基于知识发现和分层ELM的暂态失稳模式辨识
2021-11-08李欣胡晓乐郭攀锋
李欣,胡晓乐,郭攀锋
(三峡大学 电气与新能源学院, 湖北 宜昌 443002)
0 引言
近年,随着国民经济的飞速发展,充电桩,大容量储能等各种新型负荷不断地连入电力系统,系统的运行状态不断靠近稳定运行极限[1]。当出现大的干扰或故障时,如果不尽快采取有效的措施,系统将逐渐失去稳定,严重时可能会导致大规模停电,给社会带来巨大的经济损失。
当前,国内外学者致力于电力系统暂态稳定的研究,并提出了很多有效的方法,例如时域仿真[2],暂态能量函数方法[3]和扩展等面积方法[4]。虽然构建详细的系统模型可以提供准确的预测,但高额的计算量限制了算法实时应用。此外,基于系统模型的方法为了实现快速暂稳预测,难免要对系统进行一定程度的简化和假设,这可能会降低预测精度。因此,开发和运用新方法来实时识别日益复杂的电力系统的动态行为,对电网安稳运行有着重要的意义。随着相量测量单元(phasor measurement unit, PMU)在电力系统中的广泛使用,大量运行数据被收集,这些数据在很多方面能够反映电力系统的运行状态。如何从这些数据中挖掘有价值的信息来分析电力系统动态行为成为目前研究的热点。目前许多机器学习技术已被广泛用来挖掘数据中的信息,并预测电力系统的状态。例如,文献[5]将人工神经网络(artificial neural network, ANN)用于暂态稳定的评估,并取得较好的效果。文献[6]提出一种线性决策树(decision tree, DT)以提升基础DT的运算效率,并利用其实现了快速而精确的暂态评估。文献[7]利用支持向量机(support vector machine, SVM)处理高维、非线性问题的优势,将高维、非线性的故障样本进行了准确的识别。这些方法在暂态评估中认为是有效的和鲁棒的,其预测准确率通常在90%到100%之间。然而,它们在使用中依然面临着一些问题,比如ANN在处理大量的样本时会出现过拟合的问题;DT使用前需要提前获知整个样本空间的分布,对异常数据较为敏感;SVM虽能处理高维非线性问题,但其性能受到超参数的影响。此外,现有的方法其重点主要是针对故障清除后,判别系统是否保持稳定,将系统故障后的行为仅分为稳定和不稳定,少有研究发电机失稳后的动态行为。
