基于赛灵思XC7Z020 的神经网络加速算法设计
2021-10-23刘天洋杨雨薇殷世杰孙越强赵永辉
刘天洋,杨雨薇,殷世杰,孙越强,赵永辉
(东北林业大学信息与计算机工程学院,黑龙江哈尔滨,150040)
0 引言
在人工智能技术的迅猛发展下,神经网络算法在诸多方面得到广泛应用。受困于神经网络中巨大的乘累加计算,在CPU 上运行处理神经网络算法的计算效率低、运行时间长,当前已不是主流的算力执行器。目前,常见的神经网络硬件加速实验平台有GPU、FPGA、ASIC。对比GPU 拥有成熟的加速方案但价格相对略高以及ASIC 平台的低功耗高性能但研发周期较长的特点,利用FPGA 加速是一个折中的方案,其具有可配置、低功耗、高性能的优点,适合进行硬件加速的研究。但目前绝大多数的神经网络算法都是自上而下进行设计,网络架构一般十分紧凑,其架构也因此而很难移植到FPGA 等硬件设备上,故本文以SkyNet 为代表的自下而上的网络架构进行优化研究,该网络架构具有可移植性好、硬件亲和度高等优点,适合移动端深度神将网络硬件加速[1]。
1 整体设计
1.1 整体架构
深度神将网络由于其网络体积的庞大,因而难以被部署到极其有限的计算和内存资源的嵌入式系统中,为满足计算实时性的需求以及资源利用最大化,本文提出以下加速器的整体架构,如图1 所示。其中,异构集成芯片中的ARM 处理器命名为PS 端,主要负责计算任务的调度与控制,包括图像的预处理、计算边界框、输入输出图像等操作;FPGA 部分命名为PL 端,主要负责计算数据,包括计算模块间的数据传输,存储特征图、权重等数据,数据量化等操作。
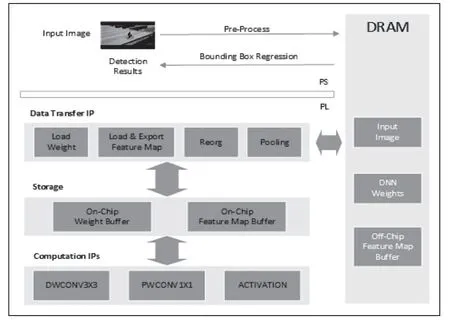
图1 软硬件协同加速框架
1.2 量化方案
一般的浮点型神经网络模型在进行计算推理时往往需要占用大量的计算资源,所以如果直接使用此类神经网络模型在硬件平台上进行推理计算,往往并不能得到预期的加速效果,因此本文采用将浮点数量化为定点数的方法对模型进行数据量化。在保证精度的前提下,使用8 位整型量化可大幅缩减数据量,从而有效解决硬件平台资源受限所导致的算力不足的问题。以浮点数W 和A 进行卷积计算为例说明数据量化的主要原理:
由线性量化公式:
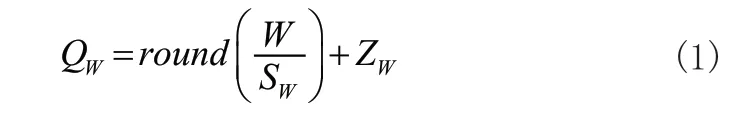
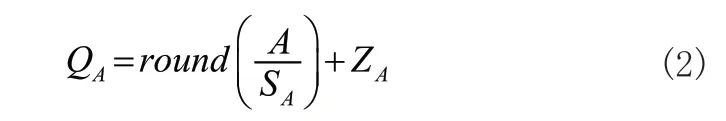
其中,SW,SA为缩放系数,ZW,ZA为偏置项,round()为按照指定的小数位数进行四舍五入运算,进而有:
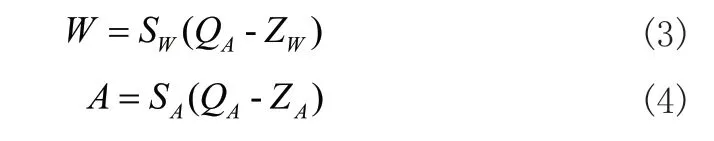
其中,QW,QA均为整型变量,W,A,SW,SA均为浮点型变量,对其进行卷积计算有:
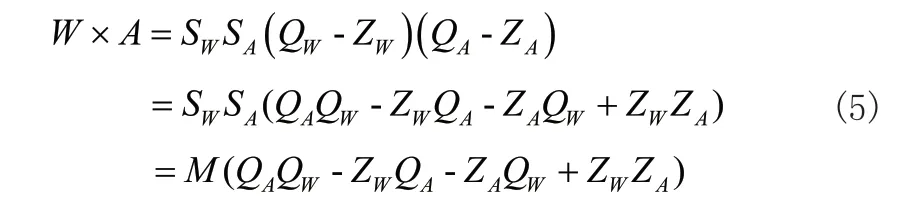
通过上式的结果可以观察到Z 项在计算过程中多次出现,而由于在硬件计算中,类似Z 项的变量需要到寄存器中反复读取数据从而进行计算,因而对于降低整个计算流程的延时性而言十分不友好,故可令Z=0,因而有:
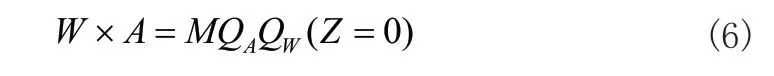
进一步将变量M 转化为2 的幂指数形式以方便硬件进行移位计算:
值得注意的是,我们看到由于 SWSA乘积结果或者说是QM一个常数,因此我们可以将其放到CPU 中进行计算以减少FPGA 计算资源负担,并且最终得到量化后的结果有:
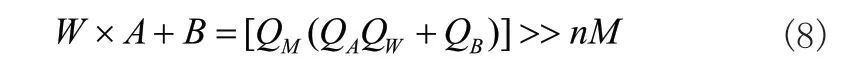
其中,QW,QA,QM,QB均为整型变量,W,A,B,M均为浮点型变量。
2 FPGA 高并行度加速计算方案
