基于XGBoost算法的基础设施项目投资预测模型
——以变电站工程为例
2021-11-10管维亚张建峰卢文飞
张 旺, 管维亚, 张建峰, 陈 红, 卢文飞
(1. 国网江苏电力设计咨询有限公司, 江苏 南京 210008;2. 国网江苏省电力有限公司经济技术研究院, 江苏 南京 210008;3. 东南大学 土木工程学院, 江苏 南京 211189)
基础设施是夯实城市建设和发展的物质基础之一,其投资是加速城市化发展进程和实现城市现代化的重要举措。据世界银行测算,基础设施的存量每增长1%,GDP也会增长1%[1]。就中国而言,基础设施投资对经济增长总体上有显著的正向影响,促进基础设施投资也是中国促进经济发展的经验之一[2]。基础设施兼具“溢出效应[3]”和“网络效应[4]”等属性,投资形成的效果呈现连锁反应和投资乘数效应[5]。在中国经济进入新常态、供给侧改革加快的背景下,提高基础设施投资效率,扩大有效投资,使投资更具有针对性,将基础设施投资规划策略由粗放型转变为精准化,解决目前基础设施投资中的投资不足、投资冗余等问题,实现资源的合理配置,是当下基础设施投资亟待解决的关键问题之一。然而以往的研究主要聚焦于基础设施投资对经济增长[6]和区域发展[7]的影响、风险评价[8,9]等方面,鲜有关注基础设施投资规划、预测的研究。基础设施投资应当兼顾规模与质量,实现基础设施项目精准、高效投资的前提就在于对项目的投资进行准确预测。
在基础设施投资预测中常用的模型或方法有回归分析、神经网络模型、矩阵模型等[10]。基础设施投资中影响因素众多,且各影响因素之间呈现非线性关系,传统的统计模型方法如回归分析在应用于非线性数据时难以克服自身的局限性[11],预测精度低。为了克服社会经济系统中存在的非线性、高维、小样本等问题,神经网络模型得到了深度的应用和发展[12]。例如,唐丽春和许秀娟利用广州市基础设施基于改进的GA-PSO(Genetic Algorithm and Particle Swarm Optimization)算法对基础设施投资进行了预测[10];Asadabadi等[13]提出了一种适用于大规模应用的递归噪声遗传算法,用以研究长期交通投资规划的优化问题;Pan等[14]基于灰色神经网络,构建了发电投资动态预测模型。神经网络模型虽然预测效果较好,但是算法参数设置复杂、解释性差,尤其在小样本时易出现过学习、泛化能力差等问题。
XGBoost(Extreme gradient boosting)是一种基于Boosting的新型集成学习算法。与传统的机器学习算法相比其具有运行速度快、泛化能力强、预测精度高、鲁棒性好等优点[15],此外XGBoost算法的模型可解释性较高,能用于小样本的预测,目前已经在径流预测[16]、信用卡交易预测[17]、电机电流预测[18]等领域得到了广泛应用,但在基础设施投资预测领域尚无深入应用。因此,本文采用XGBoost算法对基础设施投资进行预测,以便为投资者提供准确的投资参考信息。同时,为了验证算法的可靠性,本文采用交叉验证的方式,对投资预测结果的可靠性进行评估,并通过交叉验证确定模型最优参数。最后以变电站工程为例,基于国网某省公司的部分变电站实例数据,对本文的模型进行检验,说明XGBoost算法的有效性。
1 XGBoost算法概述
1.1 XGBoost算法原理
XGBoost算法是由Chen等[19]在GBDT算法基础上改进的算法,该算法通过对损失函数引入正则项来控制模型的复杂度,避免了出现过拟合的问题;同时该算法还对损失函数进行了二阶泰勒展开,进一步提高了算法的收敛速度和收敛精度[20],优化了模型的性能。
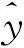
(1)
式中:fk为单棵回归树;xi为输入变量,在基础设施投资中即为各预测指标;K为回归树的个数;F为回归树所构成的空间。
为了学习得出式(1)中的函数集,需要将下面的正则化目标函数L最小化。
