基于相关主题模型和多层知识表示的文本情感分析
2021-10-27马长林
马长林,王 涛
(1.华中师范大学 人工智能与智慧学习湖北省重点实验室 湖北 武汉 430079;2.华中师范大学 计算机学院 湖北 武汉 430079;3.国家语言资源监测与研究网络媒体中心 湖北 武汉 430079)
0 引言
文本情感分析隶属于计算语言学的范畴,广泛应用于机器学习、数据挖掘、深度学习、语义相似计算等多个研究领域[1-2]。文献[3-4]提出潜在评级回归(latent rating regression,LRR)模型,但这种方法缺乏对主题特征的相关关系和语义连贯性的考虑,特征的静态分割方式导致情感得分存在偏差。文献[5]提出稀疏特征编码模型,能较好地挖掘文本中的隐含信息。文献[6-7]采用支持向量机(support vector machine,SVM)来解决该类问题,但没有考虑主题和上下文的关系。文献[8]提出一种基于图连接的半监督情感检测方法,但是普适性不强,自然语言的复杂性导致其无法通过某些特定的词库来解决所有问题。文献[9]使用从文本中提取情感词典的方式进行情感分析,但该方法的计算复杂度较高。文献[10]对推特上的数据进行情感分析,但采用的推特数据需要考虑同一个人在不同时段的情感变化,难以对多维数据进行使用。文献[11]提出一种基于情感词典的情感分析框架。上述情感分析研究在进行文本特征提取时,大都是在主题之间相互独立的假设下实现的,尽管取得了一定的效果,但割裂了文本主题特征的相关关系,导致词的表示方式存在不足,而且对主题情感的评分过于依赖人工特征种子词的选择,研究人员必须非常熟悉情感评级领域才能设计出有效的特征。文献[12]提出相关主题模型 (correlated topic model,CTM),在考虑文本特征与特征间的关系时,很好地融合了特征与特征之间的相关性;文献[13]提出的基于CTM的观点挖掘算法也验证了该结论,但该方法采用机器学习的方法进行知识表示,无法解决词表示粒度稀疏的问题。
近年来,随着词的分布式表示技术[14-15]的发展,深度学习技术和预训练语言模型[16]得到了很大改进,研究人员摆脱了传统机器学习中词表示粒度稀疏的问题,在文本的主题情感评级任务中取得了不错的效果。文献[17]提出一种情感长短期记忆网络,但该研究中使用的词向量是固定的,无法分辨同一个词有多种含义的情况,而且在模型设计中没有考虑主题本身的意义这个先验信息,导致最后的情感监测存在一定的偏差。而预训练的语言模型嵌入 (embeddings from language model,ELMo)[16]能够很好地解决一词多义的问题,该模型采用了多组向量表示的形式,能够在训练过程中根据每个词的上下文对词义进行动态调整,从而更加适应于具体的任务。文献[18]提出一种多层体系结构表示方法,利用多层感知机对于特征情感进行提取,但对于文本的特征分割存在不足,而且在文本的句子级别表示上存在缺陷,所采用的组合矢量模型不能很好地捕获句子的位置信息。多层感知机抽取能力不强,无法抽取到隐含的更深层次的信息,且参数量大,优化上也是一个难点。针对该问题,双向长短期记忆 (bidirectional long short-term memory,BiLSTM)[19]能够对词与词之间的先后顺序进行建模,更好地捕捉句子的位置信息,对语境的考虑也更加充分,而且该模型使用参数共享的方式,减少了多层感知机需要优化的参数,降低了计算量。针对多层感知机抽取能力不足的问题,注意力机制[20]在抽取过程中会考虑每个词与全文的联系,而且对于句子表示向量采用的多头抽取方式比单纯的多层感知机抽取方式更加充分,在情感评分中对于句子中的隐含特征能够考虑得更全面,和多层感知机[21]相比,能更精准地抽取出最后的评分和文本中隐含的更深层次的信息。综合以上研究,本文将CTM和多层知识表示方法相结合开展文本情感分析研究,仿真实验结果验证了所提方法的有效性。