从算法角度讲,卷积层的向前计算过程为一个6 层嵌套循环,只在循环的最内层进行乘累加运算。这六层循环之间没有依赖,其顺序可以任意调换。而硬件加速卷积层计算的基本原理就是,将某些循环部分展开后移至最内层,用多套乘累加电路进行并行计算,而剩余的循环依然在外层保持紧凑的嵌套结构,分时复用内层的计算电路。因此,并行度类型和大小的选择,将很大程度决定加速器的峰值算力、硬件利用率、逻辑复杂度、片上缓存设计以及最终性能。
2.1 乘累加运算
假设Fin 数组存储在一个BRAM 中,BRAM 有两个读端口和一个写端口,因此,可以在一个循环中执行两个读操作,但只能在两个周期内顺序进行写操作,有一些方法可以在一个循环中执行这两个语句,例如,可以将所有的Fin 数组的值存储在独立寄存器中,每个周期都可以对每个寄存器进行读写。这个循环每次迭代执行一次乘法和一次加法操作,每次迭代执行一次从数组Fin[][][]和数组W[][][][]进行读操作,并将这两个值相乘的结果累加到变量Fout 中。加、乘操作在for 循环中是独立的,加法操作取决于它是如何实现的,可能取决于前一次迭代运算的结果,但是,可以展开这个循环并删除此迭代运算的依赖关系,如代码1 所示。

2.2 并行度
在代码1 中每一次乘累加运算都存在以下四个操作:1)Fin[][][]中加载指定数据;2)W[][][]中加载指定数据;3)上述两个数组相乘;4)将相乘的结果累加到Fout[][][]中。其中读操作需要两个时钟周期,这是因为第一个时钟周期提供内存地址,第二个时钟周期完成数据传递,由于这两个操作之间没有依赖关系,所以可以并行执行。乘法操作可以从第2 个周期开始;假设它花费三个周期才能完成,即完成时是第4 个时钟周期,在第4 个周期,加法操作开始并且能够完成,因此一次循环需要4 个时钟周期才能完成[2]。
最后,可以通过拆分输入、输出的特征图以及卷积核等行为,将所有放在数组中的每个元素分解到它自己的寄存器中,最终形成触发器内存,但这需要根据数组的实际大小合理拆分,避免消耗过多硬件资源。
3 实验结果
3.1 实验环境
为了验证算法结构以及DNN 加速器架构的设计合理性,采用Xilinx 的XC7Z020 芯片进行实验验证,片上资源虽然不是特别丰富,但仍可基本满足实验要求。仿真环境为Xilinx 公司提供的集成开发环境Vivado 2018.3 及Vivado HLS 2018.3。
3.2 实验分析
在100MHz 的时钟频率下,PL 端的资源利用率如表1所示。从设计结果的各个资源利用率来看,DSP 的资源利用率为100%,触发器的资源利用率接近50%,但LUT 资源接近90%,该资源利用率表明此深度神经网络加速器虽然充分利用了计算资源,但设计还需改进以降低LUT 的资源利用率,以期不需要过多的逻辑资源实现加速器的完整功能,为片上部署其他加速算法和实现用户自定义接口保留充足的逻辑资源和片上存储资源。上述设计的硬件加速器模块通过Vivado综合后实现后,功耗为2.955W,其中动态功耗为2.75W,静态功耗为0.205W。整个计算过程中,CPU 同步调动DNN 加速器,处理1000 张320*160 的RGB 图像平均需要303.06s。
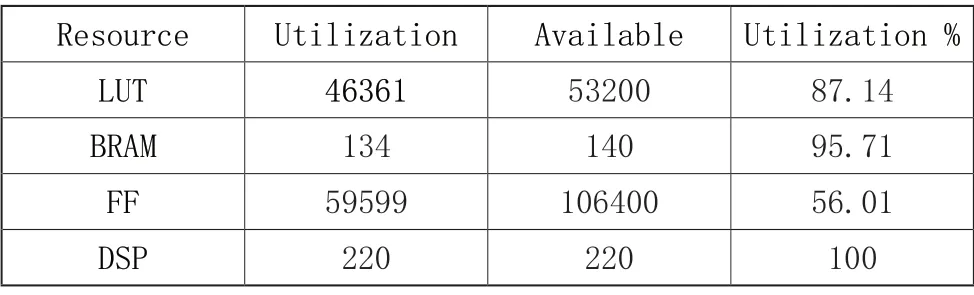
表1 PL 端的资源利用率
4 结论
本文深入分析卷积运算的原理以及在FPGA 中部署神经网络需要进行的代码修缮,在较高的硬件资源利用率的情况下,实现了一种深度神经网络加速器,同时对并行度流水化以及数据类型方面进行了优化,在一定程度上满足了低时延、低功耗的要求,可以满足受限平台的目标检测任务,同时Xilinx 的XC7Z020 芯片较其他现今的绝大多数硬件加速平台具有较为实惠的价格,更适合嵌入式部署。下一步将进一步优化硬件资源的利用,调整神经网络架构,提高资源利用率,从而进一步提升性能。
