包含6 个输入端口与其他路由节点或神经计算单元相连接,每个输入端口包含一个配有6 个FIFO(First input and first output)的虚通道.这些虚通道由虚通道仲裁器控制,使用一个计数器去顺序选择每个虚通道内的FIFO.在神经放电信息路由过程中,当第1 层路由从神经计算单元中收到放电事件信息时,放电信息包装器模块将打包过程初始化.放电信息包装器在虚通道后面使用,以便由神经计算单元输出的放电行为可以被处理成一个AER 神经放电包.AER 神经放电包有28 位,由5 部分组成,分别为AER 数据、芯片地址、层地址、节点地址与时间标记.放电信息包装器使用配置处理器中存储的信息,配置处理器能随时进行现场重复编程,根据神经元数目与连接信息进行存储信息的修改.配置处理器存储的数据包含芯片地址、层地址、节点地址以及时间标记芯片地址和层地址采用3 位定点数,节点地址选用6 位定点数,时间标记数据选用6 位定点数.输入的事件暂存在存储器中,当时间标记到达时进行处理.当前路由器相关地址编码如表1所示.

表1 当前路由器相关地址编码Table 1 The address coding of the current router
在神经放电事件被封装成AER 神经放电包以后,路由逻辑模块基于路由算法对AER 神经放电包进行处理.路由算法如图6(c)所示,交叉互联模块由多路复用器实现,由交叉互连仲裁器控制BiCoSS 系统的路由算法为确定性的非最短路径长度路由算法.路由器的节点编码与目的节点的编码相比较,在算法中,dest表示了目的节点当前路由的节点地址,由S(l,i)表示源节点和目的节点的地址分别由src和dest表示,神经计算单元的数目为N.首先输入源节点和目的节点的地址(src,dest)以及当前路由器的地址(l,i),如果l= 1,则计算当前路由器的最低范围lowRange和最高范围highRange的值,如果dest属于这个范围,神经放电包将被传输到目的节点.否则,神经放电包将被传到当前路由节点任意父节点,并重新开始路由算法.如果dest属于交叉相连的路由器,神经放电包通过交叉连接的链路传到相应路由节点,并重新开始路由算法.否则,需要判断源节点与目的节点的关系,如果存在dest-src <N/2 和dest-src >-N/2,神经放电包将传递到正确的邻居节点,否则将传递到左邻居节点,并重新开始路由算法,继续执 行.
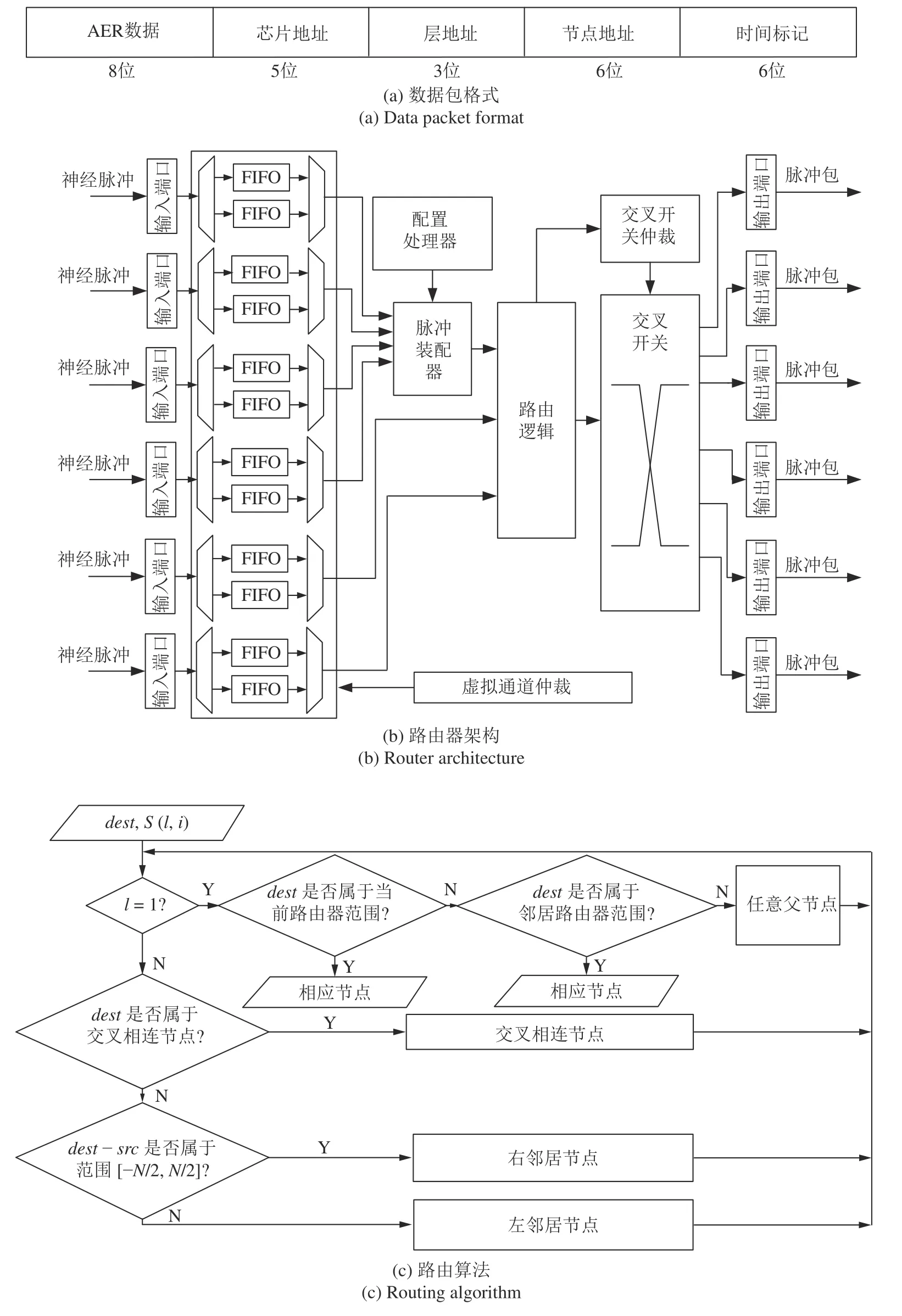
图6 BiCoSS 系统的神经放电信息路由Fig.6 Spike information routing of BiCoSS system
4 实现
大规模类脑计算系统主要包含3 种类型,分别为数字电路实现、模拟电路实现以及数模混合电路实现、模拟电路系统被认为是直接实现生物启发系统的首选方式,具有高计算速度、低功耗等优点.其缺点是计算精度比数字电路低,软件指令与硬件动作之间的一对一通信能力较差,一旦网络参数或结构发生变化则需要新一轮开发周期,难以进行灵活配置.数模混合实现方式通过定制计算系统对大规模神经网络进行模拟,是对于外界环境比较敏感,稳定性差,应用开发十分困难,可编程性差.相比之下,数字电路具有计算精度高、 计算能力强和可重复配置的优势.同时,串行计算的数字电路(如DSP(Digital signal processing)、ARM)不适用于神经网络计算所需的并行性.现场可编程门阵列(FPGA)具有并行计算能力,包含丰富的逻辑计算单元与存储单元,适合进行复杂算法与模型的实时计算.因此,BiCoSS 系统采用英特尔公司的Cyclone EP4CE115 系列FPGA 芯片,采用树形结构完成系统中芯片的级联与扩展,每个芯片上采用网格型拓扑结构进行片上系统实现,片上与片间通信采用基于地址事件表达的神经放电信息路由方式,从而提升计算效率,节约计算开销与功耗,增强系统可扩展性.