总结相关文献发现,当前对故障后动态行为研究的难点是在海量失稳场景数据中寻找并总结功角振荡的失稳模式。有监督的聚类方法需要在应用前对分组数目或模态特征进行假定和等效,从而限制了它们在失稳模态复杂的大规模系统中的应用[8]。文献[9]提出了一种基于非监督层次聚类(hierarchical clusteing, HC)算法的在线辨识失稳模式的方法,该方法不需要在模态提取过程中预先设定分组的数量,还可以在电网失稳后识别系统的不稳定动态行为。但是,该方法仅使用数据的最后一帧对模态进行聚类,可能会忽略功角振荡过程中蕴含的重要信息,对数据集的挖掘利用不够彻底,因而算法的聚类和评估精度都有待提高。文献[10]构造了一组分类器以实现并行和连续搜索来评估不稳定样本中失稳发电机的类型。但是,该方法需要将待评估发电机的动态响应与系统其他机组做一一对比,使其面对大型复杂电力系统时计算压力较大,评估速度难以满足要求。
综合上述分析,为了解决在海量失稳场景数据中功角失稳模态难以探寻和总结的问题,本文将新型的知识发现算法(knowledge discovery by accuracy maximization, KODAMA)[11]引入模态提取过程中。作为一种无监督的数据分析方法,KODAMA充分利用数据的信息和结构来获得不稳定模式,并且在应用之前无需获知失稳模态类型、特征及数目等信息,并已成功应用于生物工程[12]和信息科学[13]等诸多领域。相比于其他传统的聚类方法,KODAMA优势在于:①无需在聚类前指定分类数目及特征,基于数据自身的特性获得分类结果;②对分类结果进行交叉验证,拥有更高的分类准确度。鉴于此,利用KODAMA充分挖掘原始失稳数据中的信息,以获得更好的故障后失稳模式。
在实际应用中,考虑到电力系统的动态行为是复杂的,单个ELM难以完全反映动态特性。为了全面准确可靠的辨识结果,设计了分层架构的ELM辨识策略。在此基础上,以失稳后的功角信息为输入量,提出了综合KODAMA和分层ELM的暂态功角失稳模式识别方法,并使用74节点Nordic系统验证所提方法的有效性。实验结果表明:与相应的评估辨识方法相比,所提算法在保证尽可能高精度的前提下,具有相对快速的评估速度。
1 极限学习机和KODAMA概述
1.1 极限学习机
极限学习机(extreme learning machine, ELM)是一种用于训练单隐藏层前馈网络的数据驱动算法[14],其结构包括输入层,隐藏层和输出层三部分。假设给定一个输入向量xi=[xi1,xi2,…,xiN]T∈RN和目标向量yi=[yi1,yi2,…,yiN]T∈RM,M为目标向量的维度。这样就有N个独立的样本(xi,yi)。ELM的输出结果表示为
(1)
式中,ωi表示输入权重;βi表示输出权重;bi表示隐含层神经元的阈值;L表示隐含层神经元的个数;g(x)是激活函数。
ELM的特点在于在学习过程中通过随机给定神经元的权值和阈值参数可以使网络逼近任意连续系统并获得最优解,具有训练时间短,学习效率高和泛化能力强等优势。因此,ELM能够有效地处理电力系统大扰动后大量的运行数据。
