基于并行多任务深度学习的铁路主要技术标准优选
2021-10-20袁文辉蒲浩王光辉李伟张文初
袁文辉,蒲浩,王光辉,李伟,张文初
(1. 中南大学 土木工程学院,湖南 长沙 410075;2. 高速铁路建造技术国家工程实验室,湖南 长沙 410075;3. 长沙交通投资控股集团有限公司,湖南 长沙 410014)
铁路主要技术标准是铁路建筑物和设备的类型、能力及规模的基本标准,对铁路能力、运营安全、运输效率、投资规模、经济和社会效益产生极其重要的影响。科学合理选择主要技术标准,应根据运输需求,充分考虑资源分布和科学技术的发展,结合自然、经济及社会环境,全面比选确定,实现所有铁路要素(能源供应、机车车辆性能、线路与结构,通信信号系统)的协调工作,满足安全、经济、环保、舒适运营要求[1]。主要技术标准优选是铁路全生命周期最重要的先决技术决策之一。传统的主要技术标准优选主要依靠人工完成:由经验丰富的工程师根据运量需求,综合考虑地形地质等自然条件、桥隧站等构筑物修建技术、机车信号等装备水平等多维因素,拟定多组有价值的主要技术标准;然后分别针对每组标准设计出优化的线路方案,再通过线路方案的综合比选,完成主要技术标准的优化决策。这种基于经验驱动的决策方法工作量大、效率低、严重依赖设计者的认知水平和经验水平,且难以获得主要技术标准最优值。为提升主要技术标准决策的效率与水平,国内外学者开展了大量研究。这些研究可分为直接法(建立模型直接求解主要技术标准)和间接法(借助智能选线技术间接提高决策水平)两大类:
1)直接法
此类方法建立经济性、安全性等线路评价指标与主要技术标准之间的数学模型,直接求解满足条件的最优技术标准。最具代表性的是王柢等[2-3]构建了线路经济指标D与机车持续牵引力F,限制坡度G,最小曲线半径R之间的数学模型,并用非线性规划优化方法求解最优的主要技术标准。陈进杰等[4]在此基础上进一步考虑了资金的时间价值,采用动态经济指标作为标准综合优化的目标函数。杨长根[5]将铁路主要技术标准决策问题看作为多目标决策问题,采用线性加权的方式将其转化为单目标函数进行标准的综合优化。虽然上述研究实现了主要技术标准的自动化优选,但是它们将沿线的地形条件粗略划分为4类,不能反映真实的地形特征;而且经济指标与铁路主要技术标准之间的关系十分复杂,难以用显函数准确表达,上述方法很少应用于工程实际。
2)间接法
间接法是通过研究智能选线技术,自动生成拟定技术标准条件下的最优线路方案,从而快速完成对主要技术标准的评价。智能选线技术经过60余年的发展,优化目标从二维的线路平面优化[6]或纵断面优化[7−8]发展为三维空间的平纵面整体优化[9−10];寻优方法从传统的变分法、线性规划等数学方法[6,11]演变为遗传算法、粒子群等启发式搜索[12−13];研究重点也从平原区[12]向复杂山区[14−15,25]转变。