4.1 硬件
BiCoSS 系统采用英特尔公司的Cyclone IV 系列FPGA 芯片EP4CE115F29C7N,该芯片具有115 K垂直排列的逻辑元件(Logic elements,LEs)、4 Mbit 的嵌入式存储器和528 个IO 引脚.每个芯片与两个SDRAM 以及一个串行配置设备EPCS128相连,被扩展为6 层PCB(Printed circuit board)的核心系统.模拟神经网络需要神经元状态信息、突触事件、网络耦合矩阵与强度等.串行配置芯片EPCS128用于在电源关闭时存储程序.否则,每次重新上电时都要将所实现的大规模神经网络在BiCoSS 系统中逐片上传.BiCoSS 的7 个子系统通过PCB 底板实现引脚之间的直接连接.每个子系统上还留有额外的引脚并制成外部接口,以便实现数模转换、视觉设备、机器人控制、系统扩展等功能.
4.2 模型与算法
为了兼顾硬件资源消耗与精度,BiCoSS 系统选用欧拉法对神经元模型进行离散化,以负责运动控制认知功能的小脑中LIF 神经元模型欧拉法离散化为例,所得差分方程为
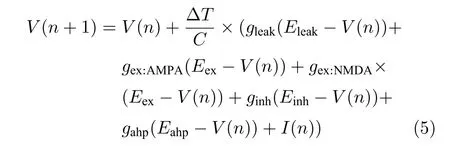
式中,ΔT是离散化采样时间,V(n)是当前时刻的变量迭代值,C为神经元电导.参数gleak,gex:AMPA,gex:NMDA,ginh,gahp分别为漏电导、兴奋性AMPA(Aminomethylphosphonic acid)突触电导、兴奋性NMDA(N-methyl-D-aspartate)突触电导、抑制性突触电导、后超极化突触电导,Eleak,Eex,Einh,Eahp分别为漏电势、兴奋性电势、抑制性电势以及后超极化电势,I为神经元外部施加电流.
为了解决FPGA 片上资源与网络规模之间的矛盾,BiCoSS 系统采用了分时复用技术,应用同一个计算单元分时段计算多路数据.对于神经元网络仿真,将神经元计算单元计算后得到的状态变量作为输出,存储在片上RAM 中.在系统始终激励下,向神经元计算单元依次输入每个神经元上一步的状态信息,在分时复用的神经元进行状态更新后,再进行下一步计算.假设网络状态存储单元的RAM存储器的存储深度为Nneu,网络中包含的神经元总数为Ntotal,考虑时间复杂度有如下式成立:
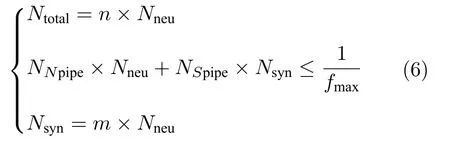
其中,fmax为FPGA 可以实现的最大计算频率,NNpipe为神经元计算单元的流水线深度,NSpipe为突触电流计算单元的流水线深度,m为并行的突触电流计算单元数目,n为并行的神经元计算单元数目.
在类脑计算系统中,硬件资源消耗随神经元功能性网络的网络规模增大而增大,图7(a)直观体现片上存储资源开销与神经元计算位宽、神经元复用次数间的关系.同时,我们定义了网络更新速度与并行突触电流计算单元(Synaptic current computation unit,SCCU)个数、网络所有神经元数Ntotal之间的关系.图7(b)显示网络更新速度会随SCCU数目的增加而增大,同时增加SCCU 有助于在确定网络连接拓扑情况下仿真更多神经元数目,网络中神经元数目的减少有利于提高网络的整体计算速度,这需要进行不同数量级的神经元功能性网络仿真以确定产生期望动力学行为的网络中最小神经元数目.
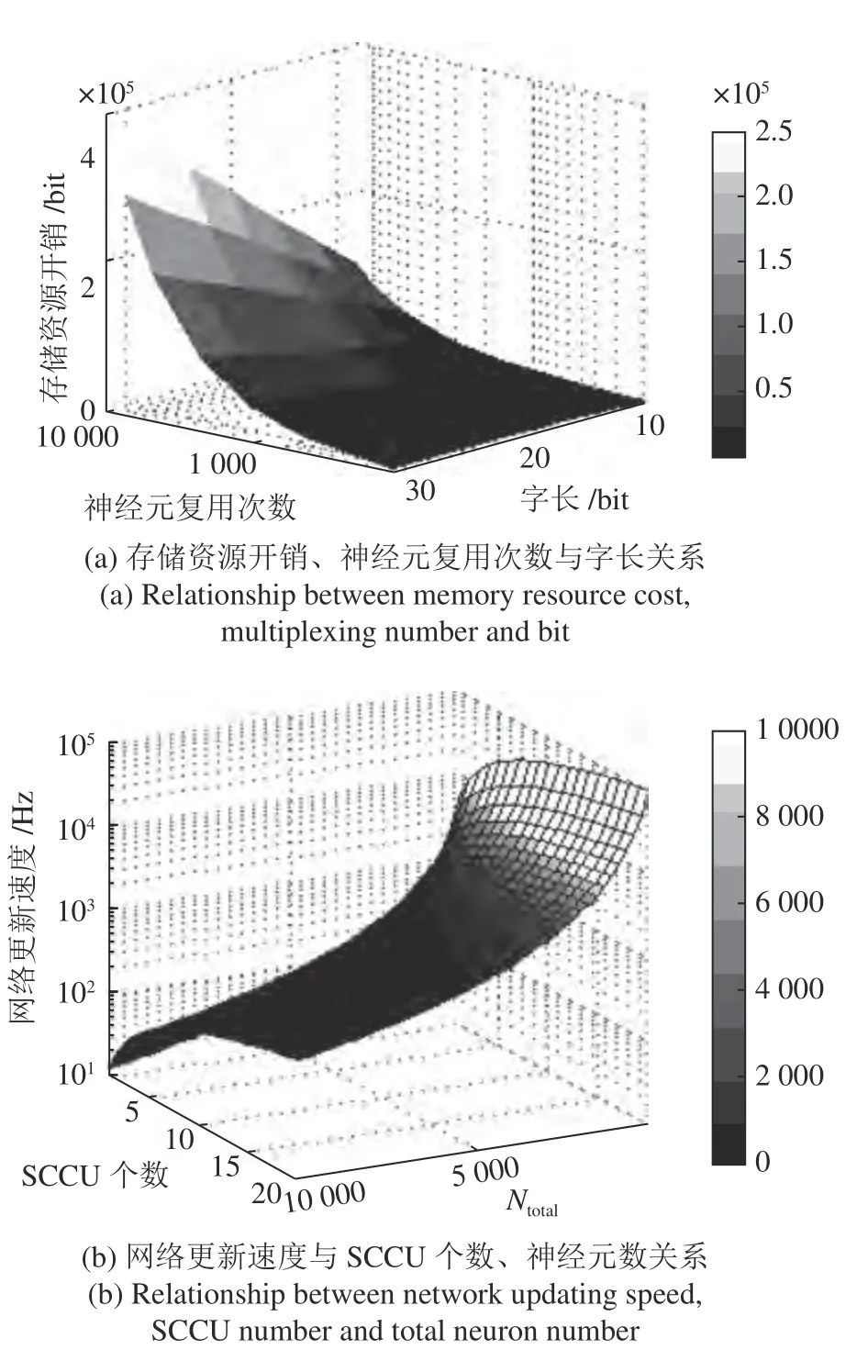
图7 模型实现的性能分析Fig.7 Analysis performance of model implementation
5 性能分析
本文通过4 个方面测试与验证BiCoSS 系统的性能,这4 个方面分别为计算效率、功耗、通信效率与可扩展性,通过计算基于生物合理性的神经元模型与具有STDP 学习机制的生物神经元网络,从而测试BiCoSS 系统的性能.