(2)
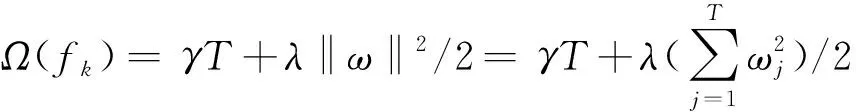
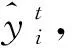
(3)
为了简化式(3)的优化过程,对其进行二阶泰勒展开,式(3)可改写为:
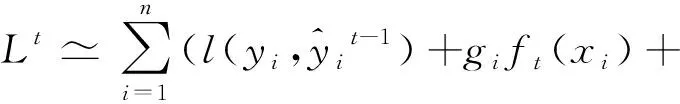
(4)
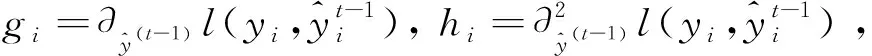
去掉式(4)中的常数项,得到第t次迭代的简化目标函数为:
(5)
设Ij={i|q(xi)=j}为叶子j的集合,将上式进行化简,可以得到:
(6)
基于以上推导,对于一个特定的树结构q(x),式(6)通过对ωj求导可以得到叶子节点的最优权重和目标函数的极值为:
(7)
(8)
(9)
式(9)的结果也叫增益,在每次分裂时选择增益最大的节点。当树达到了深度阈值或者所有节点分裂时Lsplit<0,则树停止分裂,即得到最优的集成树模型。
1.2 交叉验证与模型性能
在数据量较少的研究中,样本的划分方式及排序的随机性对预测结果影响较大,如果仅采用一组测试集与训练集,则会存在不能充分利用样本信息,导致预测准确率不高,评估可靠性不足的问题。
在K折交叉验证中,用到的数据是训练集中的全部数据。将训练集平均分割为K个互斥子集,每次选取第K份作为验证集,余下(K-1)份则作为训练集,重复该过程K次,得到K个模型对模型性能的评价,基于评价结果可以计算平均性能。由于验证集和测试集两部分数据不同,估计得到的泛化误差更接近真实的模型表现。K折交叉验证使用了无重复抽样技术的好处:每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会。通过这种方式得到的结果对数据划分方法敏感度相对较低,能提高结果的可靠性。同时,对于模型需要调整的每一个参数,都进行一整轮的K折交叉验证,如此可以找到能使模型泛化性能最优的超参值。
2 基础设施项目投资预测模型建立
2.1 预测流程
在应用XGBoost算法和交叉验证进行基础设施项目投资预测时,首要的步骤是建立相应类型基础设施项目投资预测指标体系。在确定基础设施投资预测指标体系时,需要遵循完备性、可获得性、可操作性、可比性等原则,识别基础设施投资的内外部影响因素(如建设地点、时间和技术方案、设备选型等),分项构建基础设施投资预测的指标体系(如分为建筑工程、安装工程等分项),这样不仅有利于基础设施项目总投资的预测,也有利于基础设施项目分项投资的预测。在选择投资预测指标时既要考虑全面又要甄选出关键指标,指标体系的数量选取要适度,指标过多或者过少都不利于结果的预测。在指标体系的构建过程中,可以采用主成分分析、专家访谈等方法不断对指标体系进行修正,保证指标体系的有效性,同时确保最终模型能得到可靠的结果。
在确定基础设施项目投资预测指标体系后,需要获取相应基础设施项目实例作为数据样本。将实例样本划分为训练集和测试集,训练集用于对模型进行训练,得到优质模型,而测试集则用来对模型进行检验。为了提升模型的可靠性,本文提出的模型采用交叉验证的方式,进一步将训练集均分为K份,取其中第K份为验证集,其余K-1份为测试集。在完成K次实验后取平均结果,验证其是否满足可靠性,满足则模型训练完成,不满足则对其中的参数进行优化,以满足对模型可靠性的要求。需要注意的是,对于模型中的每一个需要优化的参数,都需要进行一整轮的交叉验证,以找到使得模型泛化性能最优的超参值。在确定模型的最优参数后,在全部训练集上重新训练模型,并使用独立测试集对模型进行测试,得到最终的预测结果,同时对模型预测性能做出最终评价,基于XGBoost算法的基础设施项目投资预测流程如图1所示。

图1 基于XGBoost算法的基础设施项目投资预测流程
2.2 模型评价