1.2 KODAMA算法
最大精度知识发现算法KODAMA是一种无监督聚类算法,其算法核心由一个不断更新的交叉验证程序驱动,该交叉验证程序基于Monte Carlo算法对当前聚类结果进行交叉验证。根据交叉验证结果,对聚类模型和验证数据集拓扑进行修改和更新,最终给出基于数据集自身特性的交叉验证精度最高的聚类模型。KODAMA的流程如图1所示,详细的聚类计算过程如下:
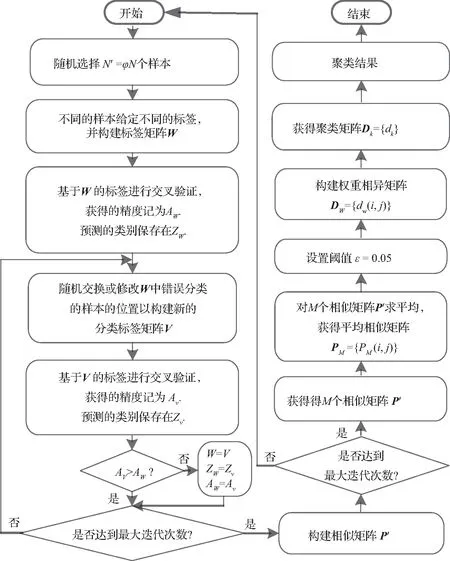
图1 KODAMA的流程
Step 1:从总数据集中随机挑选N′=φN个样本构成聚类子数据集(N为总数据集样本数,φ为比例系数)。对子数据集中的每一个样本,首先给予不同的分类标签W=[w1,w2,…,wN’]。此时算法共创建了N′个聚类模态,且每个样本的聚类标签都不同。然后基于K-近邻算法的10折交叉验证程序对聚类结果进行交叉验证。整体验证分类精度按式(2)计算,并保存在AW中。第一次验证后的分类精度AW=0。
(2)
式中,C表示被正确分类的样本个数。
Step 2:算法随机交换或修改部分被误分样本的位置及标签,构成新的分类标签V=[v1,v2,…,vN′]。重复上述交叉验证程序对新的聚类结果进行交叉验证,并计算新分类标签下的分类精度Av。若Av>AW,则用新的分类标签V代替W,Av代替AW。重复此步骤直到AW=100%或达到最大的重复迭代次数上限。
Step 3:构建相似性子矩阵P1′(i,j)={p1′(i,j)}。具体方法为:若聚类子数据集中第i个样本与第j个样本属于同一类(wi=wj),则p1′(i,j)=1;若第i个样本与第j个样本不属于同一类(wi≠wj),则p1′(i,j)=0。重复上述步骤M次。最终获得M个不同的相似性子矩阵PM′(N′×N′)。
高占斌(1971—),男,河北张家口人,副教授,硕士生导师,博士生,研究方向为内燃机性能、排放及增压技术。
Step 4:不同样本之间的关联度由M个相似性子矩阵综合给出,最终构成相似性矩阵P:
(3)
式中,K(i,j)为样本i与j同时被选入聚类子数据集的次数。P(i,j)的取值范围为0到1,值越大,说明样本i与j被同时分为同一模态的相对次数越多。最终的聚类结果由关联度阈值ε决定。P(i,j)>ε将相互间的样本聚合为同一类;若P(i,j)<ε,则将样本i与j其所连接的样本分为不同的类。采用欧氏距离计算多维空间中N个样本的距离d(i,j),从而构建加权相异矩阵DW={dw(i,j)}。其中,dw(i,j)表示加样本距离d(i,j)与样本i和j属于同一类别的概率P(i,j)的比值,如式(4)所示:
