面向机器人抓取的双目视觉单步多目标检测方法应用研究*
2021-10-21李世裴李春琳韩家哺朱新龙
李世裴, 李春琳, 韩家哺, 朱新龙
(上海工程技术大学 机械与汽车工程学院, 上海 201600)
0 引 言
机器人抓取技术是指机器人从复杂的实际环境中通过相机识别出目标物体[1],完成对目标物的定位,进而进行抓取操作。目标检测作为最核心问题之一,是一种基于目标几何和统计特征的图像分割技术[2],尤其在复杂场景中进行处理时,目标检测的准确性和快速性显得尤其重要。传统视觉[3]利用图像的几何特征、颜色特征、局部特征等来进行图像的特征提取,这种方法无法检测多种目标物,也无法模拟真实的复杂工业环境,将深度学习与图像相结合[4],可以取得很好的效果,深度学习在图像上具有很高的特征提取能力[5],能快速有效地对深度图像进行特征提取,将特征进行一系列的处理,最后输出完成对目标物的分类和定位[6]。Navneet Dalal等人使用描述方向梯度直方图的HOG[7]将图像边缘信息和形状信息由梯度信息描述,并使用线性SVM[8]作为分类器完成对目标物的提取,这种方法可以完成对单个物体的识别,这种基于机器学习的目标检测方法为目标检测提供了一种新的思路,但是这种方法仅仅局限于一种物体,且在复杂的工业场景下,难以实现对目标物的精准识别。夏晶等[9]提出一套基于Mask R-CNN的目标检测方法提取三维场景中的可抓取区域,利用深度学习完成对目标物的精准识别具有重大意义,它标志着机器人技术与深度学习的结合,这种利用深度学习对目标进行定位的机器人定位技术在深度检测上具有较大的误差,这些机器人抓取定位技术存在着定位精度不足,或者无法满足对深度精确度的要求。或者只能完成对一种物体的定位,当目标物种类变多或者工业场景发生改变,这些方法的定位便难以完成。牛津大学计算机视觉组提出构建VGGNet-16等深度学习模型[10]应用于SSD(Single Shot MultiBox Detector)深度学习模型中,能够达到目标检测的精度和速度。将这个模型基于机器人抓取实际场景,与深度模型结合,完成对深度和像素位置的双重精准定位,通过深度模型对多种不同物体进行精准识别,完成对目标物深度的精准测量,二者在视觉系统中完成协作,相互通讯,通过完成对目标物的精准定位。这种方法的精确度高,误差在毫米级别,并且可以适应多种不同环境,具有很强的鲁棒性。
依托搭建的协作机器人抓取视觉检测系统,提出通过双目相机采集目标物的图像,经过数据扩增,创建数据集,从而研究目标检测和机器人抓取技术。通过将采集的图像输送至单步多目标检测模型[11]中进行训练,完成对目标物的平面定位实验。通过双目测距原理完成对目标物的深度定位实验。由相机标定[12]和手眼标定[13]获取目标物的机器人基坐标位置信息,在机器人操作平台ROS[14]中建立机器人与上位机通讯之后,将获取到的机器人基坐标信息发送给ROS。
1 机器人抓取视觉检测系统的搭建
如图1所示,双目相机固定安装在工作空间正上方,工作空间中放置各种类的目标物,三手指灵巧手安装在协作机器人末端。双目相机经过相机标定后,采集图像输送至单步多目标检测器,完成训练识别出目标物类别和像素坐标,同时双目相机根据双目测距原理建立模型,输出得到目标物的深度。像素坐标和深度坐标信息通过手眼标定转换到机器人基坐标。在ROS中建立机器人与上位机的通讯,将机器人基坐标信息发送给ROS。

图1 机器人抓取视觉检测系统实验平台
2 视觉标定原理及方法
机器人视觉系统由双目相机、相机标定系统和手眼标定系统构成,主要完成像素坐标和目标点的深度计算,并转换为机器人基坐标,经过视觉系统转换的坐标点会提供给ROS。
2.1 双目相机标定原理
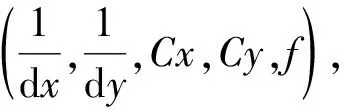

