基于梯度提升决策树的焦炭质量预测模型研究*
2021-10-21程泽凯闫小利程旺生袁志祥
程泽凯, 闫小利**, 程旺生, 袁志祥,3
(1.安徽工业大学 计算机科学与技术学院, 安徽 马鞍山 243002; 2.马鞍山钢铁股份有限公司 制造部, 安徽 马鞍山 243000; 3.工业互联网智能应用与安全安徽省工程实验室, 安徽 马鞍山 243002)
0 引 言
焦炭由配合煤在约1 000 ℃的高温条件下经干馏而获得,在高炉炼铁中起着燃料、还原剂、增碳剂及骨架的作用[1],其质量的好坏直接影响高炉运行状态和焦化厂的经济效益。随着一系列的环保政策法规逐渐完善出台,高炉朝着现代化、大型化建设,对焦炭生产的环保标准和质量要求日益提高,同时国内优质炼焦煤较少、价格昂贵且地区分布不均匀[2]。如何提高焦炭质量和产量,降低炼焦成本成了炼焦行业目前急需解决的问题之一。同时焦炭质量检测难,存在很大的滞后性,焦炉炼焦具有非线性、时变缓慢、高延迟、工况复杂的特点[3],建立焦炭质量预测模型具有重大意义。
目前,学者基本采用加权平均、专家经验、线性回归和神经网络等方法对焦炭质量进行预测。曾令鹏等[4]利用韶钢2016年的焦炭质量数据建立了线性回归焦炭质量预测模型,对焦炭灰分、硫分、耐磨强度、抗碎强度进行预测,预测模型已应用于韶钢实际生产, 实现了焦炭质量预测自动化;刘春梅[5]利用BP神经网络,通过炼焦煤质量数据对焦炭质量预测,平均准确率达到了95%;陶文华等[6]利用主元分析法确定焦炭质量预测模型输入变量,利用差分算法对神经网络初始权值和阈值优化,建立了基于DE-BP优化的焦炭质量预测模型,该模型收敛精度快,预测精度高,可以为焦炭生产提供参考价值;袁正波等[7]利用遗传算法对支持向量机进行参数寻优,建立了基于GA-SVM的焦炭质量预测模型,与BP神经网络相比,其误差更小、模型的泛化能力更好。由于加权平均法误差较大,专家经验预测的准确性主要取决于专家的生产实践经验和丰富的专业知识,但主观性太强、普适性差、不能进行定量分析,有时难以保证预测的准确性[8]。线性回归方法简单且容易实现,但对于复杂的非线性数据处理能力差,因此预测误差较大。传统的神经网络训练速度慢,容易陷入局部极小点而无法达到全局最优解,预测精度低[9]。支持向量机由Vapnik[10]等在20世纪70年代提出,具有良好的学习能力、泛化能力,可以解决高维问题,在小样本情况下预测误差较小、准确率高,可以避免选择神经网络结构和易陷入局部极小点等问题[11],但SVM对参数调节和函数选择敏感。
