基于Q-强化学习的干道交叉口信号配时模型
2021-11-08徐建闽席嘉鹏
徐建闽,席嘉鹏
(华南理工大学 土木与交通学院, 广东 广州 510000)
0 引言
现阶段交通问题频发,而信号配时作为交通管理的重要内容,保障了交通的秩序与效率。道路上交叉口之间存在着影响,所以现在主流的固定配时的信号控制方法尚有改进空间。因此,有学者利用机器学习算法来求解更好的自适应信号配时方法,所使用的方法主要有强化学习以及神经网络等。
ABDULHAI等[1-2]提出了一个通过Q-强化学习模型计算两相位信号交叉口的最优配时,并认为Q-强化学习具有对环境优秀的适应能力。WIERING等[3]通过引入网格网络系统,开发了基于模型的RL-TSC方法,此方法主要用于高流量的交通流,和固定配时相比可以大大降低车均延误。KUYER等[4]在前人的基础上,通过协调模型法并结合分布式算法,建立了新的RL-TSC 系统,不过该法对硬件具有一定要求,因为涉及到多个Agent间的协调。BALAJI等[5]对自适应信号配时模型展开论述,在模型中加入周边路口的交通状态、延误等因子,建立了更加完善的城市道路Agent系统的体系框架,并使之更加具有实用性与泛用性。王新[6]设计的城市TSC系统可适用于单交叉口和井字路网,利用Q强化学习算法[7-10]对信号配时决策法进行优化,可以完成相邻路口之间的信息交互。文峰等[11]接着他人的研究成果[12-15]提出使用多个深度置信网络的DQN方法,并把此方法与交叉口的信号配时相结合,提高了信号配时的有效性,但此方法强调单一交叉口,且每个交叉口都是独立的。
