基于多传感器信息融合和多粒度级联森林模型的液压泵健康状态评估
2021-10-20单增海李志远黄亦翔李彦明刘成良
单增海 李志远 张 旭 黄亦翔 李彦明 刘成良 张 轩
1.徐州重型机械有限公司,徐州,2210042.上海交通大学机械系统与振动国家重点实验室,上海,200240
0 引言
液压泵因其响应快速、调速范围大、单位质量的功率大等特点,已成为工程机械设备液压系统的主要驱动元件。作为液压系统的核心组件,液压泵可为整个系统提供动力,其健康状态对液压系统的运行状态和效率有重要的影响,且设备整体运行的可靠性、稳定性与液压系统紧密相关[1],因此准确地评估液压泵的健康状态对制定合理的维护计划、保障正常生产有重大的现实意义。
目前,液压泵的健康评估方法主要是基于单一的振动信号分析建立的,而压力、温度等其他信号则很少直接用于评估液压泵的健康状态,通常只是作为一个参考指标。针对单一的振动信号,HANCOCK等[2]使用小波包分解液压叶片泵的振动信号,基于提取到的特征利用模糊推理系统进行健康状态分类;ZHU等[3]使用叠加自动编码器对振动信号进行训练和识别,实现了泵的故障诊断;刘志宇等[4]使用卷积神经网络对大量历史振动数据进行训练,有效提高了预测准确率;王浩任等[5]使用小波包提取柱塞泵原始振动信号的有效特征群,通过拉普拉斯特征映射方法实现了特征向量到健康状态的映射。此外,还有学者针对振动信号外的其他信号进行分析,GAO等[6-7]使用小波分解方法对泵的压力信号进行分析,实现了对柱塞泵的实时健康诊断,并进一步使用小波包分解和小波系数残差分析方法实现了泵的故障种类诊断;ZHAO等[8]采用基于间歇性混沌和滑动窗口符号序列统计的方法,利用泵排放压力实现了对早期故障的诊断。
综上所述,当前液压泵的健康评估多依赖于单一的振动信号或压力信号,而在实际工况中,振动源多且杂,单一振动信号或压力信号易造成评估系统的不稳定,将多种传感器信号结合则能更加准确地获取液压泵运行状态的特征,提高系统分辨能力以及可靠性,从而降低系统成本[9]。相对于单传感器,多传感器能够给出更多有用信息。信息融合是对多种信息进行多级处理,每一级处理均是对上一级信息的再加工与抽象,按照实际融合过程中的体系,信息融合可以分为如下三类:数据级融合、特征级融合和决策级融合[10]。不少学者在健康诊断的研究中引入了信息融合,并取得了不错的效果[11-14]。任凤娟[15]使用BP神经网络对多路信号进行诊断,并用D-S理论进行结果融合,从而提高液压系统的诊断准确度;刘思远等[16]通过计算得到液压滑靴在不同磨损程度下振动、出口流量及压力三种信号的烈度特征因子,并基于这三种烈度特征因子建立多信息决策融合算法,从而实现磨损判断。LU等[17]利用泵级、液压动力系统级和液压执行系统级三个层次的信号构建了三个基本概率分配函数,并提出了基于新的证据相似性距离的D-S理论来融合决策,以完成对泵故障的诊断。
深度森林模型是一种基于决策树的深度模型[18],其中多粒度级联森林模型使用了一种新的决策树集成方法,是传统森林模型在广度和深度上的集成,同时具有训练速度快、参数数量少、效率高等优点。
本文提出了一种基于多传感器信息融合和多粒度级联森林模型的液压泵健康评估方法。针对柱塞泵多个传感器信号,采用了特征级融合和决策级融合相结合的信息融合方法。首先提取多个原始传感器信号的时域特征并拼接形成初步特征,其次利用多个集成模型获取初步特征的类别概率向量,并利用随机森林模型评价初步特征的重要度并选取重要度高的初步特征,将高重要度特征与前述类别概率向量集成为预测特征,然后将预测特征作为训练检测样本,使用多粒度级联森林模型进行液压泵健康检测的分类。试验结果验证了基于多传感器信息融合的多粒度级联森林模型相较于基于单一温度传感器信号的多粒度级联森林模型具有较高的健康状态评估准确度,并且在小训练样本情况下仍然有99.5%的精确率。
1 液压泵健康评估流程
随着液压泵使用时间的不断延长,磨损不断加剧,液压泵健康状态逐渐恶化,泄漏量以及压力损失逐渐增大,温度、流量等信息也会受到不同程度的影响。因此,本文在试验环境下采集液压泵出口压力、流量、温度等15路数据,经数据清洗后提取常用时域特征作为初步特征。使用分类器和特征筛选方法对初步特征进行处理,拼接形成预测特征,从而实现特征融合[19],最后利用多粒度级联森林模型进行健康状态评估。具体评估流程如图1所示。

