热电联产机组在深度调峰模式下的负荷智能分配
2021-10-28王智微徐创学薛晗光
吴 涛,赖 菲,刘 震,王智微,何 新,徐创学,薛晗光,石 磊,徐 晨
(1.西安热工研究院有限公司,陕西 西安 710054;2.上海海事大学物流科学与工程研究院,上海 201306)
近些年,风电、光电等新能源在电网中的占比逐渐增加,而新能源本身具有很强的波动性、显著的随机性和随时间周期变化的间歇性[1],导致电网结构发生不可忽略的变化,如电网负荷不稳定性增加,峰谷差随之增大[2]。这种情况下,既要保证电网的稳定性又要达到新能源的消纳指标,就需要传统火电机组通过电网调度参与调峰[3]。热电联产是电厂在生产电产品的同时,利用在蒸汽轮机中做完功的蒸汽为用户提供热产品的工艺过程。相较于单独生产电或热的方式,热电联产对一次能源的消耗量更少,排放的温室气体更少[4],运行方式也更加灵活。电厂恰当的运行方式能降低企业的发电成本,从而提高整体利润。因此热电联产机组在参与深度调峰时具有更大的优势。
机组参与深度调峰时要考虑负荷分配问题。热电联产机组既要满足热用户的供热要求,又要考虑如何分配电负荷从而使得发电和供热的利润最大化。这需要2 个步骤来达到准确分配热电负荷以期降低热电总成本[5],第一,需要建立热电联产机组能耗模型,该模型的准确性将直接影响负荷分配的合理性。目前采用的方法主要有:根据试验运行工况拟合热耗曲线,但是一般情况下,只有纯凝工况下的试验数据,对于带供热时的热耗情况没有试验数据支持;也有部分学者根据实时数据拟合热耗曲线,然而实时数据变化频繁,缺乏稳定性和可靠性,且需要寻找稳定工况的数据;也有人提出将热电联产机组根据供热循环和凝汽循环划分为一定数目的等效凝汽和背压机组[6]。第二,在能耗模型基础上建立热电负荷优化分配模型。目前采用的方法主要为人工智能算法,如粒子群算法[7]、等微增率法[8-10]、线性规划算法[11-12]、模拟退火算法、神经网络等。王珊等[7]研究热电联产机组的电热特性图后,通过变工况计算建立了热电联产机组能耗分析模型,采用粒子群算法对热电负荷建立了优化分配模型以期降低热电联产机组的总能耗,但未对机组能耗计算模型做详细介绍。李俊涛等[6]将复杂的供热机组根据供热循环和凝汽循环划分为一定数目的等效凝汽和背压机组,利用考虑了辅助汽水因素的单元进水系数法得到等效简单机组的特性方程,建立了相应的机组整体热电负荷分配的混合整数线性规划优化模型,这种分配模型有较强的理论支撑,且模型的简化减弱了组合爆炸后果,但是建模过程较为复杂且变量参数和约束条件较多,所以其负荷分配结果的准确性依赖测量设备的精准性。温志刚等在分析了供热机组热、电负荷分配特点的基础上,采用模拟退火算法建立了供热机组的热、电负荷分配模型[13],对2 台机组间的热、电负荷进行了优化分配,但存在模型求解时间长的问题。
本文首先通过性能考核试验报告数据,利用抽凝工况和纯凝工况时的相关数据推导出若干个不同供热负荷、发电负荷下的供热煤耗率和发电煤耗率。然后用origin 软件多项式拟合得到多个热负荷点对应的供热煤耗率曲线、发电煤耗率曲线,以及不同热负荷下机组的最大/最小发电功率曲线,充分考虑了供热对煤耗率的影响。接着在最大发电功率曲线和最小发电功率曲线之间的区域内,利用拉格朗日插值法得到可以计算任意供热负荷和发电功率的发电煤耗率曲面。在此基础上,根据当地深度调峰奖惩政策、煤价、电价、供热价格等,计算实时的成本和利润。最后采用遗传算法搜索当前供热负荷下使全厂利润最大的负荷分配方式。
1 煤耗率曲面
1.1 煤耗率
热电联产机组能耗模型的准确性直接影响负荷分配的合理性。由于试验报告中一般只有纯凝工况的数据,不能直接计算出供热和发电的利润以及后续的负荷优化分配,所以需要据此推导出供热时的发电煤耗率、供热煤耗率以及厂用电率。本文首先根据汽轮机热力特性书中低压缸效率曲线拟合低压缸效率与低压缸流量的关系表达式,然后根据纯凝工况试验报告数据,利用汽轮机轴端发电功率的计算公式,计算出对应工况的机械效率与发电机效率的乘积,然后拟合出汽轮机轴端功率与机械效率和发电机效率乘积的关系曲线。接着分别计算给定主蒸汽流量下,纯凝工况时的发电功率和不同供热功率下的发电功率,然后计算发电热耗量,并据此计算发电煤耗率和供热煤耗率。具体发电煤耗率和供热煤耗率计算步骤如图1所示。