5.1 计算效率与功耗
为了更好地展示BiCoSS 系统的计算效率,本文将BiCoSS 系统与3 个替代平台相比,3 个替代平台分别为CPU,GPU 与多核总线平台.为了量化计算效率,我们使用代价函数Q,其表达式描述如下:

tcom与tbio分别表示计算平台与真实生物神经元网络计算同等尺度神经元网络的的计算时间.CPU 计算平台使用Intel 双核2.4 GHz CPU 进行计算,GPU 计算平台采用NVIDIA GTX 280 GPU,多核总线平台使用EP3SE340 FPGA 芯片.仿真采用的是基于LIF 神经元模型的生物小世界神经元网络,如图8(a)所示,我们考察了 103~4×106的神经元数目范围,随着神经元数目的增长,BiCoSS系统计算效率维持在更高的数值,而其余三种替代计算平台的计算效率均呈现指数下降的趋势,这是由于BiCoSS 采用全并行的非冯·诺依曼计算架构,使计算效率得到了显著提升.
在系统功耗方面,BiCoSS 系统包含35 片Intel公司的EP4CE115 FPGA 芯片,消耗功耗为10.419 W,系统的功率密度35.4 mW/cm2,传统计算机CPU的 功率密度为50~100 W/cm2.
5.2 通信效率与可扩展性
在通信效率方面,如图8(b)所示,BiCoSS 系统的延时与传统线性结构与传统树形结构进行比较,当数据包诸如率小于0.18(数据包/周期/节点)时,BiCoSS系统结构的负载延时远低于以Neurogrid[22]为代表的传统线性结构,低于以HiAER[29]为代表的传统树形结构,随着数据包注入速率的增加,平均延时略有升高,线形拓扑结构在0.1(数据包/周期/节点)处出现拐点,传统树形结构与BiCoSS结构均在0.18(数据包/周期/节点)处出现拐点,由于BiCoSS 结构的节点连通度高于传统树形结构,BiCoSS 结构在拐点后的增幅略低于传统树形结构.
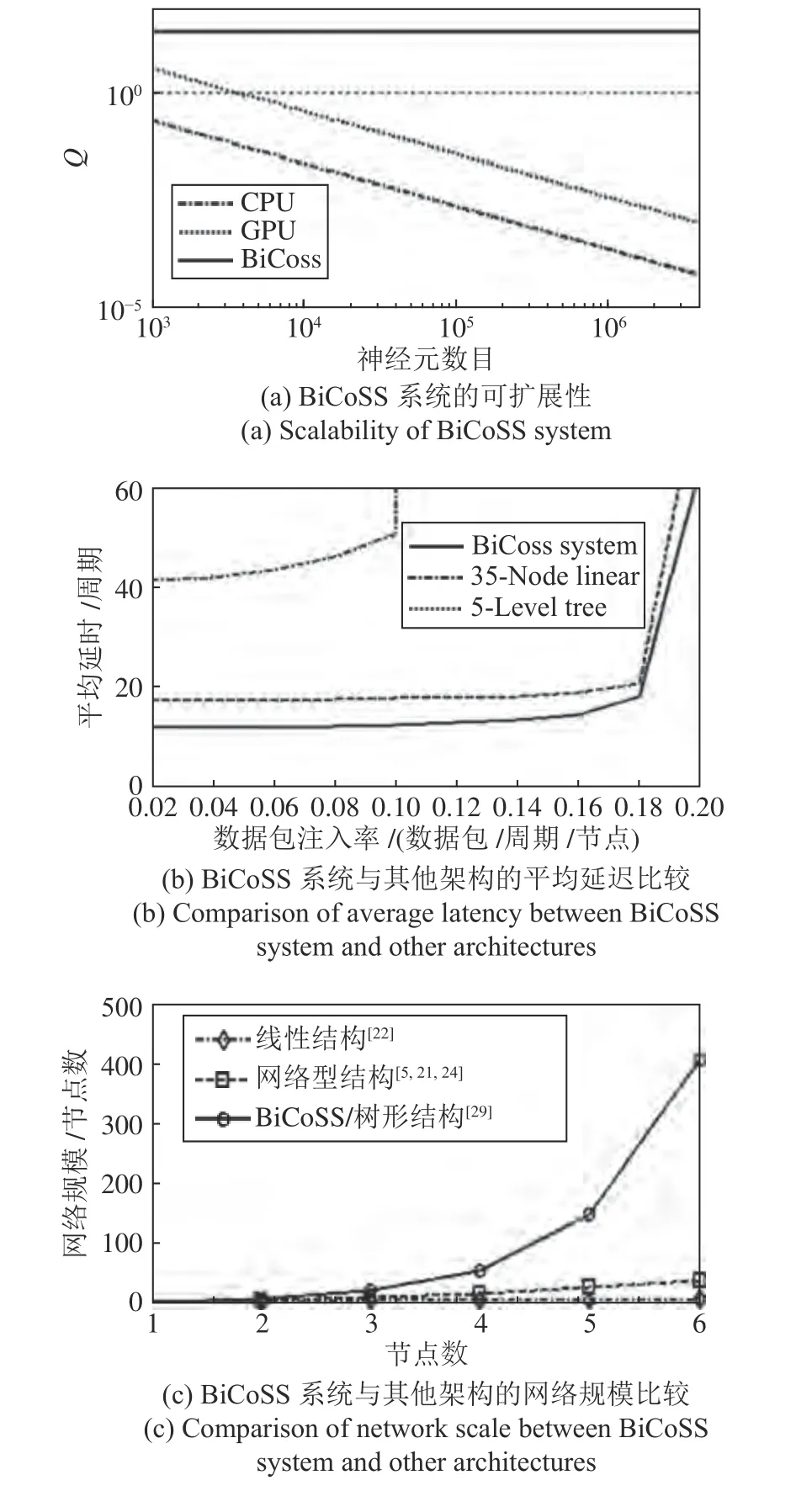
图8 BiCoSS 系统性能分析Fig.8 Performance analysis of BiCoSS system
之前的神经形态学计算平台采用了不同的多片拓扑结构完成对于大规模生物神经元网络的实现与仿真,典型的结构包括Neurogrid 使用的线性结构[22]以及BrainScaleS、Truenorth、SpiNNaker 使用的网格型结构[5,21,24].在可扩展性方面,如图8(c)所示,BiCoSS 系统采用改进的树形结构,其可扩展性远高于传统线性结构与网格型结构,使得系统具有更强的可扩展性,更利于大规模人脑神经元网络实现的扩展与网络规模的提升.