梯度提升决策树属于机器学习算法,最早由Firedman教授[12]提出,是Boosting算法的一种,它将多个性能较差的弱学习器通过某种方式集成起来得到一个强学习器模型,由分类回归树(CART)、梯度提升(Gradiant Boosting) 、缩减(Shrinkage)组成。梯度提升决策树算法可以灵活处理各种类型的数据,在相对少的调参时间情况下,预测的准确率也比较高,算法使用一些健壮的损失函数,对异常值的鲁棒性非常强,因此,近年来梯度提升决策树广泛应用于预测研究领域。路志英等[13]利用Focal Loss改进梯度提升决策树算法,并对天津强对流灾害进行预测,实验结果表明:基于Focal Loss改进的梯度提升决策树模型效果优于逻辑回归、梯度提升决策树、随机森林与多层感知机模型;徐永瑞等[14]利用梯度提升决策树对电力系统负荷进行预测,实验结果表明该模型的精度、泛化能力以及运算速度均优于LSTM。
综上所述,本文提出了基于梯度提升决策树的焦炭质量预测模型,并对某焦化厂历史生产数据进行训练。实验结果表明:该模型相比于线性回归、随机森林、决策树模型预测精度高、误差小,对焦化厂生产具有一定的指导意义。
1 焦炭质量预测模型
1.1 梯度提升决策树算法原理
假设梯度提升决策树的训练集为T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈X⊆Rn,yi∈Y⊆Rn,梯度提升决策树采用迭代的思想,每轮迭代产生一个CART回归树T(x,Θm),Θ表示第m棵CART回归树参数,m=1,2,…,M,每棵CART回归树在上一个CART回归树的残差基础上往残差gm,i减小的方向梯度迭代,更新CART回归树fm(x),使损失函数L(Y,f(x))最小,预测的结果fM(x)为初始值加上各CART回归树的残差。具体计算如式(1)(2)(3) 所示:
(1)
fm(x)=fm-1(x)+T(x,Θm)
(2)
(3)
1.2 数据预处理