1 基于CTM的文本动态分割算法
LRR模型[3]采用文本分割算法对数据集进行特征分割,在给定每个特征的种子关键词基础上,采用卡方检验进行循环迭代,直到特征关键词集合收敛。该文本分割算法是一种静态分割方式,即对文本中的句子进行最大次数匹配,最后将其归为某一个主题,这种方法割裂了文本主题方面之间的相关关系,对语义信息的连贯性考虑不足,忽略了主题方面的潜在隐含信息,从而导致最终的情感挖掘结果产生很大的偏差。在文本处理中,由于语言表达的多样性,每个句子可能涉及不止一个主题特征。为此,本文提出一种基于CTM的文本动态分割算法,充分考虑主题间相关关系和表达语义因素,使用CTM对文本主题方面进行聚类,获取语料库主题之间以及主题与其下词语之间的相关关系矩阵,在此基础上构造后续情感分析多层知识表示模型的先验信息,并基于相关关系对文本进行特征分割。
对于给定的评论文本数据集D={d1,d2,…,d|D|},数据集D涵盖了k个主题特征T={t1,t2,…,tk},并且对于各个主题特征的描述中会包含个人的情感信息,这个情感信息最终会通过一个总体评分的形式体现出来,即对于每个文档di∈D都拥有一个总体情感评分Od。首先采用CTM对语料库进行主题特征的聚类处理,可以得到主题与主题之间的协方差矩阵P∈Rk×k,以及词与主题之间的关系矩阵M∈RV×k,其中V为语料库中词的个数;矩阵M中的元素Mij表示处理语料库后的词i属于主题j的概率。随后将数据集D分解成句子集S={s1,…,si,…,sM},句子si(i=1,…,M)所对应的特征向量可以表示为Ri=(Ri1,…,Rij,…,Rik),其中:Rij的取值只能为0或1,Rij=1表示句子si属于主题tj,Rij=0则表示句子si不属于主题tj。静态文本切割算法得到的特征向量Ri中只有一个分量的值为1,其余都为0,即文档中句子只能属于一个主题,这不符合文本表达的特性,实际中文本的表述往往是多个主题特征的交叉融合,描述一个句子时经常会涉及多个主题特征。针对该情况,本文提出的基于CTM的动态文本分割算法,得到的特征向量Ri中可以有多个分量的值不为0,表明一个句子可能属于多个主题。

2 文本情感分析的多层知识表示模型
多层知识表示模型的主要思想如下:首先采用ELMo模型训练词向量,并将文本分割产生的信息作为先验信息融入词表示中。将词向量信息和主题模型产生的特征信息合并后,使用BiLSTM模型表示句子信息,然后使用多头注意力机制对文本方面的评分进行抽取,得到文本中各个主题特征的情感得分。最后将各个主题特征的评分进行结合,得到对于文本的总体评分。
多层知识表示模型如图1所示,可分为词语编码层、句子表示层、特征提取层、结果获取层。其中,词语的编码表示分为以下两个部分。1)利用ELMo模型编码词语。随着词嵌入表示方式的流行,神经网络的建模方式改善了以往采用词袋模型表示词的局限性。然而,一词多义问题成为词嵌入表示无法解决的难题,限制了自然语言处理的发展,但这一难题随着上下文词表示模型ELMo的出现得到了解决。使用该模型训练出的词向量,每一个词都由神经网络输入的词向量和中间词向量联合表示,从而解决了一词多义的问题。2)利用CTM编码主题信息。采用基于CTM的文本主题动态分割算法,可以得到句子si属于k个主题特征的相关主题特征向量Ri=(Ri1,…,Rik)(i=1,…,M),Rij表示每个句子属于k个主题的相关关系概率值,还可以得到k个主题中每个主题下特征词与所属主题之间的相关关系矩阵。依据该矩阵,对句子集S={s1,…,si,…,sM}中句子si,列出k个主题特征与si所包含的L个单词的相关关系矩阵G,维度为k×L,将以上相关关系值融入词表示中,作为文本主题先验信息,对后续的信息抽取起到很好的优化效果。
