基于对偶生成对抗网络的数字成像设备指纹提取算法
2021-11-09侯春晖田华伟肖延辉郝昕泽
侯春晖, 田华伟, 肖延辉, 郝昕泽
(1.中国人民公安大学国家安全学院, 北京 100038; 2.中国人民公安大学公安情报研究中心, 北京 100038)
0 引言
在大数据时代,数据已经成为一种重要的战略资源,在各个领域都有着重要的实际应用价值。数据的类型多种多样,图像作为信息交流的重要载体,是数据的重要组成部分,并且其中蕴含着大量的情报信息,在侦查取证与司法诉讼中都发挥着重要的作用。
现阶段对于图像的分析多是基于对图像内容进行的分析,但是图像中还有大量的其他信息可以利用。在成像时,由于数字成像设备传感器硅芯片的光响应非均质性(photo-response non-uniformity, PRNU)的影响,会在图像中留下特定的痕迹。对于每个成像设备而言,这个痕迹都是独一无二的,同时具有一定的稳定性,就像人的指纹一样,因此被研究人员称为“设备指纹”。通过对图像中提取的设备指纹进行分析,可以进一步识别图像的成像设备。基于这种技术,侦查人员可以对获得的图像进行溯源,这不仅有利于进一步明确侦查方向,进行串并案分析,还可以在司法鉴定中作为一种重要的补充证据,辅助形成完整的证据链条。
在数字图像成像时,场景内容首先在设备中转化为数字信号。这个过程中,信号要经过镜头、颜色滤波矩阵和图像传感器等进行处理,输出的数字信号再经过去马赛克、降采样、伽马校正等操作最终输出保存为我们所看到的图片。因此,在图像的成像过程中,会引入各种类型的噪声,研究者们将这些噪声作为数字图像取证的重要参考依据。传感器中的像素坏点[1-2]、CFA差值痕迹[3-4]、JEPG压缩痕迹[5-6]、镜头的色散[7-8]以及图像固有特征的组合[9-10]等都可以用于数字图像的取证。但是其中应用最多、效果最好的还是基于图像传感器模式噪声(sensor pattern noise, SPN)的图像来源取证算法。SPN中主要包括两个部分[11],即固定模式噪声(fixed pattern noise, FPN)和光响应非均质性噪声,如图1所示。

图1 传感器模式噪声的组成
固定模式噪声,即暗电流噪声,其主要是由传感器在没有受到光照的时候传感器像素之间的差异所造成的。同时固定模式噪声会受到曝光度和温度的影响,因此不易作为图像来源取证的依据。另外,在自然图像中,传感器模式噪声中最主要的部分是光响应非均质性噪声,其主要是由于传感器在制造过程中,由于硅芯片制造工艺缺陷而产生的固有噪声,具有唯一性。PRNU不受温度和湿度的影响,具有一定的稳定性。此外,PRNU中还有一部分是由于镜头上的灰尘颗粒或者镜头的参数设置等因素而产生,但是这一部分噪声不能代表特定相机传感器的特点,不能用于成像设备来源取证。综上所述,在PRNU中,仅仅是像素差异噪声(pixel non-uniformity, PNU)能够用于图像来源取证技术中。
1 数字图像的成像设备指纹提取技术研究现状
1.1 传统的成像设备指纹提取模型
成像设备指纹的提取流程可以分为滤波、联合与增强这3个阶段[12-13]。在滤波阶段,模式残差即噪声残差可以通过滤波前后的图像差值求得。传统的图像滤波方法有很多,如基于稀疏表示的方法[14],基于非局部相似性的方法[15],基于小波变换的方法[16]以及基于机器学习的方法[17]等。这些图像滤波方法往往基于高斯模型对自然图像中的噪声进行建模,但是基于传统的机器学习算法的自然图像去噪的性能已经收敛,降噪水平难以得到进一步的显著提升[18]。在滤波之后,还要经过进一步的噪声残差联合以及增强操作,从而去除噪声残差中共有的且不能用于图像溯源的成分。经过上述操作后提取的图像设备指纹中,可以保留更多的PRNU,从而能够更好地应用于图像来源取证任务当中。
1.2 基于卷积神经网络的成像设备指纹提取模型