综上,既有的直接法以模型为中心,通过有限样本统计回归模型参数的方法,无法准确反映客观规律且不具有普适性;现有的智能选线技术只能间接提升主要技术标准决策效率,难以实现主要技术标准全面、科学、高效智能优选,主要技术标准优选已成为制约铁路决策的技术瓶颈难题。因此,亟需一种人因失误少、决策效率高的方法实现主要技术标准的智能优选。
近年来,快速发展的大数据、机器学习技术为发掘多维环境因素与主要技术标准之间的潜在规律提供了新的解决思路。本文提出了基于并行多任务深度学习的铁路主要技术标准优选新方法。
1 总体思路
现代的机器学习方法已经在数据挖掘方面进入了商用阶段。尤其是深度学习方法,通过模拟人脑神经元连接方式建立深层神经网络,经过海量数据学习,使其具备模拟人脑机制解释数据的能力。目前,在语音识别[16−17],智能翻译[18]、图像识别[19−20]问题的求解上取得了巨大成功。谷歌DEEP-MIND团队2016年基于深度学习研发的围棋程序Alpha Go[21],微软研究院研发的图像识别程序[22]甚至超越了人类水平。
受深度学习在图像特征识别方面成功应用的启发,本研究提出一种新思路:将影响技术标准决策的多维环境因素表征为多通道特征图像,以这些图像为样本,主要技术标准值为标签,建立深度学习网络模型,通过对图像特征的识别,认知多维环境因素-主要技术标准之间的潜在规律,建立多维环境因素到主要技术标准的映射关系,实现主要技术标准的智能优选。主要需解决:深度学习样本的生成和深度学习网络模型构建两大关键问题。
2 多模态信息的网络接入方法
考虑到输入端的多维环境和输出端的主要技术标准值较多,无法一次性完全解决其映射规律的揭示难题,本文重点选取了部分主要因素开展研究。输入端多维环境包括:地形条件、运输需求和路网中的作用。输出端的主要技术标准包括限制坡度、设计速度、最小曲线半径、到发线有效长、机车类型、牵引质量。
与其他深度卷积神经网络处理单模态输入信息不同,本研究中输入端既有连续分布的地形,也有数值型的运量,还有枚举型的路网中的作用。为此,本文将连续分布的地形裁剪为固定大小的图像,通过卷积神经网络转化为数值型数据,再将枚举型路网中的作用通过编码转化为数值型数据,最后与数值型运量输入融合,最终形成单模态输入信息,接入深度学习网络。总体流程如图1所示。

图1 混合模态学习样本生成Fig.1 Hybrid modal learning sample generation
针对地形,本文首先将地形数据转换为数字高程模型(DEM);然后依据DEM 生成如图2 所示的2个灰度图像,即高程图和坡度图;然后将高程图和坡度图合成为双通道图像;再通过卷积神经网络提取图像特征,最后将特征图展开为一维向量,并映射为反映地形条件的数值。
运输需求通常由年客货运量预测得到,是数值型数据,可以直接作为深度神经网络的输入。路网中的作用按线路作用分为干线和支线2类,属于枚举型数据,可分别编码为1和0。
