基于自适应三元组网络的细粒度图像检索算法
2021-10-27潘丽丽陈蓉玉雷前慧邵伟志黄诗祺
潘丽丽,陈蓉玉,雷前慧,邵伟志,黄诗祺
(中南林业科技大学 计算机与信息工程学院 湖南 长沙 410000)
0 引言
面向海量的图像数据,如何以最小的代价实现快速且精确的图像检索成为目前重要研究内容。传统的手工提取特征已经不能满足互联网时代高效且精确的检索需求,图像检索的研究趋向基于内容的图像检索。基于内容的图像检索通过对图像分析,采用不同算法得到的模型来提取图像的特征并存储在特征数据库,可节省大量人力,体现图像检索的智能性。由于卷积神经网络通过不断训练与学习后具有图像的局部感知能力与局部信息的融合能力,能提取图像信息更丰富的深层语义特征,被研究者应用于图像检索领域并取得了不错的成果。然而,每次拍摄同一件物品的图像背景都不能保证一成不变,数据图像的嘈杂背景会影响卷积神经网络的训练与学习,不利于提取出表征图像主体信息更强的深度特征;经典卷积神经网络提取出的深度特征维度过高,特征表征能力不强;传统分类模型特征存在判别能力不足的缺点,并不适用于图像检索领域。针对存在的问题,本文的研究工作主要从以下几个方面着手。
1)卷积神经网络学习的特征是由具体转向抽象,最终得到的模型在网络深层尽可能忽略图像背景而实现对图像目标主体的聚焦。本文通过预训练模型提取图像最深层的特征图,并利用特征图的色彩明亮程度对图像分割来解决图像噪音问题,提升图像检索的精度。
2)卷积神经网络提取高维深度特征会消耗大量的存储内存,降低了图像的检索效率。在网络中增加特征增强模块,来保证改进后的网络能充分学习图像的语义特征,提取出表征能力更强的深度特征,提高图像的检索精度。
3)经典卷积神经网络ResNet18 针对的是图像分类,其损失函数在图像检索领域并不能充分发挥网络对样本的学习,提取出适用于细粒度图像检索的深度特征。本文改进网络结构的同时也把损失函数替换为自适应三元组损失函数,使构建的网络模型能弥补传统分类模型特征判别能力不足的缺点,提取出更适用于图像检索的深度特征。
1 相关工作
基于内容的图像检索任务(content-based image retrieval,CBIR)长期以来一直是计算机视觉领域重要的研究课题。伴随着视觉图像的不断研究,许多传统的特征提取方法被广泛提出并应用[1-3],尽管这些方法提取的图像底层特征不具有自动学习能力,但因为其算法简单、复杂度低等优势在图形图像领域取得不错的成果。卷积神经网络的兴起改进,促进了视觉图像领域的快速发展。LeNet-5[4]网络为卷积神经网络应用于视觉图像奠定了基础。VGG[5]网络通过增加网络的深度与广度提升网络的学习能力实现低分类错误率,其较强的迁移学习能力被广泛应用于图形图像的特征提取,为后续网络的构建与改进提供桥梁。残差网络 ResNet[6]在加深网络的同时通过输入、输出之间的残差学习来减少梯度爆炸,提高网络的分类准确率。DenseNet[7]采用密集连接,实现特征重用,进一步提升准确率。卷积神经网络强大的自动学习能力能提取出图像信息更丰富的深层语义特征,被广泛应用于食材分类、目标检测[8]、场景识别[9]、医疗图像检索[10]等各个领域。