近年来,深度学习技术在图像去噪领域中的研究取得了巨大进展。在文献[19]中,Jain和Seung等人最早采用了5层的神经网络结构来完成图像去噪任务,Burger等人则采用了多层感知神经网络[20],之后还有一些研究中采用了基于自编码器网络的图像去噪算法[21,22]。最引人注目的就是在文献[23]中提出的基于前馈去噪卷积神经网络的算法(DnCNN),其在高斯图像去噪任务中达到了优秀的性能。但是由于真实图像中的噪声分布更加复杂,因此其在真实图像去噪任务中的表现并不突出。还有一些其他的进行图像去噪的卷积神经网络,如RED[24],MemNet[25],NLRN[26],以及VDN[27]等。但是基于卷积神经网络的图像去噪模型的训练需要大量成对数据集,这是其面临的最大问题。
1.3 基于生成对抗网络的成像设备指纹提取模型
生成对抗网络的兴起为图像去噪网络的构建提供了新的可能,这一部分的研究大体包括两个方向:直接设计生成对抗网络来进行图像去噪[28]以及用生成对抗网络生成成对的训练数据来训练卷积神经网络完成图像去噪[29-32]。后者可以通过对真实图像中的噪声分布进行学习[33-34],也可以通过建模图像生成过程中相机内部的噪声引入过程来构建[35-36]。但是基于生成对抗网络的噪声建模往往有大量的超参数需要人工预先设置,以满足特定相机之间的差异。
1.4 对偶生成对抗网络
为了更好地拟合真实图像中的噪声分布规律并有效解决生成对抗网络中经常出现的训练不稳定的问题,文献[37]中提出了一种对偶生成对抗网络模型(dual adversarial network)。该模型中包括噪声生成网络与图像去噪网络两个子网络,基于对抗学习的策略,能够实现对子网络的联合训练。同时噪声生成网络中生成的数据集又能进一步加强对图像去噪网络的训练,提升其去噪能力。
对偶生成对抗网络由图像去噪网络、噪声生成网络以及判别器网络组成,如图2所示。因UNet网络训练速度较快并且对GPU的占用很少,因此去噪网络和噪声生成网络均使用的是UNet网络结构联合残差学习的策略,如图3所示。判别器网络则由5层卷积神经网络以及一层全连接网络组成,如图4所示。
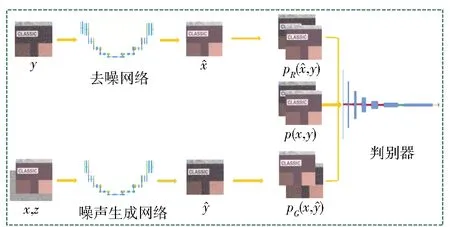
图2 对偶生成对抗网络的结构
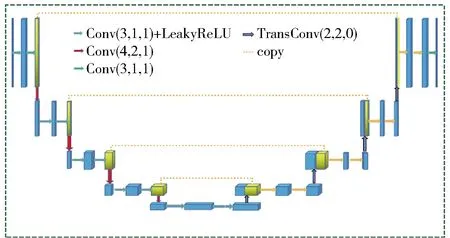
图3 图像去噪网络和噪声生成网络的结构

图4 判别器网络的结构
在对偶生成对抗网络中,未经处理的成对数据(x,y)代表SIDD数据集中提供的图像去噪网络训练集中的一对数据,x即无噪声图像,y即有噪声图像。在噪声生成网络中,还需要添加一个符合各向同性正态分布的变量z代表相机在成像时引入的与硬件相关的噪声。y经过图像去噪网络之后输出去噪之后的图像,无噪声图像x与变量z经过噪声生成网络之后生成有噪声图像,如公式(1)(2)所示。
=R(y)
(1)
=G(x,z)
(2)
在对偶生成对抗网络的训练过程中,一方面,噪声生成网络与图像去噪网络通过相互之间的对偶正则化而不断增强。另一方面,通过图像去噪网络和噪声生成网络与判别网络之间的对抗学习,使得在去噪网络中,y与之间的联合分布关系pR(,y)以及在噪声生成网络中,x与之间的联合分布关系pG(x,)最大程度地符合真实的含噪声图像与无噪声图像之间的联合分布关系p(x,y)。其中,超参数α控制着图像去噪网络R和噪声生成网络G之间的相对重要性,如公式(3)所示。
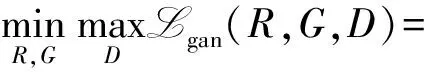
(1-α)E(x,)[D(x,)]
(3)
噪声生成网络一方面可以促进图像去噪网络的训练,另一方面也可以生成相应的噪声数据集,以进一步对图像去噪网络进行增强训练,提高图像去噪网络的去噪效果,这有效解决了图像去噪网络训练数据不足的问题。在对偶生成对抗网络框架下,图像去噪网络和噪声生成网络也可以用其他的模型进行替代。
2 基于对偶生成对抗网络的成像设备指纹提取模型
本文中提出了一种基于对偶生成对抗网络的成像设备指纹的提取模型,算法的整体框架如图5所示,具体步骤如图所示。

图5 算法框架图
(1)真实噪声提取
输入同一成像设备获取的M幅图像Ii,i=1,2,…,M,利用对偶生成对抗网络中的图像去噪模型对原始图像Ii进行去噪处理,得到去噪图像i。
(2)计算噪声残差
根据公式(4)计算任意各个图像Ii对应的噪声残差Wi,其中i=1,…,N。
