应用知识图谱的推荐方法与系统
2021-11-13饶子昀刘俊涛曹万华
饶子昀 张 毅 刘俊涛 曹万华
1.武汉数字工程研究所武汉 430205
推荐系统是一种向目标用户建议可能感兴趣物品的软件工具.随着网络与现实信息的爆炸式增长,越来越多的在线服务商为用户提供商品、音乐、电影等(以下统称为物品)的推荐服务.推荐系统能够满足用户的个性化需求,为在线服务商带来巨大商业价值.同时,推荐方法与系统的研究促进了偏好挖掘、大数据处理、决策支持等领域的相关理论和实践的飞速发展,其学术价值也引起了广泛的关注.
推荐系统面临的重要挑战主要是数据稀疏性问题和冷启动问题.数据稀疏问题指的是相对于数量庞大的用户和物品,仅有少量的物品获得了用户的评价或者购买,难以据此获得相似的用户或相似的物品,使得传统推荐方法失效了.冷启动问题指的
是系统由于并不知道新加入用户的历史行为,无法给他们推荐物品,同样新加入的物品也由于没有被用户评价或购买过而无法被针对性的推荐.
推荐系统中通常利用附加信息来解决上述问题,以提高性能.附加信息(一般也称上下文信息)分为显式信息和隐式信息[1].显式信息是通过诸如物理设备感知、用户问询、用户主动设定等方式获取的与用户、物品相关联的上下文信息.隐式信息即利用已有数据或周围环境间接获取的一些上下文信息,例如可根据用户与系统的交互日志获取时间上下文信息.
近年来,利用以知识图谱为表示形式的附加信息的推荐方法受到了学者们的关注.知识图谱最初用于提升搜索系统的性能[2],刻画了海量实体之间的多种关系,具有网状结构,能够用于推荐系统中来增强用户、物品之间联系的认知与解释,从而提高推荐准确度.本文综述了2015~2019年发表在DLRS、RecSys、KDD、CIKM、NIPS、TIST、UMAP、SIGIR 等会议和期刊中的利用知识图谱的推荐方法的文献,共23 篇.在利用知识图谱的推荐系统中,通常首先将收集到的用户信息、物品信息、用户历史行为等数据或者一些相关的外部数据表示成知识图谱的形式.然后,设计推荐算法,利用知识图谱生成推荐.此类推荐系统通常包含知识图谱构建和利用知识图谱产生推荐两个环节.本文根据这两个环节中构建知识图谱数据的不同来源,以及推荐方法中利用知识图谱信息的不同形式提出了分类框架,并据此对相关文献进行了分类综述,详情可参见本文第3 节.与本文最为相关的是文献[3].该文献综述了2009~2017年16 篇利用知识图谱的推荐方法的文献.本文在综述的文章数量上超过了文献[3].此外,本文提出文献分类框架能够更好地覆盖新提出的方法.
本文结构安排如下:第1 节介绍了利用知识图谱的推荐方法的相关背景知识;第2 节对利用知识图谱的推荐方法文献进行分类与综述;第3 节整理了目前常用的推荐系统数据集和知识图谱数据集;第4 节和第5 节分别讨论了应用知识图谱的推荐系统的研究难点与发展前景;最后,在第6 节中对全文进行了总结.
1 背景知识
本节介绍了推荐方法与系统、知识图谱等相关领域的背景知识,并对本文涉及的知识图谱与推荐系统相关术语与概念进行了说明.
1.1 推荐方法及系统概述
推荐系统通用架构流程如图1所示.推荐系统一方面从用户处收集用户信息和历史行为,挖掘用户偏好;另一方面,收集和挖掘被推荐物品的信息和特征.然后,建立评价模型,据此对用户需求信息和物品特征信息进行匹配、筛选,得到用户可能感兴趣的物品.最后,将推荐结果返回给用户,并根据用户的反馈,进一步改进推荐结果.
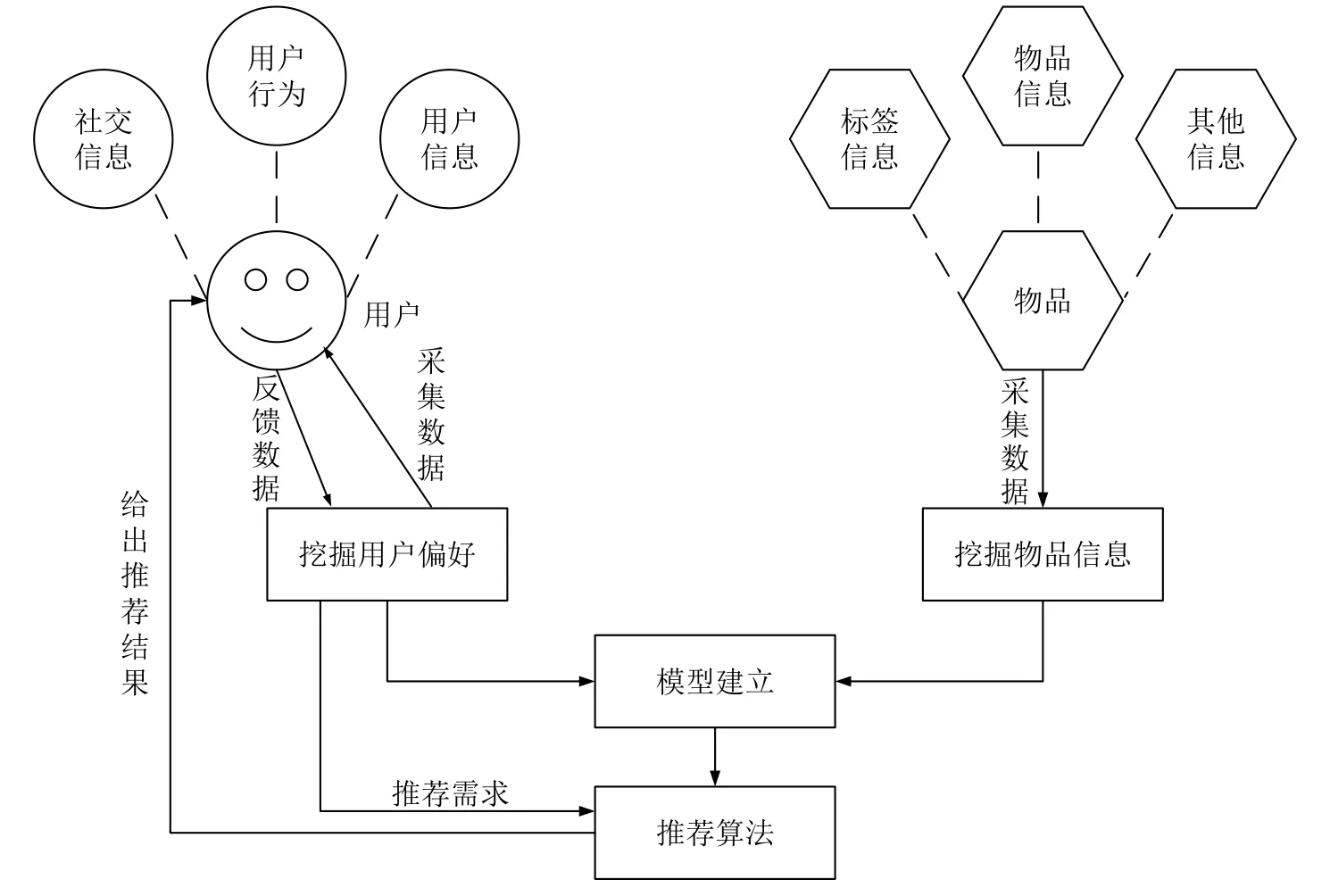
图1 推荐系统通用架构Fig.1 General architecture of recommendation system
传统上,推荐系统被分为基于内容的推荐系统、协同过滤推荐系统和混合推荐系统[4].基于内容的推荐系统关注用户和物品的特征描述.该方法根据用户与物品的交互历史(如选择、购买、浏览历史等)[2],从待推荐物品中选择特征匹配度高的物品作为推荐结果.这类推荐方法首先挖掘物品的内容特征,再与分析建模得到的用户偏好进行相似性分析.基于内容的推荐系统优势[5]在于这类方法往往有比较成熟的数据挖掘、聚类分析方法提供支持,并且对推荐任务相关的领域知识要求低.但这类方法的效果受提取物品特征能力的局限.特别是对图片、音频和视频等物品的信息挖掘、提取特征的方法还需要进一步研究完善.另外,此类方法得到的推荐结果往往局限于同一类或相似的物品,推荐结果缺乏多样性.此类方法不可避免地面临新用户的冷启动问题.
