基于KMUS-RF算法的复杂产品关键质量特性识别研究
2021-11-05柳嘉昊
柳嘉昊

【摘 要】复杂产品生产数据具有高维度、不平衡的特点,为在复杂产品的生产阶段有效识别关键质量特性,及时进行质量控制,论文提出了一种基于聚类欠采样的改进随机森林算法(Random forest algorithm base on K-Means clustering under sampling,KMUS-RF),利用K-Means算法对多数样本进行聚类,并根据聚类结果进行多次欠采样形成多个平衡数据集,以随机森林为基分类器进行识别,最终根据分类过程中的特征重要性输出关键质量特性集。算例表明,KMUS-RF算法相比现有的多种分类器有良好的整体分类性能,并能显著降低复杂产品分类的第二类错误率,满足产品实际生产需求。
【Abstract】The production data of complex products have the characteristics of high dimension and imbalance. In order to effectively identify the critical-to-quality characteristics in the production stage of complex products and timely control the quality, this paper proposes an improved random forest algorithm base on K-Means clustering under sampling (KMUS-RF). K-Means algorithm is used to cluster the majority of samples, and multiple undersampling is performed according to the clustering results to form multiple balanced data sets. The random forest based classifier is used for recognition, and finally the critical-to-quality characteristics set is output according to the feature importance in the classification process. Numerical examples show that KMUS-RF algorithm has good overall classification performance compared with existing classifiers, and can significantly reduce the type II error rate of complex product classification, and meet the actual production needs of products.
【关键词】关键质量特性;不平衡数据;随机森林;K-Means;第二类错误
【Keywords】critical-to-quality characteristics; imbalanced data; random forest; K-Means; type II error