BiCoSS 系统神经元网络单元使用BFT 结构实现,具有良好的系统延迟特性.为了显示BiCoSS系统神经元网络单元的延迟优越性,如图9(a)~9(d)所示,比较了BiCoSS 神经元网络单元与传统片上网络mesh 型、torus 型、Butterfly 型、Flattened Butterfly 型的平均延迟,本文定义了突触事件输入率为兆突触事件数据包数/秒(M synaptic events/s,MSynE/s).由图9 可以看出,随着突触事件输入率的增大,BiCoSS 系统神经元网络单元的平均延迟基本维持不变,而另外三种片上网络结构的平均延迟随着突触事件输入率的增大具有明显增加,表明了BiCoSS 系统的神经元网络单元具备在较高突触事件输入率条件下的良好延迟特性.
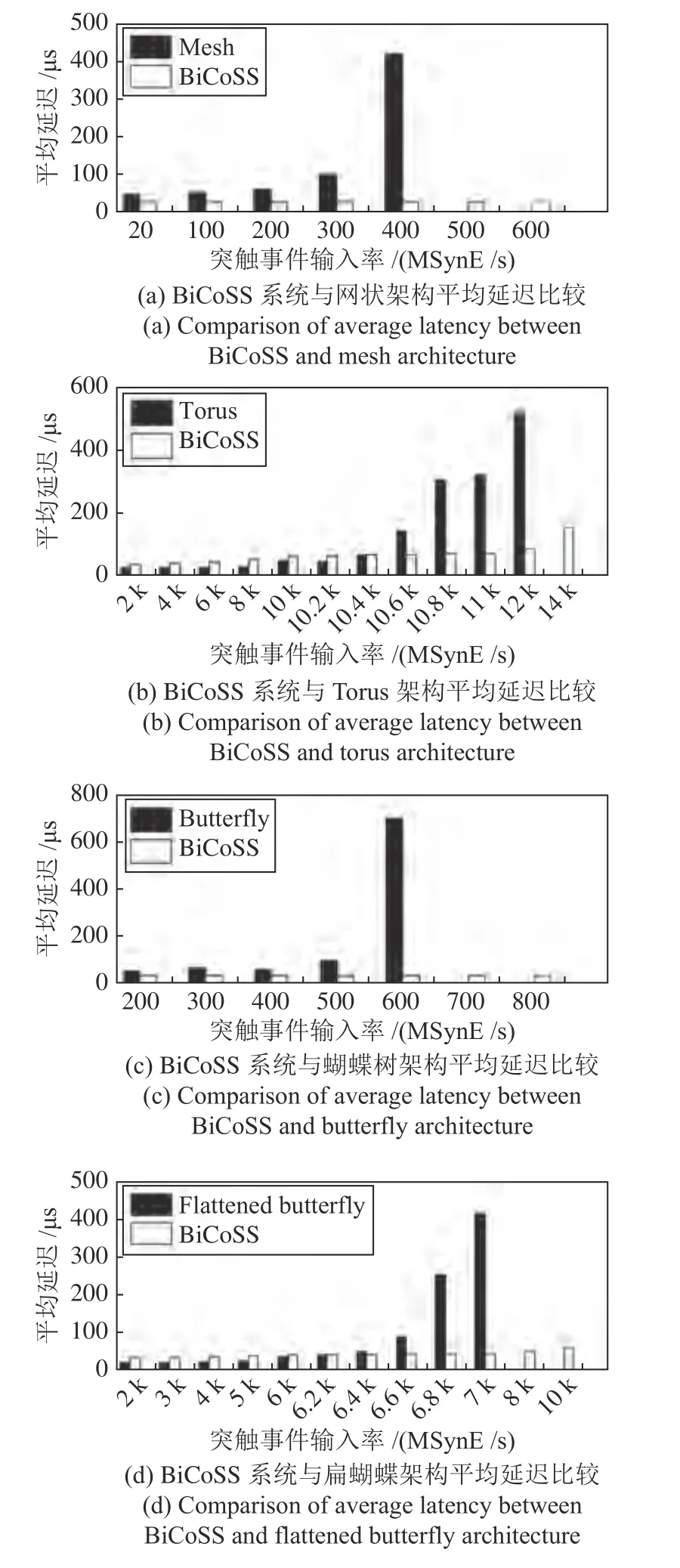
图9 BiCoSS 系统神经元网络单元平均延迟Fig.9 Average latency of neural network unit on BiCoSS
5.3 系统性能比较
为了进一步揭示BiCoSS 系统的性能优势,如表2所示,我们将BiCoSS 与国际上主要的大规模类脑计算系统进行比较.从实现方式上来看,Brain-ScaleS[24]、HiAER[29]等系统采用了模拟电路的方式实现了大规模类脑计算系统,缺点是计算精度比数字电路低,软件指令与硬件动作之间的一对一通信能力较差,一旦研究的神经元网络参数或结构发生变化则需要新一轮开发周期,难以进行灵活配置.与此相对的是以Truenorth[5]、SpiNNaker[21]为代表的数字类脑计算系统与以Neurogrid[22]为代表的数模混合类脑计算系统.数模混合系统结合了数字电路与模拟电路系统的优点,缺点是对于外界环境比较敏感,稳定性差,数模转换产生延迟,应用开发十分困难,在可编程性方面输给了数字电路实现.相比于模拟电路与数模混合电路,BiCoSS 采用数字实现的方式进行大规模类脑计算,尽管数字电路功耗更高,但其具有计算精度高,计算能力强与可重复配置的优势.神经元模型的复杂度决定了类脑计算的生理可信性,BiCoSS 系统采用数字电路可实现包括基于电导的H-H 模型在内的任意模型,以及基于生物启发的STDP 机制的学习算法,具有更强大的揭示人脑信息处理机制的能力.在计算规模方面,BiCoSS 可以计算包含100 M 神经元的大规模神经元网络;对于包含N个计算节点的BiCoSS 系统,其具有4eN的扩展性.BiCoSS 的缺点在于功耗为10.419 W,尽管远低于SpiNNaker的49 W 功耗,但相较于Neurogrid(功耗为2.7 W)、Truenorth(功耗为63 mW)等系统,BiCoSS 仍会消耗更高的功耗.然而,综合考虑网络规模、可实现模型的复杂度、生物启发的学习规则与系统可扩展性,与国际上当前代表性的大规模类脑计算系统相比,BiCoSS系统具有更突出的优势.