(4)
基于Froude算法,可以获得最终的相异度矩阵Dk={dk(i,j)},其中是任意两点之间的最短距离。对于每一个h≤N,dk定义如下:
dk=min[dw(i,j),dw(i,h)+dw(h,j)]。
(5)
2 基于KODAMA和分层ELM的暂态失稳模式识别方法
基于KODAMA和分层ELM的暂态失稳模式辨识方法的整体评估思路如下:首先基于生成的电力系统原始数据集,采用ELM将这些样本分为稳定样本和不稳定样本。随后,利用KODAMA算法对不稳定的样本进行聚类以获得失稳后的模式,并构建失稳模态集;然后,根据获得的聚类的簇数,给每个样本标注相应的失稳类别标签;最后基于分层ELM和获得的失稳模态标签进行有监督的训练,最终构建出用于故障后失稳模态辨识的评估模型。所提出的总体评估流程如图2所示,分为5个步骤:原始数据集的构建,基于ELM的稳定分类,KODAMA的失稳功角的模式提取,分类评估模型的构建以及在线识别应用,各个部分的详细描述如下:

图2 总体评估流程
2.1 原始数据集的构建
为了满足智能暂态稳定性评估的要求,数据样本集应包含尽可能多的有关于系统稳定性的动态信息。一般用于暂态失稳模式辨识的电力系统原始数据集是通过大量离线仿真建立。为了充分反映电力系统的运行状况,在数据生成过程中应考虑不确定因素的影响。不确定因素的采样基于24 h历史或预测数据的概率分布。考虑到发电机的暂态稳定性直接取决于发电机转子角的动力学特性,本文采集发电机的功角作为原始数据的特征量。具体的数据生成过程考虑了故障场景中负荷分布、发电机出力和故障设置三类不确定因素的对功角稳定的影响,具体设置如下:首先考虑负荷变化对系统运行状态的影响。参考文献[16]中的设置过程,所有负荷在满足正态分布的方式下随机获得初值,其分布函数是期望值为系统给定值,标准差σ=3.33%的正态分布。为了模拟现实中负荷增长情况以获得更多的样本,在保证功率因数基本不变的前提下,仿真中所有负荷都按同样的增长率在其初值的90%~120%变化。发电机出力根据负荷分布、基于经典发电费用函数,考虑全网发电成本最小的最优潮流给出。短路故障类型为最严重的三相短路,所有短路故障随机设置在各条线路上。
2.2 基于ELM的暂态稳定性识别
电力系统的暂态失稳常常表现为发生大扰动后,功率不平衡导致发电机之间相对转子角非周期性增大,进而生成不平衡转矩,致使转子进一步加速运动,最终两侧电源功角差超出规定的稳定范围。因此可以通过暂态过程中的发电机功角差的大小来判别系统暂态稳定性。当系统进入暂态失稳状态后,发电机的功角会基于不同的动态响应分为不同的组别,有些组别的发电机会继续保持相互同步,而有些组别的发电机会与其他发电机失去同步,不同的分组类型就构成了不同的功角失稳模态。基于电力系统的初始数据集,ELM以发电机组的功角为输入量,系统暂态稳定状态为预测目标。