【中圖分类号】F273.2 【文献标志码】A 【文章编号】1673-1069(2021)10-0134-04
1 引言
质量强则国家强,质量兴则民族兴,质量可靠性是产品生产最基本的要求。在复杂产品的生产制造过程中,由于复杂产品由诸多系统组成,且它们具有高度集成、系统之间相互关联、相互制约的特点,因此需要控制的变量极多。例如,汽车发动机由五大系统和两大机构组成。五大系统是燃料供给系统、冷却系统、润滑系统、点火系统和起动系统。两大机构是曲柄连杆机构和配气机构,其中某一系统又由活塞、连杆、摇臂等零部件组成,零部件又能进一步被分解为螺丝、轴承等,每一微小的零部件都有尺寸、重量等质量特性。在复杂产品被从部件分解成零件的过程中,产品质量特性数据集的维度会随着产品结构的逐步分解而不断升高。另外,在实际生产过程中,产品数据往往具有不平衡性。在制造业中,如果生产出的合格产品数量是不合格产品数量的10倍以上,就称这样的数据为不平衡数据(Imbalance Data Sets,IDS)。高维度、不平衡的复杂产品生产数据使质量控制成为难题。因此,质量问题成为复杂产品生产控制的关键问题,这不仅关系到复杂装备的生产质量问题,更关系到经济安全甚至生命安全。为了在较低的控制成本下有效实现质量控制,就需要从高维度、不平衡的质量特性数据集中识别出对产品质量有显著影响的关键质量特性(Critical-to-Quality Characteristics,CTQ)。
2 相关研究工作概述
传统的CTQ识别主要依赖于工程人员的专业知识或者是顾客的需求,从产品构造、产品加工、工程特性、顾客需求等角度定性或定量方法识别产品的CTQ。应用最多的就是质量功能展开法(Quality Function Deployment,QFD)。QFD法主要包括以下几个步骤:调查顾客需求、产品规划、产品设计方案确定、零部件规划、零部件设计和工艺过程设计、工艺规划、工艺质量控制。
至今,QFD仍被认为是产品设计阶段CTQ识别的最有效方法。但是,在应用中发现,当QFD法应用于高维度、不平衡的数据集时会因自身的局限性而大大降低效率,QFD法的质量矩阵变得难以确定,由此便产生了通过数据挖掘、机器学习等方法识别产品CTQ的研究,这方面的研究还相对较少。闫伟等(2012)通过改进ReliefF算法、Wrapper方法及EM(Expectation Maximization)算法,有效提高了CTQ识别性能并大幅降低了第二类错误率,还在2014年通过调整CEM(Classification EM Algorithm)算法的K值输出不同的聚类结果,消除冗余样本后作为IG(Information Gain)算法的输入,有效降低了数据高维度和不平衡带来的负面影响,正确识别了产品CTQ集。李岸达等(2016)提出了基于NSGA-II的特征选择算法,引入第II类错误率度量质量特性子集的重要性,通过理想点法在非支配解集中选择最佳调和解,得到产品的CTQ集。
从现有研究中发现,目前的CTQ识别方法有以下几点不足:难以应用于高维度、不平衡的复杂产品数据集;未考虑到第二类错误率对实际生产中的影响;基于数据挖掘、机器学习的CTQ识别算法不够高效。针对以上不足,本文旨在提供一种算法,能高效识别产品CTQ集,可应用于高维度、不平衡的数据集,并且能够降低第二类错误率,满足实际生产中的需要。
3 研究思路和方法
3.1 构建基于改进随机森林算法的CTQ识别方法
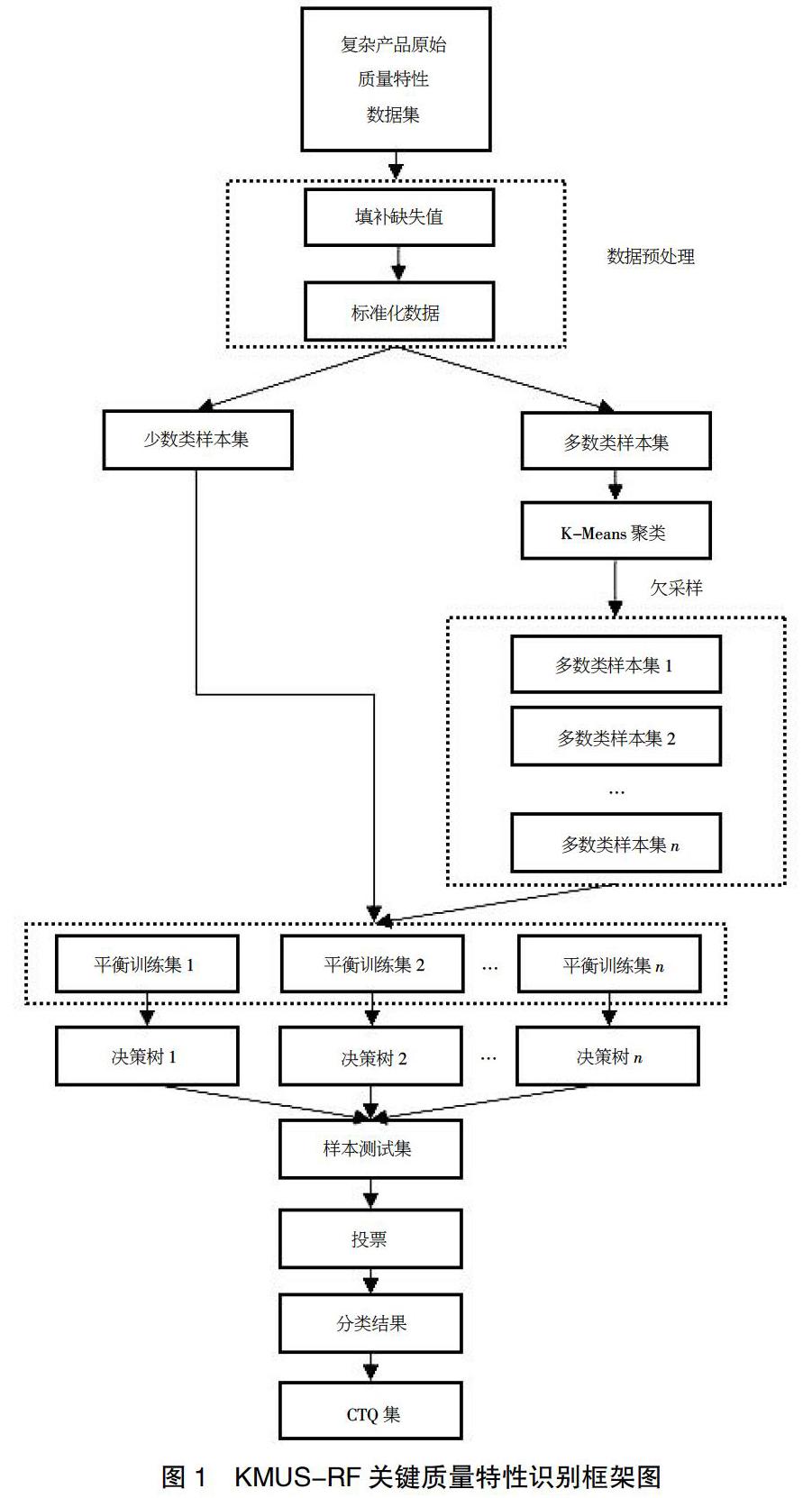