2 研究算法
为提取图像信息更丰富的表征特征,实现高检索精度和高检索效率,本文研究的整体框架如图1所示。首先使用深度卷积神经网络(deep convolutional neural networks,DCNN)预训练模型,依据深层特征图进行视觉显著性检测,实现图像分割;然后把无监督图像分割后的去噪图像输入卷积神经网络中进行训练,通过在网络中增加特征增强模块和自适应三元组损失函数提升网络的检索精度,同时使用深度哈希实现对特征的降维与编码,加速图像的检索效率。综上所述,本文研究主要从三个方面进行:特征增强模块的增加、视觉显著性检测与自适应三元组损失函数。

图1 整体框架图Figure 1 Overall frame diagram
2.1 特征增强模块
若对分类任务的ResNet18网络提取出的特征直接应用于图像检索任务,往往存在特征判别能力不足,会造成检索精度较低。为了让网络模型提取出的特征表征能力更强,本文提出在ResNet18网络中增加一个特征增强模块来获取表征性更强、更适用于图像检索任务的深度特征,特征增强模块框架如图2所示。
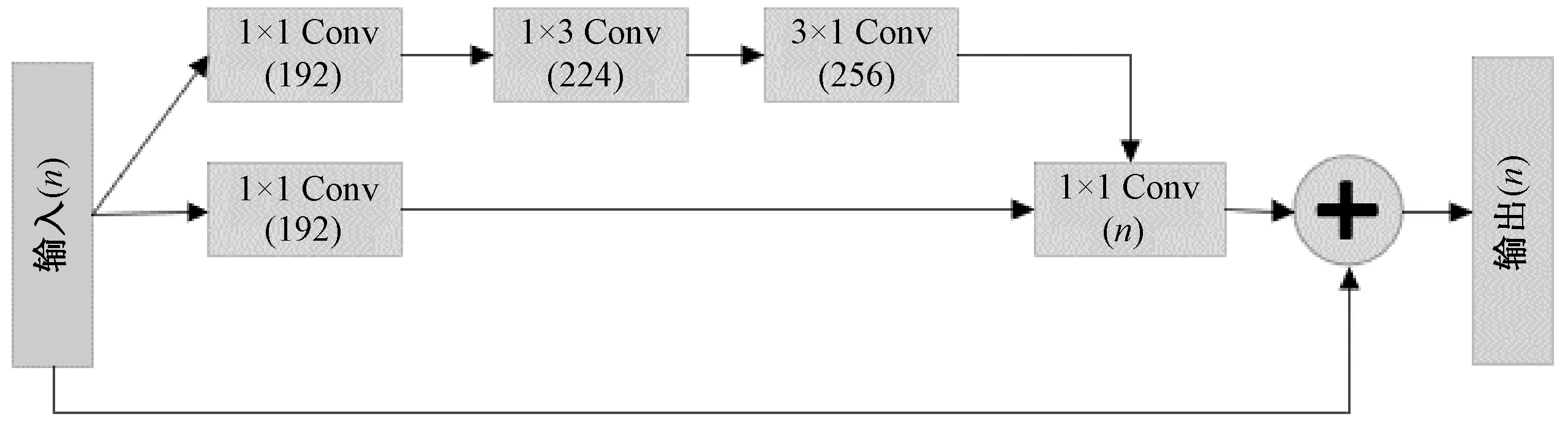
图2 特征增强模块Figure 2 The module of feature enhancement
“Inception-ResNet-V2”网络[19]采用跳远连接、残差模块、非线性映射以及多尺度特征融合等方法改善网络的性能,提升网络的分类准确率。受其启示,本文在ResNet18网络中最深层卷积层后添加“Inception-ResNet-C”模块来实现特征增强,提升网络的感知能力,提取出表达能力更强的特征。
ResNet18 网络添加特征增强模块主要有三个优势。
1)经典卷积神经网络通过添加一个模块增加网络的宽度与广度来保证提取出的深度特征具有多样性的同时,也会存在梯度消失问题。特征增强模块在加深网络深度的同时,左分支采用跳远连接解决网络梯度消失问题,提升网络的检索精度。
2)分支采用1×1卷积核可压缩特征的通道数,有效降低图像三维特征的维度,提取出表征性更强的语义特征,同时降低网络后续的计算成本。
3)3×1和1×3 卷积核的使用也能够加速网络的计算速度,增加网络的非线性映射。ResNet18网络增加一个特征增强模块,改进后网络(ResNet18-I)架构表包含卷积模块、输出尺寸及网络参数。
经典网络ResNet18由五个卷积模块构成,为改进网络训练模型时间消耗问题,本文在ResNet18基础上添加了图2所示的特征增强模块。添加特征增强模块后的ResNet18-I并不会大幅度增加网络的参数与训练时间、降低图像的检索效率。
2.2 视觉显著性检测