图1 液压泵健康评估流程Fig.1 Hydraulic pump health assessment flowchart
2 多传感器信息融合
信息融合是对多种信息的多级处理,每一级处理均是对上一级信息的再加工与抽象,信息融合可以分为数据级融合、特征级融合和决策级融合三类。
数据级融合是最低层次的融合,是将采集的信息不经过任何处理便进行拼接融合,要求信号是同一物理量的信号,融合信息量大,但处理耗时、抗干扰性差。特征级融合属于第二层次的融合,需要对传感器采集到的原始信号进行特征提取,将提取到的特征进行融合,突破了数据级融合单一物理量的限制,实现了信号压缩,便于传输处理。决策级融合是最高层次的融合,需要对每个独立的传感器信号进行特征提取、识别和决策,然后将决策结果进行融合并形成最终结果,其抗干扰能力强,分类效果更加精确。
上述三种信息融合方式分别将原始信号、数据特征、决策结果进行融合。为了更好地利用信息融合中的数据特征和决策结果,本文将不同分类器获得的类别概率向量与重要度高的特征进行融合,拼接形成最终特征,将最终特征输入到级联森林模型获得最终分类结果。本文的信息融合原理如图2所示。
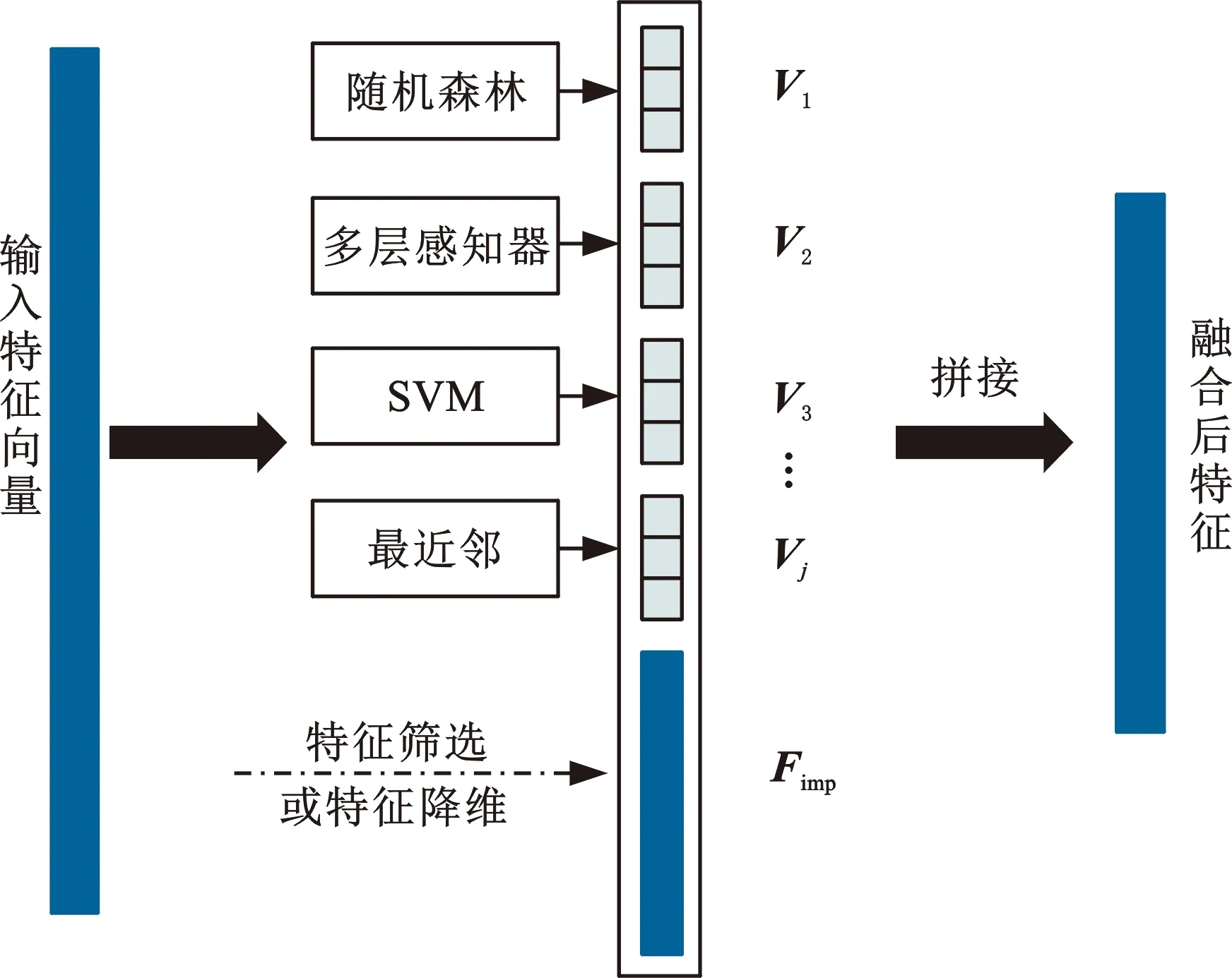
图2 特征融合方法Fig.2 Feature fusion method