协同过滤推荐系统的基本思想来源于生活中的日常经验:人们在挑选物品时,往往受到身边朋友的选择影响;另外,人们往往会喜欢与挑选的物品相似、且被其他人高度评价的物品.文献[5]中指出,协同过滤推荐一般分为三类:基于用户的方法、基于物品的方法和基于模型的方法.基于用户的方法为用户推荐有相似偏好的用户喜欢的物品;基于物品的方法则是找到与用户喜欢的物品相似的物品,将其推荐给该用户;基于模型的方法通过建立一个用户描述模型来进一步预测评价.协同过滤推荐系统优势[6-7]在于推荐性能会随着用户数量增长而提升,擅长处理特征信息难以挖掘的物品.但也存在新物品带来的冷启动问题,并且受到数据稀疏性问题的制约[5].
实际应用中针对具体问题采用推荐策略的组合进行推荐,即混合推荐系统.混合推荐系统组合不同的推荐策略,扬长避短,从而产生更符合用户需求的推荐.传统的研究最多的是把基于内容的推荐和协同过滤推荐进行结合[8-11].然而,混合推荐系统也不能避免稀疏性问题和冷启动问题带来的影响.
1.2 推荐系统中的知识图谱技术
通常知识图谱被表示为形如(头实体,关系,尾实体)的三元组集合.在推荐系统应用中,头实体和尾实体可以是用户和用户购买过的物品,也可以是其他与用户或物品相关的事物,第1.3 节中将对这些概念进行详细说明.如何根据收集到的数据(或链接外部相关数据)构建用于推荐的知识图谱、如何从知识图谱中挖掘有助于产生推荐结果的信息,成为应用知识图谱的推荐系统的重点关注的问题.知识图谱的关键技术主要有知识抽取、知识表示、知识融合和知识推理,本节介绍在推荐系统中应用较多的知识表示和知识推理技术.
1.2.1 知识表示学习
知识图谱的三元组(头实体,关系,尾实体)表示形式能够直观描述实体与关系的结构,但是不便于计算和分析.因此,需要将知识图谱中的实体或关系表示为低维向量空间中的向量,即所谓的知识表示学习,也称为知识图谱的嵌入.知识表示的结果是推荐系统中后续利用知识图谱的基础.文献[12]较为系统地回顾了现有的知识图谱嵌入技术.其中,以TransE[13]为基础的一系列翻译模型以简约的参数、较低的计算复杂度和良好的扩展性成为最流行的一类知识表示模型.文献[14-15]分别介绍了这些模型.
TransE 模型是从一个文献[16] 中受到启发,学习实体和关系的向量嵌入的模型.但是该方法难以对1-N,N-1 和N-N关系建模,为此,提出一个TransH 模型[14]用来解决上述问题.TransE 模型和TransH 模型都假设实体和关系嵌入在相同的空间中,而TransR 模型[15]则是将实体和关系投影到不同的空间中,以处理不同的关系关注实体的不同属性的现象.为进一步细化实体与关系的交互、考虑关系对应的不同语义,文献[17]和文献[18]分别提出了TransD 模型和TransG 模型来提升知识表示性能.
1.2.2 知识推理
知识图谱中存在关系缺失或者属性缺失的问题.同时由于知识图谱构建算法错误或构建过程中的人为因素,知识图谱中也存在错误的关系或属性[19].这使得知识图谱存在一定程度的不完备性和不正确性.为此,有学者提出采用知识推理的方法对知识图谱进行补全或对其中已有关系和属性进行甄别.推荐系统中,对用户是否会购买某个物品的预测可以看做是用户和物品之间关系的补全,也可以用知识推理的方法来解决.知识推理方法主要分为基于逻辑的推理与基于图的推理两种类别[20].基于逻辑的推理通过在知识库中定义逻辑规则,实现图谱上新的关系推断.例如,文献[21]通过挖掘图谱链接结构中的信息构建逻辑模型.基于图的推理方法利用关系路径中蕴涵的信息,来预测它们之间的语义关系,或者预测与给定实体关联的另一个实体.文献[22]中将知识补全任务与推荐任务相结合,来推测针对用户的推荐结果.
1.3 相关术语
本节对本文中用到的知识图谱与推荐系统的相关概念术语进行阐述和说明.
1)用户.本文中的用户是指推荐系统的服务对象.推荐系统中,用户通常用年龄、性别、职业等个人信息来描述.同时,推荐系统也会收集用户的历史行为、社交关系等数据.这些数据和用户个人信息是推荐系统产生推荐的重要参考.
2)物品.本文将被推荐的对象统称为物品,被推荐的对象可以是实际的商品,也可以是新闻、音乐、电影等,或者是为用户提供的某种服务.
3)实体.知识图谱的基本元素.知识图谱中的实体通常是指现实世界中事物.实体可以是实际存在的事物,也可以是虚拟的概念.将知识图谱用于推荐时,实体包含了推荐系统中的用户和物品,也包含了与用户和物品相关的事物,例如电影的导演、书籍的作者等.
4)关系.知识图谱的基本元素,描述了实体之间的关联关系.参与推荐任务时,关系可以是用户对物品的偏好、购买、点击等,也可以是用户或物品与属性之间的关系.例如,物品的属性可以表示为三元组(衣服,颜色,红色).从知识图谱的视角看,推荐系统即是要预测“用户”与“物品”之间可能的购买、点击、喜好等关系,并根据预测的结果产生推荐.
2 利用知识图谱的推荐方法综述
推荐系统的核心问题是如何从各种信息中挖掘和提取特征,在这个过程中,信息的稀疏性和冷启动问题制约了推荐系统的效果.知识图谱作为一种结构化描述客观世界实体及关系的信息形式,包含丰富的实体间语义关联,为推荐系统提供了多样化的辅助信息来源、以及在组织、管理和理解信息方面的帮助,从而有效缓解了推荐任务中的稀疏性问题与冷启动问题.
具体而言,知识图谱引入丰富的语义关系,以便推荐系统深层次地发现用户兴趣;此外,知识图谱中多样化的关系链接,能帮助推荐系统避免过于单一的推荐结果;同时,知识图谱的三元组结构包含的关系信息帮助提高了推荐结果的可解释性.
知识图谱的技术发展还在日渐完善中,在推荐系统中的应用也是一个新兴研究领域,因此,目前关于知识图谱推荐系统的文献综述较少.文献[3]根据推荐过程中知识图谱的表现形式,将利用知识图谱的推荐方法分为基于本体的推荐生成、基于开放链接数据的推荐生成和基于图嵌入的推荐生成.基于本体的推荐生成利用对概念的细粒度的分类描述来更加精准的表示实体特征,从而挖掘出事实中蕴含的深层次信息.基于开放链接数据的推荐生成将链接数据库中丰富的语义信息融入到现有的方法中,着重考虑用户偏好、物品属性之间的相似度.通过利用数据库中大量相互关联的数据,更加精细化的衡量物品之间的相似性,挖掘用户的偏好,最后结合上下文信息生成推荐结果.基于图嵌入的推荐生成基于随机游走等算法对图中节点进行采样生成节点序列,然后通过神经网络或者是其他机器学习算法将节点序列以及边映射到低维向量空间.
本文将近年提出的应用知识图谱的推荐方法和系统进行了综合分析,整理了利用知识图谱的推荐方法和系统的通用流程,提出基于此流程的分类框架.该分类框架依据构建知识图谱的数据来源将利用知识图谱的推荐系统和方法分为利用本地数据构建知识图谱和链接外部知识图谱两类方法;针对推荐生成过程中利用知识图谱信息的不同形式将现有方法分为基于向量表示的方法、基于路径的方法和基于邻域的方法三类.对现有方法的分类框架如图2所示,我们在每一类方法后面列出了有代表性的文献编号.每类方法将在第2.2 节和第2.3 节中详细介绍.本节的最后整合分类结果,综合分析了近年研究的贡献与特点.