图2 理想相机成像模型
P为空间中一点,f为相机焦距,b为两个相机之间的间距,z为P点到双目相机的深度。根据三角形相似定律:
由上解得:
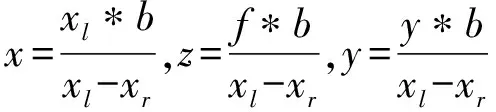
由视差d=xl-xr可得
(1)
由式(1)推导可知,左右相机之间的间距b和焦距f是相机本身的参数,数值也是固定的,相机中的唯一变量是d,故双目相机测距的核心问题是计算左右相机的视差,即左相机的每个像素点(xl,yl)和右相机中对应点(xr,yr)的对应关系。
(2) 极线约束和图像矫正技术。相机坐标系与目标物构成的三维坐标系中,目标物P点与左右相机的中心点(c1,c2)形成三维空间中的一个平面Pc1c2,这个平面称为极平面。极平面与左右图像相交的两条直线称之为极线,对于在左图像中的P点,寻找到在右图像中的对应点,便可求解出P点的深度,极线约束就是当同一个空间点在两幅图像上分别成像时,已知左图投影点p1,那么对应右图投影点p2一定在相对于p1的极线上,这样可以极大的缩小匹配范围。如图3所示,可以直观地看到,沿着极线搜索,最终可以找到与左图像对应的点p2。

图3 极线约束
但是在有些场景下两个相机独立固定,和c2不会完全水平,即使是固定在同一个基板上也会因为装配的原因导致c1和c2不完全水平,图像校正技术就是通过分别对两张图片求单应矩阵得到的,这种技术把两个不同方向上的图像平面重新投影到一个平面且光轴相互平行,将非理想情况下的模型变成理想模型。
2.2 相机标定
相机标定是完成双目测距的必要条件,使用张正友标定法,打印一张棋盘格标定板,双目相机从至少3个方向采集标定板的照片,就可以求出左右相机的内外参数和双目相机的径向畸变K1,K2,K3和切向畸变P1,P2。基于opencv将采集的图像裁剪为左右两张图像,调用matlab中的stereo Camera Calibrator函数,输入棋盘格单位格大小以及裁剪完的图像,便可求解出相机内外参数及畸变参数。如表1所示,为双目相机标定的过程与结果。Rot代表相机2相对于相机1的旋转矩阵,Trans代表相机2相对于相机1的偏移矩阵。
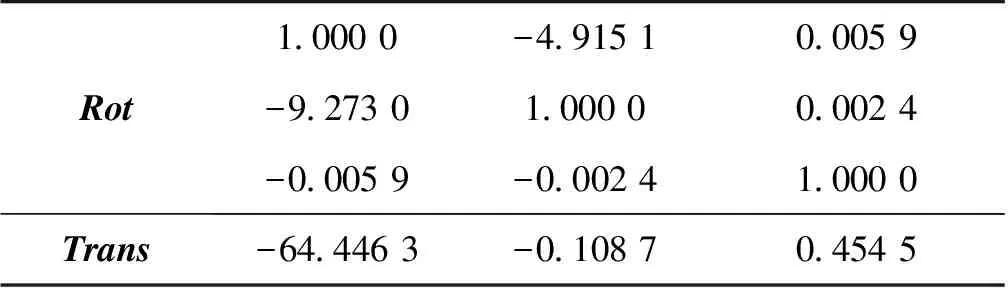
表1 双目相机标定结果
2.3 手眼标定


图4 手眼标定模型
通过求解不同位置时相机外参和机器人工具坐标系相对于机器人基坐标系的关系来求出相机坐标系相对于机器人基坐标系的关系。基于选取的手眼标定类型为眼在手,手眼变换矩阵为:
(2)
(3)

(4)