本文所有数据来自某焦化厂历史生产数据,由于采集的数据规模大,量纲不同(如焦炭质量硫分为0.7%,耐磨强度为5.5%,抗碎强度为89.4%),存在缺失值和异常值等情况,所以需要对数据进行预处理操作,这样建立的模型才能准确、真实地反应生产情况。
整个数据预处理流程:删除缺失数据,如果一组测量数据中某个测量值残余误差的绝对值xi>3σ,则该测量值为异常值,应剔除,其中σ代表标准差。利用式(4)对输入变量、输出变量归一化。式(4)如下所示:
(4)
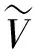
(5)
1.3 焦炭质量预测模型输入输出变量的确定
焦炭影响高炉运行状态的主要质量指标[15]有焦炭灰分、焦炭硫分、焦炭强度等。焦炭的灰分含量增高会使高炉冶炼中的炉渣量增高,导致料柱透气性和透液性变差,焦比增高;含硫量高的焦炭使高炉利用率和钢铁质量下降;焦炭的冷态强度要求高且均匀稳定,则高炉冶炼强度、焦炭负荷、喷煤比得到提高,降低了生铁成本。因此选取焦炭灰分、硫分、耐磨强度、抗碎强度作为模型的输出。
影响焦炭质量的主要因素[16]有单种煤性质(水分、硫分、黏结指数、胶质层最大厚度等)、煤场管理、配煤工艺(煤预处理工艺、装炉煤的配合与粉碎工艺等)、炼焦工艺(焦炉的加热控制、焦炉压力制度)等。配煤炼焦包括一系列复杂的化学、物理反应,但最主要的影响因素是配合煤的质量。配合煤质量指标众多且复杂,根据理论,将所有可以影响焦炭质量的指标都作为模型输入,可能会得到准确率较高的预测模型,但会增加模型的复杂度和训练时间。本文依据专家经验及变量皮尔逊相关性分析结果选取模型输入变量,降低了模型输入维度,提高了模型的收敛速度。皮尔逊相关系数广泛用于衡量两个连续变量之间的相关程度,式(6)中,i=1,2,…,N,E(X),E(Y)分别代表X与Y的均值,X={x1,x2,…,xN},Y={y1,y2,…,yN},有
(6)
分析结果如表1所示。

表1 焦炭质量数据相关性分析结果
其中,皮尔逊相关系数的取值范围为(-1,1),r>1表示正相关,r<0表示负相关,r=0表示零相关,r的绝对值越大表示相关程度越高。因此选择配合煤水分、灰分、硫分、挥发分、黏结指数、胶质层最大厚度、煤的最终收缩度作为模型的输入。
2 梯度提升决策树模型训练及实验结果
本文利用Python 3的Pandas数据处理包和Scikit-learn机器学习包进行数据分析建模。
