基于逻辑回归的企业二次创业金融数据分类方法研究*
2021-10-21赖红清
赖 红 清
(佛山职业技术学院 工商管理学院商贸系,广东 佛山 528200)
0 引 言
随着经济的发展,需要对企业二次创业金融数据进行优化聚类分析,通过提取企业二次创业金融数据的统计特征量,结合大数据信息处理和数据融合方法,将其进行优化聚类分析,以提高企业二次创业金融数据的模糊聚类能力[1]。对企业二次创业金融数据的分类是实现企业金融管理优化的关键,相关的数据分类研究受到人们的极大关注[2]。对企业二次创业金融数据的聚类分析主要采用模糊聚类方法,结合统计数据分析,进行数据分类处理,但传统方法模糊度较大,分类的准确性不好。针对上述问题,提出基于逻辑回归的企业二次创业金融数据分类方法,采用逻辑回归分析方法将数据进行融合聚类处理,结合模糊C均值聚类方法,实现数据分类的自适应寻优和收敛性控制。最后进行仿真实验分析,展示了该方法在提高企业二次创业金融数据分类能力方面的优越性能。
1 企业二次创业金融数据分布模型及特征分析
1.1 分布模型
为了实现企业二次创业金融数据分类,采用自适应无监督学习方法进行统计融合处理。首先构建企业二次创业金融数据模糊决策树模型,采用相空间重构方法进行模糊特征重构[3],采用一个四元组(Ei,Ej,d,t)来表示特征分布权系数,其中Ei,Ej是企业二次创业金融数据特征权重的实体集(即节点i和j),d为特征权重的交互性统计数据,t为企业二次创业过程中的业绩关联数据特征集,采用企业内部代理方法进行统计特征分析,得到企业二次创业金融数据的量化集为
x(t)=(x0(t),x1(t),…,xk-1(t))T
(1)
采用一个1×N维的分布阵列进行企业二次创业金融数据特征重构,确定模糊时间窗口值N,构建多维信息熵分布矩阵。采用激励机制建立企业二次创业金融数据的特征权重分析模型,建立窄时域窗TLX,TLY,得到企业二次创业金融数据特征权重的模糊特征提取模型为
(2)
式(2)中,Dx(x,y)表示特征提取最大范围值,当提范围值小于等于窗口值N时,进行特征权重的模糊特征提取;当超出窗口值N时,不进行提取。
设企业二次创业金融数据特征权重的模板特征分布为m,构建Probit多元回归分析模型[4],得到数据的有效性控制指数为Nj*,在进行企业二次创业金融数据特征权重回归分析的基础上,得到企业二次创业金融数据的统计回归分布为
(3)
根据企业二次创业金融数据特征权重进行自适应分类,构建融资相关性决策模型,提高对数据的分类和统计决策能力。
1.2 模糊特征分析
构建企业二次创业金融数据分布的不规则空间聚类模型,采用相空间结构重组方法进行模糊特征重构,采用决策树模型进行统计融合分类[5],得到企业二次创业金融数据的量化特征分布集为D,D={Si,j(t),Ti,j(t),Ui,j(t)},其中Si,j(t)表示特征权重的重复因素,Ti,j(t)表示融合分类的输出量因素,Ui,j(t)表示相似度(相关性)模型,对企业二次创业金融数据特征权重关联规则特征量进行量化回归分析,定义为
(4)
Ti,j(t)表示对企业二次创业金融数据特征权重检测的相关性特征分布集,计算表达为
(5)