可得:
AX=XB
(5)
手眼标定的主要问题就是求解如式(5),opencv提供5种方法求解AX=XB,选择Tsai两步法速度最快,通过C++定义一个手眼标定函数calibrateHandeye(),输入机器人末端相对于机器人基坐标系的旋转矩阵与平移向量,标定板相对于双目相机的齐次矩阵,计算出手眼矩阵。在深度坐标上,基于双目相机测距原理,建立一个双目测距模型,通过输入像素坐标便可得对应的深度。
3 单步多目标检测原理与方法
3.1 单步多目标检测原理
SSD(Single Shot MultiBox Detector)是一种单步多目标检测器,单步多目标检测器采用不同的尺度在不同的位置进行密集采样,用CNN得到的特征提取直接进行分类和回归。
在被SSD处理之前,图像数据会被转化为 300*300 的尺寸,SSD首先会经过VGG-16卷积神经网络的前5个卷积组,每个卷积组都由卷积层和池化层构成,SSD使用Astrous算法将第6层和第7层全连接层转换为卷积层,接着再通过3个尺寸不同的卷积组和一个平均池化层检测不同尺寸的物体。再每个卷积神经网络输出对应的特征图后,卷积滤波器会产生不同的预测,得到大量的回归框,SSD使用NMS(非极大值抑制)的方法来去除大量的重复框,当阈值设定为0.01后,候选框便被消除掉,节约了大量计算,他将所有的计算封装在单个网络中,使得速度明显加快。
3.2 单步多目标检测方法
在对机器人视觉系统搭建之后,使用相机采集了9种目标物体在不同的位姿情况下的图像。由于采集的图像数量达不到理想的数量,通常会采用一些方法去扩充这些图像,进而扩大样本集,防止过拟合的出现。接着需要对扩充后的样本集进行标注,此时样本集中的有效信息将会被进一步提取,经过训练最终生成SSD目标检测模型,完成目标检测的任务。
3.2.1 样本集的制作
深度学习中要在大型数据集上进行训练,优化相应的参数最终得到一个合适的模型。如图5所示,在实际实验中选取了9种工业中常见机械部件(轴承、螺钉等)。

图5 实验中所用的9种机械部件
3.2.2 样本集的标注
在训练SSD目标检测模型中需要对目标物进行标注,让计算机知道目标物的类别和目标物的像素坐标位置。使用LabelImg标注工具来对950张图像进行标注,标注的最终结果保存在“.xml”文件下,“.xml”下包含样本集的所有信息。
完成标注工作之后,要对数据集进行划分,将数据集划分为训练集、测试集和验证集。使用python编写一个划分的脚本,脚本按照设置的比例自动拆分训练集、测试集和验证集最终生成以.txt结尾的文件。实验选取基于Tensorflow深度学习框架的Object Detection API训练目标检测模型,其中的create_pascal_tf_record.py程序将数据集最终转换为TFRecord格式。
3.2.3 SSD模型的训练
SSD模型训练首先要进行实验模型的预训练,选择SSD-300 VGG-based作为预训练模型,编写模型训练配置文件,修改相应的训练则值为NCHW,在NVIDIA 1080TI的GPU环境下运行conda进行模型的训练。设置初始学习率0.000 6,训练次数为45 000次。使用TensorFlow中的TensorBoard可以完成对训练过程可视化,查看模型训练情况,模型的损失值随着训练次数的增加逐渐减小。最后利用Object Detection API中的python脚本将模型结构以及参数相关的文件转化为PB可执行文件。
3.3 目标检测
在ROS平台中完成SSD目标检测模型的搭建,则需要先创建detect_ros节点,这个节点集成了SSD目标检测的PB文件、Object Detection API以及数据集的TFRecord文件,对相机中的图像数据进行检测,将置信度、回归框、坐标中心等信息发布对话,完成订阅便能得到置信度、回归框、坐标中心。
4 实验及结论
4.1 目标检测实验
在目标检测实验中,取出9个目标物中的4种不同物体进行实验,用训练好的SSD模型进行检测,SSD模型会输出每个物体的回归框、编号、置信度。每个编号的回归框也用不同颜色表示,如图6所示。