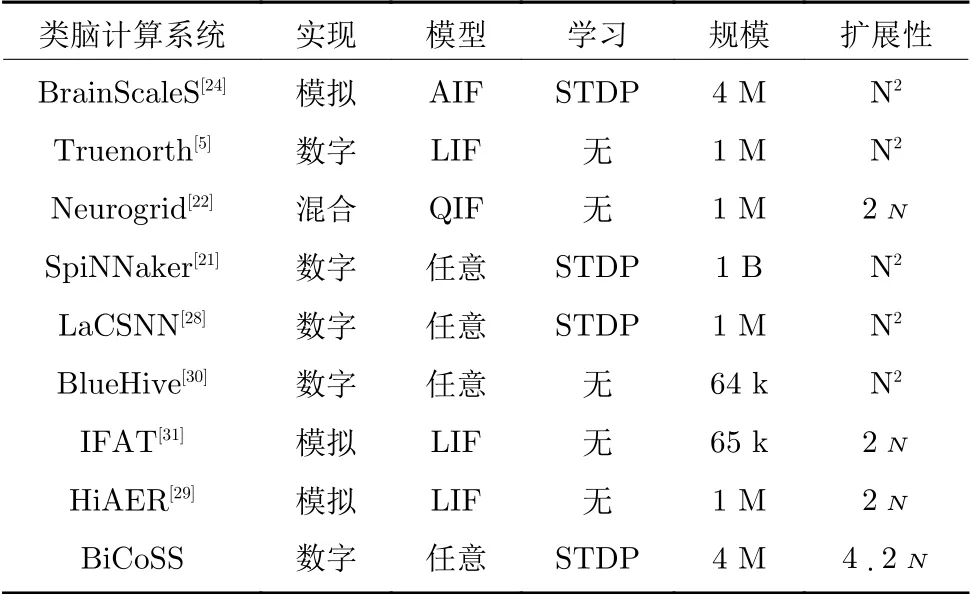
表2 与当前代表性大规模类脑计算系统比较Table 2 The comparison with the state-of-the art large-scale brain-inspired computing systems
6 BiCoSS 的类脑智能与脑机制应用
人脑一种简单的高层认知行为涉及上百万的神经元脉冲活动[5-7],大规模神经元网络的计算有助于将神经网络动力学特性与人脑高层认知行为联系起来,接近人脑的计算规模具有更强的生物可信性.BiCoSS 系统可以实时计算大规模人脑具有认知功能的神经元网络,一方面增加的网络规模可以更加接近人脑认知行为的计算规模,从而准确地揭示人脑的大规模认知机制,另一方面BiCoSS 的实时计算性能可以用于与真实生物体的接口或人工智能设备中.为了进一步研究人脑认知行为的机制,从神经元水平分析了产生类脑认知的深层机制,BiCoSS系统从类脑决策、类脑运动控制、神经疾病机制以及类脑视觉目标识别进一步探索脑机制.在后面包括类脑决策、类脑运动控制以及运动障碍性疾病机制研究的类脑计算应用中,我们均采用BiCoSS 系统中包含的所有35 片FPGA,搭建了400 万神经元的大规模神经元网络进行人脑认知机制的探索与实时计算.图10(a)所示为基于BiCoSS 系统的类脑计算平台实物图,由DE2 开发板实现的输入信号发生器,用于产生输入的离散脉冲序列,通过两位线传送到BiCoSS 系统中,用于模拟大规模神经元网络的BiCoSS 计算系统通过数模转换器将输出转换成模拟信号,并在示波器显示输出波形.图9(b)~9(e)显示了决策、运动控制、以及正常与运动障碍状态下,基底核GPi 神经元、小脑GO 神经元、丘脑皮层神经元的实时输出离散脉冲信号,在运动障碍性疾病状态下,丘脑皮层神经元放电从尖峰放电变为了簇放电,所显示的实时离散脉冲信号均来自BiCoSS大规模网络中某一特定核团内任意选取的待观测神经元.

图10 实验系统实物图与计算结果Fig.10 Experimental setup of BiCoSS system and computing results
6.1 类脑决策
在各类功能性神经元网络中,认知决策功能相关的神经元网络是当今研究的热点.大脑决策是一个极为复杂的神经活动过程,皮层-基底核-丘脑回路是人脑认知决策的重要网络,不同的多巴胺水平会影响人脑在决策的时候采用不同的策略,包括保守、冒险与随机[32],因此,BiCoSS 系统建立了负责人脑决策的大规模基底核神经元网络.该网络由纹状体(Str),苍白球外侧部(GPe)、苍白球内侧部(GPi)、丘脑底核(STN)四种核团组成,其中纹状体(Str)被分为D1 和D2 两部分,后三种核团各自为一部分,每部分均由呈网格状排列的100 万个神经元构成.除纹状体以泊松序列模拟放电信息外,其他核团的神经元均为带有离子通道电流的Izhikevich 模型,其神经元方程如下所示:
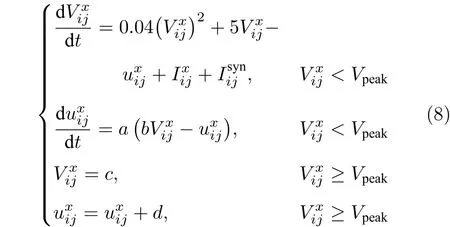
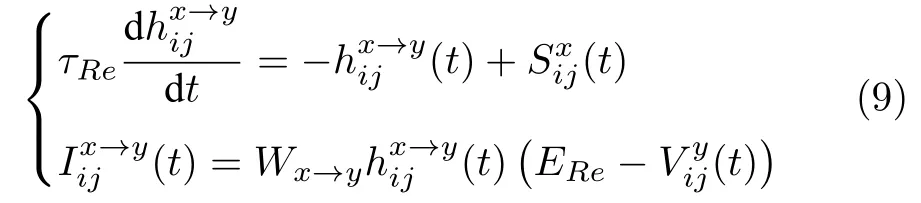
其中,τRe是突触受体的衰减常数,ERe是相关受体的突触电位,是神经元x在时间t的放电情况,放电为1,不放电为0,是从神经元x到神经元y的突触电流的门控变量,Wx→y是神经元x与神经元y连接的突触权重,是神经元y在坐标位置(i,j)处的膜电位,Re 可以代表AMPA,GABA(γ-aminobutyric acid),NMDA 三种突触受体中的任意一种.不同类型细胞的具体参数值见表3.
