车载激光点云中交通标线自动分类与矢量化
2021-10-27方莉娜赵志远付化胜陈崇成
方莉娜,王 爽,赵志远,付化胜,陈崇成
1. 福州大学地理空间信息技术国家地方联合工程研究中心,福建 福州 350002; 2. 空间数据挖掘与信息共享教育部重点实验室,福建 福州 350002; 3. 福州大学数字中国研究院,福建 福州 350002; 4. 福建省水利水电勘测设计研究院,福建 福州 350002
交通标线作为路面重要的特征标志,高精度的几何与语义信息如形状、位置、拓扑和结构关系信息的快速获取与更新对保障交通安全具有重要作用,是智能交通、智能高精地图、导航与定位服务等邻域的基础和核心元素[1-4]。车载激光扫描系统(mobile laser scanning systems,MLSs)作为近年来快速发展的高新测绘技术,能够高效、精确地获取道路场景的三维空间信息和回波强度信息,为大范围道路标线的识别和更新提供一种新的数据源[5-7]。
由于交通标线类别多样,行人和车辆等大范围遮挡和干扰会影响标线几何和纹理特征分布的连续性。如何判别分割后标线的类别,特别是相似标线的判别是标线分类难点问题。一些学者通过联合标线形状特征[6]、空间分布特征(方向、排列)[8]以及道路场景语义特征[9],利用决策树[10]、支持向量机(support vector machine,SVM)[11]、模板匹配[12-13]等分类器实现相似标线的区分,如根据相邻对象的平行关系将斑马线与虚线型标线进行精细区分[14]或利用模板匹配精细区分不同箭头标志。这些方法在一些较为规则的道路场景中取得了较好的标线分类效果,但特征选择和参数设置需要较强的先验知识,在复杂场景中自动化程度和稳健性较差。
近年来,利用深度学习理论,自动提取不同类型标线的高层次特征实现精细分类,成为发展趋势。文献[15]采用层次化分类的策略,利用尺寸信息区分大尺寸(实线标线)和小尺寸标线(非实线标线),然后将虚线、箭头等小尺寸标线栅格化成图像并构建形状描述子,采用深度玻尔兹曼机(deep Boltzmann machine model,DBM)进行标线精细分类,并结合标线排列规则,进一步优化小尺寸标线分类结果。文献[16]改进原始U-net模型[17]损失函数模型,从点云强度特征图像中进行标线分割,利用卷积神经网络(convolutional neural networks,CNN)自动提取交通标线的高层特征,实现小尺寸标线的精细分类。目前这些深度模型在小尺寸标线分类中取得一些突破性成果,但需要预先分离实线标线,且需要人工定义语义规则区分形状相似标线,缺乏场景先验知识指导,降低了标线提取的完备性和可靠性。
图是一种常见的具有强大表达力的数据结构,被广泛应用于构建对象间拓扑及语义关系[18-19]。近年来,一些研究者将图结构嵌入到深度模型中,探索基于图深度学习的点云目标分类与识别[20-21]。文献[22]提出基于离散点的边卷积模块(edge convolution,EdgeConv)。该模块在保证点云置换不变性的同时抽取点云间局部邻域信息,利用动态卷积神经网络(dynamic graph CNN,DGCNN)聚合局部邻域节点特征实现点云公开数据集的分割与分类。文献[23]使用通用卷积核(generic and efficient operation convolution,GeoConv)提取每个点中心点及其近邻点之间的边特征时,获取离散点之间的局部几何关系,提高点云分类精度。文献[24]提出一种图注意力卷积网络(graph attention convolution network,GACNet),通过给近邻点分配特定的注意权重,自适应聚焦关键特征,动态拟合特定形状以适应对象的结构,在点云公开数据集上取得了良好的分类效果。