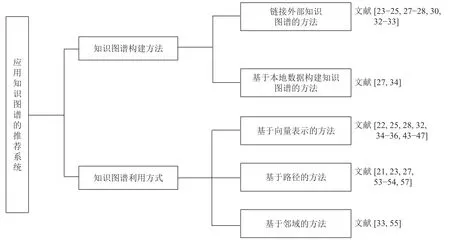
图2 应用知识图谱的推荐系统分类树形图Fig.2 Classification tree diagram of recommendation system using knowledge graph
2.1 应用知识图谱的推荐系统流程
如图3所示,应用知识图谱的推荐系统的流程主要有如下步骤:

图3 应用知识图谱的推荐系统框架流程Fig.3 Framework flow of recommendation system using knowledge graph
1)根据推荐任务特点采集数据.数据一般包括用户信息、物品信息、用户-物品交互信息(购买、点击、收藏等历史行为或评分).
2)根据收集到的数据(或者链接外部数据),构
建用于推荐的知识图谱.
3)设计推荐模型或方法,并利用步骤1)中收集到的数据和步骤2)中构建的知识图谱训练和验证推荐模型或方法.
4)利用训练好的推荐模型或方法生成推荐,为用户提供推荐服务.
2.2 构建用于推荐的知识图谱的方法
利用知识图谱进行推荐生成,首先要构建知识图谱.按照构建知识图谱的数据来源,现有方法可以分为链接外部知识图谱和利用本地数据构建知识图谱两类方法,本节将对这两类方法进行详细介绍.
2.2.1 链接外部知识图谱的推荐方法
外部知识图谱通常包含了更加丰富的物品信息,以及物品与其他实体之间的关系,这些实体往往是推荐系统中没有的.链接外部知识图谱的推荐方法将外部知识图谱作为已有信息的补充,一定程度上缓解了由于数据稀疏和推荐冷启动带来的问题,特别是物品冷启动问题.利用的外部知识图谱多数是公开的.这些知识图谱有易于获得、数据信息丰富、预处理成本低、易对比结果等优点,便于研究人员专注于推荐方法的设计和验证.
链接外部知识图谱的推荐方法一个关键问题是如何将推荐系统收集的数据与外部知识图谱进行链接,即要找到推荐系统中的实体与外部知识图谱实体之间的对应关系.推荐系统中的用户通常无法直接与外部知识图谱中的实体链接.现有方法大多是将推荐系统中的物品链接到外部知识图谱.
有些推荐系统中的物品(如电影、书籍等)就是外部知识图谱中的实体.这类推荐系统只要将物品与外部知识图谱中的实体按照名称或属性进行匹配就能建立两者的对应关系.文献[23]和文献[24]中均通过电影的标题和发行日期将MovieLens-1M与IMDB 数据集链接起来.
文献[25]应用了文献[26]中所述的两阶段方法(标题匹配和属性匹配),将每个电影从MovieLens-1M 数据集映射到知识库中的一个实体.文献[27]对于Amazon-book 和Last-FM 数据集,通过标题匹配将物品映射到Freebase 实体中,并且忽略物品是头实体还是尾实体的区别.同时,与仅提供物品的一跳实体的现有知识感知数据集不同,文中还考虑了涉及物品的两跳邻居实体的三元组.
文献[28]通过链接MIMIC-III(患者)、Drug-Bank(药物)和ICD-9 ontology(疾病)三个数据集构建知识图谱,其中患者、药物、疾病作为实体,患者-疾病和患者-药物形成关系.然后将疾病、药物、患者及其相应关系共同嵌入同一低维空间.文中通过构造患者-疾病二部图、患者-药物二部图来连接MIMIC-III 数据集、ICD-9 ontology 数据集和DrugBank 数据集.为构造患者-疾病二部图,MIMIC-III 提供了用于诊断的ICD-9 代码,通过字符串匹配将MIMIC-III 的诊断链接到ICD-9 中的本体.为构造患者-药物二部图,文中使用实体链接方法[29]来解决直接应用字符串匹配时由于MIMICIII 中包含的噪声字词(20%,50 ml,玻璃瓶等)导致的名称链接错误.
除此之外,一些推荐系统中的物品无法在外部知识图谱中找到对应的实体,例如一篇新闻报道、一段音乐等.这类推荐系统通常首先从物品的名称、属性、描述、评论等中提取实体,然后再进行实体链接.
例如文献[30]首先利用Freesound.org、Songfacts.com、Last.fm 数据集中的标签和文本描述来提取本地实体.然后使用实体链接和消歧工具Babelfy[31]将得到的本地实体链接到外部知识图谱(例如WordNet 和DBpedia)中,从而构建了声音和音乐两个知识图谱.
文献[32]通过在Microsoft Satori 知识图谱中寻找新闻标题(数据来源Bing News)中词语的对应实体.例如,对于新闻标题“新冠肺炎疫情席卷全球”,需要查找单词“新冠肺炎”在Satori 中对应的实体,即“新型冠状病毒肺炎(Corona virus disease 2019,COVID-19)”.知识抽取模块在抽取相应实体及实体在原知识图谱中的链接关系后,基于新闻标题构建子图谱.
还有一些方法通过构建和链接多个子图来完成知识图谱的链接.文献[33]中使用MovieLens-20M、Book-Crossing、Last.FM 和Microsoft Satori 为每个数据集构造知识图谱.首先以大于0.9 的置信度从整个知识图谱中选择一个三元组子集,对于给定的子图谱,收集所有有效的电影/书籍/音乐家的名字对应的Satori ID 来与子集中三元组(头实体,电影.电影名称,尾实体)、(头实体,书籍.书籍标题,尾实体)或(头实体,类别.物品名称,尾实体)的尾实体匹配.为简化步骤,排除有多个匹配或无匹配实体的物品.然后再将物品对应的Satori ID 与子集中三元组的头部匹配,最后从子集中选择所有匹配好的三元组作为要应用的数据.
2.2.2 利用本地数据构建知识图谱的推荐方法
依托于公共知识库的推荐方法研究不免会受到数据库结构和信息的制约,影响推荐方法的设计和应用.利用本地数据构建知识图谱的推荐方法致力于将链接知识实体与推荐数据的任务和推荐任务相融合,或者在表示实体的同时挖掘用于推荐系统的有效信息.由于推荐方法不再受到知识库数据的限制,可以利用知识图谱的结构特点,更加充分应用知识图谱相关技术.
利用本地数据构建知识图谱的推荐方法深入挖掘推荐系统中用户、物品及其关联关系等信息,以知识图谱的形式充实到推荐系统中,进而缓解数据稀疏等问题.此类方法在构建知识图谱时将用户、物品、与物品相关的其他事物(如电影的导演、演员、书籍的作者等)直接转化知识图谱中的实体.实体之间的关系包括用户对物品的购买、点击、评论等,以及物品与相关实体之间的关系,如物品与厂家之间的生产关系、书籍与作者之间的关系等.文献[27]对于Yelp2018 数据集,从本地业务信息网络中提取商品知识(例如类别、位置和属性)作为构建知识图谱的数据.为了确保知识图谱的质量,文中通过滤除不常见的实体(这类实体在两个数据集中数量都少于10 个)并保留至少出现在50 个三元组中的关系来预处理知识图谱的数据.文献[34]依据旅游预订数据集CEM 构建了包含用户和旅游目的地信息的知识图谱,其中实体包括用户类实体和旅游目的地类实体,其中旅游目的地实体包含模式(公民建筑、博物馆或海滩···)、种类(大学、剧场···)和所在城市三类属性.用户和旅游目的地之间的关系则是根据用户历史旅游行为构建.
2.3 推荐系统利用知识图谱的方法
利用知识图谱进行推荐生成,是应用知识图谱的推荐系统的主要特点.本节从基于向量表示的方法、基于路径的方法和基于邻域的方法三个方面介绍近期研究中对知识图谱的利用方式.
2.3.1 基于向量表示的方法
基于向量表示的方法利用知识图谱表示学习得到的实体/关系向量进行推荐.此类方法的实质是将知识图谱中包含的附加信息编码为实体或关系的向量表示.以这些向量表示做为补充来缓解推荐系统的数据稀疏和冷启动问题.此时,需要设计用户和物品等实体以及关系的向量表示学习方法,然后根据推荐问题的特点,设计合理的推荐模型.这些模型的输入即为用户或物品等实体以及关系的向量表示,输出通常为用户对物品的感兴趣程度的估计.由于深度学习的兴起,近年来文献中提出的推荐模型通常是深度神经网络.