综上所述,现阶段对于自适应交通信号配时的研究开始逐渐涉及强化学习,但是这类研究多是针对单一交叉口,也即更加强调独立强化学习[16]。可是这些方法应用于一个拥有若干交叉口的干道时,每多涉及一个交叉口,状态空间的数量就会爆炸性地增长,就会出现维数灾难。此外,单一交叉口的研究结果对整个干道甚至整个路网效率的提升帮助及其有限。因而,本文拟提出一个基于Q-强化学习的干道信号配时优化模型, 通过引入干道相邻交叉口的信息交互机制,消除维数灾难问题。同时将此方法应用在中山市主城区的道路上进行分析和仿真,证明了方法的可行性和有效性。
1 基于Q-强化学习的单交叉口信号配时优化模型
1.1 Q-强化学习模型
Q-强化学习是一个基于值的强化学习算法,利用Q函数寻找最优的“动作—选择”策略[17]。其公式为
(1)
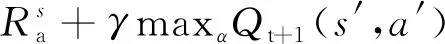
Q-强化学习的特点[18]有:
① 它根据动作值函数评估应该选择哪个动作,这个函数决定了处于某一个特定状态以及在该状态下采取特定动作的奖励期望值。
② 函数Q(s,a)→返回在当前状态下采取该动作的未来奖励期望。
③ 在我们探索环境之前:Q-table 给出相同的任意的设定值→ 但是随着对环境的持续探索→Q给出越来越好的近似。
1.2 基于Q-强化学习的单交叉口信号配时优化模型
此模型的建立方法[19]可分为以下步骤:
(1) 路口的状态空间为S,假定周期C和每个相位绿灯时间gi是状态变量。对于四相控十字路口,那么S=(C,g1,g2,g3,g4)。
(2) 交叉口信号灯配时动作的集合A对于交叉口的交通状态,把固定配时作为起始信号配时方案,再修改各个相位的绿灯时间,得到相应的信号灯配时动作的集合。对于四相控路口,设Δgi为第i相位的绿灯时间修改量,每个相位都采用3种动作,即减少绿灯时间1 s,绿灯时间不变,增加绿灯时间1 s,即Δgi={-1 s,0 s,+1 s},则A={(g1+Δg1,g2+Δg2,g3+Δg3,g4+Δg4)},此外,A是有限且离散的。