Wi=Ii-i
(4)
(3)估计成像设备指纹
如前所述,成像设备指纹能够反应特定相机传感器的特点,因而能作为图像来源取证的重要依据。但是传感器中的成像设备指纹是非常微弱的,其尺寸与传感器的尺寸是一致的。根据相机的成像过程,可以建立如下手机传感器输出模型,如公式(5)所示。
I=I0+I0K+θ
(5)
其中,I为手机拍摄的自然图像,I0为原始的没有任何噪声的真实场景图像,K即是最终想要计算的成像设备指纹。这里的成像设备指纹K以乘性运算作用于I0。Θ表示随机噪声,也是多种其他噪声,如量化噪声、散射噪声、输出噪声等的混合。根据成像设备指纹的特性,通过上述步骤可以计算出来噪声残差Wi和输入图像Ii,可以求出成像设备指纹K的最大似然估计值为
(6)
(4)溯源图像噪声残差计算
输入溯源图像Iz,利用对偶生成对抗网络模型可以得到去噪后的图像z,进一步根据公式(4),可以得到对应的噪声残差Wz。
(5)相似度计算
判断溯源图像与成像设备指纹之间的相似度,可以利用峰值相关能量比(peak to correlation energy ratio, PCE)来进行计算。当PCE值超过设定的阈值,就可以判定溯源图像来自比对设备。计算PCE值,首先需要求出最大正则化的相关系数ρ[38],如公式(7)所示。
(7)
其中,
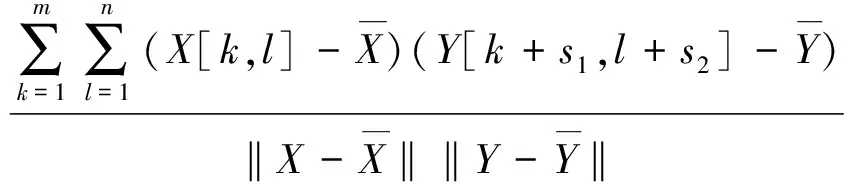
(8)
‖·‖ 为L2范数,X=I,Y=WZ,图像大小为m×n。然后,假设峰值出现在公式(7)最大值speak=[s1,s2]时,可以进一步得到

(9)
3 实验结果与分析
为了验证基于对偶生成对抗网络的成像设备指纹提取模型在真实自然图像中的性能表现,本文在当前图像规模最大的智能手机来源取证数据集Daxing[39]中进行了实验,并基于同一数据集与经典的同类算法进行了比较。Daxing数据集中包含了22个不同型号的90部智能手机拍摄的43 400幅不同场景下的JEPG图像,可以有效验证本文模型在不同品牌的手机设备及不同的拍摄场景下的实际应用效果。为了验证本文中的模型在不同的图像分辨率下的性能表现,本文将图像统一裁剪为了3种尺寸:128×128,256×256,512×512。直接训练得到的图像去噪网络记为DANet,而基于噪声生成网络生成的数据进一步训练得到的图像去噪网络记为DANet+。本文中的成像设备指纹提取模型先后采用了这两个网络进行实验,实验结果及过程分析如下。
为了验证算法的有效性,本文中的算法与基于块匹配3D滤波(BM3D)的算法[40]以及基于前馈去噪卷积神经网络(xDnCNN)的算法[41]在相同的数据集上进行了比较实验。针对每部手机,随机选取了50张用于设备指纹的提取,然后从剩余的图像中随机选取了100张,并计算这些图像的噪声残差,最后计算图像噪声残差与图像的设备指纹之间的PCE值。对这些PCE值,根据不同的阈值计算出真阳率TPR和假阳率FPR,进而得出图6中的ROC曲线。
从图6可以看出,在手机源取证数据集Daxing上,在128×128、256×256、512×512这3种不同分辨率下,本文算法既优于基于卷积神经网络的算法xDnCNN,又优于传统的BM3D算法。同时比较DANet和DANet+的实验结果可以发现,基于DANet+的实验效果要明显好于基于DANet的实验效果。因此,用噪声生成网络生成的实验数据进行训练,可以进一步提高图像去噪网络的实验效果。
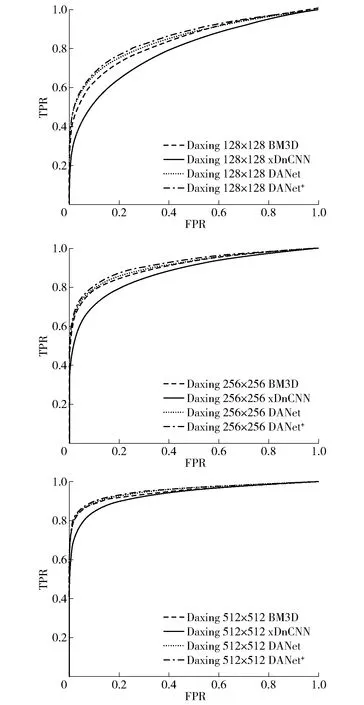
图6 实验结果比较
4 结语
本文设计了一种基于对偶生成对抗网络的成像设备指纹提取模型,该模型的实验效果既优于传统的BM3D成像设备指纹提取算法,同时也优于基于前馈去噪卷积神经网络的成像设备指纹提取算法。对偶生成对抗网络中的噪声生成模型还可以生成成对的训练数据集,以进一步提高网络模型在成像设备指纹提取中的性能表现。同时,本文在对偶生成对抗网络框架下采用了基于UNet的子网络模型,在未来的进一步研究中,可以探索其他子网络模型在对偶生成对抗框架下的成像设备指纹提取效果。