1)直接利用现有知识表示学习结果的方法
基于向量表示的方法首先需要获得知识图谱中实体和关系的向量表示.最直接的方法是利用TransE、TransD 等已有的知识表示学习方法得到实体或关系的向量表示[28,32,34-36].
文献[28]针对医学推荐领域问题提出了称为安全医学推荐(Safe medicine recommendation,SMR)的框架,用于解决由于知识图谱的不完整性引起的推荐系统稳定性问题.SMR 首先通过链接MIMIC-III(患者)、DrugBank(药物)和ICD-9 ontology(疾病)三个数据集构建知识图谱,其中患者、药物、疾病作为实体,患者-疾病和患者-药物形成关系.然后应用能够将实体编码到连续向量空间的LINE 模型[37]将疾病、药物、患者及其相应关系共同嵌入同一低维空间.基于(患者,疾病)向量表示和药物表示,设计用于前k项最佳药物推荐的评分函数.数据集MIMIC-III、DrugBank 和ICD-9 ontology上的实验结果表明SMR 能够提升推荐结果的准确率.
文献[32]关注根据用户对新闻的点击历史预测用户是否会点击某个候选新闻的问题.由于新闻具有简洁、时敏、专业性强等特点,一些传统的推荐方法无法给出足够准确的推荐结果.该方法利用TransD 模型[17]学习实体的嵌入表示,同时考虑这些实体一跳关系的实体作为上下文实体.其核心部件为知识感知卷积神经网络(Knowledge-aware convolutional neural network,KCNN).KCNN 将词(用语料库或随机初始化得到嵌入表示)、知识实体、上下文实体的向量表示作为多通道输入,连续的非线性变换能在卷积过程中保持实体的原始空间关系,得到多通道的词表示:
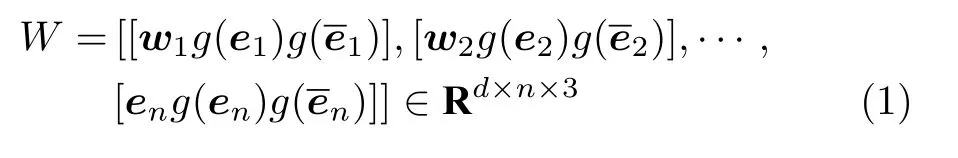
其中,n为一个新闻标题中词的个数,wi为词向量,ei为wi对应的知识实体向量,为ei的上下文向量.最后通过滤波器对多通道的词表示处理获得新闻标题的表示.注意力模块使用深度神经网络[38](一个用户点击过的某条新闻标题和候选新闻标题的嵌入作为输入)来计算一个用户点击过的某条新闻对于候选新闻的影响力权重,基于权重得到用户点击某候选新闻的概率.提出的方法用在从真实的新闻平台Bing 新闻上搜集2016年10月16日到2017年7月11日的数据进行了验证.该实验数据集包含时间戳、用户ID、新闻链接、新闻标题、用户点击次数.实验通过比较AUC(Area under curve)和F1 等评价指标,将文中提出的深度知识感知网络(Deep knowledge-aware network,DKN)与一些最先进的深度推荐模型相比较,准确率最多提高了10%.DKN 融合了新闻的语义层次和知识层次表示,通过实体和单词的对齐机制融合了异构信息源,提高捕捉新闻之间隐含关系的表现.
文献[34]提出了一种基于神经网络和知识图谱的推荐方法来预测旅行者的下一个旅行目的地.该方法在真实世界的预订数据集CEM 上获取旅客旅游信息,使用TransE 方法对构建的知识图谱中的用户实体和旅游地点实体进行向量表示学习,用户-旅游地点关系根据用户历史旅游行为构建,即用户“旅游过”旅游地点.用户实体向量、旅游地点实体向量、用户-旅游地点关系矩阵、用户统计信息如年龄、国籍等、旅游地点上下文信息作为深度神经网络的输入,通过提出的神经网络模型—深度知识分解机(Deep knowledge factorization machines,DKFM)得到一个旅客下一次选择某个旅游目的地的概率.知识嵌入信息作为输入可以有效提高推荐任务的指标表现.
文献[35]用知识图谱结合协同过滤信息,提出了一种基于图嵌入的推荐技术.文中将知识图谱节点嵌入到二维向量空间中,节点的具体映射将通过实际的图形嵌入技术来实现,如Fruchterman-Reingold 算法[39]、自组织图嵌入技术[40]、在Java 通用网络/图框架[41]中实现的图嵌入、Kamada-Kawai 技术[42]等,并通过为每个节点分配的实值坐标来定义节点之间的欧几里得距离.对于用户-物品评分,文中选择从相似用户的评分出发定义一个用户对物品的迭代评分函数,评分函数以时间戳升序遍历已知评分值列表,然后将代表已知评分值的边添加到知识图谱中.对冷启动实例(指该方法无法为其生成达到要求长度的推荐列表)的数量、精度、召回率等指标的评估表明,与通常的协同过滤进行前k项推荐的方法相比提高了性能.
文献[36]将音乐推荐表述为知识库补全任务,为单个用户提供、个性化的音乐推荐.该方法将用户视为与艺术家/专辑相关的知识库中的特殊实体,利用知识嵌入算法TransE 得到用户和物品的向量表示.用如下函数估计用户u与专辑或艺术家t之间的距离
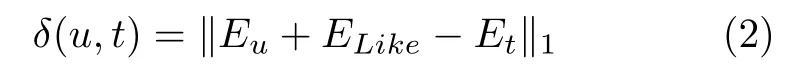
其中,‖·‖1是L1范数.Eu,ELike,Et分别是用户u、关系Like、专辑或艺术家t的训练得到的嵌入表示,通过选择距离小于定义阈值的那些专辑作为给用户u推荐的要购买的下一专辑.此推荐系统已顺利集成到基于MPD 协议的播放器中,提高了在准确率和MRR(Mean reciprocal rank)指标上的表现.
2)根据推荐问题特点改进现有知识表示学习的方法
除了直接利用已有知识图谱表示学习方法得到实体或关系的向量表示外,一些方法根据推荐问题的特点,设计了更有针对性的用户和物品实体嵌入模型[22,43-47].
文献[22]试图通过对用户喜欢某物品的原因建模,提出基于翻译的推荐模型结合知识补全任务的KTUP(Knowledge-enhanced translation-based user preference)模型,将描述用户与物品关系的知识图谱三元组作为用户-物品关系建模的补充.基础推荐模型TUP(Translation-based user preference)由两部分组成:首先在知识图谱DBpedia 上通过“硬策略”和“软策略”进行用户偏好归纳,以了解用户喜欢某个物品的原因.例如如果用户观看了由同一个人执导(关系)的几部电影(实体),可以推断出导演关系在用户做出决定时起着关键作用.其中,“硬策略”假设用户做出决定时只受一种关系的影响.“软策略”则假设用户做出决定时受多种关系的影响,这些关系按照影响重要性加权处理.其次在偏好归纳表示的基础上,定义基于翻译的损失函数Lp来作为推荐生成的约束


式中,Lk是TransH 的损失函数.文献[22]还与文献[25]中的方法进行了对比,分别通过在1-1、1-N、N-1、N-N不同情况下推荐准确率的实验结果,验证了理解用户偏好方面的优势.
文献[43]对实体间的交互和实体内的交互建模,提出了注意增强知识感知用户偏好模型(Attention-enhanced knowledge-aware user preference model,AKUPM),通过结合知识图中的不同类别实体来推断用户的潜在兴趣,使用户-物品间关系更明确,避免知识图谱中模糊的用户-物品关系带来的稀疏性问题.该方法首先利用TransR 方法获得实体的嵌入向量表示.其中,实体间交互是指当实体被包含在不同的实体集中时,实体不同属性的重要性差异很大.该方法设计了自注意网络,以某个用户点击过的物品的k阶邻域的物品的向量表示为输入,该网络通过学习不同物品对某个用户的不同重要性来表示实体间的交互.实体内交互是指对于某个用户,实体在涉及不同关系时可能有不同的特征.实体内的交互通过将实体投影到关系空间中来表示.该方法用知识图谱三元组的评分函数[15]做为点击率概率预测函数.在MovieLens-1M和Book-Crossing 上的实验结果表明AKUPM 在一些评估指标(例如,AUC,准确率(Accuracy,ACC)和召回率(Recall)@K)上取得了高于常用模型的结果.