(3) 奖惩函数r(s,a)为负面回报,即行为动作a完成后,车均延误越大,函数r(s,a)随之增大,惩罚也越大。r(s,a)的计算方法如下:
(2)
式中,rt(s,a)是在状态s时,t时间步发生行为动作a得到的回报;dtk是t时间步所对应的信号灯配时动作集合A在行为动作a发生后周期内车均延误;dt0是t的起始方案在周期内的车均延误;C0、Ck是动作变化前后的信号配时方案周期。
(4) 通过以上分析,算法如下:
① 设学习速率αt、折减系数γ;
② 令t=0,把所有交叉口的Q0(s0,a0)设置成固定配时方案的平均延误;
③ 按顺序进行各个时间步;
④ 选择一个起始状态s0;
⑤ 在状态s0所对应的信号灯配时动作集合A中选一个行为动作at+1;
⑥ 执行行为动作at+1,并计算此时的回报rt+1,然后进行下一状态st+1;
⑦ 此处的目标是车辆平均延误尽可能小,从而保证Q值最小,接着利用公式迭代Q-函数:
⑧s←st+1,t←t+1,继续返回③。
单交叉口交通信号配时优化模型的基本流程如图1所示。
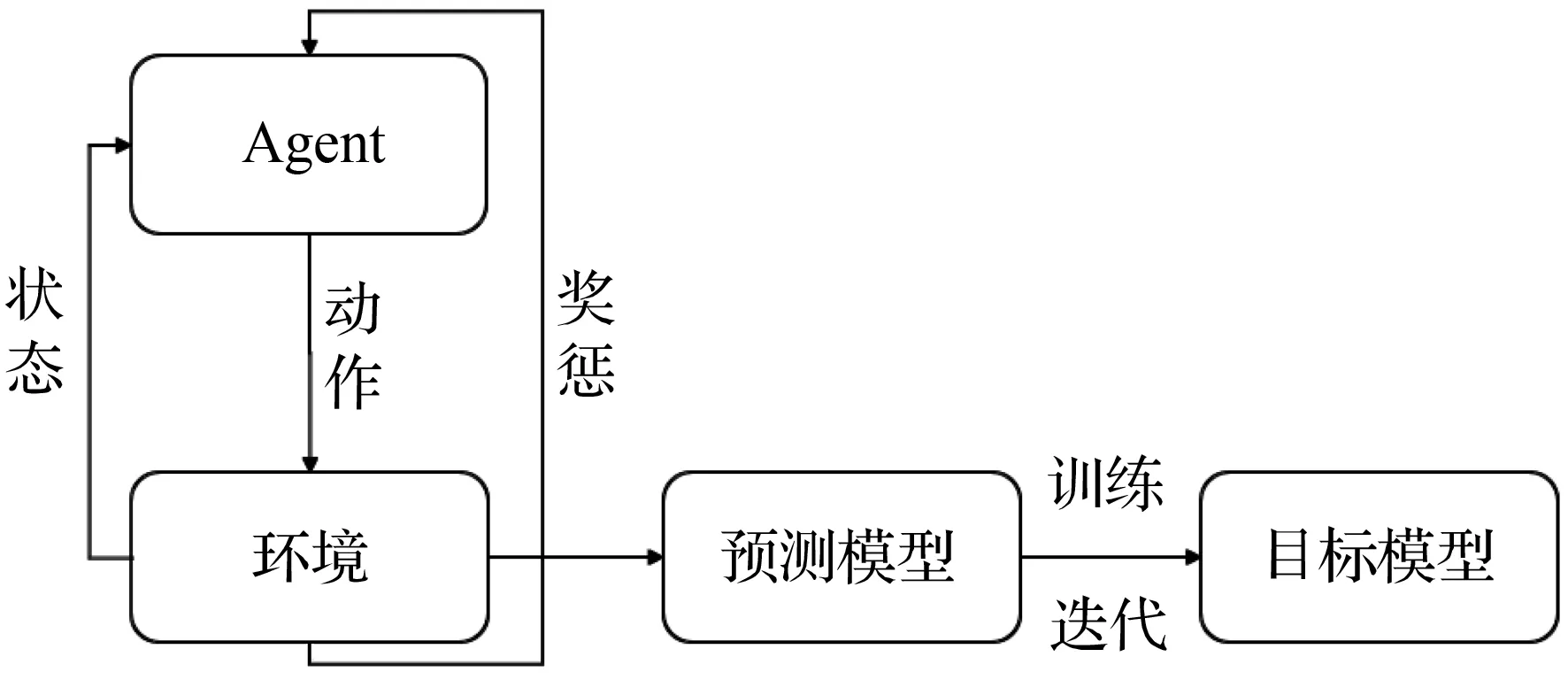
图1 单交叉口交通信号配时优化模型的基本流程
2 基于Q-强化学习的干道交叉口信号配时模型
对于单个交叉口的强化学习模型,若放在干道中使用,则具有其自身的局限性,即每多涉及一个交叉口,按照Q-强化学习的定义,状态空间的数量就会爆炸性地增长,在每个时间步内,每个交叉口Agent之间均会进行信息的交互,然后调整自身的动作,信息量会指数形式增加,长期学习过程中就会出现维数灾难。故而引入交互机制,具体方法是:干道上相邻交叉口之间,可以通过它们的交通信号控制Agent实现直接交换信号配时动作和交通状态,对单交叉口优化模型进行扩展,以达到提高干道上相邻交叉口间信息交互的效率并增强模型的适用性以及求解算法的有效性。
2.1 基本思想