交通标线作为人工地物,其存在和出现具有固定结构和模式,可以根据周围标线对象的拓扑和语义位置关系对其类型进行推断。针对以上问题本文提出一种适用于车载激光点云交通标线分类的深度图注意力网络GAT_SCNet。该模型能够自适应学习不同标线类别图结构特征,将标线精细分类问题转化为图结构中节点分类问题,实现车载激光点云中全类型标线的高精度分类;针对不同类型的交通标线,制定相应的矢量化方法,提供不同类别的矢量专题图层。因此,本文创新点主要有:
(1) GAT_SCNet标线分类模型在不需要预先分离实线型标线的前提下,利用重采样图结构来抽象表示不同道路场景中标线间的几何、拓扑和语义关系,实现不同场景中全类型标线的统一邻域结构表示。
(2) GAT_SCNet标线分类模型利用多头注意力模块建立标线邻域图结构中节点和边的特征聚合机制,实现图结构节点特征的动态更新,利用一组共享权重的多层感知机(multi-layer perceptron,MLP)对节点特征进行学习,从而实现全类型标线的精细分类。
(3) 利用点云模板匹配和GVF Snake模型分别实现非实线型和实线型标线的矢量化,能够得到形状完整且位置精度较高的标线矢量轮廓信息。
1 融合空间上下文信息的深度图注意力模型GAT_SCNet
在深度图模型GAT_SCNet中,主要通过注意力机制聚合标线自身的特征和邻居标线的形成中心节点特征hv,利用MLP{512,256}和Softmax层组成的分类器对节点特征hv进行标线类别预测实现标线精细分类,网络结构如图1所示。GAT_SCNet模型以分割后N个独立标线作为输入,n为每个独立标线包含点云个数,输出为独立标线的类别标签c,包括3个主要模块:①标线特征提取与嵌入表示;②重采样标线邻域图结构;③融合多头注意力机制的节点更新。
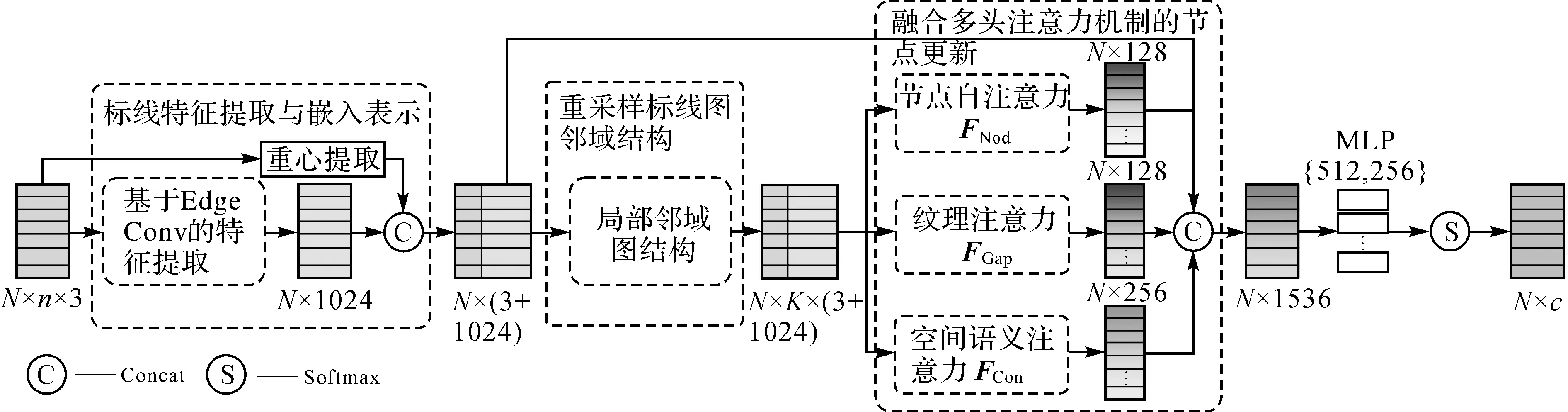
图1 融合空间上下文信息的车载激光点云标线分类图注意力模型——GAT_SCNetFig.1 A deep graph attention network GAT_SCNet road markings classification from mobile lidar point clouds
1.1 标线特征提取与嵌入表示
为了获取独立的标线对象,本文预先采用文献[25]的方法提取路面点云并增强路面点云强度信息,然后利用k均值和连通分支聚类方法将标线分割为独立对象,再将独立标线编码成节点特征嵌入到神经网络。路面标线种类繁多、形状各异,因遮挡、路面磨损及标线分割质量等因素会导致标线形状残缺,相同类别的标线也具有较大的形状、位置和纹理差异。为提取不同类型标线的可区分局部信息,如图2所示,本文堆叠两个EdgeConv模块提取标线的局部边特征,并将两个EdgeConv模块特征拼接后进行不同尺度特征融合,利用MLP{1024}学习独立标线的全局形状特征g
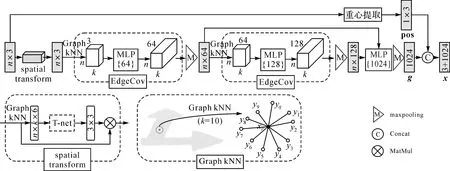
图2 基于EdgeConv的节点特征提取Fig.2 Node features extraction based on EdgeConv module