文献[44]提出嵌入联合图谱查询的框架用于药物推荐.联合逻辑查询是药物推荐领域的常见问题,是针对多个实体间逻辑关系的预测(而不是像通常的单个边预测),通过联合查询可以推断节点集之间子图关系的存在.例如在一个不完整的生物学知识图谱上,预测哪些药物可能对与X和Y两种疾病有关的蛋白质作用,就需要同时推理所有可能与两种疾病X和Y症状相关的蛋白质.处理联合逻辑查询是知识图谱推理——预测实体之间缺失边任务的一个挑战.文中提出的方法首先将知识图谱中节点嵌入低维空间中,再通过定义的算子将查询表示为嵌入向量,根据图结构上的查询关系训练算子来优化算子的嵌入准确率.然后使用生成的查询嵌入来预测节点满足查询的可能性.该方法在两个具有数百万关系的真实数据集Bio data 和Reddit data 上能够准确预测药物-基因-疾病相互作用网络中的逻辑关系.
文献[45]考虑物品的不同属性对用户偏好的影响,提出了entity2rec 方法.该方法在仅含某一个特定属性的子图谱上,通过无监督学习node2vec[48]得到该子图上实体的面向特定属性的向量表示.进而提出了计算特定属性下用户-物品相关性(参见文献[45]中第3.2 节).最后,该方法采用排序学习方法,根据不同属性下用户-物品相关性,得到全局用户-物品相关性度量,并据此给出top-N推荐结果.作者将影评数据集MovieLens-1M 与DBpedia 相链接,在其上的实验结果显示,entity2rec 方法在P@5、P@10、M@P 指标下均优于ItemKNN、SVD、NMF、MostPop 等常用的推荐技术.作者发现依据“反馈”关系产生的推荐结果精度最好.entity2rec 方法允许系统在提供建议时考虑特定属性(例如推荐具有类似演员的电影),而且允许让排序学习算法隐式地对属性进行加权,提高了推荐结果的可理解性和精确度.
文献[46]通过融合知识图谱嵌入和推荐任务得到实体的向量表示,提出了多任务特征学习方法
(Multi-task feature learning approachfor knowledge graph enhanced recommendation,MKR).其中的交叉压缩单元将知识图谱嵌入任务和推荐任务相关联,根据推荐系统中物品与知识图谱中实体之间的交互,得到实体的向量表示.在推荐模块中,通过交叉压缩单元得到用户和物品的特征表示,用于计算用户对物品的感兴趣概率;知识图谱嵌入模块根据Microsoft Satori 知识库通过交叉压缩单元得到三元组的头实体和关系的表示,用于计算得分从而预测尾实体.除此外,通过交叉压缩单元还能调整知识传播和任务之间关联的权重,从而优化模型.该方法在MovieLens-1M、Book-Crossing、Last.FM、Bing-News 数据集上优于多个常用推荐方法.
文献[47]提出了一个贝叶斯框架BEM(Bayes embedding).该方法利用了外部知识图谱(Freebase 15,FB 15)和用户历史行为构成的行为知识图谱的信息.行为知识图谱以用户行为(如购买、引用等)链接两个被同一个用户执行该行为的物品.BEM 针对推荐任务,通过贝叶斯生成模型桥接结合外部知识图谱和行为知识图谱的嵌入(其中前者被视为作为先验数据,而后者作为观测数据),优化图嵌入.文中发现BEM 可以通过整合知识图谱信息,提高行为知识图谱的嵌入表示性能,从而改善简化为“预测用户实体与物品实体之间关系”的商品推荐任务的结果.事实证明,无论是用于预测实体间未观察到的边或是进行内容推荐任务,外部知识图谱和行为知识图谱的低维嵌入都很有帮助,两种类型的图可以包含相同实体/节点的不同信息和互补信息.但是先前的工作要么集中在知识图嵌入上,要么集中在行为图嵌入上,而很少有人以统一的方式考虑这两者.
随着图神经网络模型研究的深入,也有学者提出将图神经网络应用于推荐系统中用户和物品等实体的向量表示任务.文献[49]提出带有标签平滑度正则化的知识感知图神经网络(Knowledge graph neural network-label smoothing,KGNN-LS)来缓解知识图谱信息挖掘对手动特征工程的依赖问题.该方法首先训练用户对关系重要性的评分函数,将知识图谱转换为针对特定用户的加权图.然后将其输入到图神经网络中,计算针对特定用户的物品向量表示.为优化归纳偏差,基于标签平滑度假设[50-51](该假设认为知识图谱中的相邻物品可能具有相似的用户相关标签/分数)对边缘权重进行正则化.用户与物品的预测函数和用于约束权重的标签平滑模块共同构成训练的损失函数.在数据集MovieLens-20M、Book-Crossing、Last.FM 和Dianping-Food上进行的实验表明,提出的方法优于对比算法,而且在冷启动场景中也具有出色的性能.
3)将其他非结构化信息与知识图谱融合的方法
为了提高嵌入表示的准确性,一些文献提出将知识图谱中的结构化信息与物品的文字描述、图像等非结构化信息相融合,得到实体的向量表示,进一步产生推荐.
文献[25]融合了知识图谱的结构信息、物品描述的文本信息和物品的视图信息,提出一种协同联合学习CKE(Collaborative knowledge base embedding)方法.该方法利用扩展的贝叶斯TransR方法根据知识图谱结构信息得到实体结构信息向量表示;使用堆叠降噪自编码器(Stacked denoising autoencoder,SDAE)[52]从物品的文本信息(如书、电影的摘要、简介等)中得到其文本信息向量表示;利用改进的SDAE 方法处理物品的视图信息(如书的封面、电影的海报等图像)得到视图类信息的向量表示,其中的全连接层替换为卷积层的堆叠卷积自编码器(Stacked convolutional autoencoder,SCAE).结合上述三种信息的向量表示,构造了用户兴趣概率计算函数.这些信息从不同侧面描述了物品特征,对其进行综合利用可以帮助缓解制约协同过滤性能的数据稀疏问题.与贝叶斯个性化排序(Bayesian personalized ranking,BPR)类似,该方法采用了基于比较对的目标函数.作者在MovieLens-1M 和IntentBooks 上对CKE 进行了验证和比较.
2.3.2 基于路径的方法
知识图谱中的附加信息还可以通过分析其中节点和节点之间的路径来获得基于路径的方法着重考虑用户与用户、用户与物品之间的关联路径,基于关系和路径进行知识图谱上的推理,预测用户与物品的匹配度.捕捉用户偏好路径、设计路径传播挖掘方法从而表示用户偏好等是推荐系统中这类知识图谱应用方法的关键.与基于向量表示的方法相比,此类方法具有更好的可解释性.
1)利用知识图谱中已有路径的方法
此类方法可以直接利用知识图谱中已有的路径,形成实体/路径的向量表示或设计基于路径的评分函数,从而优化推荐算法[23,27,53-54].
文献[23]中的知识图谱嵌入方法(Recurrent knowledge graph embedding,RKGE),可自动学习实体和实体(实体包含了用户、电影、与电影相关的属性实体)之间路径的语义表示,以表征用户对物品的偏好.该方法首先在知识图谱中找到从用户到物品的路径,并且按照路径长度筛选,避免过长路径带来的噪声.其次在由嵌入层和注意控制隐藏层组成的循环网络中,在嵌入层中对路径中的每个实体进行向量表示学习,形成路径表示;在注意控制隐藏层将路径中某实体前面所有的实体向量信息作为输入,控制阈值优化下一个实体的向量表示.最后通过显著性判断赋予两个实体之间不同路径不同的权重,得到实体间的关系预测函数.在基于Movielens-1M 和IMDB 数据集上验证了提出方法的有效性.
文献[27]设计了一个知识图谱注意网络(Knowledge graph attention network,KGAT),从相似用户、相似物品属性之外的角度来处理用户偏好推荐问题.该方法在考虑知识图谱的路径传播时,尽量沿着不同的关系扩展用户与物品之间的路径.该方法主要是为了对用户和物品之间的多跳关系建模.建立的知识图谱注意网络KGAT 包含三层:协同知识图谱(Collaborative knowledge graph,CKG)嵌入层、注意嵌入传播层、预测层.CKG 嵌入层采用TransR 方法学习向量表示,注意嵌入传播层通过实体关联路径传播、知识感知模型构建、信息聚合三个部分,得到用户、物品的多维向量表示.最后设计用户对物品的评分函数为神经网络得到的用户和物品的向量表示的内积.通过对损失函数的优化学习知识图谱注意网络中的参数.该方法的结果与文献[55]中RippleNet 方法等相比有了显著的性能提升.