干道上的各交叉口在进行本交叉口的交通信号配时决策时都会被其他交叉口尤其是其上下游的交叉口交通信号配时的变化所影响,所以在干道上相邻交叉口间,进行交通信号控制Agent的交通状态和行为动作的交互是必要的,干道Q-强化学习模型的交互过程如图2所示。
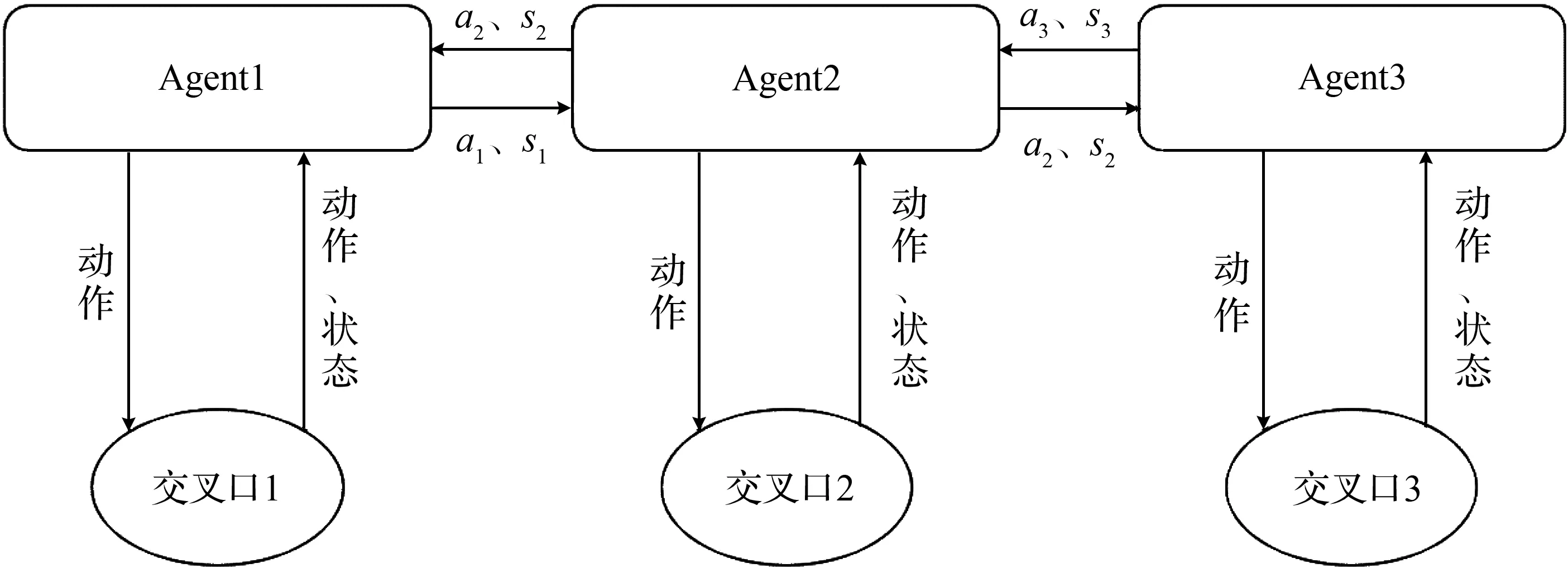
图2 干道Q-强化学习模型的交互过程
对于一条干道上的某个交叉口来说,其上下游相邻交叉口对其的交通影响最大,所以尽可能考虑其上下游相邻交叉口的状态空间可以在降低信息交互次数的同时保证模型的可靠性。在每个时间段内,先遍历这个交叉口动作集中的每一个动作,以此交叉口和相邻2个交叉口的Q值之和为目标函数,目标函数最小时,得到一个最优动作,按照这种方法,当干道上每一个交叉口Agent的动作都被改变时,跳出此时间段,等待下一个时间段重复此流程。这个方法大大降低了交叉口Agent之间的信息交互次数。
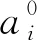
2.2 模型训练
基于Q-强化学习的干道交叉口信号配时模型(简称干道Q-强化学习模型)的模型训练方法如下:
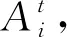
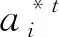
(3)
重复这个过程,等到干道上所有交叉口的交通信号控制Agent都改变了它们的行为动作为止。
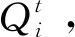

图3 干道Q-强化学习模型的基本结构框架
2.3 干道Q-强化学习模型相关参数的获取
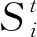
对于干道的信号控制来说,工作做到这里已经完成。但是,在城市道路中,车流量具有实时而且动态的特征,可是信号配时相位、相序、周期的调整会涉及到各个路口行为动作的选择,这对于最小时间步t的设定具有一定的影响。