区分系统稳定和不稳定的标准[15]是:系统中任意两个发电机功角之间的差异若在一定的观测时间内超过360°,则样本为不稳定样本,否则该样本是稳定的。在此阶段,电力系统的暂态稳定性由ELM确定,将判为不稳定的样本用于下一步骤。
2.3 基于KODAMA的失稳功角模态提取阶段
通过ELM对初始数据集进行稳定性判别,可得到失稳样本。为了全面反映失稳样本的功角特性,每个样本均包含有系统所有发电机随时间变化的功角值。样本的具体结构如下所示:
(6)
KODAMA失稳功角模态提取阶段的应用过程如下:首先,设置KODAMA算法的参数,包括比例系数φ、交叉验证重复次数M以及最大迭代次数,算法随机选取N′=φN个子样本(N为所得失稳功角样本的规模),给予子样本中每个功角数据一个初始标签,并执行交叉验证过程。其次,KODAMA算法随机交换或修改部分被误分失稳功角的位置及标签,并重复交叉验证过程对新的聚类结果进行交叉验证直至达到识别精度最大或预设的交叉验证重复次数。最后,基于多次交叉验证的结果,KODAMA算法将有着相似动态特性的失稳功角样本聚成一类,形成多个不同的簇数并给定编号,其对应着不同的失稳模态。因此。KODAMA的主要目的是在大量无规律的失稳功角数据中找到对应的失稳模态,将故障后失稳模态识别问题由无标签问题变为有监督问题,有助于辨识电力系统暂态失稳后发电机的动态行为。KODAMA识别失稳模态的过程如图3所示。
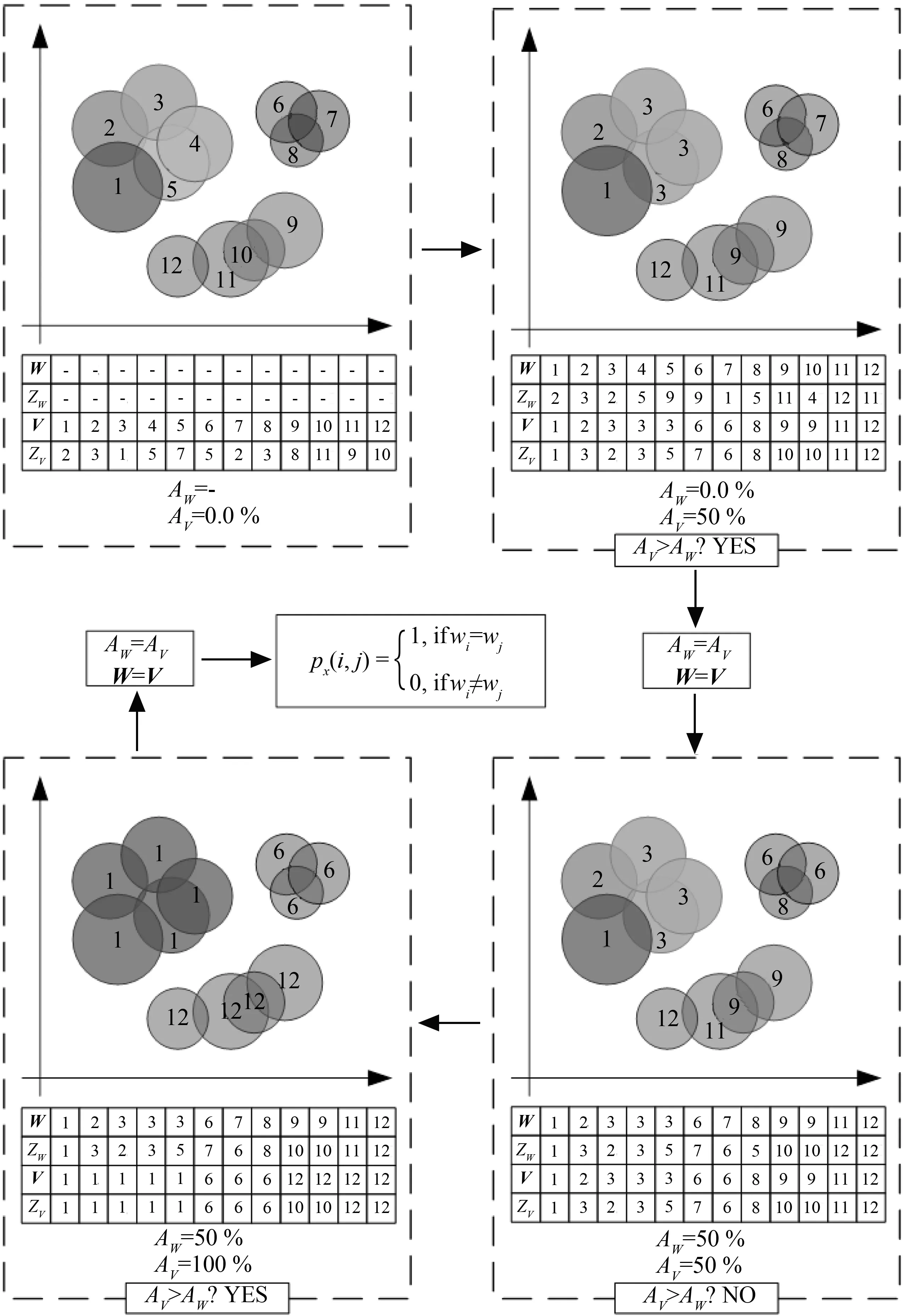
图3 KODAMA识别失稳模态的过程
2.4 分类评估模型构建阶段
考虑到电力系统动态行为的复杂性,单个ELM难以完全反映动态特性。为有效解决此问题,本文将分层技术与ELM相结合,基于上一步所获得的“模式标签”,构建分层ELM的评估模型。在训练过程中,通过随机选择样本,待选特征,构建多个ELM模型并行评估。综合每个ELM的结果给出最终的评估结果,避免使用不可信数据对评估结论产生不利影响,从整体上可以提供更加合理和可靠的评估结果。假设有n个模态,则使用以下置信度规则对每个ELM评估结果进行评估:
遵循此置信度规则,如果I个ELM评估结果中存在U个置信评估结果,则未确定的评估结果数为I-U。最终的总体评估结果可以根据以下规则获得:
① 如果I-U≤T(T≤N,T是用户定义的置信阈值),即当非置信结果的数量小于阈值时,则有90%的评估结果判断样本属于模态n。最终评估结果是该样本属于模态n。如果评估百分比低于90%,则无法确定样本属于哪种模态,需要再次增加样本和输入特征以进行评估。
② 如果I-U>T,则综合评估的结果不在置信范围内。因此,需要更多的样本来输入以便再次评估。
为了保证评估速度,随机选择50%的样本特征输入给第一评估层。基于置信度决策规则,总结各ELM故障预测模型的评价结果。如果评价结果满足置信条件,则直接给出评估结果;如果不满足置信条件,则将样本发送到下一层进行评估。第二层的评估步骤和第一层类似。在第二层中,为了保证评价的准确性,更多的数据特征被添加到数据集。这意味着新添加的特征中蕴含着新的可以利用有用的信息,从而提高评价模型对目标函数的拟合能力。具体就是,除了已输入的50%已选的特征,将随机选择20%剩余未使用的特征加入到训练样本集。如果某个样本通过第二层的评估,仍然不能给出置信的评估结果,则在第三层及以后的评估中采用所有的特征。如果样本在最后一层仍然不能给出置信的评估结果,说明该样本处于临界稳定边界附近,为了保守评估,算法会将最后一层中所有的样本认定为不稳定样本,防止将不稳定样本误判为稳定样本从而造成严重后果。此外,综合考虑评估精度和速度,在第一层后的每一层的评估中将额外增加10%的ELM数量。这样,每一层将有更多的ELM参与最终的决策,使其最后的评价结果更为全面和准确。基于分层ELM的电力系统暂态稳定性评估流程如图4所示。
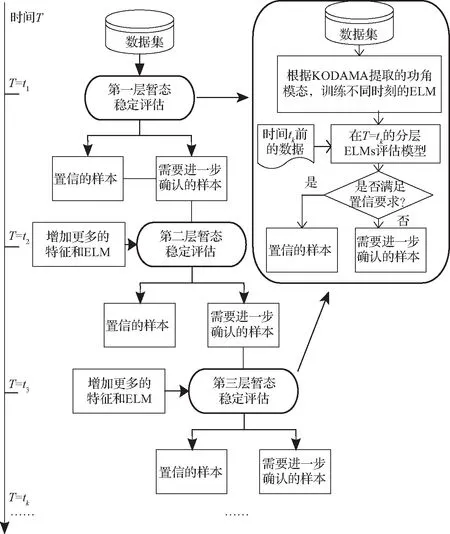
图4 基于分层ELM的电力系统暂态稳定性评估流程
2.5 失稳模态在线辨识阶段
在实际应用中,当大扰动(如短路、切除线路或机组等)清除后,由PMU记录的功角相关变量被送入ELM中,对系统的暂态稳定状态进行判定。如果系统被判定为暂态失稳,则将失稳的功角样本输入到2.4节中所构建的评估模型,并对当前系统的失稳模态进行识别,根据其对应的聚类模态类型对各发电机组的功角动态响应进行预测,对可能出现失同步的发电机组进行辨识,最终完成整个在线评估过程。
3 算例分析
3.1 训练数据集的生成
为了验证所提算法的有效性,论文基于Nordic算例系统生成相关故障场景样本数据并进行算例测试。该系统的拓扑结构如图5所示。按照2.1节所述设置数据生成过程。故障持续时间参考了文献[16]中的设置方式,其整体概率分布为一故障持续期望值为0.24 s(12 cycles),标准差为0.013 s的正态分布。最终故障点由断开对应的故障线路进行切除。最终共获得5 236个故障场景,其中不稳定样本数为825(15.76%),稳定样本数为4 411(84.24%)。通过观察总结失稳过程,发现大多数功角失同步发生在10~15 s,因此整个仿真的截止时间设定为18 s。