一般情况下,大部分图像都存在主体与背景同在,甚至部分图像背景所占比重高于主体目标。针对细粒度图像数据集,若背景比重过大,直接输入网络中进行训练与学习,会导致网络训练针对性不强,提取出的深度特征影响图像的检索精度。
经典卷积神经网络学习过程中,卷积通道中某一处数值的强弱就是对当前特征强弱的反应,通过对特征图的不断卷积与池化,可以将多个特征组合成一个特征,得到下一个特征图。网络层次越深,特征之间通过不断组合可获得的特征图就越复杂,其特征也更具代表性。由此可见,通过可视化的特征图对图像进行显著性检测,可实现图像目标主体分割,如图3所示。

图3 显著性检测Figure 3 The detection of significance
针对细粒度数据集图像尺寸不统一,本文首先对图像全部执行尺寸调整操作,让所有图像大小统一为299×299,因为分辨率高的图像有利于网络更好地学习图像的细节;其次,通过卷积神经网络的学习,浅层网络提取的是图像的纹理、细节等浅层特征,从可视化特征图中可以较清晰地看出图像中主体的轮廓,但是主体与背景图像颜色区别不大,不能进行有效视觉显著性检测;然后,通过卷积神经网络的深入学习,网络能忽略掉图像的背景图像,集中于目标主体的学习;最后一层8×8的可视化特征图中图像的主体与背景颜色对比鲜明,可以清晰地进行视觉显著性检测,定位出目标主体。
由可视化特征图可知,特征图颜色的明艳程度展示了目标主体的重要程度。针对颜色层次分明的特征图,设置不同的阈值α,得到目标图像的候选框也不一样。若阈值设定过大,目标图像则过小,将分割后得到的不完整目标图像输入卷积神经网络中就不能有效提升检索精度。目标图像过大,不能体现出视觉显著性检测的优势,以实现最佳的检索性能。当阈值α设定为合适数值时,能精准定位图像中的完整目标主体,提升图像的检索精度。
2.3 自适应三元组损失函数
经典卷积神经网络 ResNet18 在图像分类领域已取得不错的成果,但其损失函数并不适用于图像检索领域。
针对细粒度数据集,已有研究者使用三元组损失函数不断拉近同类样本间的距离,推远异类样本间的距离,得到辨识度更高的特征用于图像检索。三元组网络的输入是由锚示例(Anchor)、正示例(Positive)、负示例(Negative)组成的三元样本。网络训练过程中,以三元组之间的距离关系为先验知识,通过优化损失函数,不断调整样本间距离,实现锚示例与负示例的距离Dist(A,N)大于锚示例与正示例的距离Dist(A,P),并间隔相应的阈值(margin),三元组损失函数公式为
TripletLoss=Max[Dist(A,P)-Dist(A,N)+margin,0]。
(1)
经典三元组损失函数中margin是可设置的一个固定值,当Dist(A,N)<[Dist(A,P)+margin]时,损失值大于0,网络优化时会推远负示例,拉近正示例,使得Dist(A,N)>[Dist(A,P)+margin];然而,当Dist(A,N)>[Dist(A,P)+margin],损失值为0,已满足优化目标。此情况会导致网络后续无法有效优化,针对此问题,本文提出了自适应三元组损失函数,如公式(2)所示,并在损失函数中采用自适应阈值margin1,如公式(3)所示,激励网络在训练的过程中不断优化。