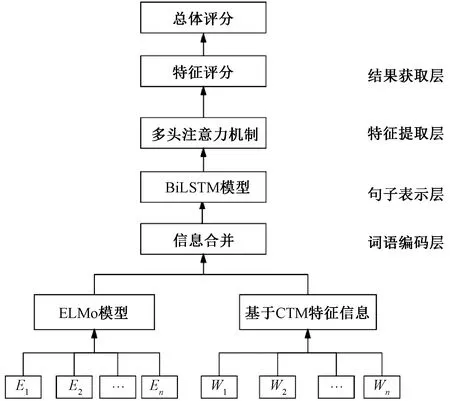
图1 多层知识表示模型Figure 1 A multi-layer knowledge representation model
主题先验信息的构造方法为:Qi=Ri×G,其中Qi表示句子si的主题先验信息向量,维度为1×L。将该向量与词向量相互融合,可以更好地对不同主题的句子进行区分。在得到文本的词表示后,需要对句子进行表示。作为比词更加抽象的一种表达方式,表达句子的方式有很多,例如组合矢量模型、doc2vec、RNN、GRU、BiLSTM等。在考虑实际效果和应用需求的情况下,采用BiLSTM作为句子的表示方法。该方法的优势在于对句子进行表示时能够充分考虑词出现的先后顺序,将每个词的前后信息都考虑进来,更好地捕捉句子的位置信息,对语境的考虑也更加充分,对于文本这种数据来说是一种比较合适的建模方式。
进行文本句子表示后,需要从句子表示中抽取文本的主题方面评分,而句子作为一个整体,如何从句子向量中抽取想要的信息则成了需要解决的问题。谷歌提出的注意力机制使用多头抽取考虑全局的方式,可以很好地发现文本中隐含的信息,能够抽取更全面的文本信息。通过多头注意力机制对文本信息进行抽取后,采用两层前馈神经网络的方式对文本主题情感得分进行获取,可以得到各个主题特征的评分,之后基于文本表述的特点,可知文本的总体评分是由各个主题特征得分综合确定的。因此,在主题情感得分的基础上,再次采用一层前馈神经网络进行建模,从而得到了文本的总体情感评分。
3 仿真实验
实验开发环境为R语言,采用文献[3]中数据集,该数据集提供了关于酒店的七个主题方面的评分,分别是价格、房间、位置、清洁程度、入住/前台、日常服务、商业服务。数据集中爬取了1 850个酒店的信息以及对应的246 399条评论数据,含有以上七个主题的情感得分以及相应文本对应的总体得分,每个主题以及总体得分的范围是1~5分。然而,由于网络数据的不规范性,在这七个主题中,入住/前台和商业服务这两个主题的得分非常不完整。为了正确评估实验效果,采取文献[3]中方法,去除不完整主题的信息,只选取价格、房间、位置、清洁程度和日常服务这五个主题作为评估标准。首先选取一段评论文本:
“Like Grandma′s house with Victorian overtones.This small hotel is one we have been to several times now and it feels almost like home.It is more comfortable and familiar than up-to-date and trendy.A little like going to Grandma′s house,with Victorian overtones,and the capacity to accommodate all your family and friends and be there for all your needs,including the warmth that goes with it.The breakfast that is available in the hotel is certainly adequate and right there when you need it.The location is great for doing a little roaming around in the historic and sports districts and the parking is very convenient and reasonably priced.I would certainly go again.”