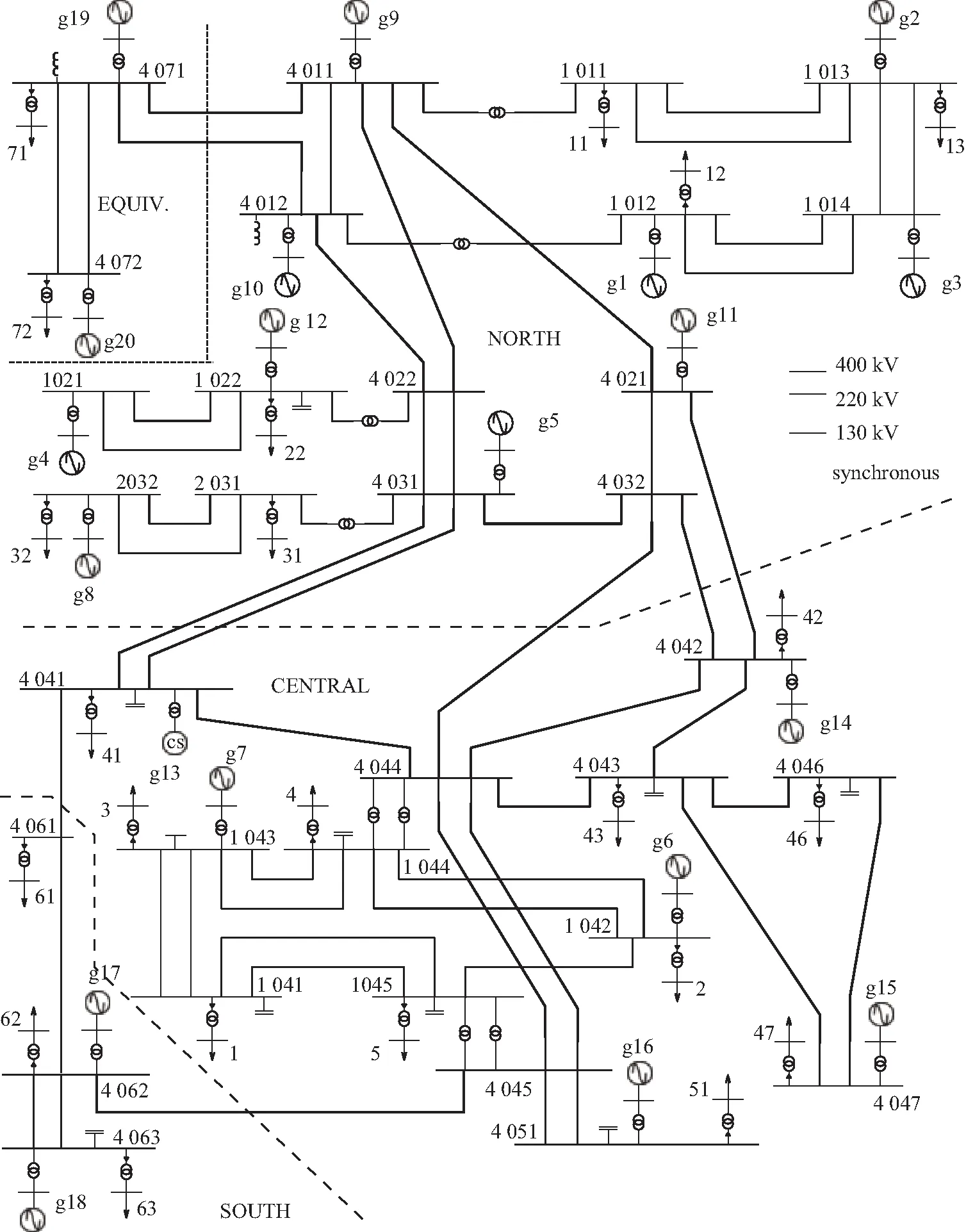
图5 Nordic系统拓扑
3.2 基于KODAMA的失稳模态聚类结果
为了全面的反映失稳后的功角特性,每个样本均包含有系统所有发电机随时间变化的功角。由于测试系统共有20个发电机组,系统频率为50 Hz且仿真时长为18 s,因此825个失稳场景下生成的功角摇摆曲线样本集Y为一个18 000×825的矩阵,具体结构如下:
(9)
依据文献[11]的参数设定,KODAMA的参数设置如下:φ=0.7,M=100,迭代次数为20次。样本集Y输入到KODAMA聚类算法中,对其进行模态聚类,最终获得8种失稳后的功角摇摆曲线模态,KODAMA的聚类结果和获得的发电机功角失稳模式分组见表1。表1中加阴影的部分为失稳的发电机组。发电机功角摇摆曲线失稳模态集如图6所示。

表1 KODAMA的聚类结果和获得的发电机功角失稳模式分组
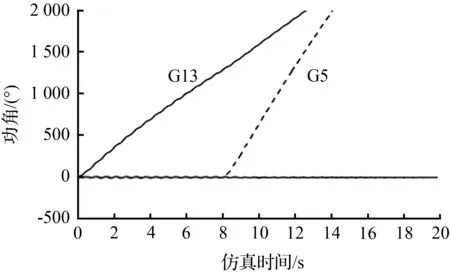
(a) 模态1
总结相关模态聚类结果可以看出,相比于其他机组,G5、G12、G13和G19发生失稳的概率相对较高,绝大部分失稳样本中的失同步发电机为它们其中之一或多个。造成这一现象的原因可能与发电机控制策略及励磁设计、系统拓扑、周边的负荷情况等因素相关。此外,分析算例参数设置可知,G5、G13和G19上并没有配备电力系统稳定器,这也可能是造成其易于失稳的主要原因之一。G12发电机组虽然装有PSS,但其容量相对较小,且周边存在多条重负荷母线,因此也易于发生失稳。
3.3 测试样本的生成
为了进一步测试在线辨识模型的评估性能,本节在Nordic算例系统中基于暂态数据的生成流程,重新生成了3 000个故障场景样本,其中失稳样本427个,稳定样本2 573个,相关参数的设置与3.1节完全相同。测试集样本失稳模态分布情况见表2,通过与3.2节获得的模态样本集比对发现:有些测试新样本可以在训练数据模态集中找到对应的模态类型,测试集中有419个样本分别对应3.2节所构建模态集中的7种模态;但也有7个测试样本的失稳功角响应模态与之前获得的模态都不相同,属于两种新发现的模态。隶属于新模态的7个样本,新获得的发电机功角失稳模式分组见表3,图7所示为新获得的发电机功角摇摆曲线失稳模态。

表2 测试集样本失稳模态分布情况

表3 新获得的发电机功角失稳模式分组
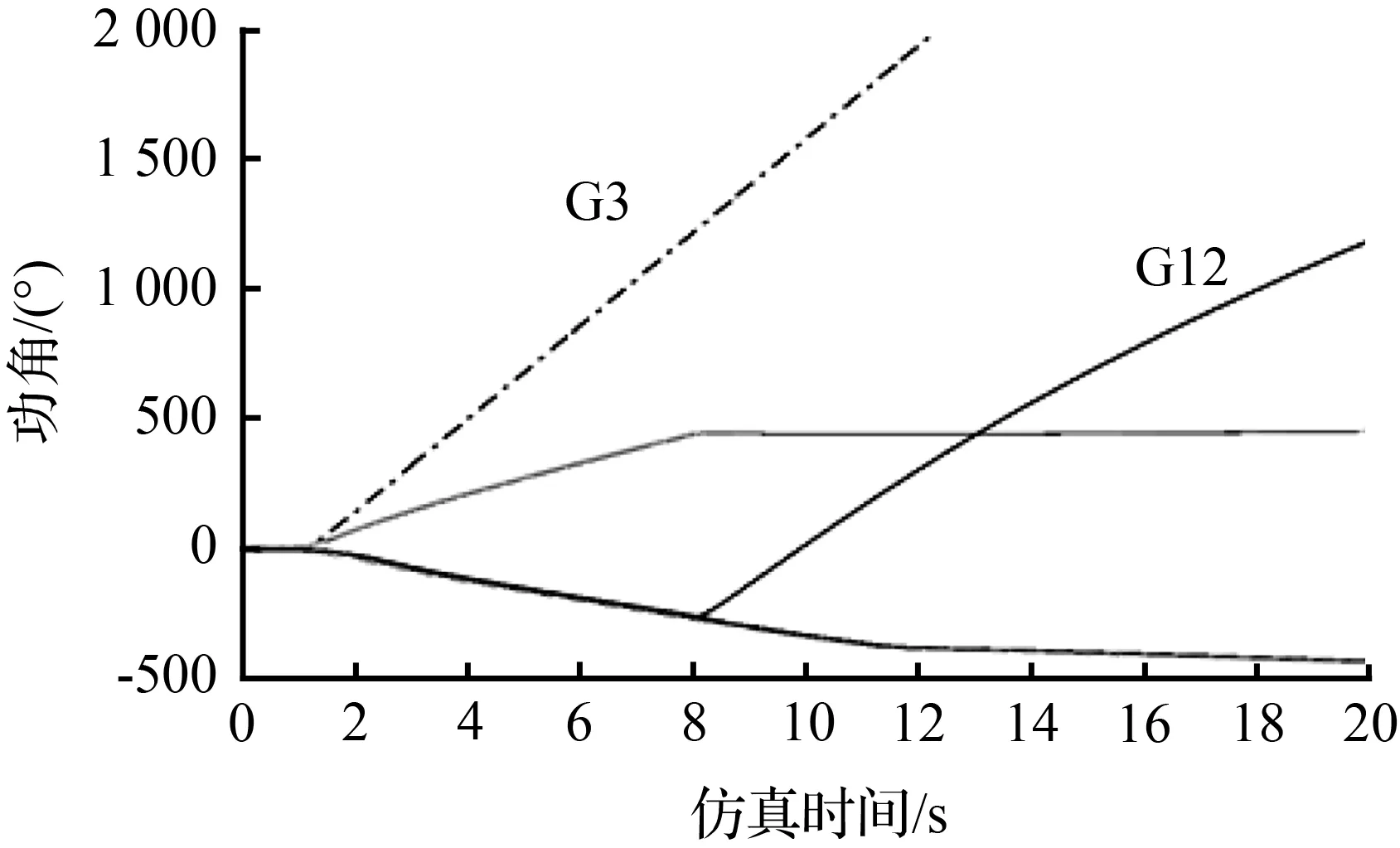
(a) 新模态1
3.4 训练在线识别模型