为了对模型的准确性和稳健性进行评估,本文选取平均绝对误差MAE以及拟合优度R2作为评价指标。其中,MAE的取值范围为[0,+∞),预测值与真实值完全吻合时等于0,即完美模型;误差越大,该值越大。R2的值越接近1说明模型预测值对实际观测值的拟合程度越好。上述两项指标对应的计算公式为:
(10)
3 算例分析
变电站工程是电力基础设施的重要组成部分,变电站工程具有投资数额巨大、产品结构单一、项目周期长等特点。其建设对完善地区电网网架结构,满足地区用电需求,发展培育战略性能源产业,优化工业结构和推动地区经济发展都具有重要意义。在新电改背景下,有效地进行变电站投资预测,对实现电力基础设施高效益发展至关重要。由于变电站投资预测存在高维、非线性、小样本的特点,采用传统的预测方法预测精度不高且计算繁杂。因此本文构建基于XGBoost算法的变电站工程项目投资预测模型,以国网某省公司2016―2020年的部分完整变电站投资工程为例,验证本文模型的有效性。
3.1 变电站工程投资预测指标体系构建
变电站由建筑工程和电气设备安装工程两部分组成。建筑工程主要包含建筑物和构筑物,电气设备安装工程主要包含一次设备和二次设备安装以及试验和调试等。因此,本文将变电站的投资预测指标分为电气设备和建筑工程两类。建筑工程类指标主要反应建筑的组成、构造、建材用量和地基处理方式等主要内容。而电气设备类指标主要反应电气设备的组成、种类、数量、接配电型式等内容。由于电气二次设备在变电站总投资中占比较小且通常在进行较为详细的设计时才能确定,因此,本文不考虑二次设备类的指标。参考QGDW 11337-2014《输变电工程工程量清单计价规范》、DLT 5218-2005《220~500 kV变电所设计技术规程》等相关规程、规范和文献等,按照变电站电气设备和建筑工程分别对变电站工程投资预测指标体系进行初步筛选。初步筛选的指标体系中指标过多,数据繁杂,且对于预测模型的建立也具有非常大的挑战。因此,以国网某省公司2016―2020年的部分完整变电站投资工程的数据对初步筛选指标进行主成分分析。假设有m个变电站工程,每个变电站工程有n个投资预测指标,首先构建原始数据矩阵X:
(11)
然后对数据进行标准化,消除量纲和数量级对评价的影响,本文采用Z-score方法进行标准化:
(12)
根据标准化后的矩阵计算相关系数矩阵R:
(13)
式中:rij为变量xi和xj的相关系数。根据式(13)的相关系数矩阵计算得出对应的特征值λ1,λ2,…,λn以及特征值所对应的标准正交特征向量β1,β2,…,βn,构成的特征向量组为β=(β1,β2,…,βn)。
得到特征向量后,根据方差累积贡献率的大小确定提取前p个主成分,方差累积贡献率为:
(14)
则提取的主成分的权重值可以根据下式计算得到:
(15)
根据上述主成分分析方法步骤,基于国网某省公司2016―2020年的部分完整变电站投资工程的数据,本文筛选出建筑工程和电气设备部分的关键指标及对应权重如表1所示。
基于上述指标,进行专家访谈,对指标进行修正。专家指出,为了较为全面地反应变电站的建设属性,还需要考虑变电站基础特征类指标,从变电站整体角度找到对投资影响较大的因素,其中需要包含的内容为:额定电压等级、建设时间、建设地点、变电站型式、全站建筑面积、建设性质和是否为智能化变电站等几个变电站基础属性。在电气设备部分,专家认为,铜排和扁钢用量对投资影响不大,而主变压器的台数和容量,高压侧配电形式、接线形式、断路器台数和母线PT间隔,桥接线和主变进线或出线间隔等几个指标对总投资影响较大。在建筑工程部分,电缆沟对总投资影响较小,建筑工程中的地基处理方案、主控(综合楼)建筑面积、钢构和支架等用钢量、主变及进出线基础混凝土量等对投资影响较大,需要增加。在进行多轮专家访谈修正后,本文最终构建了如图2所示的变电站工程项目投资预测指标体系。
偶尔迷茫的王老师(以下称王老师):还不知道呢。现在中小学教师评职称,需要做课题、发论文。美其名曰是要打造“研究型教师”,可是光发表论文这一条要求,就不知难为了多少人呢!