(1)
x=[pos‖g]
(2)
1.2 重采样标线邻域图结构
利用标线图结构进行分类不仅依赖前文中的节点嵌入特征,还依赖图的结构信息。因此本文利用独立标线对象的k(k-nearest neighbor,kNN)近邻标线作为邻居节点,建立标线邻域图结构。传统方法以标线间重心点距离进行kNN近邻对象搜索,会导致更利于中心标线识别的邻居标线由于重心点间距离较大在搜索时被忽略,因而无法准确构建标线邻域图结构。如图3(a)所示,对于中心停止线,边缘实线因重心点间距离较大,不在k近邻范围中。针对此问题,本文提出基于标线间最短距离的重采样邻域图结构构建方式(图3(b))。
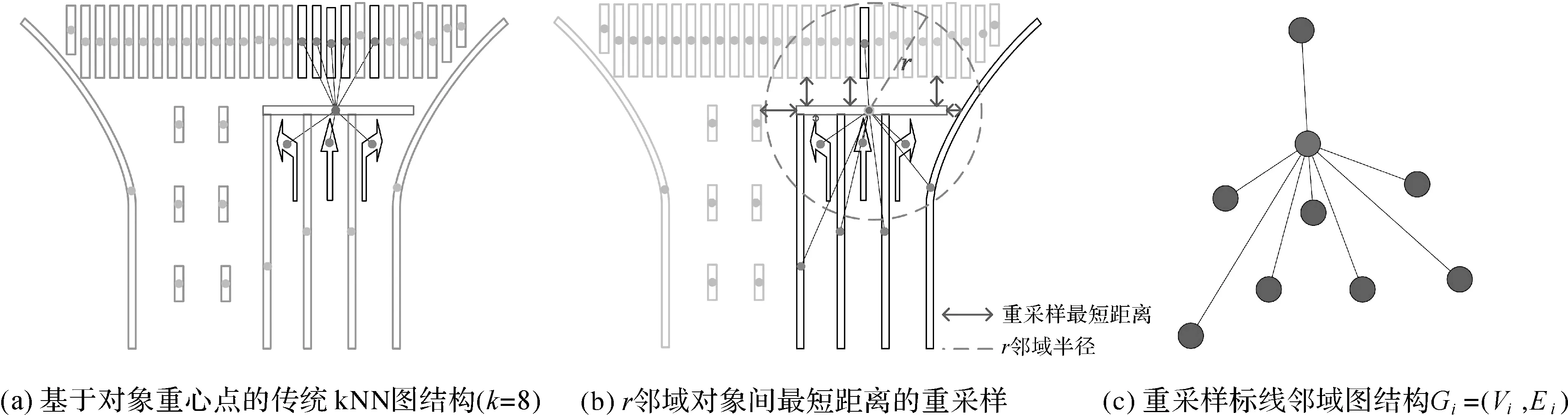
图3 重采样标线图结构Fig.3 Resampled marking graph structure
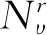
(3) 建立标线i邻域图结构Gi=(Vi,Ei),其中Vi={υi,u1,…,uj},j∈(1,K)为图的节点,Ei={ei1,ei2,…,eij},j∈(1,K)为中心节点υi与邻居节点uj之间的边。
1.3 融合多头注意力机制的节点更新
标线作为人工地物,其出现和存在与周围标线的类型、空间结构密切相关。为了动态建立不同标线的结构关系,GAT_SCNet模型在前文构建的标线邻域图结构的基础上融合多种注意力机制聚合邻居节点的特征进行图结构学习,其中包括节点自注意力、纹理注意力和基于空间结构的语义注意力(图4)。
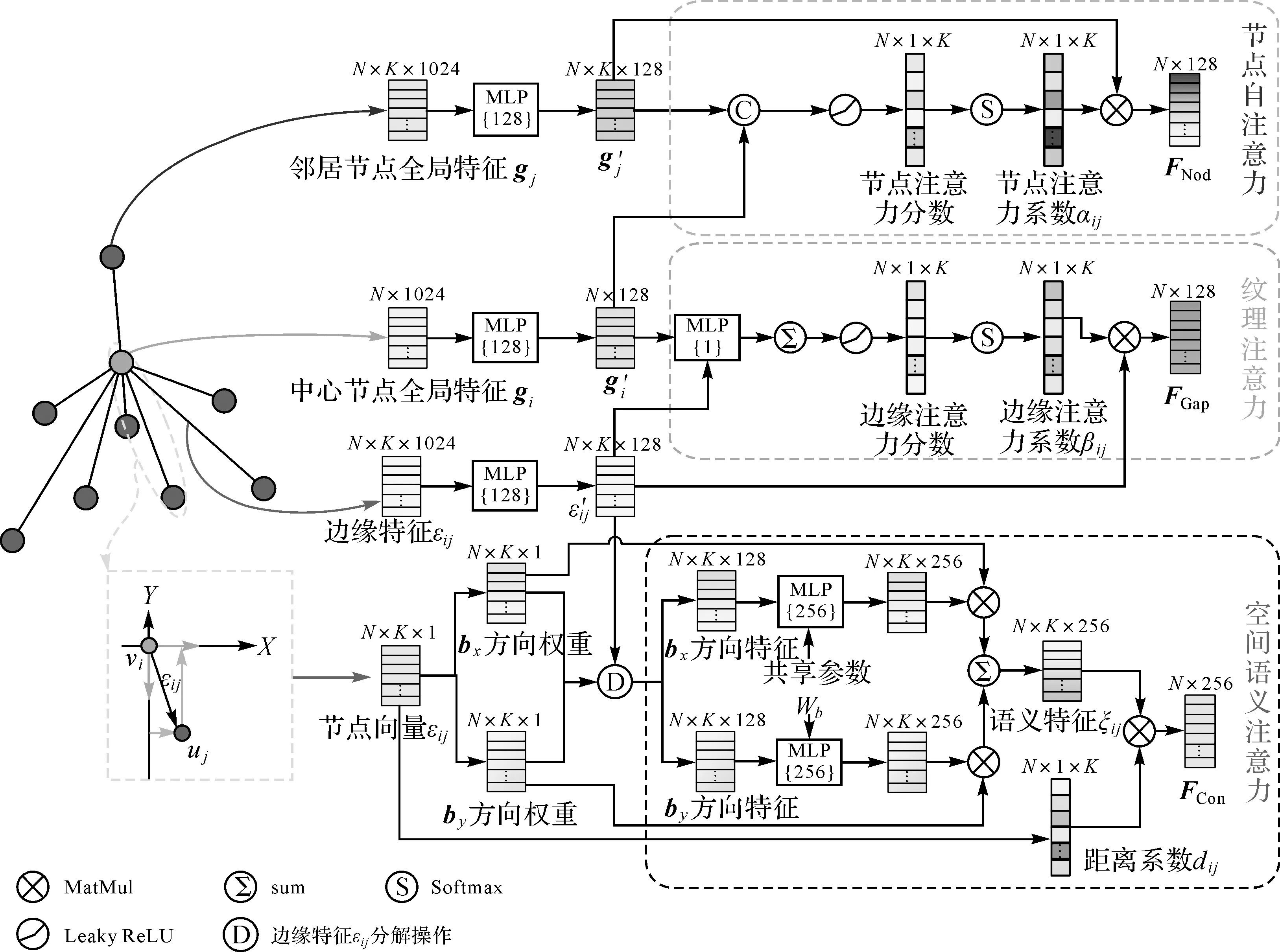
图4 多头注意力机制的节点聚合模块Fig.4 Node features aggregator based on multi-head attention mechanism
为了使注意力机制层具有丰富的表达能力,将节点全局特征g进行编码映射为更高层次特征g′
g′=h(g,θ)
(3)
式中,h(·)为非线性参数函数,选用激活函数为ReLU单层感知机进行学习;θ为网络参数。
定义边缘特征eij为节点间全局特征的差异
eij=gi-gj
(4)
1.3.1 节点自注意力特征FNod
在图结构中,与中心节点具有相似全局特征的邻居节点更利于中心对象的识别。为了使GAT_SCNet模型在学习过程中增大相似邻居节点的特征权重,本文通过文献[24]提出的节点注意力有效刻画这种相似性特征关系。
根据节点注意力机制,本文对邻居节点特征加权聚合作为中心节点的节点注意力特征FNod为
(5)
式中,f(·)为非线性聚合函数;aT为一个可训练的节点级的注意力向量;LeakyReLU表示激活函数。
1.3.2 纹理注意力特征FGap
标线自身信息和与邻居标线的联结强度能更好地表达邻域图结构的纹理结构特征,而图注意力网络(graph attention based point network,GAPNet)(https:∥arxiv.org/abs/1905.08705.)通过自注意力来提取中心对象自身特征,邻域注意力来提取中心对象与周围邻居之间的结构关系,以此获取更为丰富的图结构特征。因此本文在GAT_SCNet模型中融合自注意力与邻域注意力计算中心节点υi和边缘特征eij形成的纹理特征FGap
(6)
