雾计算辅助车联网中面向视频直播业务的资源分配研究*
2021-11-01张志才张熠宁
张志才,张熠宁,付 芳
(1. 山西大学 物理电子工程学院,山西 太原 030006;2. 北京邮电大学 信息与通信工程学院,北京 100876)
0 引 言
车联网实时视频流直播服务面对两个挑战:一是路边单元覆盖范围的有限性与车辆视频业务QoS保障的严苛之间的矛盾[1]. 由于电磁波在传播过程的衰减特性,每一个路边单元对车辆用户的下行发送功率在远距离传输后会变得很弱,路边单元的覆盖范围有限,然而,接收端信噪比低不利于视频业务QoS保障. 二是按照高峰时段来部署固定数目雾计算节点导致在车流量小的时段里大部分计算资源被浪费了. 城市车流量在高峰时段(工作日的早7点~8点和下午4点~5点)是低谷时段(工作日的早1点~4点,周六的早2点~4点和周日的早3点~5点)的5倍~8倍[2].
为了应对这些挑战,学术界将公交车作为雾计算节点,随着车流量大小而动态部署雾计算节点,不仅能避免计算资源的浪费,而且能增大车联网的覆盖范围. 车联网中将车辆作为雾计算结点已经有了一些研究成果. 文献[3]针对车辆自组织网(Ad Hoc)场景,提出了一种基于遗传算法的计算任务卸载方案,实现了计算任务执行时间和能量消耗的最小化. 文献[4]针对高速公路车辆雾计算网络场景,提出一种能量效率动态计算卸载和资源分配方案以提高能效和降低时延. 文献[5]针对停车场车辆雾计算网络场景,提出一种智慧泊车的新方法,将已停好的车辆作为雾计算节点来引导正在行驶的车辆尽快找到合适的停车位. 文献[6]针对车辆视频业务,将基站和出租车作为雾计算节点,其优化目标是最小化时延和视频质量损失. 需要注意的是,上述文献都是以降低时延为优化目标,而且只有文献[6]考虑的是车联网视频业务,但是其不足之处是其QoS只考虑了视频质量和时延而没有考虑视频抖动,由于车联网环境的动态变化易导致相邻时隙的比特率发生变化,进而引起视频抖动,因此,在车联网视频业务的QoS保障中,视频质量、时延和抖动都是重要的指标.