本文从不同于传统CTQ识别方法的视角,构建了一套完整的高维度、不平衡复杂产品数据集CTQ识别方法,基本框架如图1所示。
基于改进随机森林算法的CTQ识别方法步骤如下:
①获取复杂产品原始质量特性数据集。
②数据预处理(填补缺失值、标准化数据)。
③对多数类样本进行K-Means聚类。
④根据聚类结果进行欠采样生成n个多数类样本集。
⑤将每个多数类样本集与少数类样本集组成n个平衡的训练集。
⑥对每个平衡训练集用决策树进行分类,直至生成n棵决策树形成随机森林。
⑦对于测试集,经过每棵树决策判断,最后投票确认分到哪一类。
⑧根据分类过程中的特征重要性输出CTQ质量特性数据集。
该方法的构建总体分为3个阶段:第一阶段(步骤①、②)对原始高维度、不平衡数据进行初始处理;第二阶段(步骤③~⑥)基于聚类欠采样的改进随机森林算法(Random forest algorithm base on K-Means clustering under sampling,KMUS-RF)对样本数据进行分类;第三阶段(步骤⑦、⑧)验证算法的有效性,并输出CTQ数据集。
3.2 KMUS-RF算法评价指标
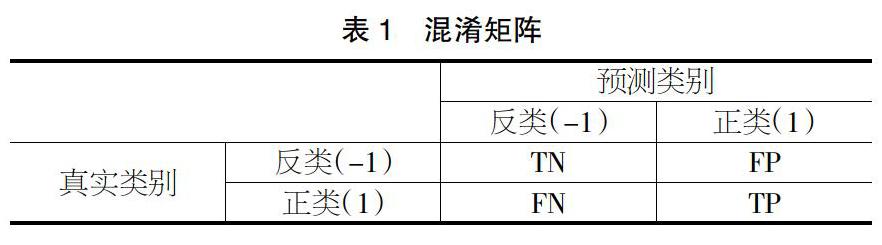
为评价KMUS-RF算法的分类效果,本文构建了混淆矩阵,如表1所示。TN表示模型将反类样本预测为反类的数量,FP表示模型将反类样本预测为正类的数量,FN表示模型将正类样本预测为反类的数量,TP表示模型将正类样本预测为正类的数量。
基于表1,可以得到各种分类性能的衡量指标,包括:分类精度(Accuracy)、准确率(Precision)、召回率(Recall)、F1得分(F-score)、第二類错误率(Type II error)。各评价指标的计算如式(1)~(5)所示。
本文选用分类精度和第二类错误率2个指标对分类结果进行评价。其中,第一类错误的定义为错误地将合格产品判定为不合格产品,这类错误的风险承担者为生产者,因此也被称为“生产者风险”;第二类错误的定义为错误地将不合格产品判定为合格产品,这类错误的风险承担者为消费者,因此也被称为“消费者风险”。在复杂产品的生产过程中,第二类错误带来的损失通常远高于第一类错误。因此,本文选用的评价指标兼顾了分类器的性能和实际生产应用的需求。
4 实证分析
4.1 数据获取与预处理
本文复杂产品质量特性数据集来源于UCI数据库的SECOM数据集,该数据集为半导体生产过程控制数据。数据集共有样本1567个,每个样本有590个质量特性,将其标号为“Q0”“Q1”…“Q589”,样本分为合格产品和不合格产品2类,其中合格产品数量为1463个,不合格产品数量为104个。SECOM数据集中质量特性数量多,合格产品数量超过不合格产品数量的10倍,是典型的高维度、不平衡数据集。因此,在分类器识别之前需要对数据进行预处理。
首先,填补缺失值。SECOM数据集中,部分样本缺少某个或某几个质量特性的数据,为便于模型进行预测,本文使用均值填充法(Mean Completer),用每一质量特性的均值填充缺失值。
接着,标准化数据。为进一步提高模型的收敛速度和预测精度,本文使用标准差标准化(StandardScaler)对数据样本进行无量纲化处理,具体方法如式(6)所示。
(6)
式中,x'表示无量纲化样本,x表示原始样本,表示样本均值,s表示样本标准差。最后,分割数据集为训练集和测试集,本文随机选取26个合格产品和26个不合格产品组成测试集,剩余数据为训练集,具体信息如表2所示。