按照一般情况,交叉口信号配时周期不宜小于60 s,而模型的计算时间远远小于交叉口信号配时周期,所以,最小时间步t宜设定为干道所有交叉口信号配时周期的最大值。这样可以保证每次优化都处于不同的信号周期,提升优化效率。
3 实例分析——中山市主城区示范道路路口信号优化
3.1 问题描述
中山市东区南北向最为关键的通道—兴中道,是中山市城区南北向的一条主干道,也是一条模范严管路,该道路限速60 km/h,从南至北共有5个重要信号灯控交叉路口,沿街出入出口也偏多。
交通流量数据是通过支队自建的信号控制平台中安装在路口进口道处的交通线圈检测器获取的。线圈检测器作为一种高可靠性的全场景检测手段,在实际应用中是最为可靠的车辆检测器,能够用于分析存在的主要交通特性。以下数据分析时段中早高峰时段定为7:00-9:00时,平峰时段定为9:00-11:00时。
经过实际观察以及市民反馈得到的信息,兴中道也是交通问题频发路段。以兴中道为例来进行交叉口间交通信号配时决策分析。
仿真所使用的路网如图4所示:从上到下交叉口的间距分别是: 612、681、321 m。南北为主干道方向,自由车流速度45 km/h,早高峰(7:00-9:00)时,南北向车流量qSN=1 488 辆/h,qNS=1 232 辆/h,东西向的流量分别为:qEW1=713 辆/h,qWE1=728 辆/h,qEW2=qWE2=903 辆/h,qEW3=1 072 辆/h,qWE3=1 153 辆/h,qEW4=830 辆/h,qWE4=635 辆/h。平峰(9:00-11:00)时,南北向车流量qSN=1 161 辆/h,qNS=1 050 辆/h, 东西向车流量分别为:qEW1=580 辆/h,qWE1=451 辆/h,qEW2=502 辆/h,qWE2=435 辆/h,qEW3=850 辆/h,qWE3=909 辆/h,qEW4=207 辆/h,qWE4=271辆/h。