图1 计算发电煤耗率和供热煤耗率Fig.1 The flow chart for calculating the coal consumption rate for power generation and heat supply
以某厂2 台型号CLN670-24.2/566/566 的汽轮机为例,该汽轮机为超临界、一次中间再热、双缸双排汽、单轴、抽汽凝汽式,加热器为3 高压加热器(高加)+1 除氧器+4 低压加热器(低加)。
纯凝工况时,汽轮机的轴端功率为
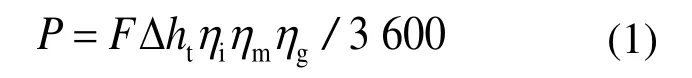
式中:F为汽轮机进汽量,t/h;P为汽轮机发电功率,MW;Δht为蒸汽在汽轮机中的理想比焓降,kJ/kg;ηi为汽轮机内效率;ηm为汽轮机机械效率;ηg为发电机效率。
为方便计算起见,将式(1)转化为

5 号—8 号低加、1 号高加以及3 号高加从汽轮机级中抽汽,而2 号低加、4 号低加从汽轮机末级抽汽不影响缸焓降,因此,式(2)中高压缸实际焓降ΔHH(MJ/h)为

中压缸实际焓降ΔHI(MJ/h)为

低压缸实际焓降ΔHL(MJ/h)为

式中:hHi、hIi、hLi分别为高、中、低压缸进口实际比焓,kJ/kg;hHo、hIo、hLo分别为高、中、低压缸出口实际比焓,kJ/kg;FHi、FIi、FLi分别为高、中、低压缸入口流量,t/h;Fj为j号高加抽汽流量,t/h;hj为j号高加抽汽焓值,kJ/kg。
根据式(2)可以计算出汽轮机机械效率与发电机效率的乘积ηmηg,由于ηmηg的变化主要与发电负荷有关,所以可以根据不同的纯凝工况重复若干个工况拟合出ηmηg与发电负荷P之间的关系曲线:

式中a2、b2、c2均为常系数。
纯凝工况时,给定主蒸汽流量下的发电功率由机组试验报告查得。当机组发电带供热时,如供热功率为Q(GJ/h),则供热流量为

式中h0为回水焓值,kJ/kg。
则供热功率为Q(GJ/h)时的发电功率Pr(MW)为

其中低压缸实际焓降ΔHL′(MJ/h)为

式中低压缸效率可将(FLi–hLo)代入式(10)计算得出,根据汽轮机特性说明书中低压缸效率随流量变化的特性曲线,拟合低压缸效率随低压缸流量变化的表达式为

式中:ηL为低压缸效率,%;FL为低压缸流量,t/h;a1、b1、c1为常系数。
发电热耗量QP(GJ/h)为

式中Qnet为蒸汽侧吸热量,GJ/h,计算式为

因此,带供热时的发电煤耗率bd(g/(kW·h))为

式中,ηb为锅炉效率,ηp为管道效率。
而纯凝工况的发电煤耗率b(g/(kW·h))为

按照功率损失法,热电联产生产过程中因抽汽供热而引起的汽轮机组电功率的减少量就是供热产生的成本[14]。带供热时的供热煤耗率br(g/GJ)可表示为
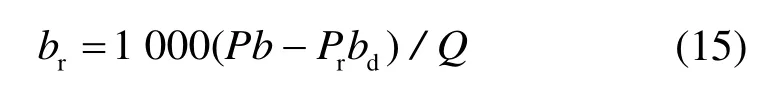
利用上述方法计算出不同工况下的煤耗率,然后利用origin 软件多项式拟合出煤耗率曲线。
1.2 煤耗率曲面计算
拉格朗日插值法是一种多项式插值方法。许多实际问题中都用函数来表示各个结果之间某种内在联系或规律,而不少函数都只能通过反复实验和多次观测来了解[15]。如果对实践中的某个物理量进行观测,在若干个不同的地方得到相应的观测值,拉格朗日插值法可以找到一个多项式,其恰好在各个观测的点取到观测到的值。这样的多项式就称为拉格朗日(插值)多项式。对某个多项式函数,已知有给定的k+1 个取值点:(x0,y0),… ,(xk,yk)。其中xk对应自变量的取值,yk对应函数在这个位置上的取值。假设任意2 个不同的xk都互不相同,那么应用拉格朗日插值公式得到的拉格朗日插值多项式为

式中每个lj(x)为拉格朗日插值基函数,其表达式为

拉格朗日基函数lj(x)的特点是在xj上取值为1,在其他点上取值为0。
假设机组的发电煤耗率在供热功率(MW)为Q1、Q2、Q3时的表达式分别为:

式中:x为发电机功率,MW;bdi为发电煤耗,g/(kW∙h)。
将拉格朗日插值法进行拓展,得到发电煤耗率曲面,此时的基函数lj(y)为:

式中yi为供热功率,MW。
因此由根据拉格朗日插值法得到的发电煤耗曲面为

由式(24)可以计算任意供热负荷、任意发电功率下的发电煤耗率。同理可得任意供热负荷、任意发电功率下的供热煤耗率br和厂用电率σ:

2 深度调峰模式下利润计算模型
以某热电联产机组为例,当地深度调峰的补贴政策见表1。若电网调度需要深度调峰,而电厂未参与调峰,此时未参与调峰的分摊金额为Φ(元/h)。此外机组是否参与调峰以及参与哪档调峰是根据所有机组的功率之和来判定,而非根据单台机组功率判定。

表1 当地深度调峰补贴政策Tab.1 The local in-depth peak shaving subsidy policy
对于某热电联产机组的2 台机组进行负荷优化分配,以全厂利润最大化为目标,该厂的供热、发电负荷优化分配数学模型如下。
目标函数,即全厂利润为