在获取初步特征后,分别训练随机森林、多层感知器[20]、支持向量机(SVM)[21]、最近邻[22]等分类器,得到类别概率向量(V1,V2,…,Vj)。同时对原始输入特征使用随机森林模型进行特征筛选,得到特征筛选后或特征降维后的重要特征Fimp。最后将类别概率向量和处理后的重要特征Fimp进行拼接得到最终的融合特征。融合特征的长度Fl与所使用分类器个数j、分类类别个数c、特征筛选或降维后选择的特征个数Fc有关,即
Fl=jc+Fc
(1)
最终融合特征既包括了多类分类器的决策结果,同时也保留了原有特征中较为重要的信息。这样可以避免所选择的分类器不适用或特征提取不到位的情况发生,从而可更有针对性地提高特征的可靠性以及预测准确度。
3 深度森林模型
近年来深度学习已被应用于各个领域中,目前深度学习大多基于深度神经网络(DNNs)实现。然而,深度神经网络的结构复杂、参数数量过多、训练困难、超参数调整困难、要求训练数据量大、模型难以解释等问题阻碍着其在多个领域中的进一步应用。多粒度级联森林模型是一种非神经网络实现的深度模型,其参数量较少、训练难度低,可以用较少的数据完成训练。
3.1 随机森林模型
随机森林模型是一种机器学习模型[23],它以决策树为基分类器构建Bagging集成,Bagging集成可通过降低基分类器的方差来减小模型的泛化误差。将待分类样本数据通过随机森林分类器进行分类处理,最后通过多数投票的方式得到最终的结果。随机森林模型的结构如图3所示。