图4 仿真所使用的路网
针对这两种强化学习模型,干道上每一交叉口的Agent在做决策用到Q-学习算法时,只受到该交叉口的状态和行为动作影响,控制中心发出指令判断需要协调的车流方向。以兴中道为例,事实上,南向北方向的车流量更大,控制中心起始选择南向北方向作为协调,仿真所使用的路网如图4所示,南向北车道上的车得到行驶优先权。
图5和图6所示分别为1、2、3、4路口早高峰(7:00-9:00)和平峰(9:00-11:00)的干道上各路口固定信号配时相位图。
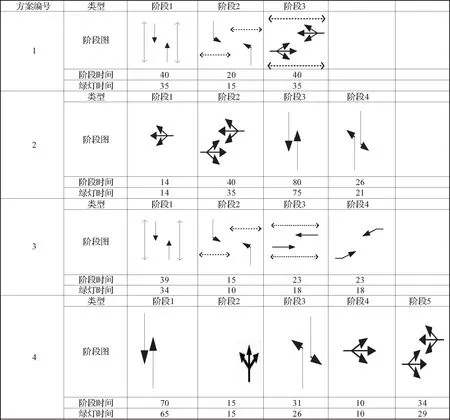
图5 干道上各路口早高峰固定配时相位图
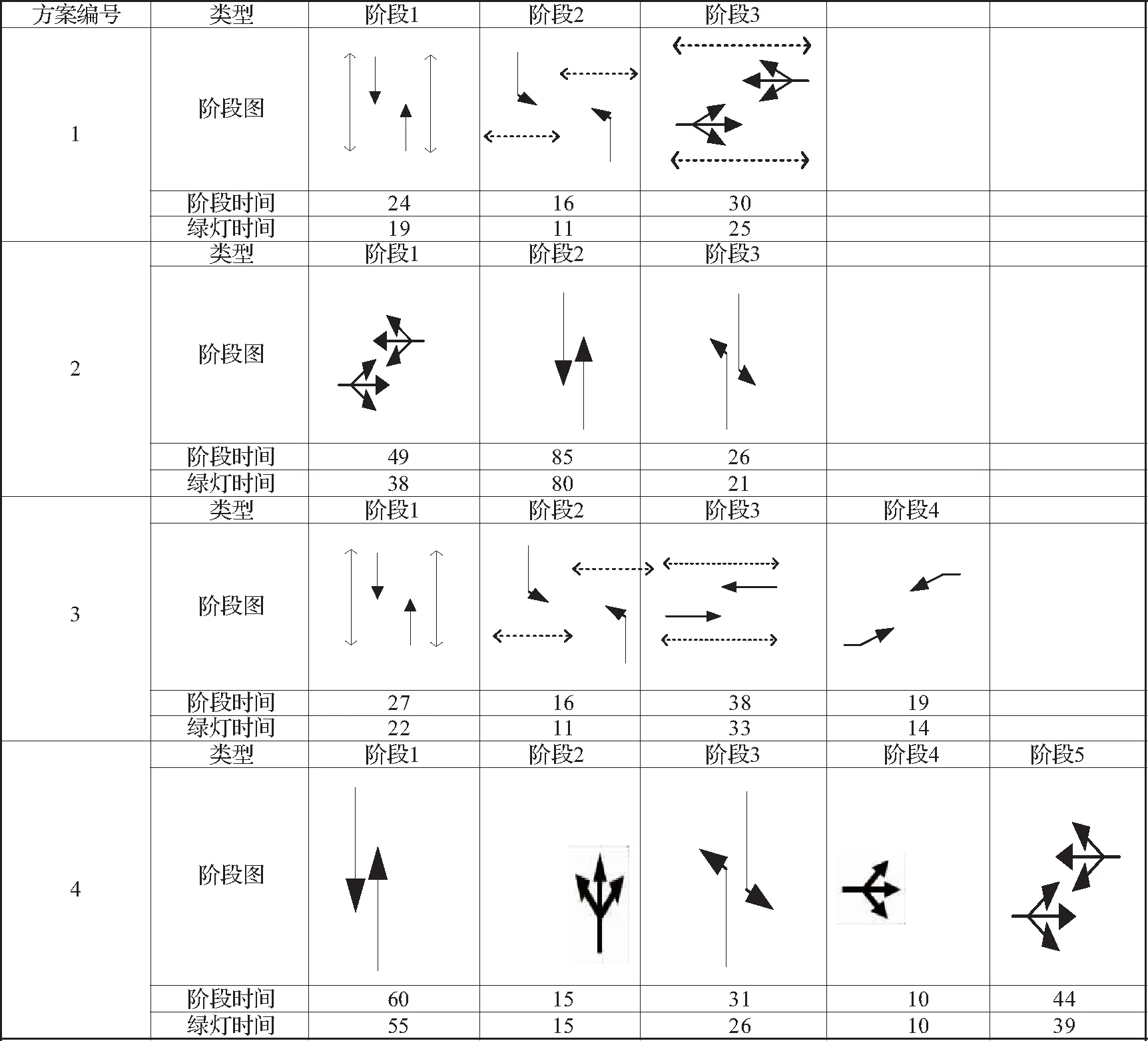
图6 干道上各路口平峰固定配时相位图
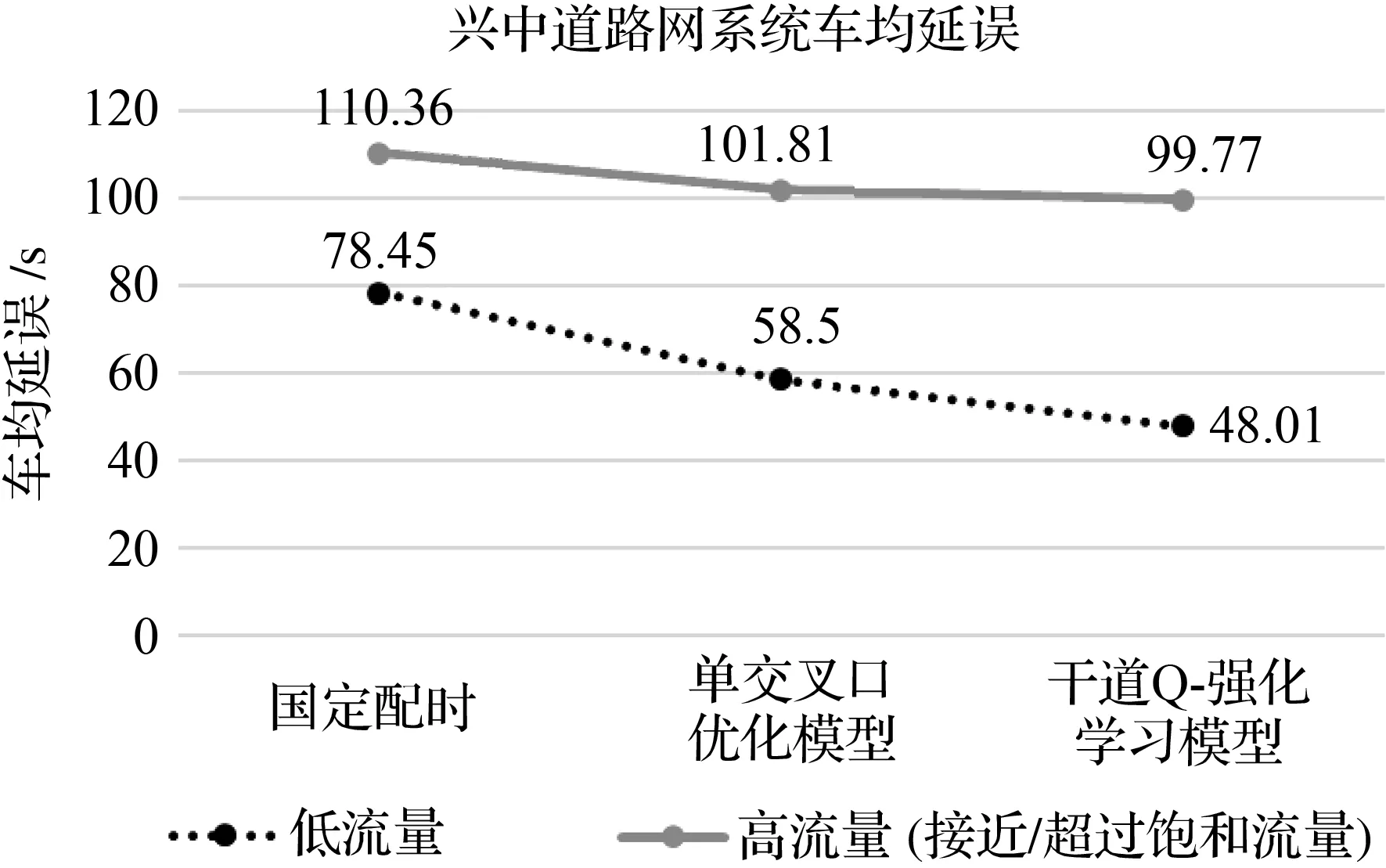
图7 兴中道路网系统车均延误
取兴中道-松苑路(2号交叉口)为模型训练的开始,Δgi={-1 s,0 s,+1 s},从而得到该交叉口此时间段的动作集,开始模型训练。
3.2 路网系统的性能分析
把上文所述的路网的平均延误当做性能指标,不同的两种车流情况下,即南北向均得到较小车流量(平峰,接近自由流)以及较大车流量(早高峰,接近饱和流量)的时候,固定配时、单交叉口优化模型、干道Q-强化学习模型3种方案仿真结果如图7所示。
总的来说,两种基于强化学习的配时方法的车均延误小于固定配时的车均延误。
经过多次仿真实验可以看出,干道Q-强化学习模型在平峰流量的情况下具备快速收敛的作用。实验证明,经过300次迭代运行后,干道Q-强化学习模型已经开始收敛,相比单交叉口优化模型还未开始收敛具有优势。当车流量接近饱和流量时,干道Q-强化学习的效果逐渐变差但仍具备一定优势。