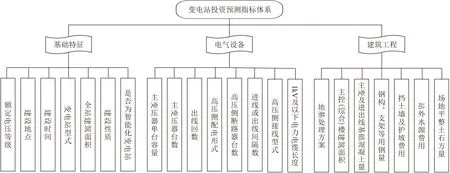
图2 变电站工程项目投资预测指标体系
在预测结果方面,本文在预测结果输出方面选择了建筑工程费和安装工程费两项进行预测。由于设备费需要根据具体的电气设备型号确定,且各型号设备之间费用差异较大,因此本文没有考虑设备费用的预测。
3.2 案例数据
本文的数据来源于国网某省公司主网工程数据,选取了自2016―2020年期间的变电站工程数据,经过前期数据清洗,删除了空缺值较多的工程,对于部分特征数据不全的项目采用回归插补法进行填充,最终共采集到642个变电站工程的数据用于本文的模型,测试集和训练集的划分比例为7∶3。文中的相关模型计算在Python 3.7的环境下完成。
3.3 模型参数设置
在采用XGBoost算法对基础设施项目投资进行预测时,需要对大量模型中的参数进行设定。XGBoost模型涉及到三类参数,第一类参数是通用参数(General Parameters),作用是设置模型的整体功能;第二类是提升参数(Booster Parameters),该类参数是选择每一步采用的booster,值得注意的是,其中的lambda和gamma对应正则项中的惩罚系数λ和γ,用来控制XGBoost的正则化部分;第三类是学习参数(Learning Parameters),作用是进行模型的优化。模型的预测结果对模型参数的具体设置较为敏感,参数设置不合理易导致模型欠拟合或者过拟合,使模型预测精度不高。本文基于网格搜索(Grid Search)搜索最优参数,并选择交叉验证后的最优结果作为模型的最优参数。