基于无人机可见光和LiDAR数据的单木树种识别
2021-10-21李华玉徐志扬刘浩栋白明雄陈永富
李华玉 张 超 陈 巧 王 娟 彭 希,3 徐志扬,4 刘浩栋 白明雄 陈永富
(1. 西南林业大学林学院,云南 昆明 650233;2. 中国林业科学研究院资源信息研究所,国家林业和草原局林业遥感与信息技术重点实验室,北京 100091;3. 四川农业大学林学院,四川 成都 611130;4. 国家林业和草原局华东调查规划设计院,浙江 杭州 310019)
森林类型/树种(组)的精准识别是森林参数提取和计算的前提,是林业遥感领域的重要研究方向,对于森林生态系统和生物多样性的宏观监测具有深远意义[1-2]。传统的森林类型/树种(组)识别主要依靠地面调查手段,根据林木的根、茎、叶、花、果等外部形态特征识别和鉴定树种。这种方法虽然相对准确,但野外调查成本高工作量大,很难在短时间内实现宏观尺度的树种识别[3]。遥感技术的发展为树种识别提供了更为方便的数据源,但高分辨率卫星遥感影像获取困难、时效性较差,且易受外界环境因素的干扰,开源卫星数据针对精确至树种层面的分类空间分辨率仍不够高。近年来,无人机作为一种新兴遥感平台,可搭载可见光、多光谱和激光雷达等传感器,具有灵活、高效、便捷的特点,且获取影像过程中受大气因素的干扰较小,在小区域遥感应用方面前景较好[4]。利用无人机进行数据获取为提取树种空间信息提供了新的手段,准确快速提取树种信息的技术则是无人机在林业应用发挥作用的关键。
从大多数研究看来,高分辨率无人机影像为树种识别提供丰富的纹理信息,是应用较多的一种数据源。Chenari等[5]应用无人机可见光数据对伊朗法尔斯省一个开阔林地中的2个树种进行了分类研究,总体精度达90%。滕文秀等[6]使用无人机可见光影像数据通过深度迁移学习的方法对江苏省东台林场中的4个树种进行了分类,精度达96%。此外,利用无人机搭载高光谱、多光谱和激光雷达传感器获得地表森林植被的高空间分辨率、高光谱分辨率的影像,为实现森林类型/树种(组)的识别提供了更丰富的光谱信息和空间结构信息。Valderrama-Landeros等[7]利用多光谱数据对墨西哥太平洋沿岸的红树林区域进行分类识别,并进一步对红树林的不同健康状况进行了分析,为红树林的保护提供了一定的参考。相比光学遥感,激光雷达穿透性较强,生成密集的三维点云数据,能够提供与单木结构、冠层高度模型及森林垂直结构等相关的特征,在单木水平上,复杂的几何特征有助于树种分类识别。陈向宇等[8]充分利用LiDAR点云数据提供的单木结构、纹理特征和冠型结构特征,按照不同的组合方式对5个森林树种进行识别,精度达85%。不同遥感数据既可以单独用来进行森林树种识别,也可通过多源优势互补,辅助结合应用,以提高树种分类识别的精度。