发电功率约束为

供热功率约束为

机组发电功率与供热功率耦合约束为

式中:J为全厂总利润,元;Ji为第i台机组的利润,元;pi为第i台机组的发电功率,MW;Δpi为调峰负荷,MW;和分别为第i台机组的下限发电功率和上限发电功率,MW;P为总发电功率,MW;σi为厂用电率,%;qi为第i台机组的供热功率,MW;和分别为第i台机组的下限和上限供热功率,MW;Q为总供热功率,MW;pp为售电价格,元/(kW·h);pq为售热价格,元/GJ;pc为燃煤价格,元/t;ξ为调峰补偿系数,%;Φ为未参与调峰分摊金额,元/h;ηi为第i台机组发电效率,%;Qnet为燃煤低位发热量,kJ/kg;f1(qi)=max{pi(汽轮机进汽量最大时)|qi},即当前供热功率下,汽轮机进汽量最大时达到的发电功率函数;f2(qi)=max{pi(锅炉最小稳燃负荷);pi(低压缸最小冷却流量下的负荷)|qi},即当前供热功率下的最小发电负荷,取决于锅炉最小稳燃负荷和低压缸最小冷却流量的负荷函数。
3 基于自适应遗传算法的负荷优化分配求解
遗传算法通过模拟自然界生物遗传和进化过程来求解极值问题。从任意的初始种群开始,遗传算法通过个体的遗传和变异有效地实现了稳定的优化选育过程,从而可以将种群进化到更好的搜索空间区域[16]。自适应遗传算法是对基本遗传算法的一种改进,通过对遗传参数的自适应调整,大大提高了遗传算法的收敛精度,加快了收敛速度。
自适应遗传算法求解热电联产机组最优负荷分配具体步骤如下:
1)编码 通过约束条件式(28)—式(30),对2 台机组的发电功率做实数编码,由于约束区间较大,为加快迭代速度,设定种群数量为100。
2)适应度计算 将深度调峰模式下热电联产机组的利润(式(27))作为适应度函数,计算每个染色体的适应度值,并对适应度值进行标准化,即将适应度函数为负的赋值为0。
3)选择 基于轮盘赌法对标准化后的适应度进行选择。
4)交叉 本文通过自适应交叉与自适应变异提高算法的收敛速度和全局搜索能力,从而提高算法的执行效率。计算每对染色体对应的交叉概率pc

式中,fmax为最大适应度,fs为选中染色体中较大的适应度,fa为平均适应度,k1=1,k2=0.5。
当随机概率小于pc时,进行染色体交叉,交叉原则为:

式中:α为交叉算子,取0.6;c1为交叉后的x1变量;c2为交叉后的x2变量;ch1为交叉前的x1变量;ch2为交叉前的x2变量。
5)变异 计算每对染色体的变异概率,进行单点变异。首先,计算每对染色体对应的自适应变异概率pm

式中,k3=1,k4=0.5。当随机概率小于pm时,进行染色体变异,随意选择染色体变异。由于初始种群采用实数编码,因此实数变异即为该染色体基因初始化的过程。
迭代次数设置为150,通过迭代,找出最优个体。最优个体对应的染色体即对应供热、发电总利润最大时的发电功率。
4 实际算例及结果
首先计算煤耗曲线,根据某电厂2×670 MW 纯凝工况性能考核试验报告数据,按照前文方法,计算并拟合不同供热负荷下,随发电负荷变化的供热煤耗率和发电煤耗率(表2),利用origin 软件多项式拟合的供热煤耗曲线和发电煤耗曲线如图2所示。