基于3.2节所获得的发电机功角失稳模态和3.3节构建的测试样本集数据,五种不同的机器学习方法用来构建并训练预测因子(输入量)是发电机的功角,分类目标(输出量)是功角失稳模态类型的分类评估模型。具体包括分类回归树(classifilation and regression tree, CART)、C5.0决策树、多重支持向量机(multiple suport vector machine, MSVM)、随机森林(random forest, RF)和分层ELM。为了公平地进行对比,每种方法的最大输入特征数为80,基本树和多重学习的数量设置为100,其他参数采用软件默认值或最佳测试参数。5种不同的数据挖掘方法对暂态失稳模态的评估精度见表4,总结表4中的数据可以看出:在故障清除后的第十个仿真周期(0.2 s),约有87%的测试样本可被正确地分类,基本满足在线辨识要求。而在故障清除后1 s,约有91%的样本可被正确地归类,这说明随着时间向后推移,数据对失稳模态的表达能力越来越强,各种评估方法的精度也随之增加。CART的评估精度相对较差,ELMs的评估精度相对最好,结合表4中相关数据,本文最终选择ELMs作为最终的评估模型。
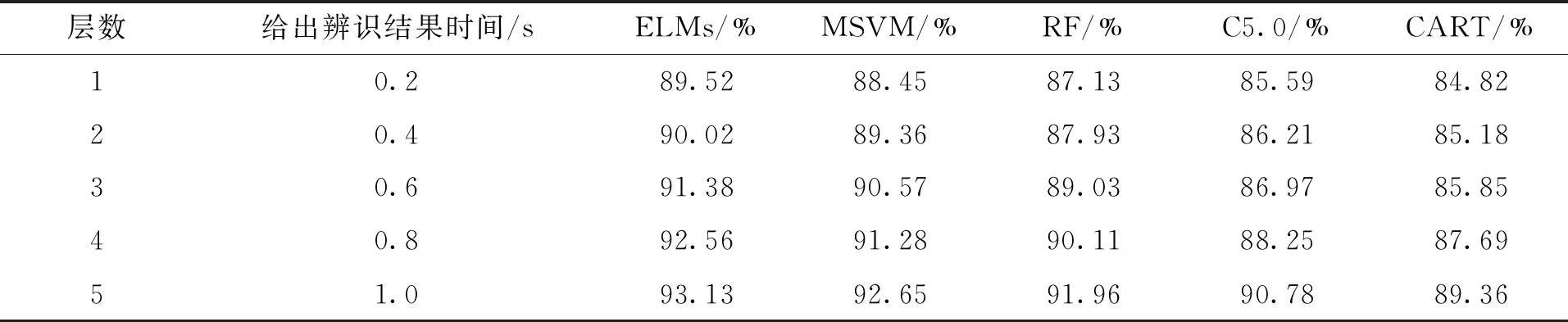
表4 5种不同的数据挖掘方法对暂态失稳模态的评估精度
3.5 评估速度测试
基于上述测试数据集,5种不同的评估模型(CART、C5.0、MSVM、RF和分层ELM)进行评估速度测试,不同评估模型的运行时间见表5。根据表5中的结果,和其他评估模型相比,本文所提方法分层ELM能够获得最高的评估精度。同时,5种模型的运行速度整体较为接近。具体而言,分层ELM可以在0.7 s内给出评估结果,其评估速度优于除CART外的其他评估模型。也就是说,所提的分层ELM评估模型保持较高的评估精度下,也具有相对较快的评估速度。

表5 不同评估模型的运行时间
4 结语
为了维持电力系统的安全运行,在先前的研究中已经进行了各种尝试来研究系统的暂态稳定性评估。然而,暂态稳定评估通常集中在暂态稳定状态的评估,在不稳定情况下对发电机的动态行为少有研究。针对这一问题,提出了一种基于KODAMA和分层ELM的故障后失稳模式在线辨识方法,其结论可以总结如下:
① 实验结果表明,与其他方法相比,基于KODAMA和分层ELM评估策略的方法可以达到92.98%的最高评估精度。
② 所提的分层评估策略可以在1 s内提供更快的评估结果,可以满足在线识别的要求为紧急控制留出更多时间。此外,所提方法为电力系统运行人员总结常见的易失稳发电机组,且在故障发生后无需监视所有发电机。