对于平峰低流量的外部环境,干道Q-强化学习模型的收敛速度在单交叉口独立优化模型的基础上提升76.79%,车均延误降低17.93%。低流量下不同模型的收敛速度和车均延误见表1。

表1 低流量下不同模型的收敛速度和车均延误
对于早高峰高流量的外部环境,干道Q-强化学习模型不能保证模型一定收敛,10次仿真实验结果有2次并未收敛(在模型未收敛时,下一时间段的信号相位保持不变),但是在这种高流量的情况下,此模型同样具备快速收敛的作用。在收敛情况下,干道Q-强化学习模型的收敛速度在单交叉口独立优化模型的基础上提升67.77%。高流量下不同模型的收敛速度和车均延误见表2。

表2 高流量下不同模型的收敛速度和车均延误
该仿真运行结果证实干道Q-强化学习模型通过引入相邻交叉口的信息交互,有效地改善了Q-强化学习模型直接应用在干道上多个交叉口时的局限性,此模型能够改善相关交通问题。
4 结语
本文在交叉口交通信号控制单交叉口独立优化模型的基础上,利用干道相邻交叉口间的交互机制对模型进行优化,解决了该模型在实际应用中有可能出现的维数灾难问题。从仿真结果来看,当车流量处于较小水平(平峰期,此时车流状态接近自由流,车辆间干扰较小)时,基于Q-强化学习的干道信号配时决策方法对比固定配时和独立强化学习算法优越性明显,既缩短了延误,又提升了收敛速率;当车流量处于较高水平(高峰期,此时车流量接近饱和流量)时,基于Q-强化学习的干道信号配时决策方法在延误方面对比固定配时和独立强化学习算法有所改善但差别不大,在收敛速率上有一定优越性。因此,本文还存在一些后续的问题值得研究,即在较大流量时,该模型是否可以具备更强大的环境适应能力和动态协调能力,比如在这种特殊情况下,是否可以改进协调机制,添加一个新的影响因子,以达到提高交通运行效率的目的。