Matsuki等[9]在对日本的森林进行分类时,通过结合光谱信息和LiDAR数据的冠层结构特征,对16种森林树种的分类精度达82%。多源数据结合后相应的特征维度就会增加,过多的特征会对精度造成影响,因此需要从包含丰富信息的诸多特征中选择信息量大且冗余度低的特征进行树种识别,张大力[10]的研究表明经过随机森林特征筛选之后的分类识别精度明显提高。除了数据源和特征之外,树种识别另一个关键是分类器的选择,传统的最大似然法、决策树属于传统的需要进行参数优化的分类器,而非参数化分类器如随机森林(RF)、支持向量机(SVM)等则不需要假设数据符合正态分布,有利于将光谱、非光谱等特征数据纳入分类过程来提高精度[11]。Dalponte等[12]通过结合高光谱数据和LiDAR数据识别复杂森林地区树种并证明支持向量机(SVM)分类器对多源数据分类结果的准确性。林志玮等[13]基于无人机搭载光学相机获取的影像,采用随机森林算法建立植被识别模型。
因此,利用无人机平台的优势,获取多源数据进行森林参数提取和树种的识别是目前林业遥感领域的一大热点,但大部分研究采用的数据源较为单一或者在对特征选择和筛选组合方面的研究较少。为研究不同数据源和不同特征组合对树种识别精度的影响,本研究基于无人机可见光和LiDAR数据,结合特征筛选方法,采用随机森林和支持向量机进行树种分类,旨在为今后无人机在森林类型/树种(组)的识别中提供一定参考。
1 研究区概况
研究区为中国林业科学研究院亚热带林业实验中心年珠实验林场,位于江西省新余市分宜县西南部(114°30′~114°45′E,27°30′~27°45′N)。年平均气温16.8℃,年降雨量1 950.9 mm,主要集中在3—6月,年珠林场属低山丘陵地貌,海拔高度220~1 092 m,母岩以千枚岩为主,土壤类型多为黄红壤。主要植被类型为常绿阔叶林、落叶阔叶林、混交林(杉阔、杉竹、杉竹阔混交等)及灌丛(丘陵灌丛与山顶灌丛),主要树种有杉木(Cunninghamia lanceolata)、马尾松(Pinus massoniana)、鹅掌楸(Liriodendron chinense)、桤木(Alnus cremastogyne)等人工林树种,山矾(Symplocos sumuntia)、毛竹(Phyllostachys heterocycla)、木荷(Schima superba)、丝栗栲(Castanopsis fargesii)、刨花楠(Machilus pauhoi)等天然次生林树种。
2 材料与方法
2.1 数据来源