最后,将上述代表线路基本信息的3个数值型数据融合成数值向量,作为深度学习的样本输入。而输出端6项待优选的主要技术标准则可全部用数值表示,由人工进行标注。在此基础上,本文将建立深度卷积神经网络挖掘线路基本信息与主要技术标准之间的映射规律。
3 并行多任务深度学习网络模型构建
通常的深度学习模型输出端为单一因素,或者是相互独立的多维因素,而主要技术标准决策输出端各标准是相互关联的。如何在网络训练过程中考虑各标准之间的关联是基于深度学习铁路主要技术标准优选中另一个关键问题。
3.1 深度学习网络模型结构
多任务学习是一种通过利用相关任务训练信号中有价值的信息来提升模型泛化能力的方法[23]。在深度学习中,神经网络可以通过设置共享层引入多任务学习机制,可以看出该模型适于主要技术标准决策。然而,在铁路主要技术标准优选问题中,如何在各个标准决策分支间设置共享层,即采用怎样的多任务神经网络结构能够更好地考虑标准之间的耦合关联关系是一个值得探索的问题。
多任务深度学习网络整体由卷积神经网络和全连接神经网络2 部分构成,网络结构概览如图3所示。
其中,卷积神经网络能够提取地形图的特征并将图像数据转化为数值数据,全连接神经网络则利用多任务学习机制更好地挖掘输入与多任务输出之间的潜在规律。本研究基于ALEXNET[24]建立了如图4所示的面向主要技术标准决策的卷积神经网络结构。

图4 并行多任务基准模型的卷积神经网络部分Fig.4 Convolutional neural network part of parallel multitask benchmark model
基准模型的全连接神经网络部分采用并行多任务网络形式(如图5),具体网络参数参照卷积神经网络部分的全连接层确定。全连接神经网络部分首先采用融合层将表征地形条件、运输需求和路网中的作用的数值数据融合为长度为3的一维向量;然后设置一个包含2个全连接层的全连接模块共享6项主要技术标准决策的训练信号,神经元数目均为512;最后每项主要技术标准决策分支从共享层中独立出来,各自包含与共享层相同的全连接模块,用于学习各项任务所独有的特征。
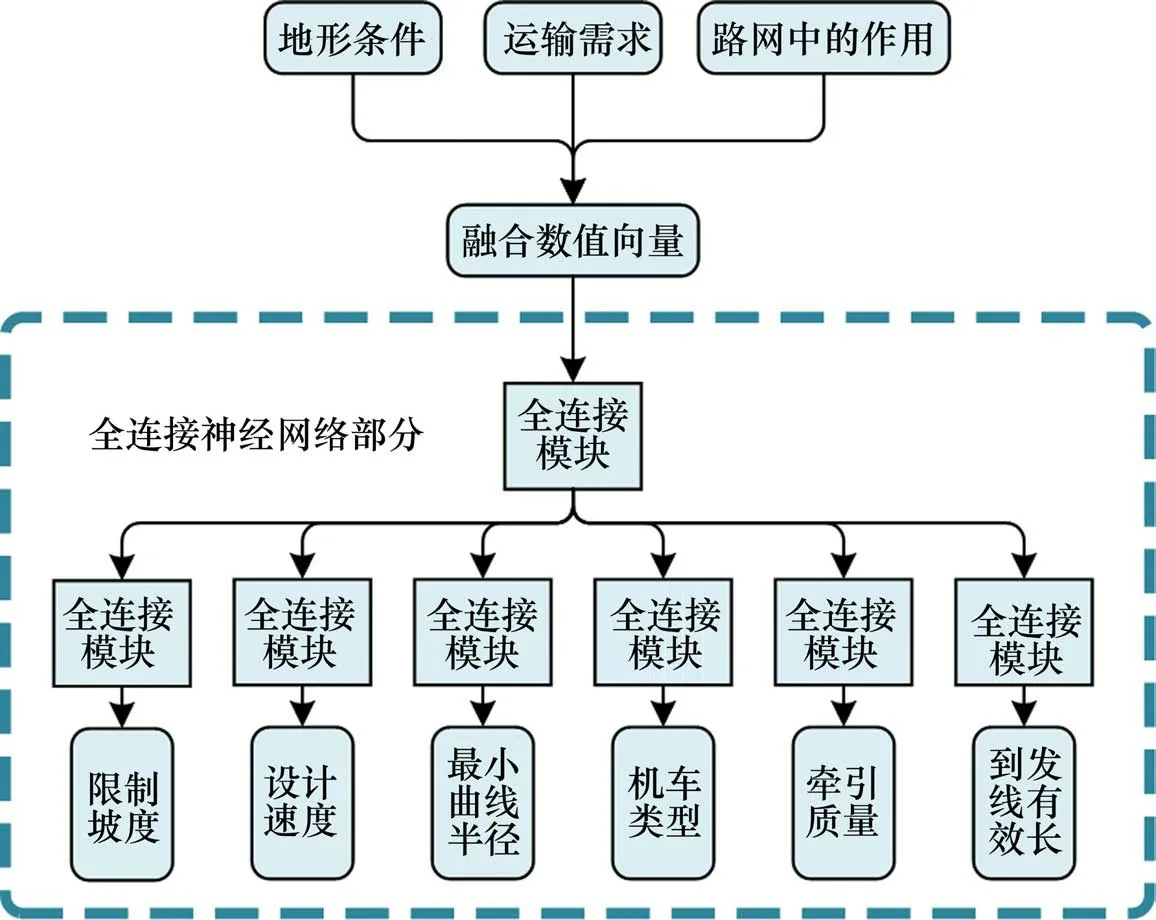
图5 并行多任务基准模型的全连接网络部分Fig.5 Fully connected network part of the parallel multitasking benchmark model
3.2 深度学习网络模型参数确定
首先确定损失函数,以及训练集和验证集的损失函数曲线。然后需要通过调节关键的网络参数提升并行多任务网络的性能。卷积层和全连接层是并行多任务网络的主要组成部分,卷积层层数、卷积核数量、全连接层层数和包含的神经元数目与网络性能有着密切的关系。本文通过对比实验确定上述4种网络参数。为了简化网络参数调节过程,本研究假设卷积层有着相同的卷积核数量,相邻全连接层组成全连接模块,全连接模块具有相同的层数,每层具有相同的神经元数量。