在进行K折交叉验证时,不同的K值对模型性能的提升效率不同,根据Jung[21]在2017年的研究提出,建议选择K值时满足n/K>3d,其中n为样本数据量,d为特征数目。本文的样本量为642个,特征维数为25,结果为K<8.56,因此本文选择5折交叉验证进行模型参数的优化。本文选取的主要参数最终调参结果如表2所示。
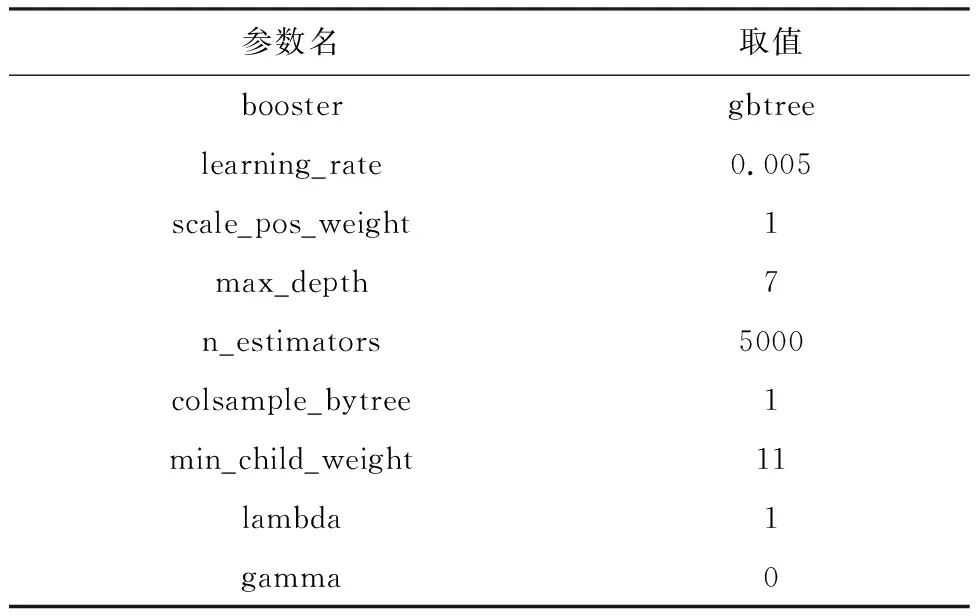
表2 XGBoost参数设置
3.4 模型预测结果分析
利用表2中调整后的最优参数对基于XGBoost的基础设施投资预测模型进行训练,再用训练好的模型对测试集数据进行预测。本文的预测值包括建筑工程投资、安装工程投资两项,最终输出的基于XGBoost的基础设施投资预测模型预测值与真实值的对比如图3,4所示。
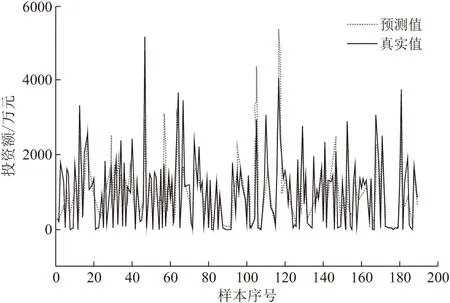
图3 建筑工程投资预测结果
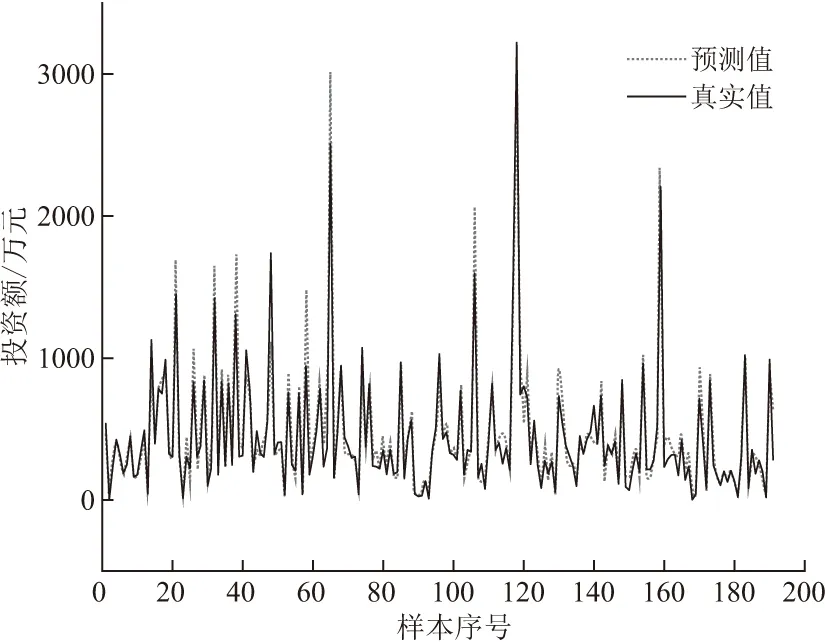
图4 安装工程投资预测结果
从图3,4的预测值与实际值的对比来看,建筑工程投资和安装工程投资的预测值曲线与真实值曲线基本吻合,说明预测值与真实值比较接近,预测效果良好,体现了本文所提出的基于XGBoost的基础设施投资预测模型效果良好。
为了进一步体现本文所构建的基于XGBoost的基础设施投资预测模型的性能,本文还采用了传统的线性回归模型和神经网络模型对本文的案例进行预测,并将MAE和R2作为评价指标,各模型的输出结果如表3所示。
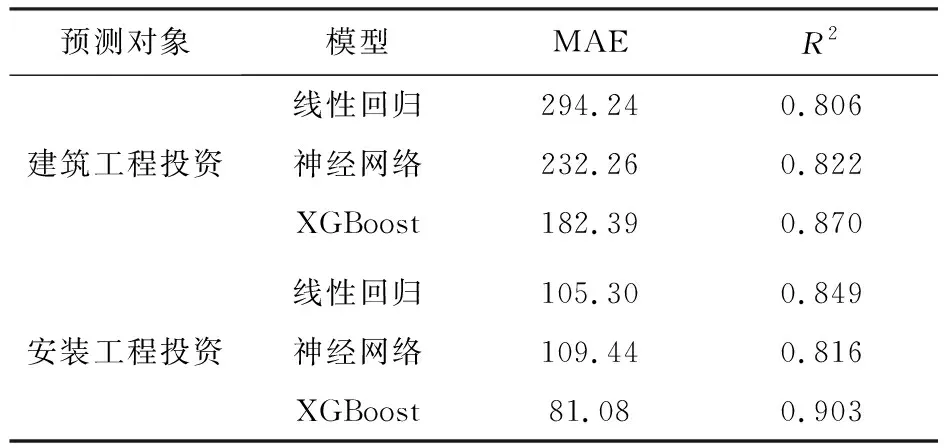
表3 模型预测性能比较