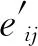
1.3.3 空间语义注意力特征FCon
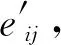
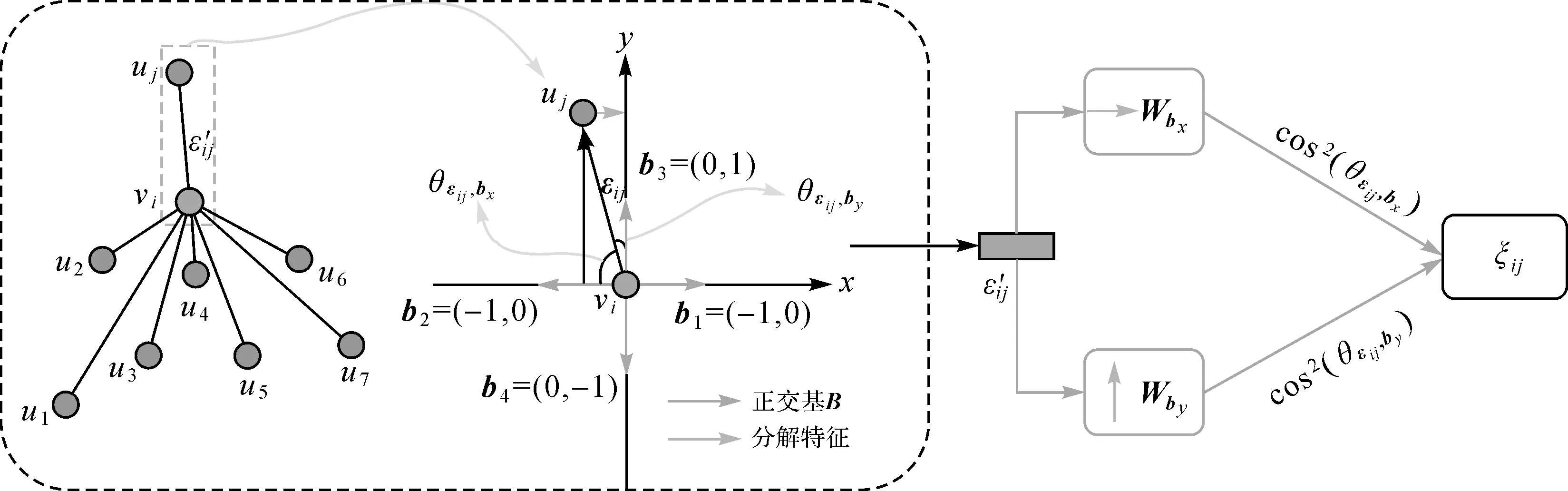
图5 基于空间方向的边特征分解Fig.5 Edge features decomposition based on its spatial direction
(7)
式中,节点向量εij为中心标线重心点指向邻居标线重心点向量(εij=posj-posi);为了区分正交基的正负方向,定义正交基B={b1,b2,b3,b4}={(1,0),(-1,0),(0,1),(0,-1)};Wb为特征分解转换矩阵,通过MLP学习。
然后根据标线间距离dij对节点语义特征ξij加权聚合得到中心节点υi的空间语义注意力特征FCon
(8)
(9)
本文将节点、纹理和语义注意力特征与中心点vi进行特征拼接,经过特征更新函数ζ(·)得到输出特征hv进行整个图神经网络的节点特征更新,将更新后的节点特征作为下一次循环的输入
(10)
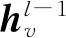
1.4 损失函数
在城市道路场景的中,虚线、斑马线数量占较大比例,采用标准的交叉熵损失函数来训练GAT_SCNet模型容易导致严重的类别不平衡问题,数量较少的标线(箭头、符号)损失将无法精确计算。因此本文在目标损失函数中引入中值频率平衡策略[26-27]来加权每个类的损失,如式(11)所示。
(11)
(12)
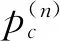
2 道路标线矢量化
为保证标线矢量化数据的完整性,基于精细分类后结果,对非实线型标线建立一组形状完整的标线标准模板库,通过计算待测标线R和标准模板Mm之间归一化形状互相关(normalized cross correlation,NCC)系数S(R,Mm)来度量二者的相似性,取最大系数对应的模板标线作为匹配模板M*
(13)
(14)
式中,gR、gMm为前文中节点特征提取网络提取的全局特征;cov(·)为特征协方差矩阵函数;D(·)为特征方差函数;m为每类标线标准模板个数。
将匹配模板M*坐标(XM*,YM*,ZM*)依据标线的空间姿态进行微量旋转和平移,同时将模板边界点赋给待测标线,按照边界点次序依次相连,线状标线存储为线状矢量图层,非线状标线存储为多边形矢量图层
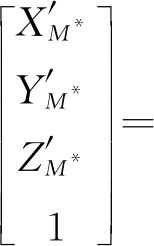
(15)
式中,Δx、Δy、Δz为标线间中心点坐标差;η为待测标线R和标准模板M*主方向夹角。
对实线型标线基于GVF Snake模型[28]进行矢量化,生成相应的实线型标线的矢量化数据,存储到线状矢量图层。
3 试验与分析
3.1 试验数据
本文选取3份国内外不同道路场景和数据差异的车载激光点云数据作为训练数据:训练数据Ⅰ中标线类别相对齐全、完整度较好;训练数据Ⅱ和Ⅲ中均缺乏部分异形标线且标线存在不同程度的缺失和噪声。整体而言3份训练数据中标线类型多样,标线及邻域图结构的缺失增强了训练样本完备性,能够满足GAT_SCNet模型的训练需要。