该文本的第1句是总体评价,对其余六个句子,从价格、房间、位置、清洁程度和日常服务五个主题,分别采用文献[3]中Bootstrap-based静态文本分割算法和本文算法进行主题分割,文本分割结果对比见表1。可以看出,Bootstrap-based算法存在句子包含的词不属于任何主题特征的情况,导致某些句子无法进行特征匹配,同时,对于一个句子包含多个主题的情形也无法进行匹配。例如文本第5句话,Bootstrap-based算法将该句话归为主题1,但是从原文来看,该句子描述了两个主题,显然在这种情况下本文算法的结果更好。

表1 两种算法的文本分割结果对比Table 1 Comparison of text segmentation results between the two algorithms
下面对文本情感分析效果进行实验仿真对比。作为神经网络需要优化的目标,本研究是获取文本主题各个方面的情感得分,故采用了交叉熵损失函数。另外,因为使用了文本的总体评分信息,所以在损失函数中也考虑了总体评分的信息,具体的损失函数可以表示为
其中:N为文本的个数;α为超参数,表示文本的主题情感得分在优化中需要占据的比重;t为真实的主题情感得分;y为利用模型预测出来的主题情感得分;c和x分别为真实的文本总体情感得分和预测的情感得分;λ为超参数,这里采用的是L2正则;θ表示模型中出现的参数。在实验中,采取深度学习中常用的Adam优化器,它是一种改良的基于反向传播的梯度优化器,学习率为1×10-5,两个衰减率参数分别设置为0.9与0.99。实验环境为Ubuntu16.04,神经网络框架为keras,后端采用的是tensorflow,keras是对tensorflow更上层的一种封装,相较于直接用tensorflow来编程,keras使用起来更加方便。对于输入的ELMo词向量,使用tensorflow_hub(https:∥tfhub.dev/google/elmo/2)提供的开源实现,因为里面已经加载了预训练好的词向量,所以为了降低计算量,将ELMo词向量的trainable参数设置为False,表示该层不可训练。对于使用BiLSTM结构进行的句子表示,将输出向量的维度设置为256。对于多头注意力机制,设置头的个数为16。实验中将数据划分为五份,其中四份用于训练,一份进行测试;在训练集中选取了10 000条数据,用作验证集。超参数α的取值从0到1,步长为0.1。通过实验发现,当α设置为0.8时,在测试集上效果最好。
采用文献[3]中评价方法,从以下三个指标进行评估。1)根均方误差Δa。该指标的目的是评估预测的主题情感得分和实际结果的欧氏距离,这项指标的值越低越好。2)单条数据的相关关系Pa。该指标是利用皮尔逊相关系数来计算真实主题情感向量与预测向量之间的相关关系,可以反映出对于主题情感预测的相关性,这项指标的值越高越好。3)整篇文档的比较Pr。该指标对整个文档的各主题情感向量计算皮尔逊相关系数,在具体的对比中将整个文档定义为关于一个酒店的所有评论,这项指标的值越高越好。
本文模型与LRR[3]、LRNN-ASR[22]和Full-LRNN-ASR[18]模型进行对比,其中LRR是基于词袋模型,属于机器学习方法;其他两种模型使用神经网络建模,在词的表示上均使用传统的词向量,属于深度学习方法。不同模型情感分析结果对比如表2所示。可以看出,对于主题级情感分析,使用词袋模型的效果最差。对比评论准确性指标Δa,本文模型的效果最佳,这说明了使用多头自注意力机制对于抽取文本信息的有效性;对比横向指标Pa,本文模型的得分趋势和真实的得分趋势相关性最强,说明和真实情况最为吻合;对比纵向指标Pr,本文模型的提升效果明显,这说明本文模型能够有效地学习到评论的整体信息。
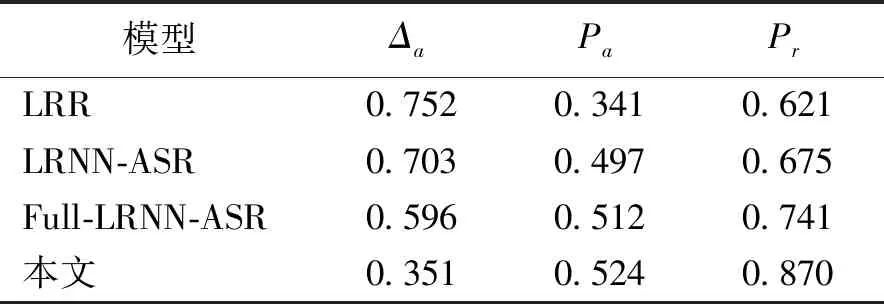
表2 不同模型情感分析结果对比Table 2 Comparison of sentiment analysis results of different models
整体来看,本文提出的方法对于获取主题级情感得分是一种比较有效的方式,在酒店领域的评论数据集上可以较好地获取各个主题的情感信息,这对于用户和商家具有重要的指导意义。
4 结论
本文的情感分析模型将文本隐含的相关关系融入多层知识表示模型中,采用CTM对文本进行主题特征动态分割,并构造主题先验信息输入预训练语言模型;利用预训练的ELMo模型进行文本词的动态表示以解决一词多义的情况;使用BiLSTM模型对文本句子进行表示,更好地捕捉句子的位置信息,在对句子表示向量进行信息抽取时融入注意力机制,可以抽取更全面的文本信息。