HardTripletLoss=1-Sigmoid[Dist(A,N)-Dist(A,P)-margin1],
(2)
margin1=Average[Dist(A,N)-Dist(A,P)]。
(3)
利用Sigmoid函数性质将[Dist(A,N)-Dist(A,P)]的差值映射在[0,1]之间,当激活值接近1时,得到的损失值也趋近0。也就是说,网络的优化目标是尽可能地使[Dist(A,N)-Dist(A,P)]的差值接近5。在此基础上,自适应三元组函数中采用训练样本中所有样本[Dist(A,N)-Dist(A,P)]的平均值作为自适应阈值,在合理范围内提高网络的优化目标,保证在绝大多数情况下目标优化都能够有效进行。此外,为解决三元组网络训练困难及训练样本过少导致的过拟合问题,本文提出了困难三元组样本挖掘算法,通过在一定排名比例范围内随机挑选样本来丰富三元组样本的多样性,提高网络的学习能力。如公式(4)所示,
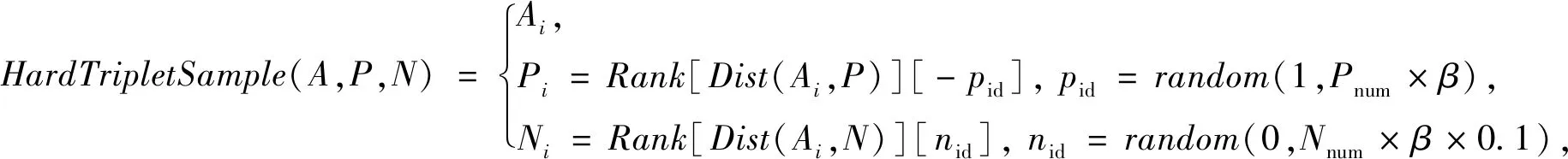
(4)
式中:Pnum表示同类样本的数量;Nnum表示异类样本的数量;β为困难因子,用于指定控制困难样本的选择范围;pid为依据困难因子随机抽取正示例的位置;nid为依据困难因子随机取负示例的位置。
3 实验结果及分析
所有的网络都是基于Tensorflow2.2版本实现。服务器内存为16 G,显存为11 G,配备NVIDIA GeForce RTX 2080显卡。本文首先使用十字交叉熵损失函数训练50轮得到预训练模型,然后冻结所有的网络层,设置哈希编码层后再训练90轮,每三轮生成困难三元组。
本文主要采用CUB200-2011和Stanford Dogs两个细粒度图像数据集进行检索,用准确率作为图像分类评价指标,并按照Yang等的方法进行数据集划分[20],采用平均精度值(mAP)作为图像检索精度的评价指标来验证本文所提出方法的有效性。
CUB200-2011数据集[21]是由加州理工学院在2010年提出的细粒度数据集,该数据集由200个鸟类构成,共有11 788张鸟类图像。Stanford Dogs 数据集由世界各地的120种狗的图像构成,共有20 580张图像数据。
3.1 分类准确率与mAP对比
本文首先对 ResNet18 与采用特征增强模块与自适应困难三元组损失函数(HardTripletLoss,记为Triplet)后改进的网络(ResNet18-I)在分类准确率与mAP指标上进行对比(表1)。