4.2 基于K-Means聚类欠采样
随机森林算法基分类器的多样性将决定最终分类效果,为此,本文通过聚类的欠采样方法构建不同的训练子集,以提高基分类器的多样性。首先,对多数类样本进行K-Means聚类,具体过程如下:①从多数类样本中选择k个样本作为初始簇中心:C=η。②计算每个多数类样本xj到k个簇中心ηi(1≤i≤k)的欧氏距离dij,确定xj的簇标记λj=arg mini∈{1,2,…,k)dij,并分配给最近的簇中心Cλj=Cλj∪{xj}。③将每个簇中心设置为所分配的所有多数类样本的平均值。④重复步骤②、③直至簇中心不再变化,结束循环。⑤输出多数类样本的聚类结果。
本文取k=39,经过K-Means聚类后,训练集中的多数类样本被聚类成39个簇。接着,从39个簇中有放回得抽样2次,并与少数类样本进行合并,生成1个平衡训练子集(其中含有78个多数类样本和78个少数类样本)。最后,重复进行上一步中的抽样,得到n个平衡训练子集。
4.3 基于随机森林算法的产品分类实现
对上文得到的n个平衡训练子集,构建n棵决策树组成的随机森林,根据每棵决策树对单一训练子集的训练结果,对测试集进行分类,最终输出n棵决策树投票得到测试集分类结果。
本文设定n=50,为增加实验结果的客观性,本文通过调整采样时的随机数种子,进行5次实验,分别记为E1、E2、E3、E4、E5。结果如表3所示。
此外,本文选择RF、RUS-RF、SMOTEENN-RF、SMOTETomek-RF、ADASYNENN-RF、CEM-IG、改进ReliefF、改进Wrapper、改进EM九种算法作为本文的对照算法。
其中,RF代表不做任何处理的随机森林算法;RUS-RF代表先采用随机欠采样,再用随机森林进行分类的算法;SMOTEENN-RF代表先用SMOTE进行过采样,再用EditedNearestNeighbours进行欠采样,最后用随机森林进行分类的算法;SMOTETomek-RF代表先用SMOTE进行过采样,再用Tomek Links进行欠采样,最后用随机森林进行分类的算法;ADASYNENN-RF代表先用ADASYN进行过采样,再用EditedNearestNeighbours进行欠采样,最后用随机森林进行分类的算法,其余为现有文献中应用的算法。另外,在用到随机森林进行分类的算法中,统一设定用50棵决策树进行投票。各算法的比较结果如表4所示。
从表4可以很直观地看出,本文提出的基于KMUS-RF算法的分类方法在分类精度和第二类错误率2个指标均优于现有的基于重采样技术的随机森林算法,证明本文的聚类欠采样方法能够良好保留多数类样本的信息。
此外,与其他CTQ识别算法相比,虽然分类精度不是最优,但也表现出良好的性能。本文算法大幅降低了产品分类的第二类错误率,有效降低了实际生产过程中的负面影响。
4.4 基于KMUS-RF算法的CTQ识别
本文根据每次实验中随机森林算法的特征重要性(feature_importance)进行降序排列,即对影响复杂产品分类结果的各个质量特性的重要性从高到低进行排列,可认为,某个质量特性对分类结果影响越大,该质量特性越重要。为不失一般性,本文对5次实验的前top_n个質量特性取交集,得到对每次实验的产品分类都起重要作用的质量特性集,将其作为CTQ集,具体结果如表5所示。
由表5可得,通过对top_n值的改变,能够明显看出质量特性的重要性梯度,在实际生产应用中,企业可根据自身的质量控制能力灵活调整top_n值,对关键质量特性进行有效控制,便于及时发现产品缺陷,调整生产策略。