图3 随机森林模型结构Fig.3 Structure of random forest model
3.2 多粒度级联森林模型
多粒度级联森林模型主要包括多粒度扫描结构和级联森林结构两个部分。
多粒度扫描结构采用多个不同宽度的窗口进行滑动采样,可获得多个相互联系又具有差异性的子样本,分别使用普通随机森林分类器和完全随机森林分类器对得到的子样本进行训练,将输出的类别概率向量进行拼接得到最终的转换特征,如图4所示。
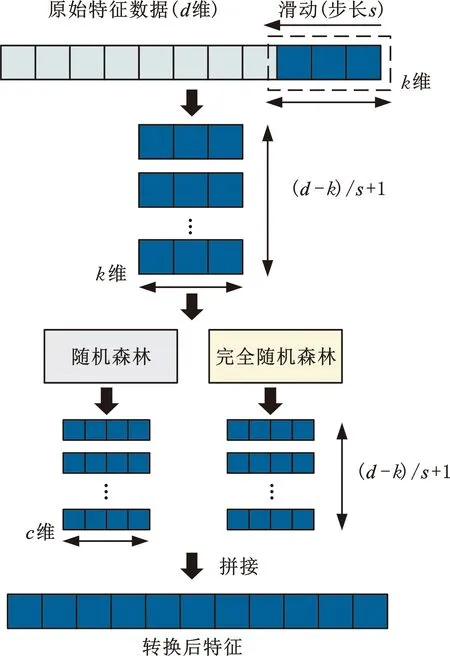
图4 多粒度扫描结构Fig.4 Multi-grained scanning structure
以使用一个宽度为k维的滑动窗口为例介绍整个特征扫描转化过程。当原始输入特征向量为d维时,将滑动步长设为s(即每取一个子样本,窗口移动s维),则可以得到的特征子样本个数为m=(d-k)/s+1。分别使用普通随机森林和完全随机森林两种分类器对每个特征子样本进行训练,每个分类器训练后可以得到一个c维(即分类类别数c)类别概率向量,对于所有特征子样本共得到2m个类别概率向量。将得到的所有类别概率向量进行拼接即可得到2×m×c维转换特征向量。