关于车联网视频业务中自适应比特率技术,文献[7]提出一种双时间尺度的动态缓存方案,文献[8]提出一种车载视频自适应上传方案,文献[9,10]将视频质量和时延分开考虑. 关于车联网视频业务中强化学习算法,文献[11,12]使用深度Q学习网络(DQN)算法来优化频谱和计算资源,文献[13]证明把车载环境建模为马尔可夫决策过程(MDP)模型的效果优于非MDP模型,文献[14]研究了最小化所有用户设备的总下载延迟的D2D缓存问题,文献[13,14]均采用Q-learning算法来求解. 然而,上述算法大都采用ε-greedy策略进行探索,这种随机策略的探索能力非常有限,很难找到问题的最优解. 为了增强算法的探索性,本文采用最新的深度强化学习算法Soft Actor-Critic求解问题,该算法在ε-greedy策略的基础上,引入关于动作策略的最大熵目标以提高其探索能力,从而获得最优解.
综上所述,本文提出一种车辆雾计算网络中基于Soft Actor-Critic的视频传输方法,采用雾计算网络和基于HTTP的动态自适应流(DASH)技术相结合[15],将路边单元和公交车视为雾计算节点,核心网发出的视频通过雾计算结点传输给目标车辆[16],并且将视频内容编码成多个比特率的版本,通过联合优化比特率选择、用户调度和频谱资源分配,以最大化视频质量,同时降低时延和视频抖动.
1 系统模型
1.1 网络模型
图 1 为城市中车联网的场景图,我们将配备LTE-V2X无线接口的路边单元(RSU)和公交车作为雾计算结点,可以为私家车提供低时延的通信服务. 根据当前的信道条件及自身需要自适应选择不同比特率的视频,通过核心网把视频传输到雾节点,雾节点再把视频传输到目标车辆. 采用集中式资源分配方式,RSU决定其覆盖范围内用户的资源分配.
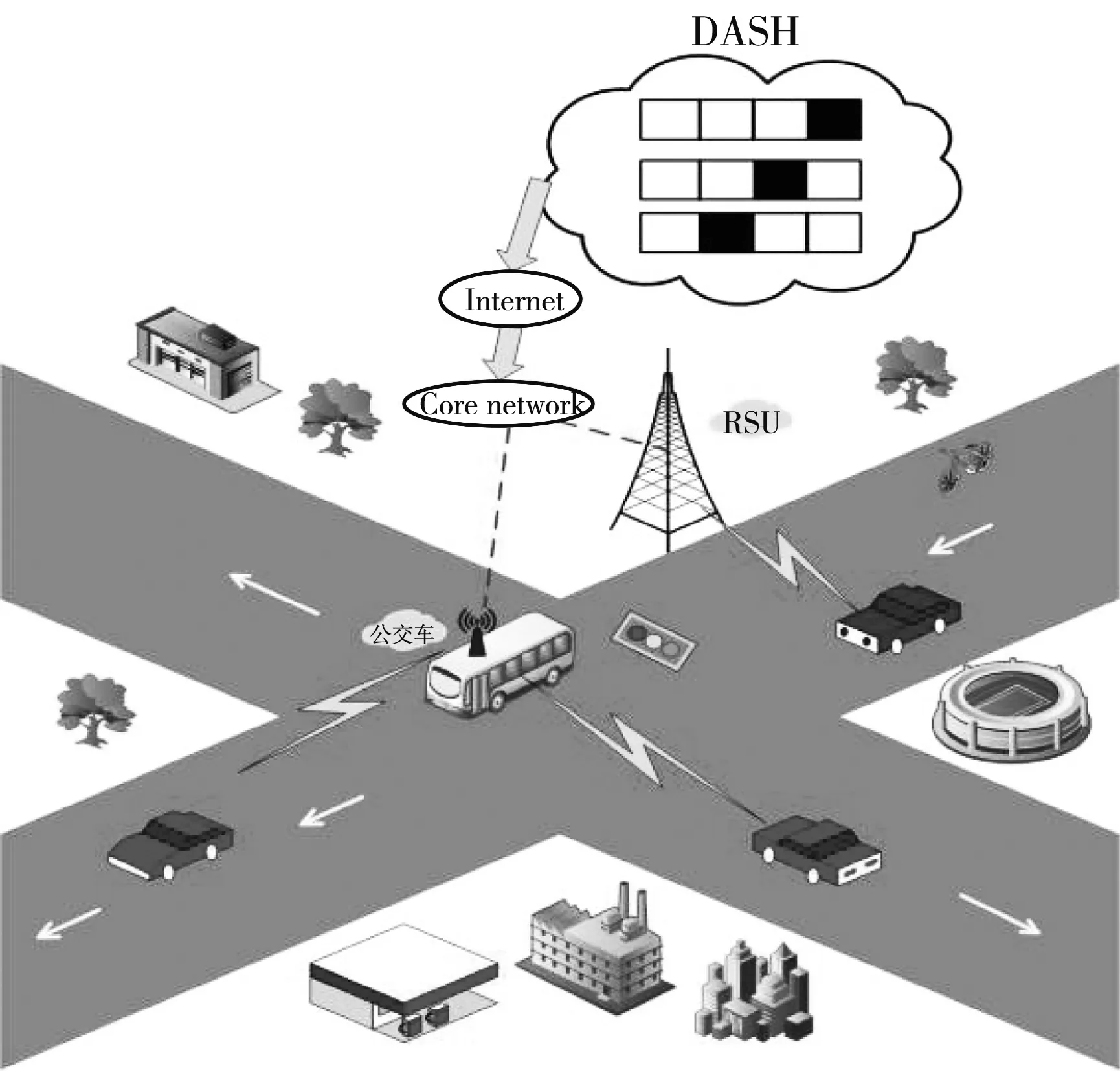
图 1 网络场景图