文献[53]提出了一种可解释的交互驱动用户建模(Explainable interaction-driven user modeling,EIUM)算法,该方法除利用了物品的内容信息(如文字描述、图像等)来缓解数据稀疏问题外,还利用知识图谱来构建可解释的顺序推荐器.所谓顺序推荐是根据用户的历史行为序列来预测其当前可能需要的物品[56].该方法首先融合了物品的内容信息和知识图谱中的结构信息,利用知识图谱表示学习方法得到物品和关系的向量表示,然后提取用户-物品对之间的语义路径,例如和是知识图谱中用户user和电影m5之间的两条不同语义路径.在交互表示模块中设计了基于注意力机制的神经网络,将用户-物品语义路径上融合了内容信息和结构信息的实体向量输入到该网络中,得到每个语义路径的向量表示,结合赋权的池化层计算每条路径的重要性得分.在顺序交互建模模块中,基于物品的表示,定义了表示用户偏好的预测函数,用来预测用户选择某个物品的概率.最后,对两个模块的目标函数进行联合训练.该方法通过对用户-物品对之间的语义显式路径(而不是隐式嵌入)进行建模,通过赋权的池化层中每条路径的权重产生推荐结果,使推荐系统能够按路径进行解释.在MovieLens-20M 上进行的大量实验表明,就准确性和可解释性而言,该方法在提出顺序推荐建议方面具有更好的性能.文中表示将进一步研究将用户的个人资料和上下文信息与外部知识图谱结合在一起,以解决冷启动推荐问题.
文献[54] 提出的策略引导路径推理(Policyguided path reasoning,PGPR)方法,将推荐问题转化为在知识图谱中寻找以用户为起点物品为终点的路径的问题,并据此提供推荐的理由.该问题通过强化学习的方法来解决.核心路径推理方法是,将用户向量表示和在定义的评分函数下与用户评分计算在阈值内的(关系,实体)集合所形成的路径,基于其路径推理策略、路径跳数限制和每一跳的采样范围,输出路径集合、跳跃概率集合和跳跃奖励集合.用马尔科夫决策过程描述实体间的路径传播,定义了实体的路径状态表示、基于用户的(关系,实体)对的采样限制、终点态实体的“软奖励”、路径状态转移的概率函数、用于最优化奖励的随机策略优化函数,得到针对单个用户的路径推理策略.其中基于用户的(关系,实体)对的剪枝由定义的评分函数进行.在Amazon e-commerce 数据集上取得了出色的结果,且结果能够展示可解释的推理过程.
除利用实体间的单条路径外,一些方法同时挖掘知识图谱中多条路径蕴含的信息.例如,文献[24]利用知识图谱的连通性来挖掘用户偏好,提出了知识路径递归网络(Knowledge-aware path recurrent network,KPRN)模型.该方法重点关注路径中的顺序依存关系和整体语义建模.KPRN 嵌入层将实体、实体类型和指向下一节点的关系三者嵌入向量空间;LSTM(Long short term memory)层按顺序对用户和物品之间的实体和关系语义信息进行编码,从而生成路径的表示;最后结合多条路径表示,计算用户对物品的评分.其中,定义了一个含超参数的函数来区分用户和物品之间不同路径的权重影响,并且展示了用于预测一个用户评分的三条路径以表明可解释性.在MovieLens-1M 和IMDb 上进行了实验,表现出对协同知识嵌入(Collaborative knowledge base embedding)和神经因子分解(Neural factorization machine)方法性能的提升.
2)挖掘路径规则的方法
为了获得更好的可解释性,一些学者提出挖掘已有路径中蕴含的推荐规则来产生推荐.此类方法通过挖掘已有路径中的推荐规则,提高推荐结果的有效性和可解释性[21,57].这种推荐规则具有普适性,能够在一定程度上缓解数据稀疏和冷启动问题.
文献[21]使用称为ProPPR 的通用概率逻辑系统研究了提高基于知识图谱推荐系统性能的三种方法.EntitySim 模型仅使用知识图谱单一实体-关系路径链接结构构成规则集,进行预测.扩展模型TypeSim 建立在EntitySim 之上,另外模拟了实体类型的流行度和相似性,使用节点的类型信息来优化图谱路径.提出的基于图的潜在因子模型GraphLF结合了潜在因子分解[58]和图谱优势,主要规则是潜在因子相似性simLF 的定义:两个输入实体X和Y,选取一个维度D,沿着D测量X和Y的值.如果有许多维度D上X和Y的值都很高,那么概率上它们的相似性得分也很高.GraphLF 沿着每个维度分别学习用户和物品的权重,计算用户与物品的相关性.三种模型在Yelp2013 和IM100K数据集上与 HeteRecp[59]模型、朴素贝叶斯模型公布的结果进行比较,在Precision@K 结果精度上有大幅提升.在改变数据集密度的情况下进一步实验,发现在更高密度下,只需图谱链接结构形成规则集就足以提出准确的建议.这表明,稀疏数据集中,知识图谱是一种很有价值的信息来源,但当对于每个用户的训练样例足够时,它的效用会降低.这从侧面表现出了知识图谱在推荐系统冷启动问题中的效用.
文献[57]提出了一种联合学习框架,该方法包含规则学习模块和推荐模块.规则学习模块采用随机游走方法,从知识图谱中提取物品-物品之间的路径,进而学习以物品为中心的多跳关系模式,即规则.然后得到物品对的向量表示,其中的每一个元素表示两个物品之间由某个规则相连的概率.在推荐模块中提出了结合现有用户-物品评分预测结果和前述物品对向量表示的评分函数框架.规则学习和推荐模块的目标函数加权求和后得到多任务学习的目标函数,对该目标函数优化后即可产生推荐结果.得到的规则权重可用于解释推荐结果.该方法将基于矩阵分解的方法(Bayesian personalized ranking matrix factorization,BPRMF)和基于深度学习的方法(Neural collaborative filtering,NCF)集成到提出的评分函数框架中,作者将Amazon Cellphone 和Amazon Electronic 数据集与公开的知识图谱Freebase 和DBPedia 相链接,在其中对提出的方法进行了验证.
2.3.3 基于邻域的方法
知识图谱结构的复杂性导致单一路径的挖掘往往不能充分利用实体间的复杂关联关系.因此,一些推荐方法利用用户或物品在知识图谱中的邻接实体来挖掘更多特征,以更充分地利用知识图谱中的附加信息.将知识图谱结构以中心-邻域的方式考量,能够充分发挥知识图谱网状结构的优势,其向量形式也便于对用户或关系进行数值建模,从而产生推荐.高效利用知识图谱的邻域结构信息是这类方法研究的关键.此类方法通常可以分为物品为中心的方法和以用户为中心的方法.
1)以物品为中心的邻域方法
文献[33]考虑了物品为中心的知识图谱邻域信息,设计了端到端框架知识图谱卷积网络(Knowledge graph convolutional networks,KGCN).该方法通过在知识图谱上挖掘物品的相关属性来有效地捕获物品间相关性,相关而不是孤立的物品信息可以减轻数据稀疏性问题带来的影响.在每一层KGCN 上,首先将用户-物品关联矩阵和描述物品属性信息的知识图谱作为输入,再从知识图谱的每个实体邻居实体中抽样形成物品的“感受域”,然后将邻域实体表示与实体之间的表示偏差结合形成特定物品实体的表示.扩展“感受域”到多跳实体可以得到高阶邻居信息,推理出用户潜在的远期兴趣.基于高阶邻居信息和物品实体的表示设计用户评分函数.在MovieLens-20M、Book-Crossing、Last.FM三个数据集上的实验结果优于同期优秀推荐方法.