5 结论与展望
近年来,随着制造业的不断发展和各种测量仪器的进步,从产品加工过程中获得各个零部件的尺寸参数等技术已较为成熟,但复杂产品组成系统众多,客观上造成了数据的高维度性,而合格产品数量远大于不合格产品数量,又造成了数据的不平衡性,这2个特性给企业在生产过程中的CTQ识别控制带来了一定困扰。本文提出的KMUS-RF算法以高维度、不平衡的复杂产品生产数据为研究对象,算例结果表明:该方法可以准确地对复杂产品进行分类,并有效识别复杂产品CTQ集,还能有效降低产品分类的第二类错误率。算法既给复杂产品高维度、不平衡数据的CTQ识别研究提供了理论借鉴,也给企业实际生产过程中进行质量控制、降低第二类错误率提供了方法参考。在后续的研究中,可将更多的数据挖掘、机器学习方法应用于复杂产品CTQ识别中,探究更精确的算法,也可根据其他复杂产品生产数据集对本文算法进行改进和创新。
【参考文献】
【1】李伯虎.复杂产品制造信息化的重要技术——复杂产品集成制造系统[J].中国制造业信息化,2006(14):20-24.
【2】张健,方宏彬.剪枝与欠采样相结合的不平衡数据分类方法[J].计算机应用研究,2012,29(03):847-848.
【3】何益海,唐晓青,王美清.产品设计质量数据与管理模型研究[J].计算机集成制造系统,2006,12(8):1161-1166.
【4】马骊.随机森林算法的优化改进研究[D].广州:暨南大学,2016.
【5】Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic Minority Over-sampling Technique[J].Journal of Artificial Intelligence Research,2002,16(1):321-357.
【6】He H, Bai Y, Garcia E A, et al. ADASYN: Adaptive synthetic sampling approach for imbalanced learning[C]// Neural Networks, 2008. IJCNN 2008. (IEEE World Congress on Computational Intelligence).
IEEE International Joint Conference on. IEEE, 2008.
【7】Batista G E A P A , Prati R C, Monard M C. A study of the behavior of several methods for balancing machine learning training data[J].Acm Sigkdd Explorations Newsletter,2004,6(1):20-29.
【8】闫伟.基于数据挖掘的复杂产品关键质量特性识别的方法研究[D].天津:天津大学,2012.
【9】闫伟,何桢,李岸达.基于CEM—IG算法的复杂产品关键质量特性识别[J].系统工程理论与实践,2014(5):1230-1236.
【10】于志忠.利用QFD方法建立基于顾客满意的质量目标[J].中国认证认可,2010(11):35-37.
【11】李岸达,何桢,何曙光.基于NSGA-Ⅱ的非平衡制造数据关键质量特性识别[J].系统工程理论与实践,2016,36(06):1472-1479.