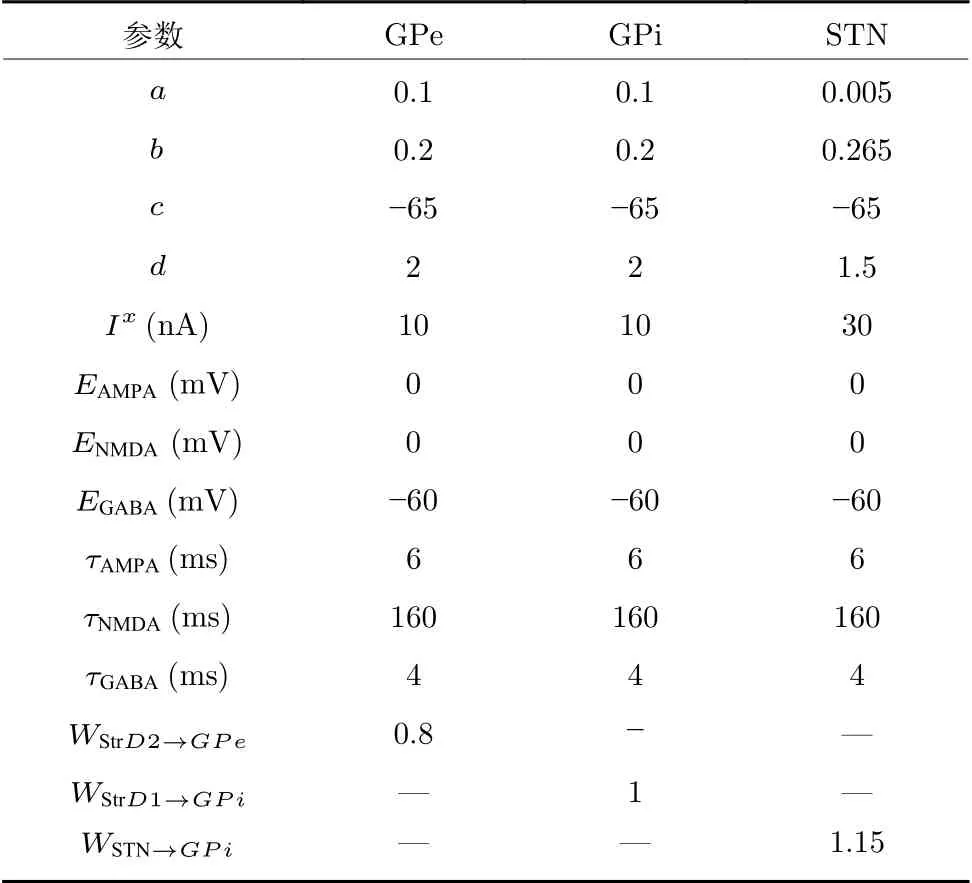
表3 基底核模型中不同细胞的参数值Table 3 Parameter values of different cells in the basal ganglia model
在基底核网络中,D1 纹状体(Str)和D2 纹状体(Str)分别向苍白球内侧部(GPi)和苍白球外侧部(GPe)传递抑制性信号,苍白球外侧部(GPe)向丘脑底核(STN)传递抑制性信号,丘脑底核(STN)向苍白球内侧部(GPi)和苍白球外侧部(GPe)传递兴奋性信号,基底核网络的最终输出由苍白球内侧部(GPi)给出.在高多巴胺水平的条件下,我们输入BiCoSS 网络两个不同的刺激信号,两个刺激信号分别为频率4 Hz 和8 Hz 的泊松序列.我们从100 万个STN 和GPi 神经元中各取2 000 个神经元绘制放电栅图,观测到STN 和GPi 核团的放电栅图如图11(a)和图11(b)所示,可以看出,在高多巴胺水平下,基底核网络做出了相应的选择策略,更强的8 Hz 泊松序列刺激使得网络活动更快达到阈值,因此基底核网络选择了8 Hz 刺激作为最佳决策.
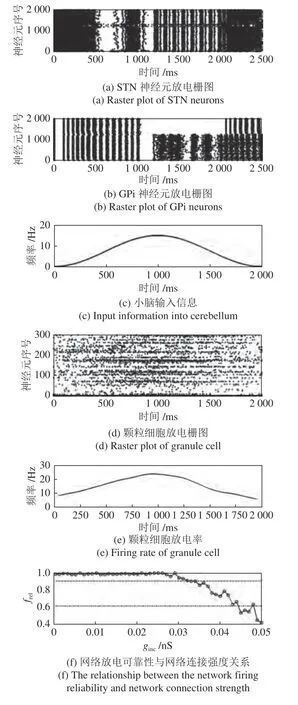
图11 基于BiCoSS 系统的认知计算Fig.11 Cognition computing based on BiCoSS system
6.2 类脑运动控制
小脑在人脑的运动控制功能中起着重要的作用,包括维持躯体平衡、调节肌张力及协调运动等.BiCoSS 系统建立了大规模的小脑神经元网络,用于人脑运动控制机制的探索.其中,搭建了由400万个神经元构成的小脑模型,其中包括100 万个颗粒细胞(Granule cell,GR),100 万个高尔基细胞(Golgi cell,GO),50 万个浦肯野细胞(Purkinje cell,PC),50 万个篮状细胞(Basket cell,BS),50万个下橄榄核细胞(Inferior olive,IO)和50 万个前庭核细胞(Vestibular nuclei,VN).颗粒细胞(GR)和高尔基细胞(GO)均呈网格状排列.所有的神经元细胞均为带有离子通道的LIF 模型,其统一的膜电位方程和突触电导方程如下所示.

其中,C是神经元的膜电容,V是膜电位,gx代表突触电导,Ex代表静息电位,Gx为最大突触电导,τahp是电导延迟时间,x可以是{leak,exc,inh,ahp}中的任意一个,θ是膜电位阈值,t0是神经元的上一个放电时刻.I是自发电流,只存在于少数类型的细胞中.不同类型细胞的具体参数值参见表4.