无人机影像数据由数字绿土公司GV2000无人机搭载可见光传感器和激光雷达传感器获取。可见光传感器为Sony ILCE-6000,有效像素2 430万。影像获取时以地面为基准,设置相对高度160 m,飞行速度为6 m/s,平均航向重叠率为83.2%,获取的可见光影像分辨率为0.05 m。LiDAR传感器为RIEGL VUX-1LR,通过近红外激光束和快速扫描实现数据的高速获取,波长1 550 nm,激光离散束角0.5 mrad,激光脉冲发射频率820 kHz,视场角330°,垂直精度15 mm,获得的LiDAR数据点云密度234 pts/m2。将获取的可见光单幅影像利用Limapper软件进行预处理,使用自动空中三角测量和光束平差法原理自动提取影像特征点,计算正确的位置参数,经过几何校正、正射校正后自动拼接成一幅影像,数据坐标系统为WGS-84,采用UTM投影。
样地数据在无人机飞行区域内树种丰富的区域选取100 m×100 m样地,郁闭度0.7,进行每木检尺,记录树种名称、胸径、树高、冠幅等信息,具体信息见表1。通过罗盘定位皮尺拉距离记录每木相对位置,同时选取样地内在影像上较为明显的单木和样地空旷区域的地物点作为控制点定位。

表1 样地信息统计Table 1 Information statistics of sample plot
2.2 数据预处理
对获取的可见光数据以LiDAR数据为基准进行几何校正,LiDAR数据预处理包括:1)去除空中噪点,提高数据质量;2)从点云数据中分离地面点;3)基于地面点生成数字高程模型(DEM);4)利用DEM对点云进行归一化,将原始LiDAR点云的高程值减去其对应地面的DEM值,去除地形影响,使得点云能呈现地物真实形态;5)利用首次回波插值生成的数字表面模型(DSM)与DEM差值生成冠层高度模型(CHM)。由于CHM生成过程中因个别栅格的高度值小于周围相邻像元现象明显而产生灰色或者黑色的空洞,会使树冠区域变得不连续,导致LiDAR变量提取不准确,因此需要对CHM进行优化,研究采用Ben-Arie等[14]提出的平滑滤波方法进行空洞填充,优化前后的CHM见图1。
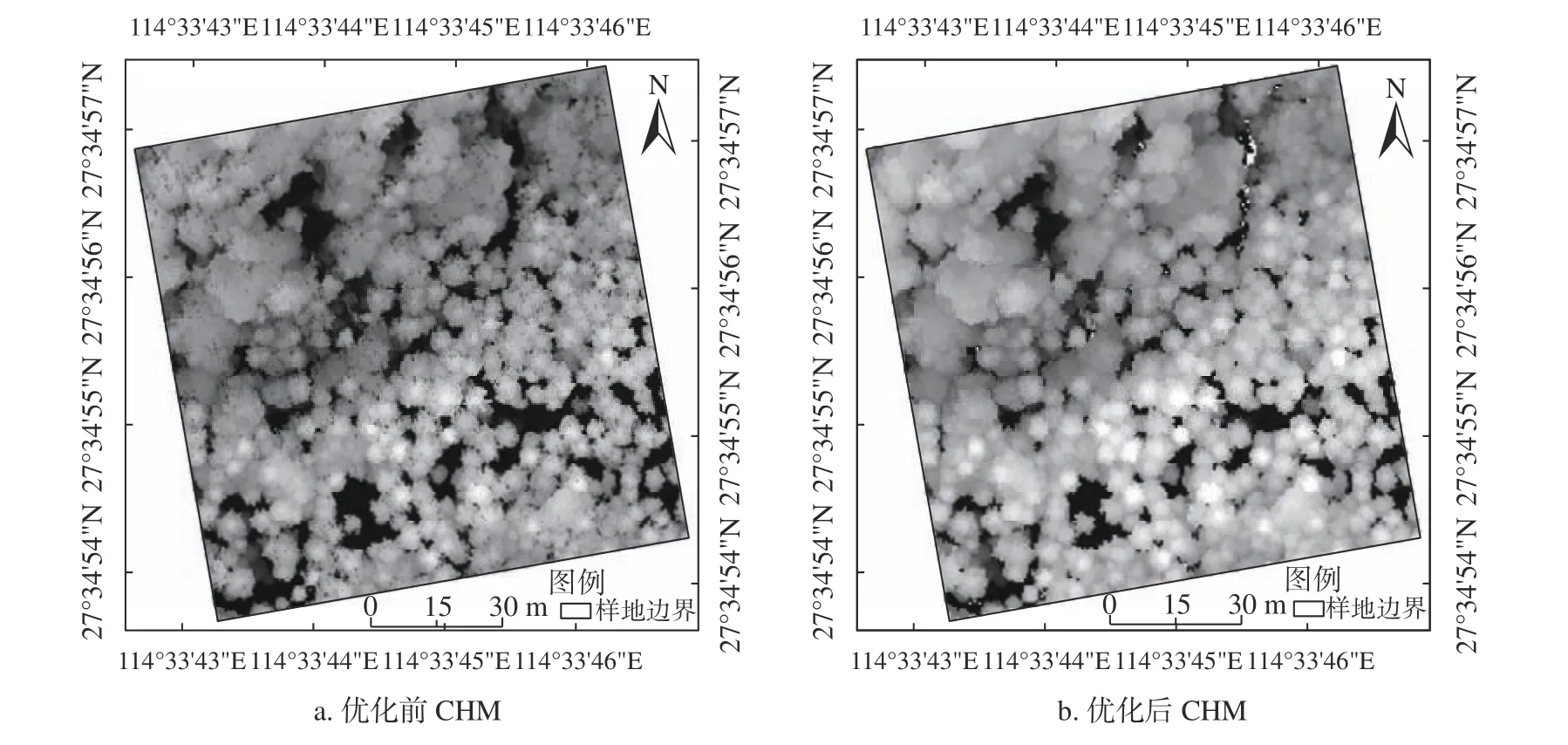
图1 优化前后的CHMFig. 1 CHM before and after optimization
2.3 单木分割
单木分割算法将点云或影像分割成多个部分,每个部分可以看作一棵单木。高郁闭林区单木树顶难以确定导致严重的过分割现象;同时,树冠与树冠之间的重叠存在欠分割现象。本研究采用分水岭算法基于郁闭林区的CHM进行单木分割,获取单木位置、冠幅直径和面积,以及单木边界。再以CHM分割结果为辅助参考,在eCognition中基于预处理后的影像进行多尺度分割,分割尺度设置为60,形状因子0.2,紧致度0.5,得到单木树冠分割结果,根据地面实测数据进行单木分割结果检验。