区别于训练数据,本文采用4份试验数据验证GAT_SCNet标线分类模型的有效性。这4份试验数据由不同车载激光采集系统获取,位于国内外不同区域,数据质量和场景具有较大差异(如图6(b)),其中试验数据Ⅰ和Ⅱ均为城市道路场景,数据中标线种类繁多且存在因遮挡、路面磨损、点密度不均等造成的标线残缺,导致实线、斑马线等同类标线(①—④)过分割为多段,长短不一,形状多样,较难进行标线的精细分类;试验数据Ⅲ和Ⅳ为高速公路场景,数据中包含大量虚线和实线,道路边缘存在由于遮挡造成的实线型不连续,导致较短的实线型标线易与虚线等混淆,影响标线精细分类精度,同时试验数据Ⅲ中存在大量曲线型和部分环状实线(⑤),试验数据Ⅳ中存在多种汉字符号(⑥和⑦),均与训练数据有较大的差异,增大了标线分类的难度。
本文预先利用文献[25]中方法从数据中分割出独立标线,根据《城市道路交通标志和标线设置规范 GB 51038—2015》对交通标线的相关规定,将标线划分为菱形、虚线、直行箭头、单向转向箭头、双向转向箭头、斑马线、停止线、符号(文字、三角形、自行车标记)、实线9类。训练数据和试验数据一些具体信息见表1。原始点云和分割后标线如图6所示(标线对象随机赋色)。由于试验数据Ⅳ数据范围较大,图6中仅展示部分代表性的子场景。

图6 不同道路场景的训练数据集和试验数据集(标线对象随机赋色)Fig.6 The training datasets and test datasets of different road scenes (individual road markings colored randomly)
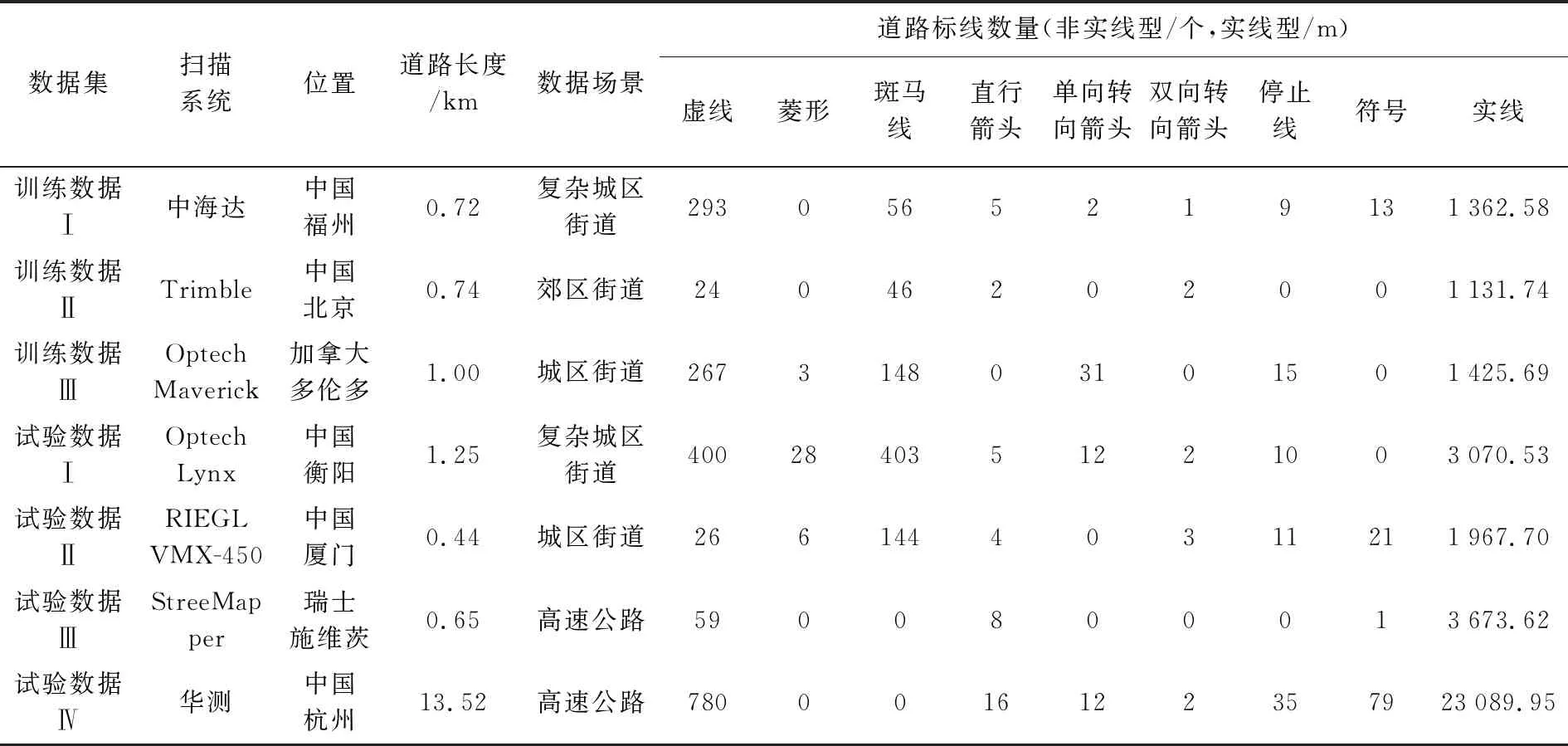
表1 试验数据集基本信息Tab.1 Descriptions of the experimental datasets
在分割后的训练数据中,本文沿道路方向随机选取长为15 m的路段作为批训练样本场景,通过水平旋转、抖动、标线残缺处理等操作扩增形成5500个路段作为训练样本,其中随机选取4000个样本作为训练数据,其余样本作为试验数据。在标线矢量化过程中,根据非实线型标线不同的形状、大小、长度等从数据中选取了各类别数量不一的完整标线作为匹配模板,部分匹配模板如表2所示。
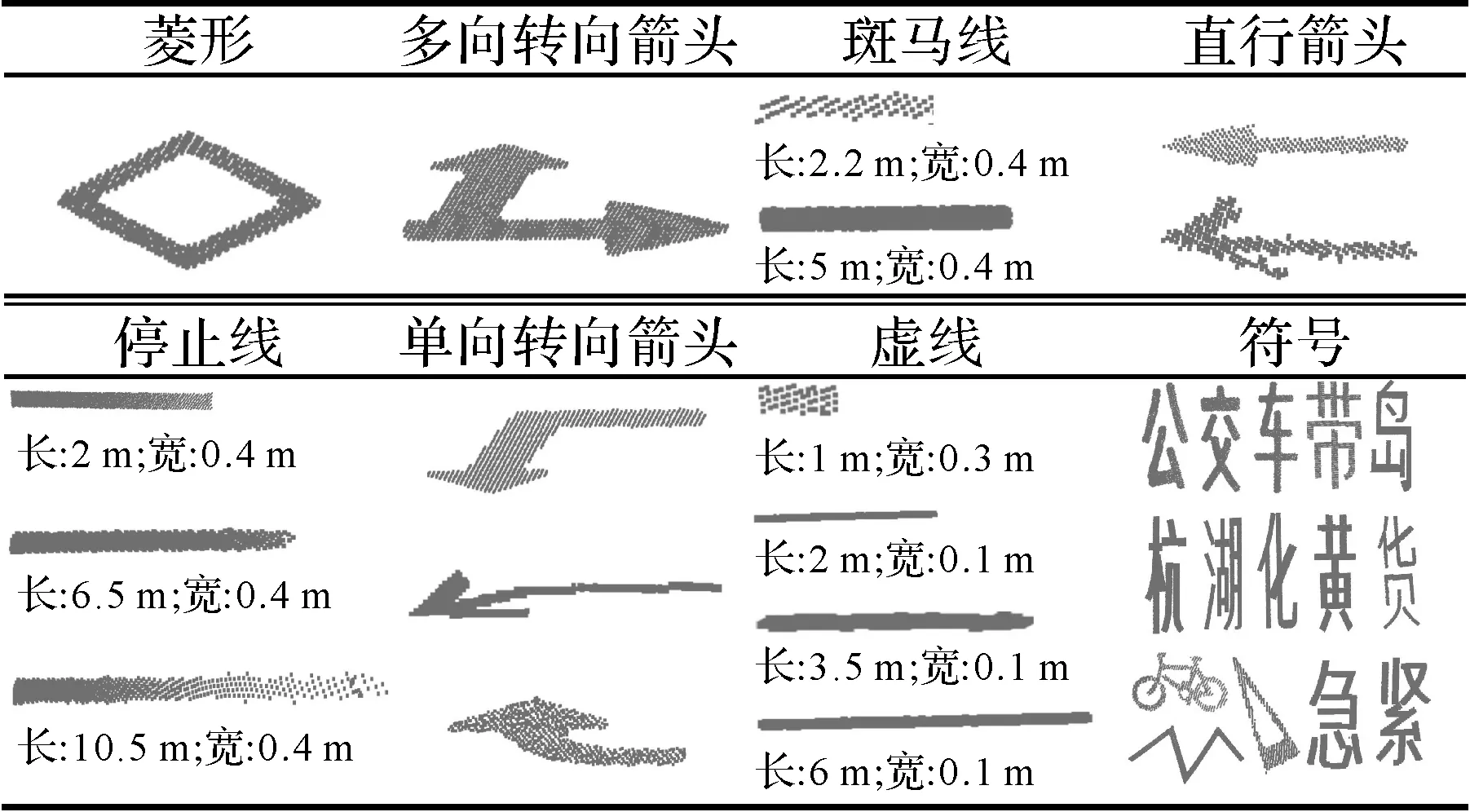
表2 非实线型标线匹配部分标准模板集Tab.2 Road marking matching standard template set
3.2 试验结果
图深度模型GAT_SCNet基于Python 3.5构建,主要使用的库有Tensorflow GPU 1.8.0,CUDA 9.0,cuDNN 7.0等,所有试验均在配置为NVIDIA GeForce GTX 1060 3 GB的环境上运行。
对于道路场景中所有标线,依据每个标线的位置,根据国内外车道宽度设置邻域半径r为7 m,即为1.5倍车道宽度,遍历此范围内的标线进行节点重采样,选取距离最短的8(K=8)个邻域节点构成中心节点的子图结构。对于深度图模型GAT_SCNet,在训练阶段本文采用带动量(Adam)的小批量随机梯度下降法(stochastic gradient descent,SGD)进行优化。

由于GPU能力的限制,综合考虑训练精度与时间效率,本文将批处理大小(batch size)设置为16,初始学习率为0.001,衰减率与步长(epoch)分别设置为0.98和65,动量设置为0.5对GAT_SCNet网络进行训练和学习。4份试验数据利用本文方法的精细分类与矢量化结果如图7所示。