1.2 V2I和V2V通信模型
RSU和私家车之间的通信属于车辆到基础设施(V2I)通信,它采用LTE-Advanced标准,其链路的子载波为2 GHz,而公交车和私家车之间的通信属于车到车(V2V)通信,它采用专用短距离通信频带,其链路的子载波为5.9 GHz. 故V2I链路和V2V链路之间无同频干扰.

由香农公式可知,V2I和V2V的通信速率为
Gu,k=bu,kB0log(1+γu,k),∀u∈U,k∈K.
(1)
V2I链路的信干噪比(SINR)为
γu,0=pu,0gu,0/(I+σ2),
(2)
式中:I为其他RSU导致的干扰;σ2为高斯白噪声功率;pu,0和gu,0分别为V2I链路的发射功率和信道增益.
V2V链路的SINR为

(3)
式中:pu,k和gu,k分别为雾节点k对用户u的V2V链路的发射功率和信道增益.
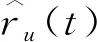

(4)
将目标视频从雾节点下载到用户u消耗的时间为

(5)
1.3 设计效用函数

(6)
式中:参数ξ为正值,并且随着特定应用的变化而变化.


(7)
视频被等分成若干小段播放和处理,每一段的播放时间长度为L,在播放一小段视频流的同时处理下一小段视频流. 从视频提供商到雾节点传输消耗的时间不受本文策略影响,因此,处理视频的时间只考虑雾节点下行传输到车辆的时间Tu(t).保证连续播放需满足处理视频的时间不能超过播放视频的时间,否则就会产生时延Du(t)
Du(t)=Tu(t)-L.
(8)
设计效用函数
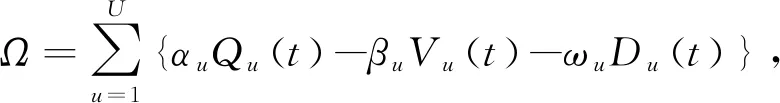
(9)
式中:αu为视频质量价格;βu为比特率切换价格;ωu为时延价格.
1.4 问题建模
联合优化比特率选择、车辆调度和频谱资源分配,在约束条件下最大化效用函数,即
Maximize:Ω,
(10-1)
cu,k∈{0,1},∀u∈U,∀k∈K,
(10-2)
约束(10-2)表明V2V和V2I两种通信链路,约束(10-3)表明每辆车同时能且只能与一个雾节点通信,约束(10-4)表明雾节点k可用来分配给车辆u的频谱资源有限,约束(10-5)表明目标视频比源视频的比特率低.
将上述优化问题建模为一个马尔科夫决策过程MDP〈S,A,r,P〉,其中S表示状态空间,包含可用的资源块数量和下行链路的信干噪比;A表示动作空间,包括车辆调度策略、频谱资源分配策略和视频比特率选择策略;P表示状态转移概率函数;r表示执行完一个动作后,环境反馈给智能体的奖励值,即效用函数的值.
2 Soft Actor-Critic算法
2.1 软价值函数
该算法在长期回报的奖励值中引入熵,寻找最优策略π(a|s)使式(11)熵目标最大化.
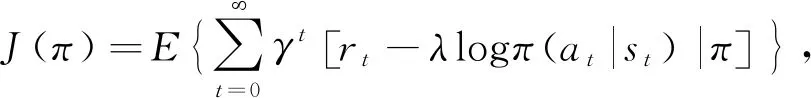
(11)
式中:γ∈[0,1]为折扣因子;λ为温度系数,通过调整温度系数的大小来控制策略的随机性. 给定初始状态和初始动作后,式(11)变换为软Q值函数,即
Qπ(s,a)=

(12)
状态值函数又称软V值函数,其与软Q值函数的关系为

(13)
式(11)的最优策略π*为

(14)
2.2 Critic部分

∇θL(θ)=

(15)
设αc(αc>0)为critic部分的学习率,在梯度下降方向更新参数θ
θ←θ-αc∇θL(θ).
(16)

(17)
式中:τ为平滑系数,0<τ<1.
L(ϑ)=

(18)
L(ϑ)的梯度为
∇ϑL(ϑ)=
∇ϑVϑ(s)[Vϑ(s)-Qθ(s′,a)+λlogπφ(a|s′)].
(19)
在梯度下降方向更新参数ϑ
ϑ←ϑ-αc∇ϑL(ϑ).
(20)

(21)
式中:k∈(0,1)为平滑系数.
2.3 Actor部分
Actor部分采用参数为φ的DNN网络来表示策略分布,通过软Q值和软V值函数计算得到的策略来训练该DNN. 用KL散度最小化式(21)损失函数,从而得到最优策略.
L(φ)=E[DKL(πφ(·|s)||π*(·|s))],
(22)

L(φ)=

(23)
L(φ)的梯度为
∇φL(φ)=∇φλlogπφ(a|s)+
(∇aλlogπφ(a|s)-∇aQθ(s,a))∇φfφ(ξ;s).
(24)
设αa(αa>0)是Actor部分的学习率,在梯度下降的方向更新参数φ
φ←φ-αa∇φL(φ).
(25)
3 仿真结果与分析
在Tensorflow1.14.0平台上采用Python仿真器进行实验,场景为一条500 m的城市公路,在一个RSU覆盖的范围内随机分布了4辆公交车和10辆私家车用户,仿真参数见表1.

表1 仿真参数
图 2 显示了当αa=0.000 05、αc=0.05时,随着私家车用户数量的增加,视频比特率分布情况的变化. 由图可见,当用户越来越多时,高比特率(2 750 kbps)用户的比例在降低,低比特率(1 750 kbps、1 250 kbps)用户的比例在上升. 这是因为频谱资源是有限的,根据下行链路的无线信道环境和可获取的频谱资源后,就需要牺牲视频比特率的级别以降低视频抖动.

图 2 用户总数变化对接受视频比特率的影响
图 3 显示了Soft Actor-Critic算法、Actor-Critic算法和无学习状态下收敛性能的对比. 由图可见,Soft Actor-Critic算法的收敛最快,而且回合平均奖励值最高,为0.57,经过20个回合已收敛;普通Actor-Critic性能其次,经过350个回合才收敛,回合平均奖励值略大于0.48;无学习状态的收敛性能最差.

图 3 算法收敛性能对比
4 结 论
本文提出了一种雾计算辅助车联网中视频直播业务的资源分配方法,联合优化用户调度、资源分配和视频比特率选择,旨在最大化视频质量,同时降低时延和抖动. 创新点如下:
1)利用雾计算辅助车联网,将公交车和RSU都视为雾计算结点,将计算和通信资源带到距离用户更近的地方以降低时延.
2)设计了一个面向视频直播业务的效用函数,将相邻视频片段的比特率切换和时延作为惩罚因子,以降低时延和视频抖动,区别于现有大多数文献只考虑提高视频质量或只考虑降低时延.
3)采用Soft Actor-Critic深度强化学习算法获得最优资源分配策略,算法的收敛性和探索能力更好.