表2 不同工况下的煤耗率Tab.2 The coal consumption rate under different working conditions

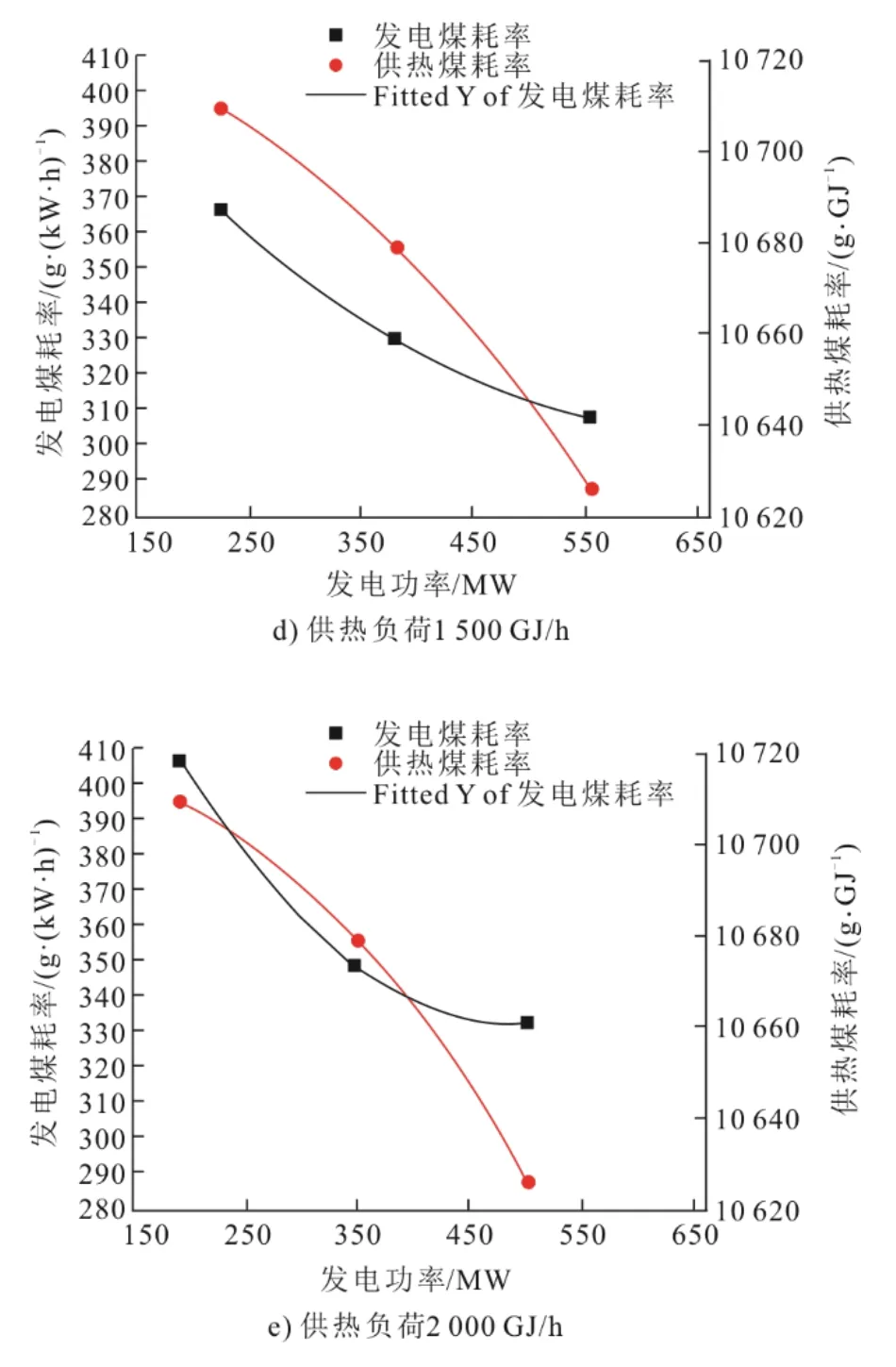
图2 发电煤耗率曲线Fig.2 The coal consumption curves
以1 号机组为例,供热负荷为0、500、1 000、1 500、2 000 GJ/h 时发电煤耗曲线表达式分别为:


利用1.2 小结中拉格朗日插值法得到的以供热功率和发电负荷为自变量,发电煤耗率为因变量的曲面为

同理可以插值得出供热煤耗曲面和厂用电率煤耗曲面。
取锅炉稳燃负荷率为40%,低压缸最小冷却流量为额定流量的10%,根据1.1 小节确定在某供热负荷下机组负荷的可行域为

将煤耗率曲面、供热煤耗曲面和厂用电率曲面的表达式结合利润计算模型(式(20)—式(23)),即可得到利润曲面,将供热负荷定义为不同的值即可得到不同供热负荷下、不同不参与深调时分摊金额下的单机运行利润曲线,如图3—图5所示。类似地,将2 台机组的煤耗率曲面结合利润计算模型可以得到不同供热负荷下双机组运行时的利润曲面(图6)。