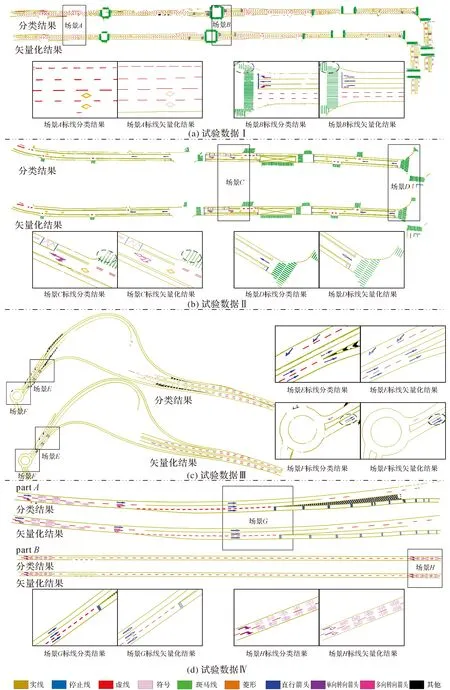
图7 交通标线分类和矢量化结果Fig.7 Classification and vectorization results of road markings
由图7中可以看出,本文构建的深度图注意力模型GAT_SCNet能够准确识别绝大多数道路标线,不仅能够有效区分形状差异较大的菱形、箭头、符号,同时对形状相似度高的虚线、斑马线、停止线、实线也能够精细分类,能较好地克服大尺寸实线型标线对小尺寸标线影响,具有较强的稳健性。对于因磨损、遮挡导致的标线缺失如菱形(场景A)、斑马线(场景B和场景C)、符号(场景H)或因过分割导致同一目标存在多个部分的箭头标线(场景F),深度图模型GAT_SCNet能够准确将其分类,能够较好地克服原始数据质量及分割结果对标线形状、结构的影响。
利用模版匹配能够较好地进行非实线标线的矢量化,如菱形(场景A)、箭头(场景E)、斑马线等缺失部分(场景B和场景C)利用模板匹配后能精确描述标线结构完整的形状、位置等信息的矢量数据。对于不同形状的实线如直线(场景C)、曲线(场景D)、高速路交汇线(场景E和场景G)和高速出入口的转盘(场景F),利用GVF Snake模型都能完整和准确提取其矢量化数据。场景A中因遮挡原因,边缘处实线结构不完整,导致该处的实线被错误分类为虚线,本文利用GVF Snake模型依据全局场景结构对该处进行矢量化,纠正该错误类别。
3.3 试验结果分析与精度评价
由于试验数据原始信息中没有真实标签,本文通过CloudCompare软件人工标定9类标线,采用准确率(precison,P)、召回率(recall,R)评价4份试验数据中标线分类精度
(16)
(17)
式中,TPs为标线正确识别的数量;FPs为标线错误识别的数量;FNs标线未被识别的数量。本文只对试验数据中存在的标线类型进行统计(表3)。非实线标线按类别个数统计,实线型标线按线段长度统计。
由表3中可以看出,城市道路场景(试验数据Ⅰ和Ⅱ)中GAT_SCNet模型对菱形、多类箭头和符号的标线分类精度能达到100%,同时对虚线、斑马线和实线的识别召回率在90%以上,说明本文方法在城市道路场景中能精确识别大部分标线,对形状相似的线状标线的识别也较为稳健。而试验数据Ⅰ停止线召回率仅有70%是因为数据扫描过程存在地物遮挡且远距离处点密度较小,导致少量停止线发生过分割,未与实线型相连的停止线被误分为虚线(如图8场景A),并且原始数据场景中停止线数量少,因此召回率低。试验数据Ⅱ道路中设置了交通护栏,导致实线由于遮挡被分为多段,其中部分形状、大小、空间结构与虚线、斑马线相似的会产生交叉错分(如图8场景B和场景C),导致该数据中这两类标线的准确率相对较低。
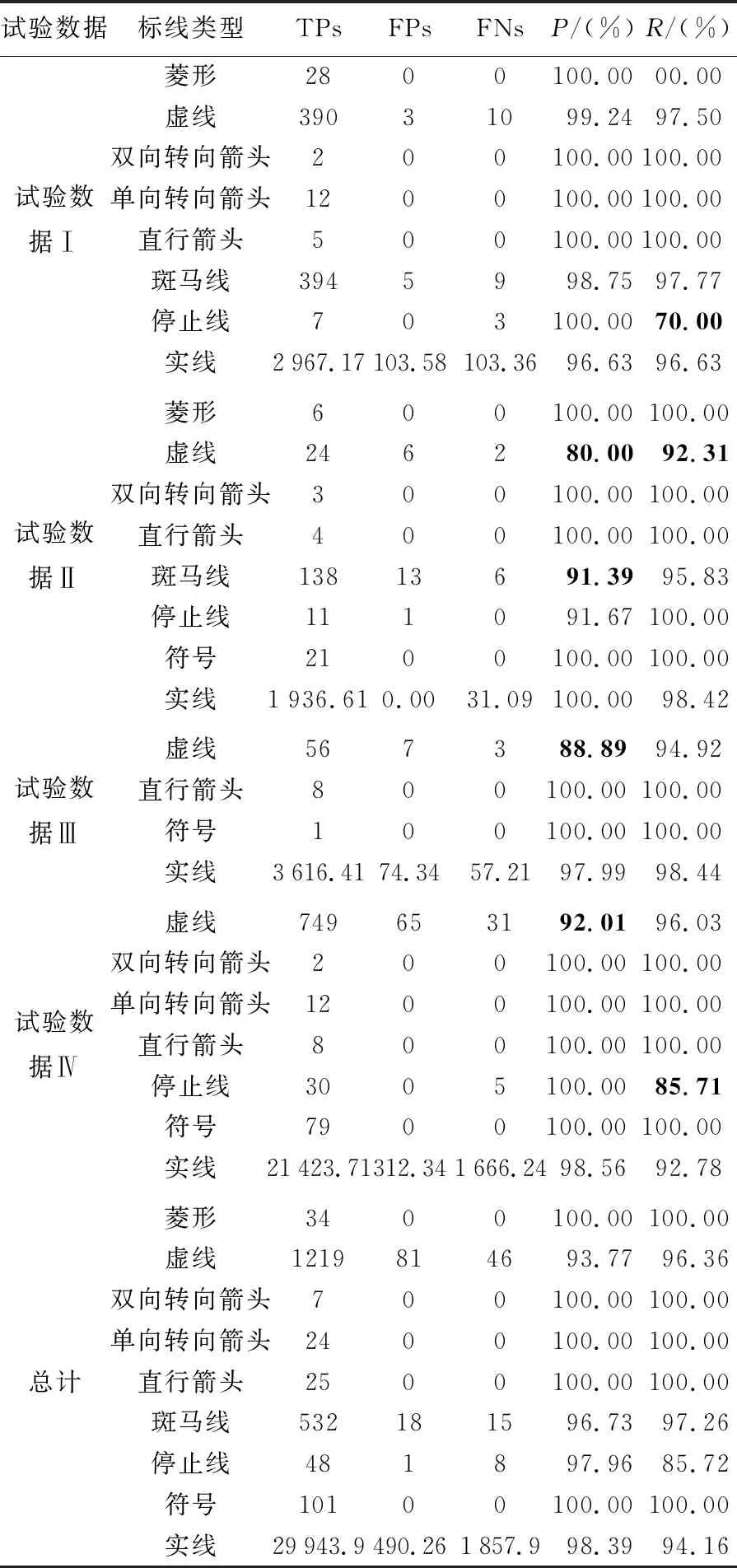
表3 交通标线分类结果精度Tab.3 Accuracy of road marking classification results