由图4可知,随着迭代轮次增加,ResNet18-I网络的检索精度逐步稳定上升并达到一个稳定值,且一直高于ResNet18的检索精度。图5中,Triplet伴随着迭代轮次的增加其示例间的距离也在不断增长,并有继续增长的趋势,说明训练效果一直有效。由表1可得,ResNet18在图像分类领域性能良好,图像分类准确率在CUB200-2011数据集上达到61.87%,然而此网络所提取的特征用于图像检索时,mAP低至40.65%。在Stanford Dogs数据集上,检索性能更差,检索精度只有38.26%。由此说明,ResNet18提取的特征尽管图像分类准确率良好,但并不适用于细粒度数据集的图像检索。当Triplet替换针对分类任务的损失函数时,CUB200-2011数据集上的检索精度提升约16%,Stanford Dogs数据集上的检索精度提升约21%。由此可见,采用Triplet网络对图像检索更有针对性,图像检索精度有较大提高。增加特征增强模块的ResNet18-I在分类准确率上没有明显变化,但其搭配Triplet后,在Stanford Dogs数据集上的检索精度高于ResNet18。检索精度的大幅提升,说明特征增强模块的添加让网络学习表征能力更强,更适用于图像检索的语义特征。
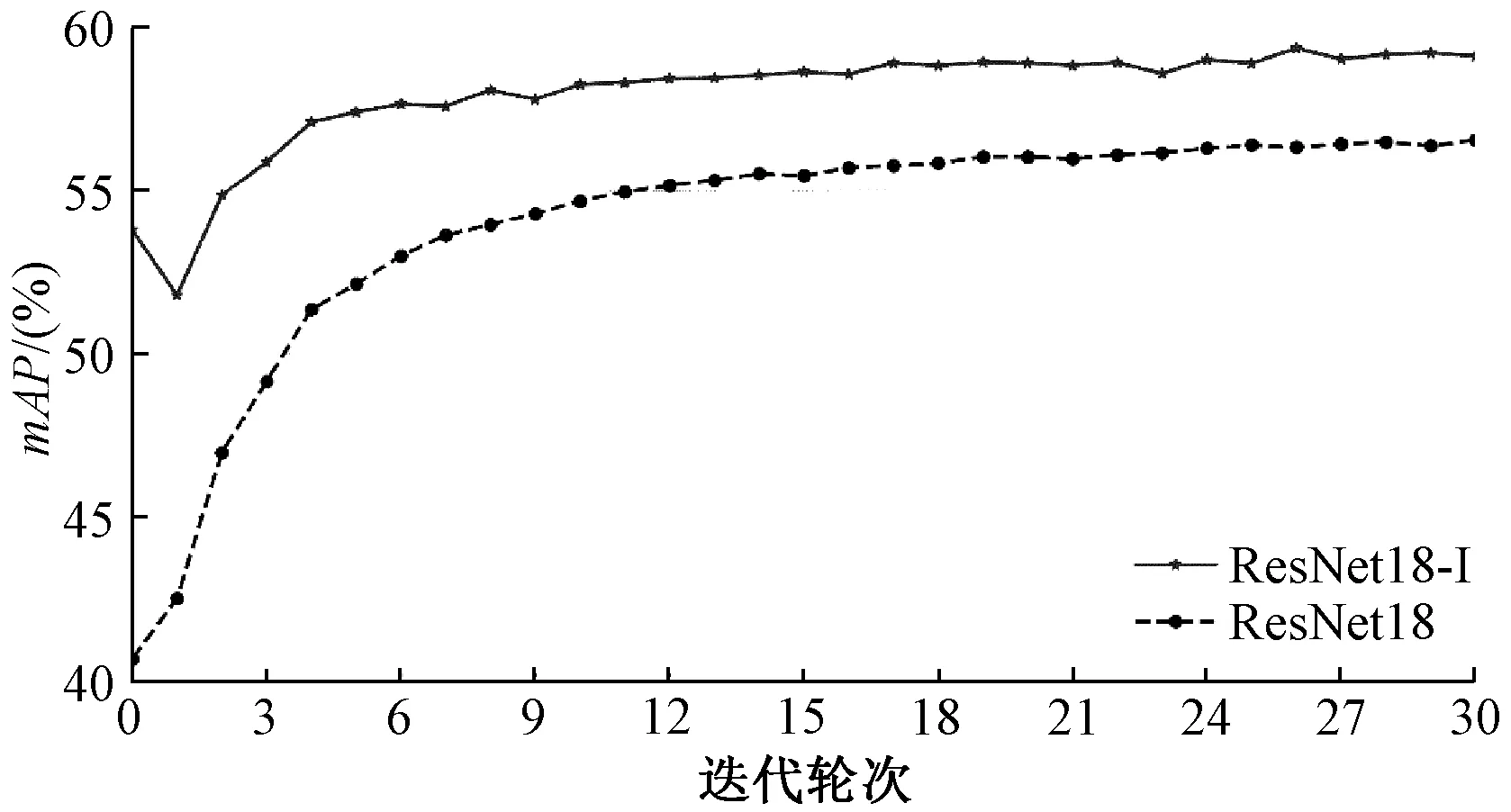
图4 不同迭代轮次mAP对比Figure 4 The comparison of mAP in iterative rounds
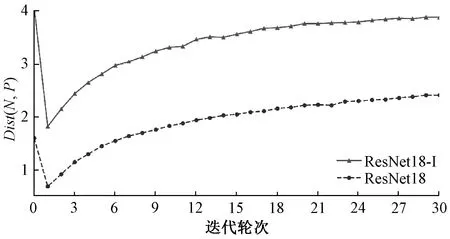
图5 不同迭代轮次距离对比Figure 5 The comparison of distance in iterative rounds

表1 ResNet18与ResNet18-I 分类准确率和mAP对比(64比特)Table 1 The comparison of classification accuracy and mAP between ResNet18 and Resnet18-I (64 bit)单位:%
3.2 显著性检测(α)mAP对比
可视化特征图可直观展现DCNN不同网络层次的特征提取能力。为实现快速且准确的目标定位,首先把可视化特征图转换为灰度图像,像素点值为0~255,然后设置不同的阈值(α),α值的大小表征着图像的明亮度,可选择合适的α来确定图像主体目标所在的像素点范围,实现分割。图像分割与未分割显著性检测对比结果如表2所示。

表2 CUB200-2011显著性检测结果对比(64比特)Table 2 The significant detection results of CUB200-2011 (64 bit)单位:%
由表2可以看出,对于CUB200-2011数据集,当阈值α=0.4时,保留像素点值位于(102,255)的显著性图像,实现图像主体的准确切割,分类准确率和Triplet的检索精度分别提升约7%,但此方法在Stanford Dogs数据集上显著性检测效果不明显。经过对比分割后的数据图像发现,CUB200-2011数据集中每张图片只存在一个主体目标,使用预训练模型进行显著性检测效果明显,而Stanford Dogs数据集每张图片除了目标主体后还存在其他干扰主体,如人、其他动物等。由于预训练模型并没有针对目标数据集进行训练,不能有效识别出每张图像中的目标主体,会存在误判情况,如图6所示。