图3 供热期不参与深调分摊为5 000 元/h 时不同供热负荷单机运行利润曲线Fig.3 The operating profit curves of the unit during single-machine running at different heating loads(in heating period with no deep peek regulation,proportion 5 000 yuan/h)

图5 非供热期不参与深调分摊为5 000 元/h 时不同供热负荷单机运行利润曲线Fig.5 The operating profit curves of the unit during single-machine running at different heating loads(in non-heating period with no deep peek regulation,proportion 5 000 yuan/h)
该电厂为单机供热,设置电售价0.39 元/(kW·h),热售价21 元/GJ,煤价610 元/t。表3 为1 号机组单机运行时不同运行状态下机组利润。应用遗传算法进行负荷优化分配后的利润对比,各工况下利润随发电负荷的变化曲线如图3所示。表4 为双机运行时不同运行状态下机组利润。各工况下利润随2 台机组发电负荷变化的曲面如图6所示。

图6 供热期不参与深调分摊为5 000 元/h 时不同供热负荷双机运行利润曲面Fig.6 The operating profit curve surface of the unit during two-machine running at different heating loads(in heating period with no deep peek regulation,proportion 5 000 yuan/h)

表3 1 号机组单机运行不同运行状态下机组利润Tab.3 The profit of No.1 unit during single-machine running at different states

表4 双机运行不同运行状态下机组利润Tab.4 The profits of the units during two-machine running at different states
对比遗传算法给出负荷分配结果和图3—图5曲线变化,可以得出遗传算法给出的负荷分配是较为合理的数值。由图2—图6 及表2—表4 还可以发现:
1)供热功率 单机运行时,观察图3 单机案例发现,当供热功率较小且不参与调峰时的分摊金额(即惩罚金)较小时,发电负荷越大,总体利润越高,原因是此时抢发电量带来的利润高于参与深度调峰带来的利润。当供热负荷较大时,发电负荷越小,总体利润越高。原因是此时机组供热,最大发电功率受到限制致使参与深度调峰带来的补贴收益较高,总体收益大于抢发电量带来的收益。当供热负荷很大时,由于此时最小发电功率受到限制无法参与二档调峰,致使抢发电量带来的收益更大。
2)调峰分摊金额 观察图4 单机案例发现,当调峰分摊金额较大时,应尽量使机组在保证安全的同时在较低负荷段运行。

图4 供热期不参与深调分摊为40 000 元/h 时不同供热负荷单机运行利润曲线Fig.4 The operating profit curves of the unit during single-machine running at different heating loads(in heating period with no deep peek regulation,proportion 4 000 yuan/h)
3)运行时期 对比图5 和图3 发现,由于不同档的深度调峰补贴政策不同,即使相同的运行参数得到的热电总利润也不相同,非供热期应尽量使机组处于高负荷运行。
4)运行方式 对比双机运行案例(图6)和单机运行案例(图3)发现,当供热负荷相同,总发电负荷也相同时,双机运行可以带来更多的利润。如单机500 MW 时视为不参与调峰,而双机运行每台250 MW 视为参与二档调峰,所以会享受到较高额的别贴。
对比表3 或表4 中的负荷优化前后的利润,可以看出经过负荷分配优化后的热电总利润均有显著提升。综上所述,热电联产机组在运行时应综合考虑运行时期、供热功率、调峰分摊金额和运行方式等因素来调整运行策略,使电厂利润最大化。
5 结语
本文基于热电联产机组性能试验报告数据,提出一种新的方法推算不同供热负荷、发电负荷下的供热煤耗率和发电煤耗率,并据此建立热电联产机组煤耗率模型,结合当地的调峰补贴价格和实时的不参与调峰时的分摊金额,计算实时成本和利润。然后利用自适应遗传算法在当前供热功率下的曲线/曲面里找出使得机组收益最大的运行参数,为发电企业提供运行建议,用以提高发电企业的整体收益。