将分割出来的矢量数据与实地调查数据进行1对1匹配,匹配规则为:若分割矢量树冠内仅包含一个实地调查单木数据,则认为分割准确;若分割矢量树冠不包含实地调查单木数据,则认为过分割,删除该树冠;若分割矢量树冠内包含多个实地调查单木数据,则认为欠分割,通过手动调整保留分割结果,以满足分类要求[15]。
2.4 特征提取与筛选
2.4.1 特征提取
对可见光影像提取影像各波段的均值、标准差、偏度、贡献率,以及纹理特征、几何特征和植被指数共32个特征。纹理特征基于灰度共生矩阵(GLCM)提取,包括均值、方差、信息熵、角二阶矩、相关性、异质性、对比度和同质性8个纹理参数。几何特征主要提取面积、长宽比、形状指数、紧致度、密度和不对称性等特征[5]。植被指数主要包括归一化差异绿度指数(NDGI)、红色植被指数(RI)、可见光波段差异植被指数(VDVI)[16],计算方法如下:

式中:R为红光波段的值,G为绿光波段的值,B为蓝光波段值。
LiDAR数据提取特征包括首次回波和所有回波高度和强度的均值、最小值、最大值、标准差、方差、变异系数、峰度、偏度和分位数等。相关研究表明以5%为间隔的分位数之间相关度较高[17],因此,以1%为起始,5%为间隔提取所有高度和强度特征的15个百分位数用于分类识别。
2.4.2特征筛选
为了避免维数灾难,产生过拟合现象,需要进行特征约简,减少冗余特征,保留对树种识别贡献度较大的特征。常用的特征筛选方法有主成分分析法、特征递归消除法、遗传算法和随机森林算法等。随机森林回归算法可以在进行分类前对要进行分类的特征进行重要值排序,获得特征的重要值,计算模型的准确率,方便筛选出识别效果较好的特征,进而解决大量特征的冗余问题[18]。因此,本研究在R中使用random Forest进行特征筛选,解决原始特征过多问题。
2.5 分类方案
利用遥感数据获取森林类型信息有多种方法,诸如最小距离法、最大似然法以及神经网络、决策树、随机森林和支持向量机等。其中,随机森林(RF)是一种非常有效的分类器集成算法,不需要对数据的分布进行估计,对不同类型或不同尺度的输入变量很有意义,且随机森林具有对结果的可解释性,这些优异的性能使得随机森林适用于基于遥感的森林树种识别[19]。支持向量机(SVM)是一种常用的非参数方法,分类时可将非遥感变量纳入其中,所需训练数据相对较少且无需分布假设,在样本数量较少时,依然有较好的泛化能力[20]。因此,研究选择随机森林和支持向量机两种分类器进行分类识别。