图6 不同α值时显著性检测结果Figure 6 The detection results of significance with different α values
总而言之,在卷积神经网络图像输入前,用预训练模型对数据图像进行显著性检测的方法对一个目标主体图像能进行有效分割,去除背景噪音,网络也能更有针对性地学习出辨识度更高的深度特征,提升图像的检索精度。
3.3 细粒度图像数据集mAP对比
就CUB200-2011数据集和Stanford Dogs数据集而言,已经有研究采用多种算法提取图像的特征维度,为有效验证本文方法的优越性,本文特征提取维度与已有研究保持相同。
由图7可知,迭代次数为0表示没有使用三元组损失函数进行训练,网络检索精度低。随着网络训练过程中迭代轮次的增加,ResNet18-I的检索精度一直在稳步上升并趋于平缓,相比较于16、32、48 三个特征维度,64维的特征包含图像的信息最丰富,图像检索性能最好。

图7 Stanford Dogs 数据集不同维度下mAP对比Figure 7 The mAP comparison with different dimensions of Stanford Dogs dataset
如表3所示,深度特征的检索精度远高于底层特征,深度特征已经被广泛用于图像检索领域并取得不错成果。2019年Yang等[20]用ResNet18与三元组损失函数进行图像检索,在CUB200-2011数据集上,64维哈希特征检索精度达到62.33%,远高于其他特征提取的深度哈希特征。为验证本文方法,本文也基于ResNet18-I分别提取图像的16、32、48、64维特征,不同维度特征得到的检索精度在表3中用黑色加粗数字展示。从表3中黑色加粗数据可以看出,CUB200-2011数据集上不同维度检索精度都高于前人方法,特征维度为64时高达68.22%,比Yang等[20]提出的方法提升了约6%。同样地,在Stanford Dogs数据集上无论48维还是64维都提升了约2%,展示了本文提出方法在不同数据集上的有效性。综合所有的实验数据可以看出,目标定位、特征增强模块和自适应三元组损失函数针对细粒度图像检索是有效的,网络可学习代表性更强的特征,提升图像的检索效率与检索精度。
4 结论
针对细粒度图像检索,本文通过特征增强模块的放置、显著性特征图检测和Triplet的使用来提升图像的检索精度与检索效率。显著性特征图检测可实现对图像的主体目标定位,去除嘈杂的背景干扰,有利于网络学习目标主体更加精细的图像特征,充分发挥网络性能。特征增强模块、深度哈希和Triplet能使ResNet18-I网络学习代表性更强的语义特征,提取出来的语义特征更加具有针对性,更适用于图像检索领域。ResNet18-I 网络相比 ResNet18,不仅节省了图像特征的存储空间,加快检索效率,也提升了图像的检索精度。