提取企业二次创业金融数据的关联规则特征量,根据谱聚类结果,进行自适应筛选和优化决策,建立关联规则模型,输出为
Ui,j(t)=exp[-b[zi(t)-zj(t)]2]
(6)
式(6)中,pi,j(t)为统计融合分类的互信息量;spi,j(t)为特征权重检测的分叉度重复量;Δp(t)为增益系数;zi(t),zj(t)表示为模糊度函数,由此建立企业二次创业金融数据的特征提取和大数据融合聚类模型,采用模糊特征分析方法,进行企业二次创业金融数据的模糊聚类处理,提高数据的分类挖掘和识别能力[6]。
2 企业二次创业金融数据分类优化
2.1 金融数据的关联规则特征提取
在构建企业二次创业金融数据优化分类模型中,采用融资决策模型,进行融合调度,提取关联规则特征集进行金融数据的自适应分类,分析企业二次创业金融数据的离散空间调度模型,采用模糊控制方法[7],进行融分段样本检验,得到自适应加权权重为
ωj=(ω0j,ω1j,…,ω(k-1)j)T
(7)
建立企业二次创业金融数据的模糊聚类模型,进行特征分析,得到数据序列的统计特征序列为
(8)
式(8)中,k为企业二次创业金融数据的聚类空间分布权重。采用离散序列调度方法,构建企业二次创业金融数据的特征匹配模型,根据多分类器融合结果进行信息分类,实现企业二次创业金融数据的统计特征检测,得到检测统计量为
(9)
(10)
构建企业二次创业金融数据统计分布有限数据集模型,得到关联特征为
(11)
(12)
在分散子空间中进行企业二次创业金融数据实时检测,实现关联规则特征提取[8]。
2.2 数据模糊C均值聚类和优化分类
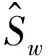
(13)
采用多队列调度方法,建立企业二次创业金融数据的决策调度模型,得到特征训练集si={xj:d(xj,yi)≤d(xj,yl)},企业二次创业金融数据的显著性特征权重为
MinWH=min{w(cc),h(cc)}
(14)
(15)
建立模糊度核函数模型,采用相空间结构重组方法,得到Nj*的几何邻域NEj*(t),企业二次创业金融数据统计融合分类的模糊聚类中心为
U={μik|i=1,2,…,c;k=1,2,…,n}
(16)
在关联规则聚类下,得到企业二次创业金融数据的模糊调度函数为
(17)
采用空间网格聚类方法得到优化的企业二次创业金融数据特征权重聚类中心为
(18)
(19)
式(18)(19)中,m为企业二次创业金融数据统计融合分类的适应度函数,(dik)2为样本xk与特征聚类中心与样本Vi的测度距离。结合模糊C均值聚类方法,得到企业二次创业金融数据主成分分布为
(20)
构建企业二次创业金融数据模糊聚类的回归分析模型,根据特征分布进行线性结构重组,得到企业二次创业金融数据的多元决策模型,对其进行分布式检测和自适应聚类分析,得到相关性概率密度特征为
(21)
在关联规则特征分布集中,企业二次创业金融数据分类的互信息量为
(22)
建立企业二次创业金融数据的特征提取和大数据融合聚类分析模型,实现特征权重分类[10],得到企业二次创业金融数据统计分布序列特征矩阵,满足:
(23)