多粒度级联森林模型采用与DNNs类似的层级结构(即级联森林结构),将前一层森林分类器的输出作为下一层森林分类器的输入,如图5所示。将经过多粒度扫描结构转化得到的转换特征向量输入到级联森林结构,再与每一层森林分类器输出的类别概率向量进行拼接作为下一层的输入,最终获得预测结果。级联森林结构的每一层包含若干个普通随机森林分类器和完全随机森林分类器,每层两种不同的森林分类器增加了模型集成的多样性,多个森林分类器可以充分利用特征的差异来更好地表征特征信息。
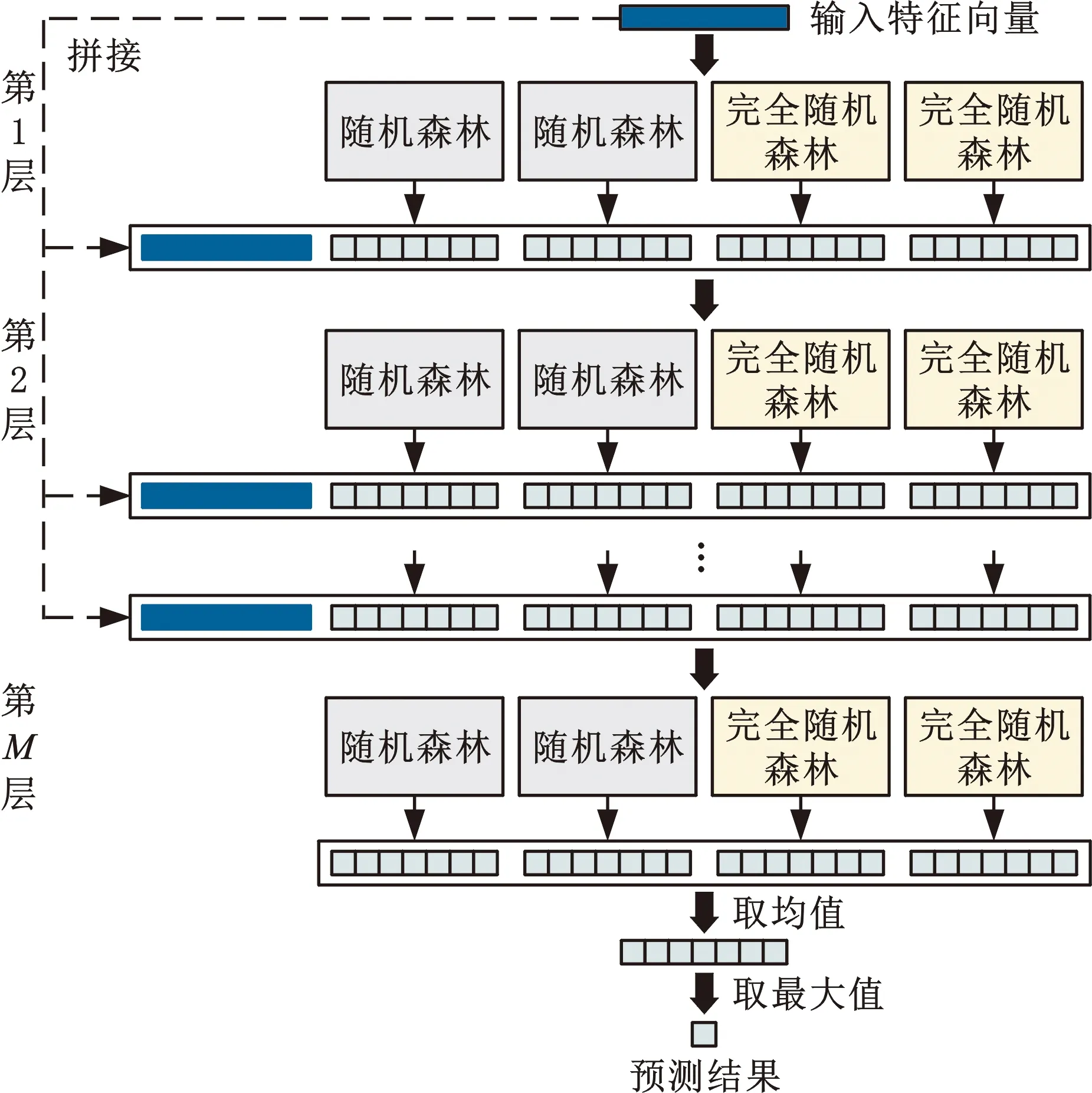
图5 级联森林结构Fig.5 Cascade forest structure
为了避免过拟合的发生,在级联森林结构各层的每个森林分类器的训练过程中均采用k折交叉验证。
4 试验方案与数据预处理
4.1 试验方案
图6所示为本文液压泵试验系统,试验系统按照国家标准GB/T 23253—2009《液压传动电控液压泵性能试验方法》搭建,试验装置由电机、液压泵、油箱、溢流阀、压力传感器等构成,试验液压泵为川崎K3V系列斜盘式轴向柱塞泵。如表1所示,共使用三种不同健康状态下的柱塞泵进行试验,分别是:完全健康的1号泵,使用2000 h左右、中度磨损状态的2号泵,使用3000 h以上、即将处于报废状态的3号泵。图7所示为3号泵的零部件磨损情况,经测量可知,柱塞磨损量为0.06 mm,斜盘支撑座最大磨损为1.24 mm,斜盘支撑座的高压区铜镀层已经磨尽,在低速运转时,容积效率低于80%,转速及压力均有明显下降[24]。