从表3所显示的MAE和R2的结果来看,本文所提出的基于XGBoost算法的基础设施投资预测模型输出的建筑工程投资和安装工程投资的预测精度均高于传统的线性回归模型和神经网络模型。其中基于XGBoost算法的建筑工程投资预测的拟合优度为0.870,安装工程费的拟合优度为0.903,相较于线性回归模型和神经网络模型均有较大的提升,均接近于1,说明了预测值与真实值之间的拟合程度很高,模型的可靠性强。从平均绝对误差来看,基于XGBoost模型的基础设施投资预测模型相较于线性回归模型和神经网络模型误差更小,预测所得的结果更为接近真实值,能为决策者提供更为准确的参考信息,实现基础设施投资的精准预测,从而依据精准预测制定合理的投资策略,提高基础设施投资效益。
4 结 论
准确预测基础设施项目投资,对于投资者而言,能够在有限的资金条件下对基础设施优化配置提供参考,实现基础设施项目高效益投资。本文通过采用XGBoost算法对基础设施项目投资进行预测,并以国网某省公司变电站工程项目实例为样本,对本文提出的模型进行了验证,并将该模型的预测性能与传统的线性回归模型以及神经网络模型的性能进行对比分析,结果显示本文提出的基于XGBoost算法的基础设施项目投资预测模型具有良好的预测性能,能够较为准确地预测基础设施项目的投资,能为决策者提供有效的参考,为项目科学化投资提供重要借鉴。
虽然本文提出的基于XGBoost算法的基础设施项目投资预测模型能够较为准确地预测基础设施项目的投资,但是提出的模型主要是针对电力基础设施投资预测,未来可对其他类型的基础设施投资做深入分析,针对具体的基础设施项目类型进行预测指标体系的确定,以形成完整的基于XGBoost的基础设施投资预测体系。