高速公路场景(试验数据Ⅲ和Ⅳ)中GAT_SCNet模型同样对具有显著形状差异的多类型箭头、符号的识别精度达到100%,并且试验数据Ⅲ中实线型的识别精度达97%以上,说明GAT_SCNet模型能克服数据中实线型标线形状的多样化。同时试验数据Ⅳ存在训练数据中没有的符号标线,GAT_SCNet模型依然保持高精度的识别效果,说明该模型对数据泛化能力较强,对场景的适应性较为稳健。但在高速公路场景中,存在部分强度属性成高亮被误提取为标线的噪声数据(如图8场景D),这些噪声数据被错分到与其属性特征、结构关系相似的虚线中,导致试验数据Ⅲ和Ⅳ的虚线型识别准确率相对较低。同时试验数据Ⅳ存在部分与实线型粘连且与道路方向呈垂直分布的线状标线(如图8场景E),本文将其归为停止线,此类标线由于欠分割被识别在实线型标线中导致停止线召回率较低。

图8 部分错误分类场景Fig.8 Some misclassification cases
为进一步验证本文提出的多头注意力机制的有效性,本文在深度图模型GAT_SCNet基础上消减不同注意力模型构建无注意力机制模型(modelno-GAT)、节点注意力机制模型(modelFNod)、纹理注意力机制模型(modelFGap)、空间语义注意力机制模型(modelFCon)、节点和纹理注意力机制模型(modelFNod+FGap)、节点和空间语义注意力机制模型(modelFNod+FCon)、纹理和空间语义注意力机制模型(modelFGap+FCon)等7个深度图模型进行消融试验。同时将本文方法与车载激光点云标线分类中取得较好效果的文献[15]、[16]和[11],以及在点云公开数据集中取得较好分类效果的模型:DGCNN[22]和GAPNet1进行分类结果对比分析。本文采用相同的训练数据和试验数据进行消融和对比试验模型的训练与验证,典型场景试验结果如图9所示,采用综合评价指标F1对9类标线进行分类精度分析(表4)
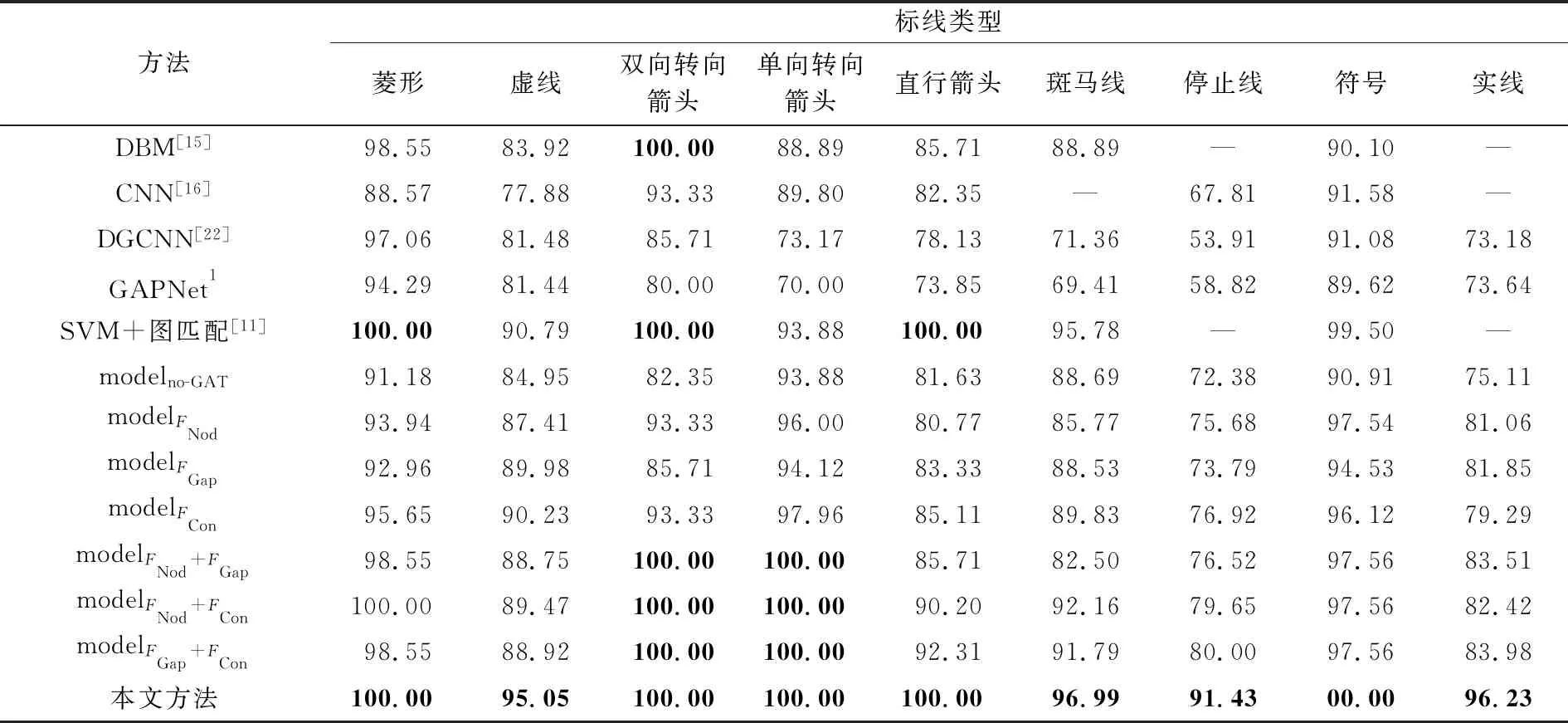
表4 消融试验与对比试验标线分类精度(F1)对比分析Tab.4 The comparison accuracy(F1) between different attention models (%)
(18)
通过表4和图9,本文对邻域图结构和不同注意力模块对标线分类精度的影响进行分开讨论:
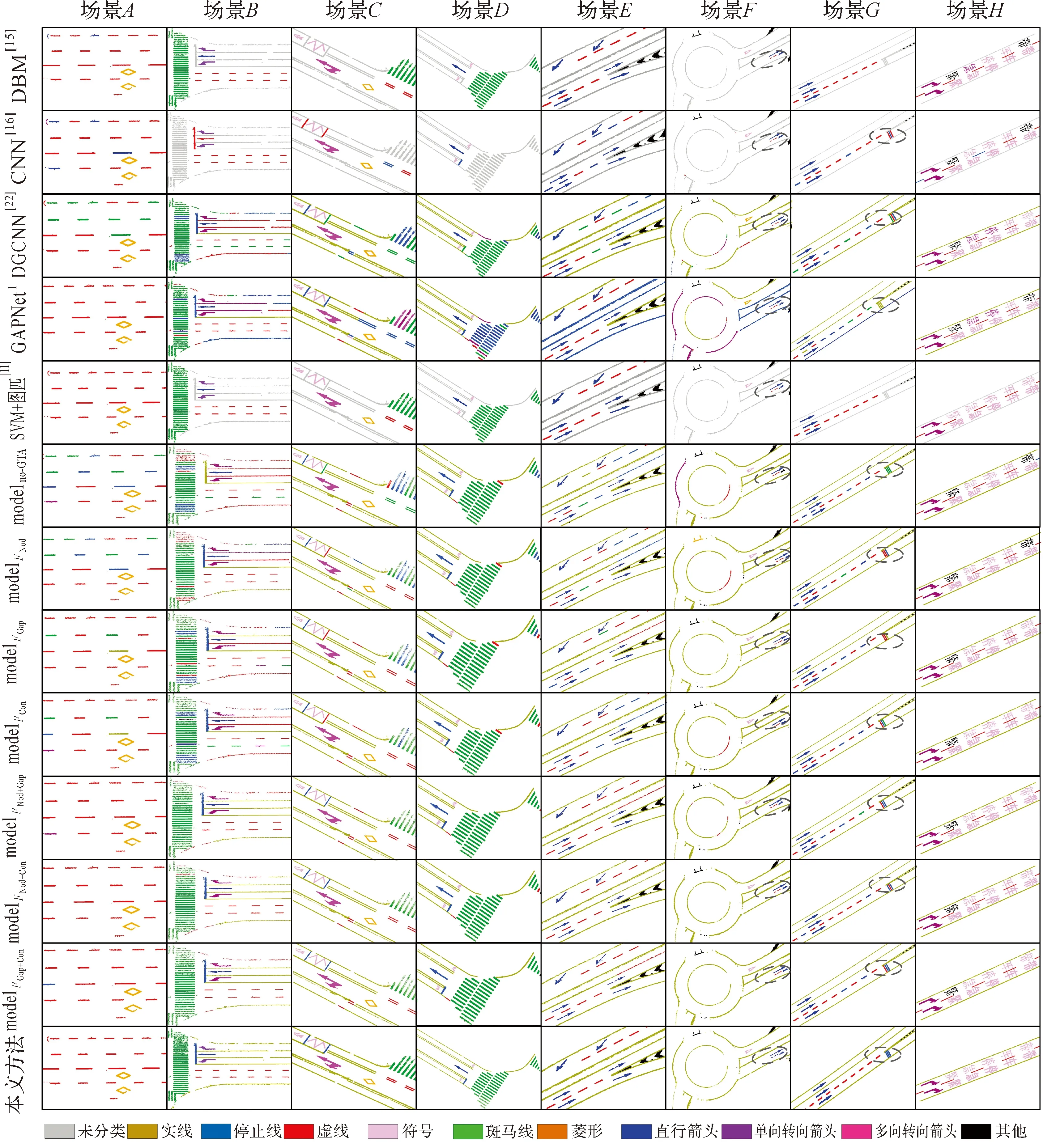
图9 本文方法和其他方法在典型场景中标线分类结果对比Fig.9 The comparison results between ours and some existing methods in typical scenes
(1) 邻域图结构对标线分类的影响。文献[15]用层次分类法将实线与停止线去除后利用DBM模型对小尺寸标线进行粗分类,基于空间语义信息利用阈值对虚线和斑马线进行精细区分。该方法对具有显著形状差异的菱形、双向转向箭头区分能力较强。由于该方法仅对虚线和斑马线进行精细区分,因此虚线与直行箭头(场景A)等相似目标仍然存在交叉错分,分类精度仅有85%左右。文献[16]将实线与斑马线剔除后,仅依靠独立标线的自身属性利用CNN模型进行小尺寸标线的识别。如可视化结果所示,该方法受标线分割、遮挡和磨损等因素影响严重,如形状不完整的直行箭头易被分类为虚线(场景B)、虚线与停止线(场景G)发生严重错分。而DGCNN模型和GAPNet模型虽然能够区分形状差异较大的非线性标线,但是对形状相似且具有多尺度的线性标线错分严重,导致模型分类总体识别精度很低。以上方法仅依靠标线自身属性特征,没有考虑邻居标线对识别的影响,导致相似标线的识别精度都普遍较低,通过与仅利用邻域图结构的modelno-GAT模型分类结果对比,发现斑马线(场景C)、实线(场景D)等形状相似标线的分类精度显著提高,从而证明邻域图结构在相似标线识别中的有效性。