2)以用户为中心的邻域方法
文献[55]挖掘以用户为中心的邻域信息,以提供个性化的推荐.提出的RippleNet 首先将一个用户点击过的物品作为网络的“种子节点”,然后将种子节点作为头实体的三元组形成第一环“涟漪集”,其中的尾实体就是第一环的“涟漪实体”.以此类推,可以得到H 环的“涟漪集”.在每一环根据该环遵循的关系、头实体向量表示构建激励函数,在尾实体上作用,从而得到这一环的用户表示,所有环的用户向量表示相加形成一个用户的向量表示,从而完成用户建模过程.用户向量与用户-物品关联矩阵作为RippleNet 的输入,训练参数后得到用户和物品关联概率(也即用户点击某物品概率)的预测.在MovieLens-1M、Book-Crossing、Bing-News数据集上采用Precision@K、Recall@K、F1@K 指标评价的实验中,RippleNet 相比其他推荐方法表现出显著优势.
2.4 综合分析
在本文第2.2 节和第2.3 节对近年文献的综述基础上,本节主要依据图2 对上述研究进行进一步的分析:
1)就推荐系统中知识图谱的来源而言,由于公共知识图谱数据集便于获取,现有方法中选择链接公共知识库的较多.
2)在知识图谱利用方式上,基于向量表示的方法更受关注.因为向量学习和向量计算方面的各类算法已经较为成熟,便于结合知识图谱进行推荐的生成.
3)基于路径和基于邻域来挖掘知识图谱信息的推荐方法是有待继续发展研究的方向,理论研究和算法设计都不够完善.
3 知识图谱推荐系统数据集
本文综述的文献中涉及的数据集有推荐系统数据、外部知识图谱数据和将推荐数据和知识图谱链接后的完整数据.下面分别对这些数据进行简要介绍.
3.1 推荐系统数据集
推荐系统数据集目前较为丰富,本文涉及文献中用到的数据集主要有MovieLens、Book-Crossings、Last.FM、Yelp、Bing News、Drug interactions、IntentBooks、ICD-9 ontology、Freesound、MIMIC-III、CEM、Amazon-book、Amazon e-commerce datasets collection、All Music Guide、Alibaba Taobao.表1列出了这些数据集的主要信息.
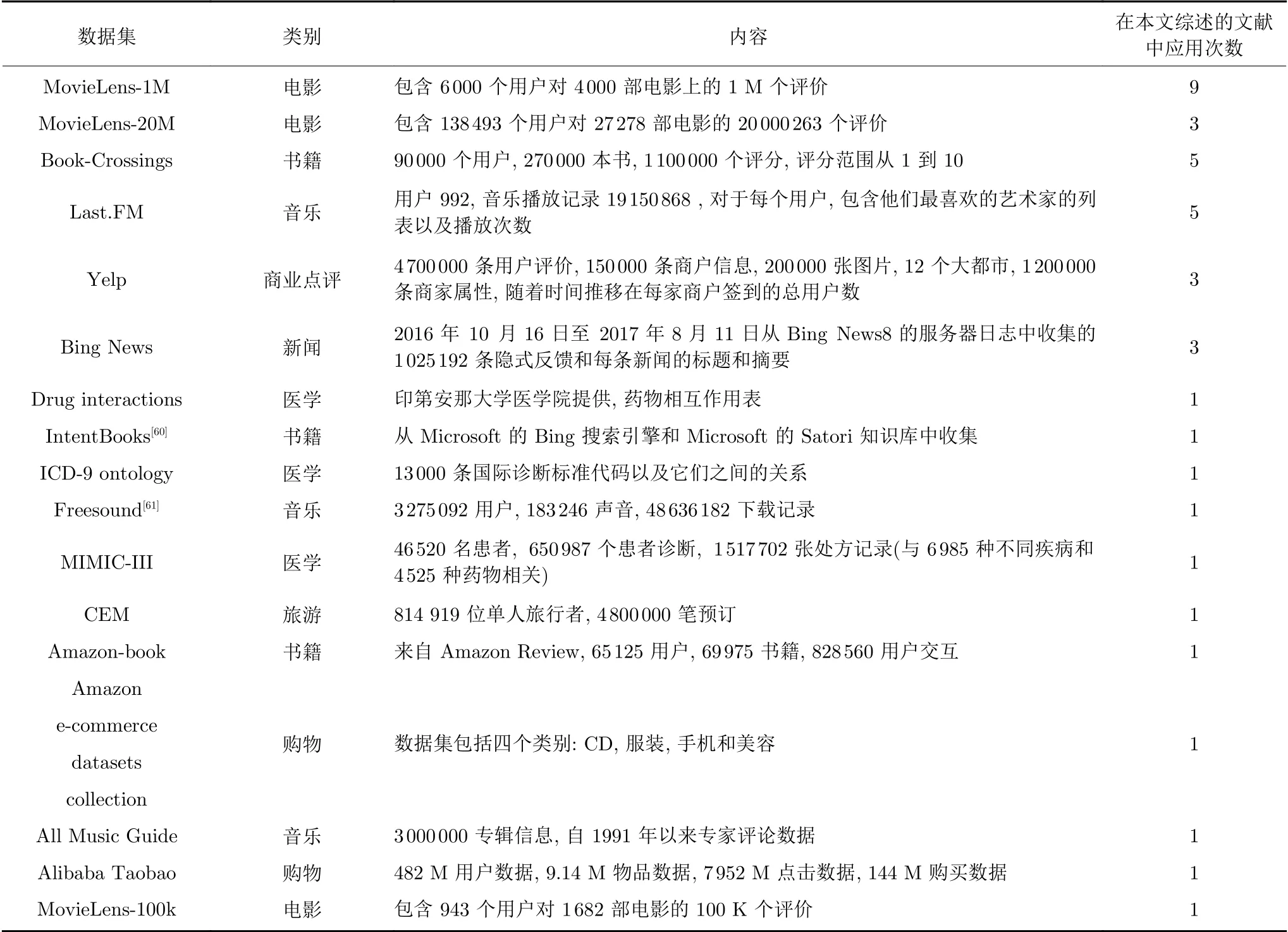
表1 主要推荐系统数据集信息Table 1 Main recommendation system datasets information
3.2 知识图谱数据集
推荐系统中链接的外部知识库数据集主要有:DBpedia、Wikidata、Freebase、YAGO,其中包含大量半结构化、非结构化数据.下面分别详细介绍.
1)DBpedia
DBpedia[62]是一个多语言综合型知识库,由德国莱比锡大学和曼海姆大学科研人员创建,从维基百科中抽取结构化信息,以关联数据的形式发布.DBpedia 的数据来源覆盖范围广阔,包含了众多领域实体信息.DBpedia 2014 版的资料集具有超过458 万实体,包括144.5 万人、73.5 万个地点、12.3万张唱片、8.7 万部电影、1.9 万种电脑游戏、24.1 万个组织、25.1 万种物种和6 000 个疾病.它不仅被BBC、路透社、纽约时报所采用,也是Google、Yahoo 等搜寻引擎检索的对象.DBpedia 还能够自动同步维基百科.
2)Wikidata
Wikidata[63]是有超过4 600 万个数据项的维基数据库(2018年),为维基百科、维基共享资源以及其他的维基媒体物品提供支持,也是Wikipedia、Wikivoyage、Wikisource 中结构化数据的中央存储器,并支持免费使用.Wikidata 可以被用户和机器阅读和编辑,包含丰富的数据类型(文本、图像、数量、坐标、地理形状、日期等),使用SPARQL 查询.Wikidata 的数据主要以文档的形式进行存储,每个文档都有一个主题或一个管理页面,并被唯一的标识符标记.
3)Freebase
Freebase 知识库[64]由美国软件公司Metaweb开发,于2007年3月公开.它整合了包括部分私人wiki 站点在内的许多网上资源内容,主要来自其社区成员的贡献.其中一部分数据来源于维基百科、IMDB、Flickr 等网站或语料库.Freebase 的结构分为三层:Domain →Type →Topic.Freebase2014版包含了6 800 万个实体,10 亿条关系信息,超过24 亿条事实三元组信息.Freebase 具有查询简单便捷的特点,在2015年6月整体移入WikiData.
4)YAGO
YAGO[65]由德国马普研究所研制,主要集成了来自Wikipedia、WordNet 和GeoNames 的数据.YAGO 融合集成了WordNet 的词汇定义和Wikipedia 的分类体系,使得YAGO 实体分类体系更加丰富,同时还考虑了时间和空间知识,为许多知识条目添加了时空维度的属性描述.目前YAGO 包含1.2 亿条三元组知识,是IBM Watson 的后端知识库之一.