图6 液压泵测试系统Fig.6 Hydraulic pump test system

表1 液压泵简记代号Tab.1 Hydraulic pump health status mark

(a)柱塞磨损 (b)斜盘支撑座磨损图7 液压泵的磨损状况Fig.7 Situation of hydraulic pump wear
试验中,使用PCI-E8025数据采集卡采集信号,信号采样频率为12.5 kHz,采样时间为800 s,试验采集到约1000万条数据。信号通道共使用了15路,分别记为AI 0~AI 14,主要采集的液压泵信号有泵1、2出口压力、流量和温度,泵泄油口温度和流量,油箱温度,电机扭矩、转速等,各通道对应的具体采集信号如表2所示。本次试验采用的噪声计有两个通道的输出,通道AI 10为交流电输出,1 Vrms(电压有效值)对应噪声计的一个范围档,每一范围档内并非线性均分;通道AI 11为直流电输出,电压10 mV对应噪声1 dB。

表2 各通道采集信号Tab.2 Acquisition signal corresponding to each channel
4.2 数据处理
以P1泵为例展示传感器信号,分别绘制出P1泵各个传感器信号的图像,如图8所示,其中噪声信号用电压信号表征,取所有传感器试验数据均较为稳定的160~480 s共400万数据点进行分析。每5000个数据点作为一个数据样本,每种健康状态共800个样本,3种健康状态共2400样本。每种健康状态随机采样获取560个训练集样本和240个测试集样本,3种健康状态共获取1680个训练样本和720个测试样本。按照上述操作,依次对模拟信号的其他数据进行操作。
5 液压泵健康状态评估
5.1 时域特征提取
获取健康状态下的测试样本后,需计算稳定工况下信号的时域特征,包括均值、峰峰值、均方根值等12维特征,具体参数特征如表3所示,然后将所有时域特征进行拼接集成,形成15×12=180维特征。

表3 特征参数表Tab.3 Characteristic parameter table
5.2 特征构建与模型训练
初步特征集为180维,易出现数据冗余,影响模型效果,因此,本研究采用决策级融合和特征级融合相结合的信息融合方法形成新的预测特征,以减少特征冗余,提高模型预测准确度。如图2所示,新特征主要由两部分组成,第一部分是多个分类器通过初步特征得到的类别概率向量,第二部分是基于随机森林模型中特征的重要度所选取的重要特征。
第一部分中,分别使用初步时域特征训练随机森林、多层感知器、SVM、最近邻四个分类器来获取P1、P2、P3三个类别的分类概率,其中训练样本比例和后续深度森林模型训练样本比例保持一致。第二部分中,使用随机森林模型对初步特征进行重要度评估,选取重要度高的前8个初步特征作为新特征的组成部分。前8个重要特征及其含义如表4所示。

(a)泵1出口压力 (b)泵2出口压力 (c)泵泄油口压力

表4 重要特征介绍Tab.4 Introduction of important features
由表4可知,从时域特征来看,泵泄油口温度、泵2出口温度、泵1出口温度是最重要的特征,均方根值和整流平均值是较为重要的统计特性,这说明柱塞泵泄油口和出口处的温度能很好地体现出柱塞泵健康状态的变化,与以往研究中最常选用的振动、油压等信号一样,对泵的健康状态诊断都具有重要的意义。
上述8个重要特征和第一部分中3×4=12个类别概率向量拼接形成最终20维的预测特征。
5.3 基于多粒度级联森林模型的液压泵健康状态分类
多粒度扫描结构的超参数主要有森林分类器数量、森林分类器类型、决策树数量、滑动窗口大小以及节点分裂最小样本数等;级联森林结构的超参数主要有森林分类器数量、森林分类器类型、决策树数量和节点分裂最小样本数。
本文中,多粒度扫描结构和级联森林结构的森林分类器类型均选为完全随机森林和普通随机森林的组合,按照经验选取滑动窗口大小分别为2、4、8,多粒度扫描结构和级联森林结构的节点分裂最小样本数均为5。具体参数设置如表5所示。