通过对比modelno-GAT模型与利用了标线图结构的文献[11]方法的分类结果,可以发现虽然modelno-GAT模型总体分类精度与平均综合评价指标低于文献方法,但文献[11]方法的邻域图模板匹配策略仅用来精细区分虚线、斑马线与直行箭头,对实线型这种多尺寸、多类型、多空间结构的标线,模板定义与匹配都较为困难。并且文献[11]利用人工提取标线图结构的基础特征,对标线位置、结构和语义描述有限,降低了复杂场景中标线识别准确性,如过分割的直行箭头一部分被识别为虚线(场景F)。
(2) 注意力机制对标线分类的影响。相较于无注意力机制的modelno-GAT模型,节点注意力将邻域图结构中与中心对象特征更为相似的邻域对象赋予更大的权重,试验结果表明有节点注意力机制的modelFNod、modelFNod+Gap和modelFNod+Con对虚线(场景B和场景C)的识别较为稳定。纹理注意力通过学习邻域图结构的整体图结构属性辅助标线分类,从试验精度与结果中也可以看出modelFGap模型更利于实线型标线(场景F)的识别,融合了纹理注意力的modelFNod+Gap和modelFGap+Con模型对实线型的识别同样表现出较好的效果。空间语义注意力在邻域图结构的基础上基于位置属性对特征进行分解,以此促使模型更关注与中心对象空间排列更为相似的邻域标线,而试验结果表明仅用空间语义注意力机制的modelFCon模型对城市道路场景中的斑马线(场景D)识别较为稳定,融合空间语义注意力机制的modelFNod+Con和modelFGap+Con模型对斑马线的识别精度显著提高3%左右,说明该模块对此类标线的识别具有较强的稳定性。
(3) 综上分析,邻域图结构在标线识别过程中能够有效提升特征相似的线状标线分类精度,不同注意力模型对不同类型的标线均表现出较好的分类结果和模块稳定性。本文采用融合节点、纹理、空间语义的注意力机制的标线分类模型结合了3种注意力模型各自的优势,更好地刻画标线邻域对象间的结构关系,增强全局结构特征描述,达到了最佳的分类效果。
4 结 论
本文通过分析标线与邻接标线的几何、结构和语义关系,提出融合空间上下文信息的车载激光点云标线分类图注意力模型——GAT_SCNet。该模型对每一个标线构建一个可计算子图结构,通过构建多头注意力机制描述和提取标线间连接关系,并将此子图结构节点、边关系嵌入到图神经网络进行特征的自动学习,实现标线对象的精细分类。在分类结果基础上利用模板匹配和GVF Snake模型分别对非实线型和实线型标线进行矢量化。采用4份试验数据对GAT_SCNet标线分类模型进行精度验证,9类标线的准确率、召回率达93.77%和85.72%。相较于现有方法,本文将全尺寸标线分类统一到一个框架中,克服实线对非实线分类的影响,同时将标线间几何和依存关系统一利用图结构描述并融合多头注意力机制获取邻域图结构多尺度局部特征,提高形状相似标线的分类精度,解决复杂道路环境中因残缺、磨损、遮挡等导致的结构缺失标线的识别问题。目前本文方法仍然存在一定的缺陷,分类精度在一定程度上受到标线分割精度的影响,并且由于数据的限制很难涵盖同种标线的所有空间结构。在今后的研究中,将致力于实现一种“点到点”的深度学习模型,直接从增强后地面点云数据中识别多类型标线,并且引入迁移学习策略,从图像、机载雷达数据等其他数据源中构建标线的全类型图模板数据库,服务于车载激光点云交通标线分类。