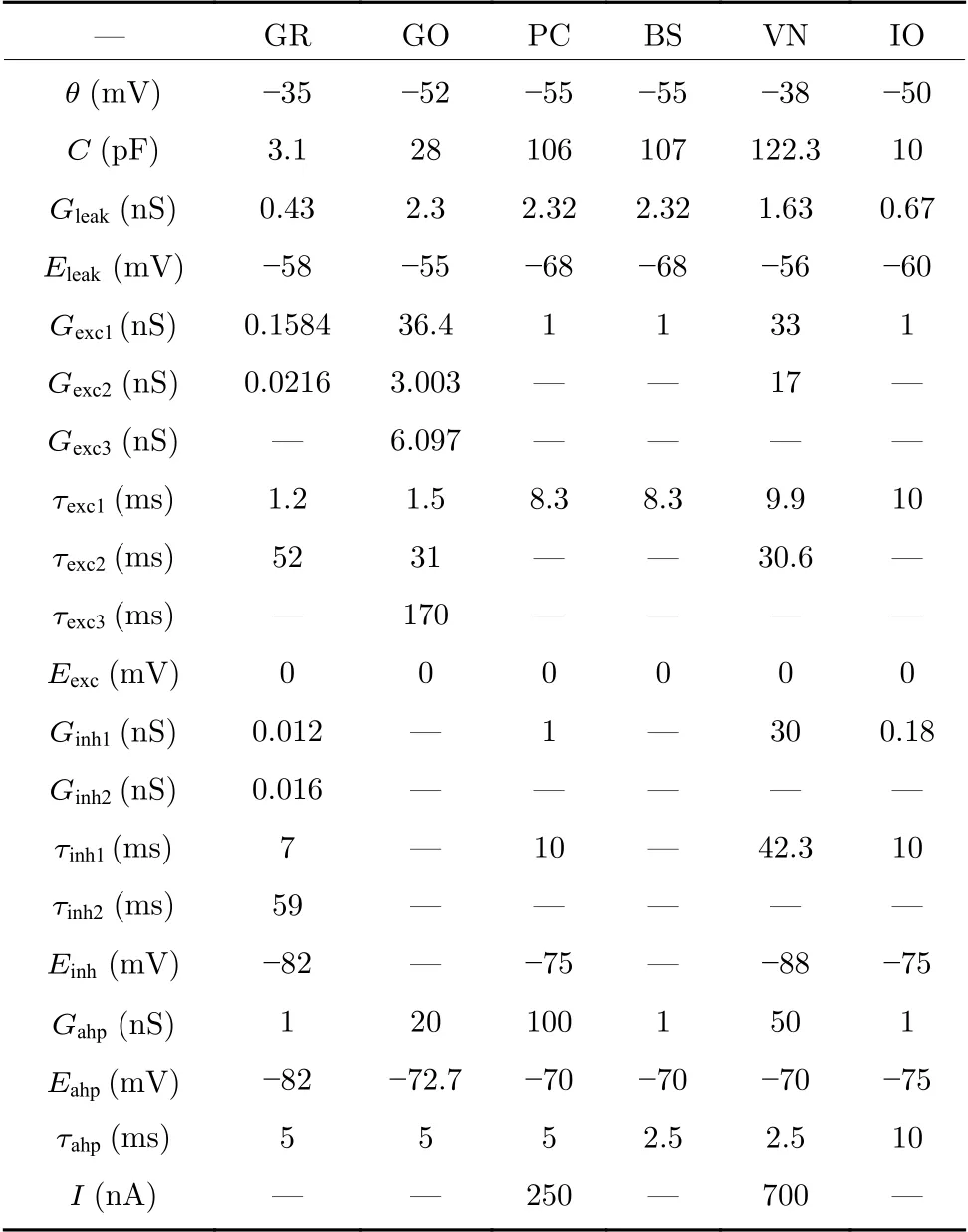
表4 小脑模型中不同细胞的参数值Table 4 Parameter values of different cerebellar cells
在小脑网络结构中,我们采用之前的研究[33]提出的具有解剖学意义的小脑网络结构进行计算.其中,外部输入通过苔状纤维(Mossy fiber,MF)传递给颗粒细胞(GR),颗粒细胞(GR)与高尔基细胞(GO)相互耦合,将输入信息进行处理并通过平行纤维(Parallel fiber,PF)传递给浦肯野细胞(PC)和篮状细胞(BS).外部误差信号输入给下橄榄核细胞(IO),并转化为学习信号通过爬行纤维(Climbing fiber,CF)传递给浦肯野细胞(PC),通过长时程增强(Long term potentiation,LTP)和长时程抑制(Long term depression,LTD)改变其与颗粒细胞在PF-PC 的突触强度,这也是小脑学习的基础.此外,浦肯野细胞(PC)还接受来自篮状细胞(BS)的抑制信号,之后将信息传递给前庭核细胞(VN),前庭核细胞(VN)的输出即为小脑的最终输出信号.前庭动眼反射实验反映了当头部位置改变时,视网膜成像保持稳定的神经响应过程.在头部运动的过程中,前庭会产生刺激并引起眼球的反射运动,使得眼球不会随头部位置的改变而改变,从而保证视网膜稳定成像.图11(c)~11(e)显示了在头部运动时,随头部移动的变化的前庭信息被编码为泊松序列输入给颗粒细胞,颗粒层细胞中任意300 个细胞的放电栅图与颗粒层细胞的放电率.从图中可以看出,颗粒细胞群的总体放电率随着刺激强度从小变大,然后变小,表明颗粒细胞可以将输入信号的幅度和时间信息传递给浦肯野细胞,从而对眼球运动产生影响,实现小脑的运动控制认知功能.