表5 多粒度级联森林模型的参数Tab.5 Parameter of multi-grained cascade forest model
本文选用20%的样本作为测试集,剩余样本作为训练集。考虑到分类问题的普遍性,选用分类问题中常用的两个参数(精确率和召回率)作为评价指标,其表达式如下:
(2)
其中,NTP为预测为正样本、标签为正样本的样本数量;NFP为预测为正样本、标签为负样本的样本数量;NFN为预测为负样本、标签为正样本的样本数量。在上述选用的测试集(测试集比例为20%)下对多粒度级联森林模型进行测试,经计算可知,分类的精确率和召回率均为100%。
依次将测试集比例设置为30%、50%、70%、90%、99.5%(即训练集比例依次为70%、50%、30%、10%、5%),通过对比不同训练集情况下模型的精确率来评价模型在小训练样本情况下的健康评估性能,分类结果见表6。
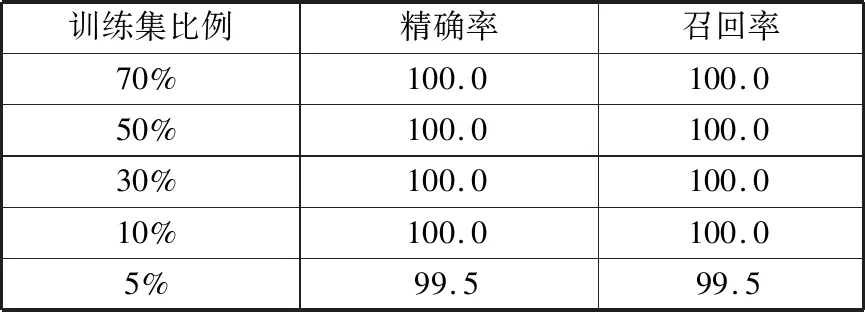
表6 不同训练比例下的分类结果Tab.6 Classification results under different training set ratios %
由表6可以看出,在小训练样本的情况下,基于多传感器信息融合的多粒度级联森林模型预测得到的液压泵健康状态评估的精确率仍较高,即使在训练集比例仅为5%的情况下,基于特征融合和深度随机森林模型的液压泵健康状况评估结果仍有高达99.5%的分类精确率。
单独采用预测向量中的第一部分和第二部分数据进行分析,使用多粒度级联森林作为分类器,在训练集比例为10%(即测试集比例为90%)的情况下可以得到表7所示的分类结果。

表7 部分预测向量分类结果Tab.7 Classification results of partial prediction vector %
由表6和表7可知,在级联森林结构中单独使用部分预测向量时(即每一层只将各个随机森林模型输出的类别概率向量拼接或只将原始特征筛选得到的高重要度特征拼接后输入下一层)的分类效果相较于将两者进行融合后的分类效果有明显降低。
为了进一步探究不同信息融合方式对结果的影响,结合采集端口情况挑选出压力、流量、温度三类数据,并将上述原始数据进行前文所述流程的处理(即提取时域特征(5.1节)、特征构建、模型训练(5.2节))。为了更清晰地呈现不同类别的预测结果,分别计算测试集比例为90%时P1、P2、P3三个类别的精确率和召回率的参数变化情况。组合方式及分类结果如表8所示。
由表8可知,对于同一分类器,单一温度特征不能兼顾精确率和召回率这两个参数,在增加流量信息后,三类别数据的平均预测精确率提高了8%;增加压力信息后,三类别数据的平均预测精确率提高了7%,分类效果均得到了一定的提高。同时,“温度+流量”组合中所有类别的平均预测精确率和召回率均高于“温度+压力”和“压力+流量”两组合中的平均预测精确率和召回率,这证明了温度融合流量这种信息组合的优越性。因此,在精确率要求不高(即精确率不超过95%时)的情况下,可以只使用温度传感器和流量传感器的组合,而不必使用压力、流量、温度三种传感器,这样能够降低传感器成本、减少数据采集量,传感器的具体放置位置如表9所示。
此外,预测特征生成中所使用的分类器也会产生特征的冗余,从而影响分类效果,因此在前期选用类别概率向量生成算法时,需要选择小训练样本情况下分类效果仍可以接受的算法,从而提高多粒度级联森林模型最终的分类精确度。

表8 数据组合方式及分类结果Tab.8 Data combination and classification results

表9 推荐的传感器组合Tab.9 Sensor combination recommended
6 结语
本文针对柱塞泵健康评估的问题,采用了多传感器信息融合方法,利用多个集成模型与特征筛选的方式组合得到的特征融合器进行信息融合,使用多粒度级联森林模型进行液压泵健康评估。试验结果表明,所提特征融合方法在降低特征维度的同时保留了重要特征信息,健康分类精确率较高。通过对不同训练集比例数据进行对比,可以看出该柱塞泵健康评估方法在样本量较小时也有较高的精确率;与不同信息融合方式的对比也验证了本文的信息融合方式在柱塞泵健康评估时更加准确有效。