根据最新的林场森林资源调查数据,结合样地实测数据,最终将分类系统定为杉木、马尾松、山矾和其他阔叶树(主要包括鹅掌楸、丝栗栲、苦槠等数量较少的树种)4类。为更好的研究多源遥感数据对单木树种识别的作用,探索特征筛选的效果以及不同特征在分类识别中的重要程度,以单木分割结果为对象,研究分别使用2种数据(可见光和LiDAR数据),是否经过特征筛选,以及2种分类器(RF、SVM),共12种分类方案对实验区的4个树种进行研究,具体分类方案见表2。

表2 不同组合分类方案Table 2 Different combinations of classifications
2.6 精度评价
单木分割精度评价分为3种情况:正确分割、欠分割和过分割。正确分割是指分割结果和实测结果一对一的关系,真正的个体树被分割为一棵单独的树,即有效单木分割,用TP表示;过分割指的是一对多的关系,把本来属于一个整体的单木分成了多株单木,用FP表示;欠分割是一或几棵树被划分到其临近的单木中,未被检测出来,用FN表示[21]。研究了采用召回率(r)、正确率(p)、综合考虑r和p的调和值(F)来评价单木分割精度。r表示有效单木探测株数占真实参考数据的比例,p表示有效单木探测株数占整个提取结果的比率,r、p、F的变化范围为0~1[22],具体计算方法如下:
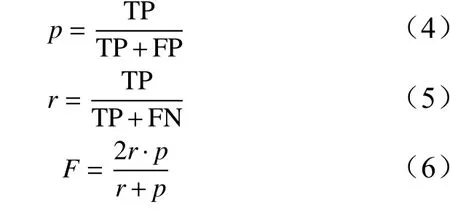
对于正确分割出来的单木,采用随机抽样的方法,将所有数据的70%作为训练样本,30%作为验证样本。采用混淆矩阵中的生产者精度(PA)、用户精度(UA)、总体精度(OA)、和Kappa系数4个指标检验识别结果[23]。
3 结果与分析
3.1 单木分割结果
将单木分割矢量结果与蓝绿红3波段的可见光影像叠加,见图2。根据实地调查结果,剔除枯立木、濒死木和一些冠幅被大树遮挡的小树后共有461株,总共探测到树冠437个,正确分割树冠372个,欠分割36个,过分割29个,计算得召回率为91.17%,调和值0.91,总体精度为80.69%,分割精度较好,满足识别需求。

图2 单木分割结果Fig. 2 Segmentation result
3.2 特征筛选结果
经过RF特征筛选后,可见光保留红光波段均值、蓝绿红3个波段的贡献率、红光波段、绿光波段的标准差、纹理因子冠幅面积等13个特征;LiDAR数据保留首次回波高度和强度变量的平均绝对偏差、最大值、最小值、中位数和峰度等17个特征;可见光和LiDAR结合保留共18个特征,不同数据源特征对分类识别的重要性见图3。
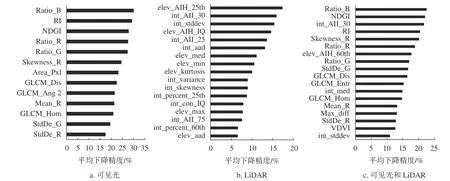
图3 随机森林特征筛选后保留特征及重要性排名Fig. 3 The results of feature selection by RF and importance