5)ICD-92(国际疾病分类第9 版)
包含13 000 条诊断的国际标准代码及之间的关系.
6)DrugBank
是由医学相关实体组成的生物信息学/化学信息学数据库.版本3 包含8 054 种药物,4 038 个其他相关实体(例如蛋白质或药物靶标)和21 种关系.
3.3 链接了推荐系统和知识图谱的数据集
为了便于开展研究,一些学者将推荐数据中的物品和知识图谱中的实体建立连接后形成完整的数据集.这种数据集能够直接用于基于知识图谱的推荐算法产生推荐结果.
文献[66]提供了一个用于推荐系统的公共链接知识库(Knowledge base,KB)数据KB4Rec v1.0.该数据集将三个推荐系统广泛使用的数据集Movielens(电影)、Last.FM(音乐)和Amazon Book(书籍)与知识库Freebase 建立链接.建立链接时将物品标题作为关键词检索知识库中的实体,如果没有返回具有相同标题的实体,则认为相关推荐数据集中的项目在链接过程中被拒绝;如果返回至少一个具有相同标题的KB 实体,则进一步用辅助信息作为精确约束以准确链接(例如IMDB ID、艺术家姓名和作家姓名分别用于电影,音乐和书籍三个领域).在链接过程中,处理了会影响字符串匹配算法结果的问题,例如小写,缩写等.对于MovieLens-20M,LFM-1b 和Amazon book 分别找到了25 982、1 254 923 和109 671 个链接ID 对.文献[66]还发现物品流行度越高,越有可能在知识库中成功链接;物品越新颖,即发布时间越晚,链接比率越低.
4 应用知识图谱的推荐系统研究难点
应用知识图谱的推荐系统是一个充满挑战的研究方向,面临如下研究难点:
1)数据集制约
较完整地构建一个完整、准确、实用的知识图谱是一项艰巨且复杂的工程.因此,当前应用知识图谱的推荐系统绝大多数采用已公开的知识图谱数据集和推荐系统数据集(如第2 节中介绍).公开的数据集方便了各种方法的效用评价与比较,但同时也对方法设计造成了一定程度上的限制和影响.例如,现行的知识图谱多为描述用户-偏好-物品或者物品-属性的数据集,有利于基于内容的推荐方法和基于物品的协同过滤推荐,但基于用户的协同过滤推荐面临稀疏性问题.此外,用户与物品之间的关联在数据集中的体现往往较为单一,给进一步细化关系推理的方法设计造成了一些困难.
2)数据稀疏和冷启动问题
推荐系统大多面临数据稀疏和冷启动问题.知识图谱的加入为用户和物品提供了更多的描述信息,一定程度上缓解了数据稀疏和冷启动问题.但是,知识图谱本身也是非常稀疏的,知识图谱中的关系数量相对于实体数量非常少.同时,知识图谱也存在冷启动问题,不容易完整地获得新加入的实体与已有实体之间的关系.知识图谱的这些特点使得应用知识图谱的推荐系统同样面临数据稀疏和冷启动问题.其中,用户和物品与知识图谱中的其他实体往往关系稀疏.同时,新用户和新物品等新加入的实体难以与已有的知识图谱中的实体建立链接.
3)推荐规则单一
应用知识图谱的推荐系统在推荐建模中所依据的推荐规则往往是知识图谱中物品相似的特征、推荐系统中用户相似的评价、时空距离上相近的信息(例如新闻推荐、旅游推荐中考虑时效性)等.现实中用户的选择往往受到更多复杂因素的影响,而且不同类型的推荐任务中,推荐生成的因素可能有差异.例如电子商务推荐任务中,用户购买过耐用型产品后,短期内按照物品特征相似规则给出推荐结果,未必得到用户的积极反馈;而旅游推荐或者求职推荐任务中,特征相似的物品推荐较符合用户的选择心理.在充分利用知识图谱技术的同时,结合推荐任务情景知识,能够提高模型性能和结果表现.
4)网络社交信息
随着在线社交网络成为现代生活的重要组成部分,网络用户的交互信息成为生成推荐的重要参考.例如文献[67]将社交网络信息应用于汽车推荐领域.文献[68]则提出了基于信任关系传递的推荐模型.在社交网络中除了上述信任关系外,还包含了用户之间的其他关系,例如朋友关系、敌对关系、不信任关系等.此外社交网络中的用户影响力、交互频率、交互对象和各类隐性反馈都极具参考价值.如何应用知识图谱技术将社交网络中的多种信息进行统一表示并综合利用是一个难点问题,解决此问题有望进一步提高推荐的效率和准确率.
5)隐私安全
信息安全逐渐成为上至国家、企业,下至团体、个人都非常关注的问题.随着知识图谱信息收集和传播成本的下降带来的个人隐私的泄露,用户的个人信息保护意识在增强.推荐系统所相关的知识图谱记录、收集用户信息和行为数据的难度在增加,如何安全收集记录更多可信的用户数据,从而突破已有数据集的制约、缓解稀疏性和冷启动问题也成为一个关注点.
5 应用知识图谱的推荐系统前景展望
应用知识图谱的推荐方法和系统是推荐系统领域的一个新兴方向.目前来看,应用知识图谱的推荐方法和系统在未来的研究中有如下几个潜在的方向:
1)知识图谱应用多样化
应用知识图谱的推荐系统中,知识图谱多作为上下文信息的补充,使得用户偏好和物品特征挖掘环节能够得到更多有价值信息.随着知识图谱技术的发展,将推荐任务结合到知识推理过程中的推荐方法崭露头角,知识图谱与推荐模型之间不再是简单的辅助关系.有效利用知识图谱多样性信息,将推荐任务与知识图谱中的知识抽取、知识表示、知识融合和知识推理结合,极有可能成为应用知识图谱的推荐系统的研究方向之一.
2)图神经网络的应用
图神经网络(Graph neural network,GNN)是最近兴起的深度学习模型,此类模型能够很好地利用知识图谱的图结构.在知识图谱的表示学习、关系抽取、补全与扩展、知识推理等任务中利用图生成、图编码或图神经网络等技术,可以精确捕获许多种要结构特征信息,有助于更准确地预测用户、物品在知识图谱中的关联关系.探索图神经网络等图模型在知识图谱上应用,提高推荐的准确性、可解释性,缓解稀疏性和冷启动问题,将成为今后的研究热点.
3)直接利用现有知识表示学习结果的方法
将用户的历史行为构建为知识图谱,有助于挖掘学习用户选择物品因果关系,进而提高推荐结果的可解释性.通过训练模型学习和理解用户-物品的“配对原因”,推荐系统就如同能够“读心”.如何提高推荐系统对推理规则的感知,甚至对推理规则的自动拓展学习,都可能成为今后推荐系统设计的关键技术.
4)知识图谱的演化与用户偏好变化的联合利用
用于推荐生成的相关知识会随着时间、空间发生变化.相应的,知识图谱中的关联关系也会发生变化.同时,用户的偏好也会随着时间发生改变.例如,某些偏好可能出现周期性变化规律.知识的演化与用户偏好随时间的改变是否有某种同步关系? 两者变化的规律是什么? 如何利用这些变化和规律指导推荐方法和系统的设计? 回答这些问题需要将知识演化与用户偏好的变化相结合,开展更深入的研究.
6 结论
本文综述了2015~2019年发表在DLRS、RecSys、KDD、CIKM、NIPS、TIST、UMAP、SIGIR 等会议和期刊中的利用知识图谱的推荐方法的文献.本文根据此类推荐方法中知识图谱构建和利用知识图谱产生推荐两个环节中构建知识图谱数据的不同来源、推荐方法中利用知识图谱信息的不同形式提出了分类框架,对相关文献进行了分类综述.最后,本文分析和总结了当前利用知识图谱的推荐方法和系统的研究难点,提出了基于图神经网络的方法、考虑因果关系的推荐方法等有价值的研究方向.未来,我们将进一步研究近年的这些利用知识图谱的推荐方法在表1 中所整理的benchmark 数据集上的表现结果对比,以更全面地探讨这些方法的优势与特点.
随着知识表示、知识推理等知识图谱关键技术研究的深入,知识图谱在推荐系统将获得更广泛的应用,利用知识图谱的推荐方法和系统的研究也将获得更多关注.