根据上述分析,采用决策树模型,构建企业二次创业金融数据的空间聚类模型,结合统计特征分析方法,实现数据的均值聚类和自适应分类识别方法,实现对企业二次创业金融数据分类的自适应寻优和收敛性控制,提高数据的分类检测能力。
3 仿真实验与结果分析
为了验证本文方法在实现企业二次创业金融数据分类中的应用性能,进行仿真实验分析。采用Matlab和C++进行数据分类的算法设计,对金融数据采样的样本数为1 200,控制权重系数为0.36,金融数据的模糊特征检测迭代次数为800,采样周期T=0.86 s,信息的扰动强度为SNR=0~-20 dB,统计采样率为fs=(10*f0) Hz=10 kHz,根据上述仿真环境和参数设定,进行企业二次创业金融数据统计融合分类,得到大数据集采样分布如图1所示。

图1 企业二次创业金融数据的大数据集采样频域分布Fig. 1 The sampling frequency distribution of the big data of the financial data for the secondary entrepreneurship of a firm
以图1的数据为研究对象,构建企业二次创业金融数据分布的不规则空间聚类模型,采用相空间结构重组方法进行模糊特征重构,得到企业二次创业金融数据的聚类中心分布如图2所示。
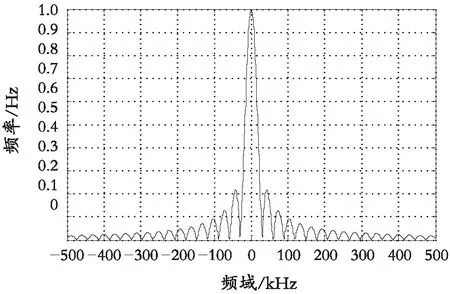
图2 企业二次创业金融数据的聚类中心分布Fig. 2 The clustering center distribution of the financial data
分析图2得知,采用本文方法进行企业二次创业金融数据分类的空间聚集性较好,聚类中心检测的抗干扰能力较强。测试不同方法的企业二次创业金融数据的准确性,得到收敛性测试结果如图3 所示。
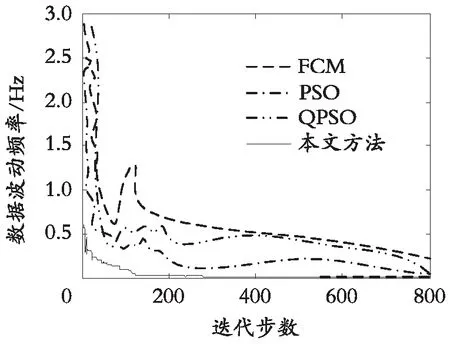
图3 企业二次创业金融数据分类的收敛性结果Fig. 3 The convergence result of the financial data classification of the secondary entrepreneurship of a firm
分析图3得知,采用本文方法进行企业二次创业金融数据统计融合分类的准确性较高,进一步测试企业二次创业金融数据的误分率,得到对比结果见表1。分析表1得知,本文方法进行企业二次创业金融数据统计分类的误分率较低。
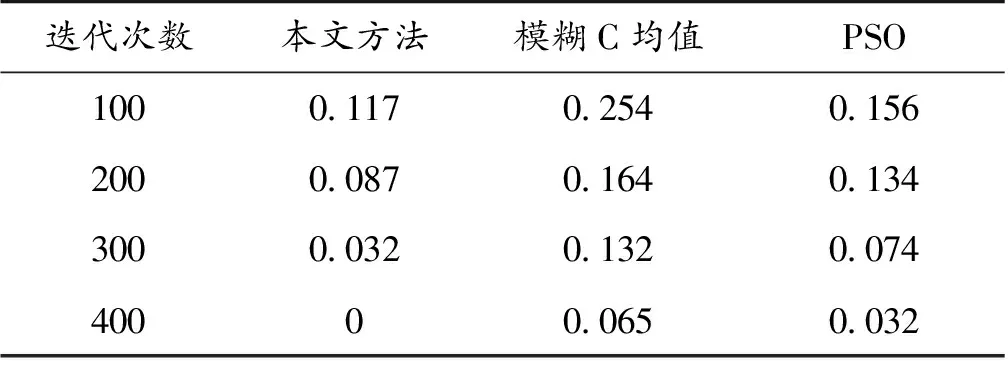
表1 误分率对比Table 1 Comparison of error rate
4 结 语
结合大数据信息处理和数据融合方法,进行企业二次创业金融数据的优化聚类分析,提高企业二次创业金融数据的模糊聚类能力。提出基于逻辑回归的企业二次创业金融数据分类方法,采用自适应无监督学习方法进行统计融合处理,构建企业二次创业金融数据分布的不规则空间聚类模型,采用相空间结构重组方法进行模糊特征重构,采用逻辑回归分析方法进行融合聚类处理,结合模糊C均值聚类方法,实现对企业二次创业金融数据分类的自适应寻优和收敛性控制,实现分类优化。研究得知,采用该方法进行企业二次创业金融数据分类的准确性较高,误分率较低。