从特征重要性排名可以看出,在使用可见光数据时,蓝光波段比率的贡献度最大,红色植被指数、归一化差异绿度指数贡献度次之,红光和绿光波段比率、红光波段偏度、冠幅面积和纹理信息也有较好的表现;在使用LiDAR数据时,25%累积高度百分位贡献度最大,总体看来,强度变量的贡献度大于高度变量;当2种数据结合后,不同数据源的特征重新组合,原本单一数据源特征的重要性就会改变,形成对分类结果贡献度最佳的特征组合。
3.3 分类结果
经过不同数据源组合,应用RF、SVM分类后结果见表3。仅使用可见光数据时,方案Ⅷ(经过特征筛选后SVM分类)识别结果最好,精度达88.89%,其中山矾的精度最高,达90.86%,杉木次之;仅使用LiDAR数据时,方案X(经特征筛选进行SVM分类)识别效果最好,精度达78.47%,其中马尾松识别效果最好,其他阔叶树最低,仅74.68%;当可见光与LiDAR数据结合进行树种识别时,方案Ⅻ(经过特征筛选之后进行SVM分类)识别结果最好,精度高达90.93%,杉木识别结果最好,其他阔叶树精度最低。

表 3 分类结果Table 3 Classification result
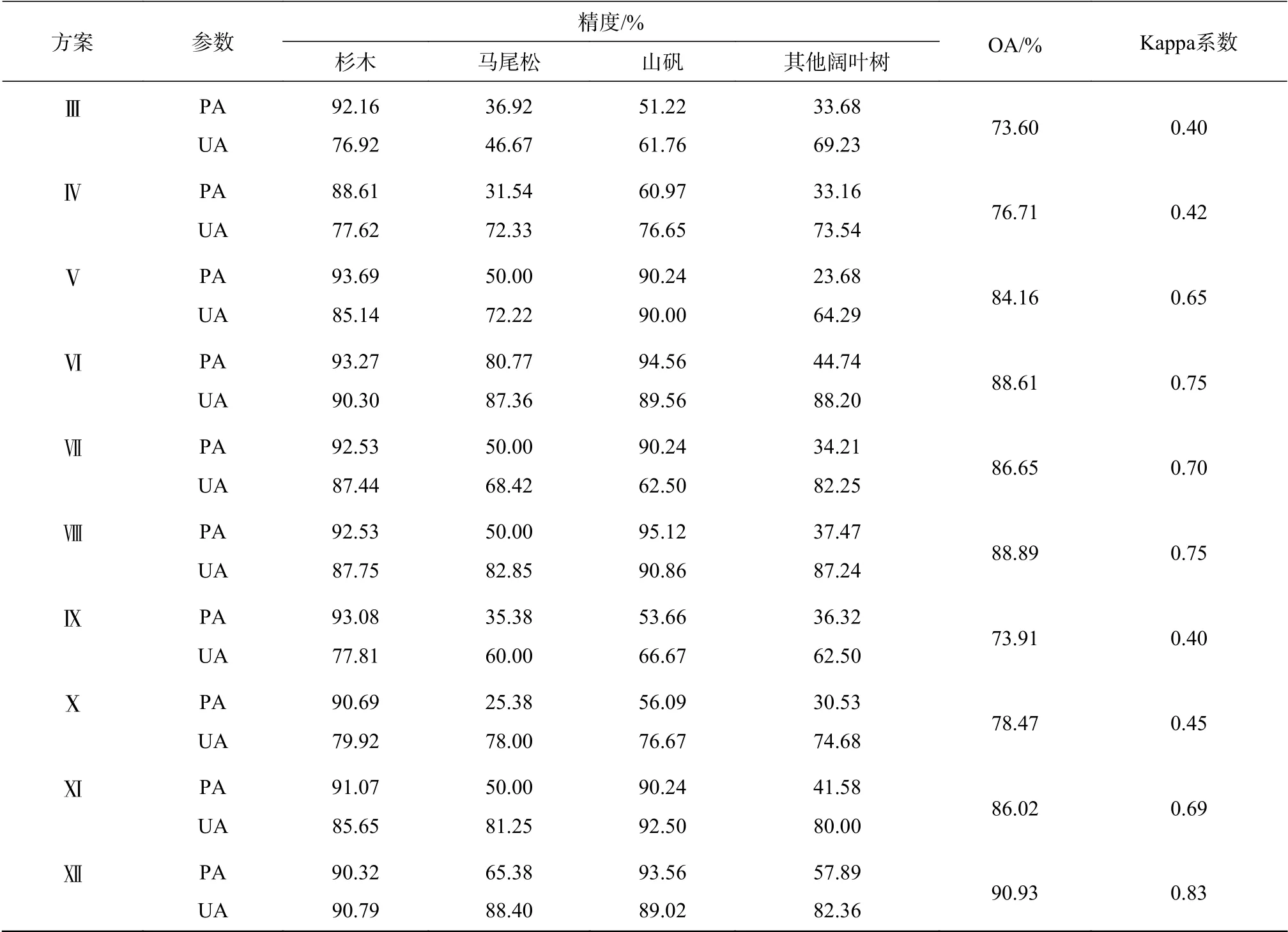
续表 3
4 结论与讨论
在以无人机可见光和激光雷达数据为基础进行树种识别时,结合CHM和多尺度分割的方法能够有效提取出单木树冠,以便于单木树种识别;经过随机森林特征筛选之后精度优于未进行特征筛选的结果;针对本研究区,支持向量机的分类结果优于随机森林分类器。
单木分割结果。先基于CHM分割提取出大概样木边界,再以分割结果为基础进行多尺度分割,能够将树冠边缘细化,得到单木精细树冠边界,满足单木树种识别要求,这与曾霞辉等[24]在利用无人机影像进行树冠信息提取的研究结果是一致的。
特征筛选对分类识别结果的影响。采用多源遥感数据对树种进行识别时,在进行特征筛选之后,相比未进行特征筛选结果,仅使用可见光数据时,RF和SVM的精度均提高1.25%和1.19%,仅使用LiDAR数据的精度提高了0.31%和1.76%,2种数据源结合的精度提高了1.86%和2.32%,不论单一数据源还是2种结合,在经过特征筛选之后,总体平均精度提高1.45%。由此可以看出,本研究和赵颖慧等[11]的研究结果一致,特征筛选能够减少冗余特征和特征共线性的影响,提高分类精度和计算效率。不同的特征对树种识别贡献度不同,从分类结果中可以看出,光谱特征对于分类的贡献度最大,蓝光波段和绿光波段对识别有较大影响,可能因为不同树种的色素含量不同,色素中叶绿素、类胡萝卜素、花青素、叶黄素的含量和绿色波段的反射率有紧密联系[25]。