网格搜索法是一种穷举搜索方法,通过循环遍历,在候选参数集中选取不同的参数进行训练,选取误差最小的参数作为模型的最终参数。本文利用网格搜索法来确定模型相关参数,当梯度提升决策树的学习率为0.01,损失函数为平方损失函数,弱学习器的数目为100, CART最大深度为5时,误差最小。
将数据集中前530组数据划分为训练集,剩下的50组为测试集,对线性回归、决策树、随机森林、梯度提升决策树这4个模型进行训练,为了比较各种模型的性能优劣,采用平均绝对误差MAE、其值均方根误差RMSE衡量模型的预测精度和泛化能力,如式(7)、(8)所示:
(7)
(8)
其中,y代表样本观测值,f代表预测值。实验结果如表2和图1—图4所示。
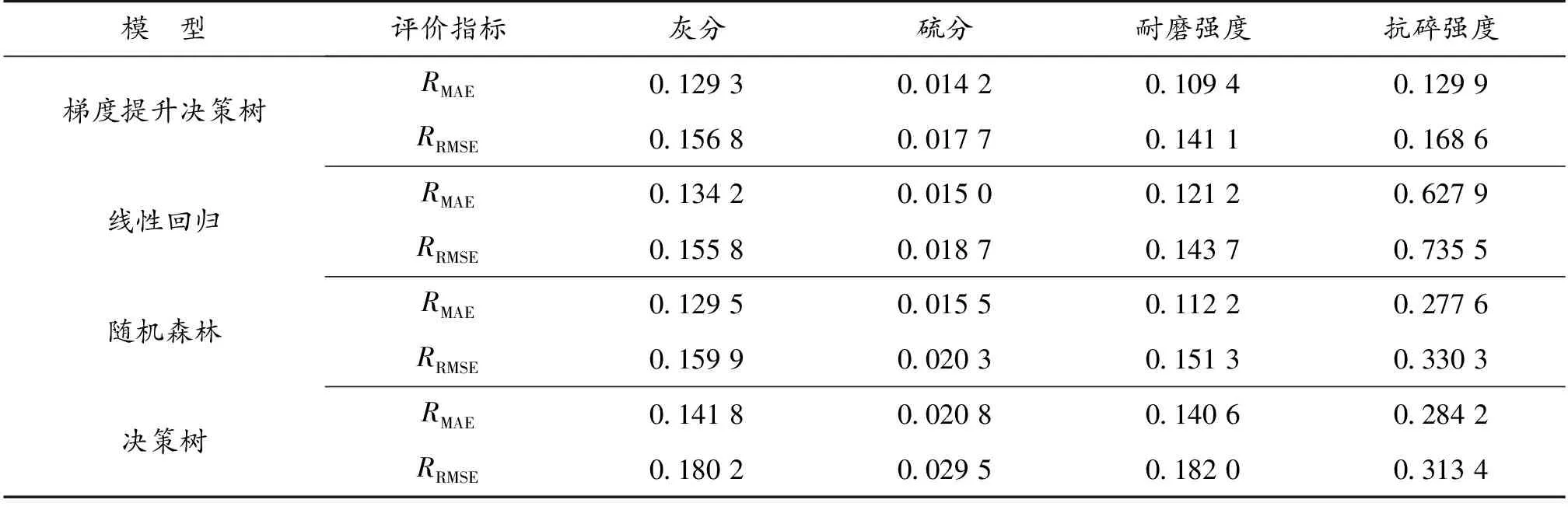
表2 模型性能比较结果

图1 灰分预测绝对误差对比
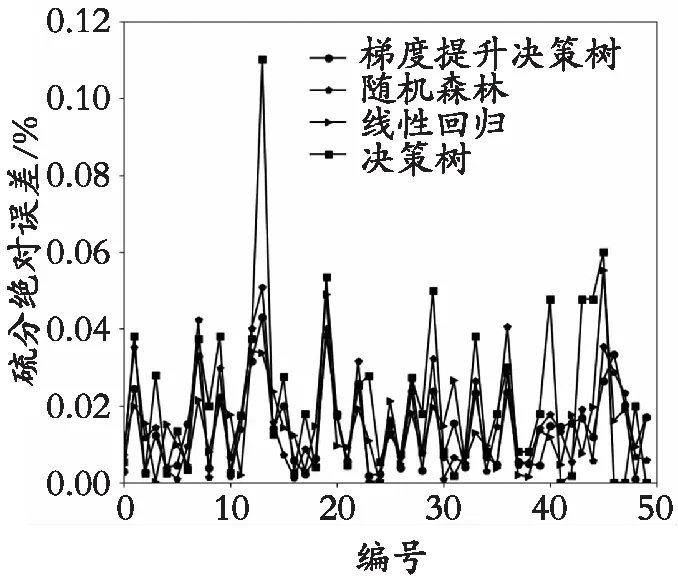
图2 硫分预测绝对误差对比
图3 耐磨强度预测绝对误差对比
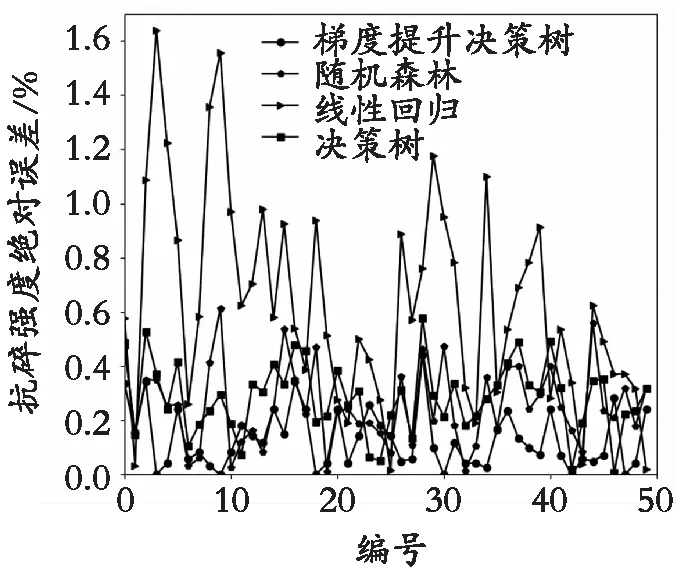
图4 抗碎强度预测绝对误差对比
由表2和图1—图4可知:梯度提升决策树模型预测焦炭各质量指标的RMAE、RRMSE均为最小,相比于其他3种模型更适合焦炭质量预测;线性回归模型对焦炭质量指标灰分、硫分、耐磨强度拟合较好,抗碎强度预测误差较大,但梯度提升决策树的预测精度更高;非线性3种算法拟合误差由小到大顺序为梯度提升决策树、随机森林、决策树,其中梯度提升决策树、随机森林都属于集成学习算法,相比于单一决策树预测精度高、误差小且不容易过拟合;由于存在焦炉炉况波动,数据波动较大,随机森林对波动值不怎么敏感,所以预测误差比梯度提升决策树模型大。
3 结论与讨论
梯度提升决策树、线性回归、随机森林、决策树均属于机器学习算法,在训练样本数量有限的情况下,基于梯度提升决策树的焦炭质量预测模型相比于线性回归模型、随机森林模型、决策树模型误差更小,准确率更高。梯度提升决策树建立的焦炭质量预测模型拥有较好的泛化能力和鲁棒性,能够较为准确地预测焦炭质量,可以为配煤炼焦提供一定的理论依据。目前,只考虑了配煤工艺对焦炭质量的影响,后续工作将研究配煤工艺与炼焦工艺对焦炭质量的影响,以提高预测精度与准确率。