图6 目标检测结果
4.2 物体定位实验
SSD在输出矩形框的同时,会输出矩形框的四点像素坐标,如图7所示,根据坐标位置可以确定目标物的中心点,物体的中心点经过双目测距模型可得目标物的深度,实验使用HBV-1780双目相机,相机参数如下:焦距2.1 mm,FOV为100°,相机间距60 mm,分辨率2 560*720。实验选择了4个位置,其像素坐标分别为(540,270)、(550,300)、(690,260)、(700,330),将9种不同的物体分别放置在这4个位置,通过目标检测系统得到的像素坐标平均值(Xm,Ym)与真实像素坐标(Xr,Yr)的偏移量来计算x方向上和y方向上的绝对误差,结果如表2所示。通过双目测距模型得到的深度Zm和真实的深度平均值Zr来计算深度方向上的绝对误差,结果如表3所示。

图7 双目测距结果
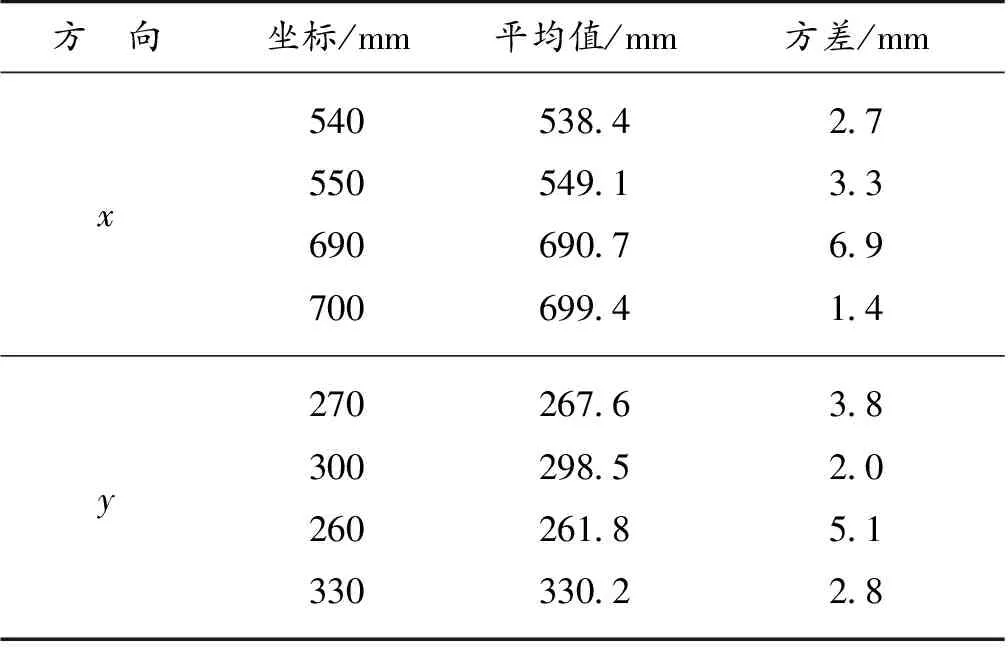
表2 像素坐标平均值与方差

表3 深度测量平均值
试验最终结果表明:整个抓取检测系统能够快速准确地测量出多个物体在平台的像素坐标和深度值,且具有同时检测多个目标物的能力,像素坐标位置误差在3.5 mm以内,深度误差在1.2 mm之内,整体定位误差较小,可以满足抓取操作的要求。
5 结 论
(1) 针对机器人抓取技术难以适应真实工业环境的问题,面向机器人抓取给出了一种双目视觉单步多目标检测方法。
(2) 采用单步多目标检测器替代传统视觉检测器检测多种物体,获得类别、回归框、置信度,对获得的回归框进一步处理获取目标物的中心点。
(3) 通过目标检测实验表明,测试集表现良好,方法的目标检测误差在3.5 mm以内,深度误差在1.2 mm之内,具有很好的应用推广价值。下一步单步多目标检测算法可进一步优化,进一步对像素坐标的偏差进行修正。