几何特征、纹理特征贡献度次之,这些特征能够表征树的冠型,杉木冠幅面积小,马尾松树冠较为分散,山矾和其他阔叶树冠幅较大且较圆,纹理特征是一种全局特征,可以描述图像区域对应地物的表面性质,因而对分类有较大的潜力。LiDAR数据的高度变量和密度变量对于树种区分同样有着不可或缺的贡献,其中强度变量在区分树种时表现得更加稳定,高度变量精度下降的较快,主要是因为首次回波受冠幅的影响较大,能够很好的表现冠形结构特征,而高度特征受点云遮挡效应的影响,对树冠下面的表现能力有限,高度特征存在一定局限性[15]。有研究表明,特征重要性会随着数据源的组合而发生改变[26],单个特征的重要性可能会受特征组合的影响,在加入其他数据源特征后,原本单一数据源特征的重要性可能会下降,因此,在多种特征结合时,需要考虑其他特征对原本贡献度高的特征的影响,这需要通过更多的实验来验证它们的稳定性。
数据源对识别结果的影响。从不同分类器的识别结果中可以看出,不同数据源对树种识别的影响不同,可见光数据分辨率较高,在单木分割时能够准确区分各个树冠,其光谱特征和纹理特征对识别的贡献度较大,LiDAR数据的首回波强度对分类也有很大贡献且表现稳定,首回波强度均值对冠层条件较敏感,能够很好地代表树冠结构和形态学特征。将2种数据源结合,能够充分利用可见光的光谱和纹理特征,与LiDAR数据特征结合,提高树种分类精度,总体平均精度提高6.01%,这与许多研究得出的结果是一致的[19]。目前的研究仅使用可见光和LiDAR数据,缺少近红外波段等光谱相关特征,无法计算归一化植被指数等森林树种识别的重要遥感参量[27]。Ferreira等[28]在对巴西大西洋沿岸热带森林树种识别时发现,可见光、近红外和短波红外波段是研究森林树种分类的重要波段,在以后的研究可以增加数据源,以此来试验多源结合对识别精度的影响。
通过将2种数据源进行不同组合,在特征筛选和未进行特征筛选下用RF和SVM进行分类,分析不同组合方案下的精度。2种数据源各有优势,无论是单一数据源还是2种数据源结合,在经过特征筛选之后,树种识别精度较单一数据源结果均有不同程度的提高,除了LiDAR数据外,精度均达85%以上。
从研究结果看,特征优选对分类精度的提升起到积极的作用,应予以充分利用,但由于不同特征优选方法所基于的模型和原理存在一定差异,单一特征优选方法所得结果可能存在片面之处,故应考虑通过多种特征优选方法联合使用的方式获取优选特征。RF分类方法在本研究中由于样本量太小,适用性较低,相比之下,SVM分类器在训练样本数量有限的情况下能表现出良好的性能,减少了错分漏分现象。研究表明,多源数据结合能大幅提高分类识别精度,近地低空无人机平台在森林树种的识别上有很大发展空间,未来,以多源无人机遥感数据为基础的森林树种的快速高效识别将会向多模式方向发展。