6.3 神经疾病机制研究
BiCoSS 系统的另一个重要应用是人脑精神疾病机制的仿真与分析.为了探索运动障碍性疾病的发病机制,基于BiCoSS 系统实现了大规模皮层-基底核—丘脑皮层神经元网络,在此基础上探索运动障碍性疾病的发病与皮层-基底核-丘脑皮层神经元网络耦合强度的关系.皮层-基底核-丘脑皮层神经元网络由Izhikevich 神经元模型构建,其中包含GPe、GPi、STN、丘脑皮层(Thalamocortical,TC)四种核团,神经元模型由下式表示:
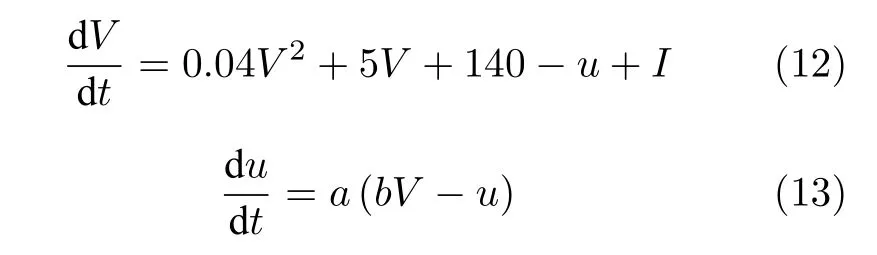
电流I包含3 部分,即
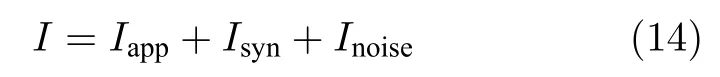
其中,Iapp为对不同种类核团的施加电流,Inoise为神经元固有噪声,Isyn为突触电流,脉冲复位等式为

其参数值如表5所示.突触电流计算式为
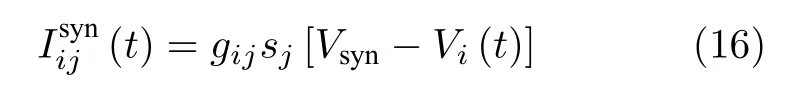
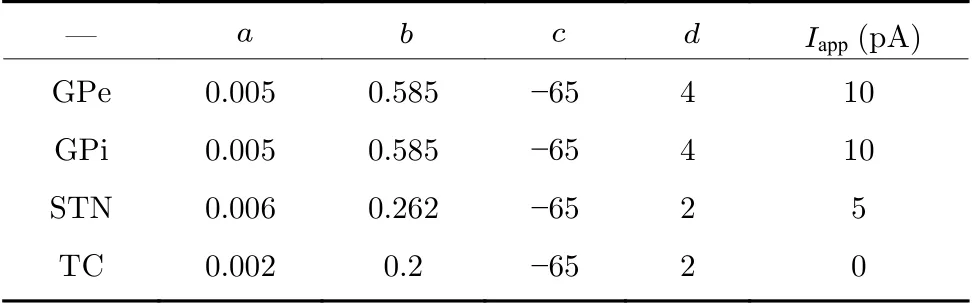
表5 皮层-基底核-丘脑皮层模型中不同神经元的参数值Table 5 Parameter values of different cells inthe cortico-basal ganglia-thalamocortical model
突触连接权重gij如表6所示,表6 中ginc为突触增加权重.突触变量sj由下式定义:
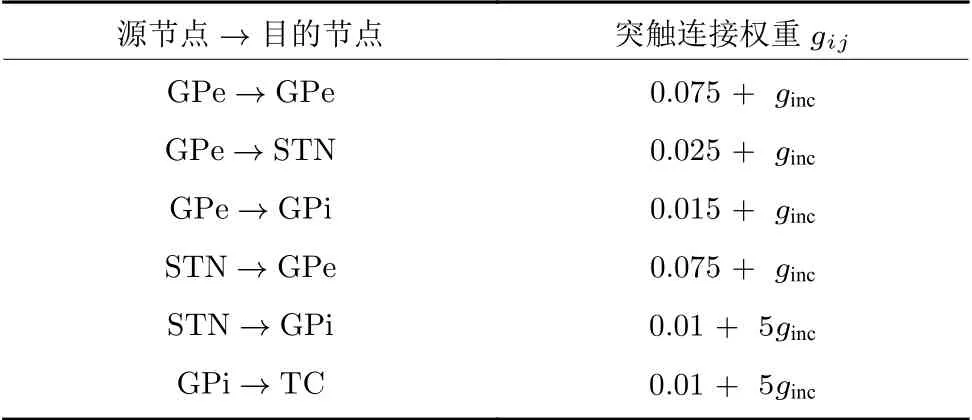
表6 皮层-基底核-丘脑皮层模型网络连接权重Table 6 Parameter values of synaptic coupling weight in the cortico-basal ganglia-thalamocortical model

其中,τS是突触延迟时间参数,恢复函数计算如下:
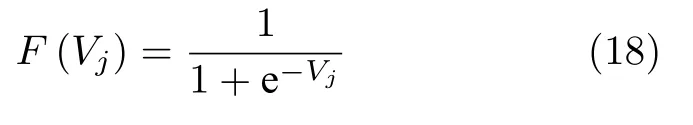
感觉运动区对TC 神经元的输入电流表示为
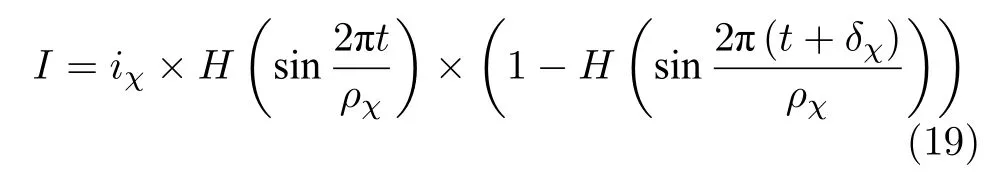
其中,H为Heaviside 函数,参数值iχ= 30 pA,δχ=3 ms,ρχ= 25 ms.
定义神经元网络放电的可靠性为
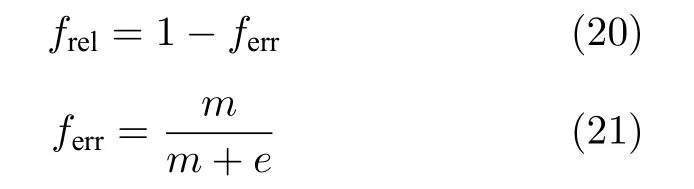
其中,ferr表示放电失败的百分比,m表示丘脑皮层输出簇放电或放电失败的次数,e表示丘脑皮层输出正常放电的次数.较高的可靠性frel表示神经元网络的放电属于正常水平,过低的可靠性表示神经元网络已处于运动障碍性疾病发病状态.
如图11(f)所示,随着网络耦合强度的增加,神经元放电的可靠性在一定范围内保持不变,网络耦合强度的进一步增加导致网络放电可靠性迅速下降.因此,皮层-基底核-丘脑皮层神经元网络中突触耦合强度的增加是运动障碍性疾病致病的重要因素之一.
7 结论与展望
本文开发了一个基于神经认知计算架构的大规模类脑计算系统BiCoSS.该系统能够实时地计算四百万神经元数量级的、与人脑认知功能相关的大规模神经元网络以及基于生物启发学习机制的在线学习与训练.相比传统类脑计算平台,该系统具有更高的计算效率,更低的计算功耗以及良好的扩展性,适合进行具有认知功能的人脑大规模神经元网络实时计算与仿真分析.增加的网络规模可以更加接近人脑认知行为的计算规模,从而准确地揭示人脑的大规模认知机制;同时,BiCoSS 的实时计算性能可以用于与真实生物体的接口或人工智能设备中.综合考虑网络规模、可实现模型的复杂度、生物启发的学习规则与系统可扩展性,与国际上当前代表性的大规模类脑计算系统相比,BiCoSS 系统具有更突出的优势.同时,BiCoSS 系统从类脑决策、类脑运动控制、神经疾病机制的脑认知任务方面进一步进行脑机制的计算与研究.本研究完成了将类脑智能与机器智能进行融合的重要一步,并可以作为进行脑机制实验的重要依据.