1) 损失函数由于工程实际中各项标准是从多个离散值中选取,因此,将主要技术标准优选问题视为多分类问题,并选定多分类交叉熵函数作为每项标准的损失函数形式。为了综合评价网络输出的主要技术标准组合与人工决策结果的接近程度,将各项标准的目标函数进行加权求和,构建了铁路主要技术标准优选的损失函数如式(1)和式(2)所示。

其中:L为神经网络的总损失函数;Li为各项标准的损失函数;wi为各项标准损失函数在总损失函数中的权重;Ni为各项标准中的分类数量;yij=[yi1,yi2,…,yiNi]是第i项标准中第j个标签,yij= 1,否则,yik= 0(k≠j);pij=[pi1,pi2,…,piNi]是网络对样本归属于第i项标准中各个分类的概率预测。
2) 训练集和验证集的损失函数曲线根据损失函数定义和试验训练,训练集总损失在第48 步达到最小值0.547 7,验证集总损失在第43 步达到最小值0.537 1,如图6所示(详见第4节试验部分)。
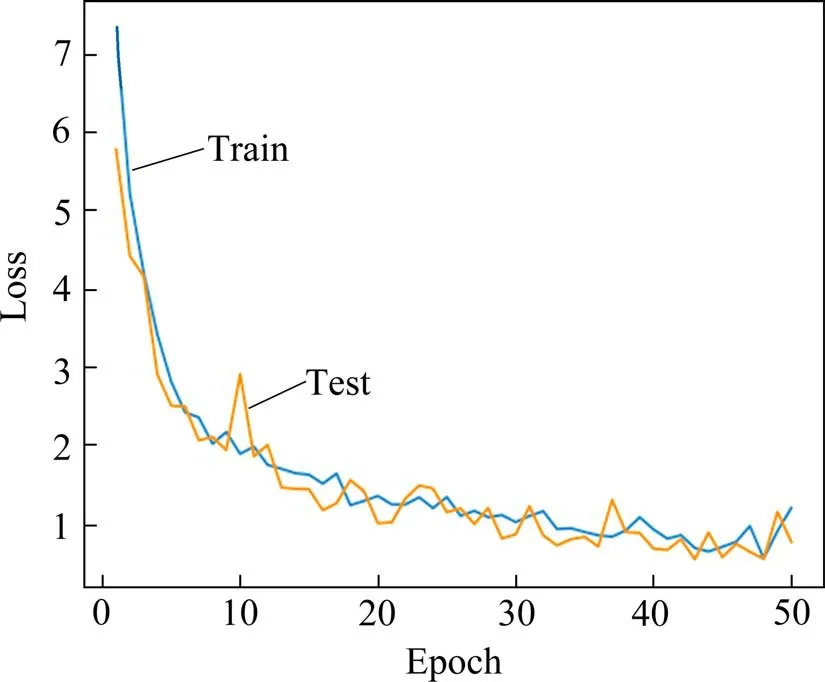
图6 训练集和验证集的损失函数曲线对比Fig.6 Comparison diagram of loss function curves of training set and verification set
3) 卷积层层数一般来说,卷积层越深,网络的表达能力越强,有助于提高网络性能。但是卷积和池化操作会压缩特征图尺寸,过深的卷积层会丢失较多的特征图信息,而过浅的卷积层会因为特征图尺寸过大而降低训练效率。本研究中输入的地形图尺寸为333×333,卷积层为2 层时,特征图尺寸为157×157,展平为一维向量后长度是24 649,连接全连接层会占用过多的计算资源而影响训练效率;卷积层为6 时,特征图尺寸为3×3,特征图信息被过度压缩。因此,本研究分别取3,4和5作为卷积层层数,其他网络参数同基准模型,在相同数据集和训练参数条件下进行对比实验,结果如下:
通过图7 可知,具有5 个卷积层的网络决策准确率显著高于具有2个,因此卷积层取5层。

图7 卷积层层数对网络准确率的影响Fig.7 Effect of the number of convolutional layers on the accuracy of the network
4) 卷积核数量卷积核数量即为卷积层中提取到的特征图数量,目前大多数研究中的卷积核数量通过实验确定。一般卷积核数量为2n个,本研究中地形特征没有特别复杂的模式,因此分别取神经网络的卷积核数量为8,16,32 个,设置5 个卷积层,其他网络参数同基准模型,观察卷积核数量对网络性能的影响。
从图8 可以看出,采用8 个卷积核能让网络有更好的性能表现,因此卷积核数量取8。
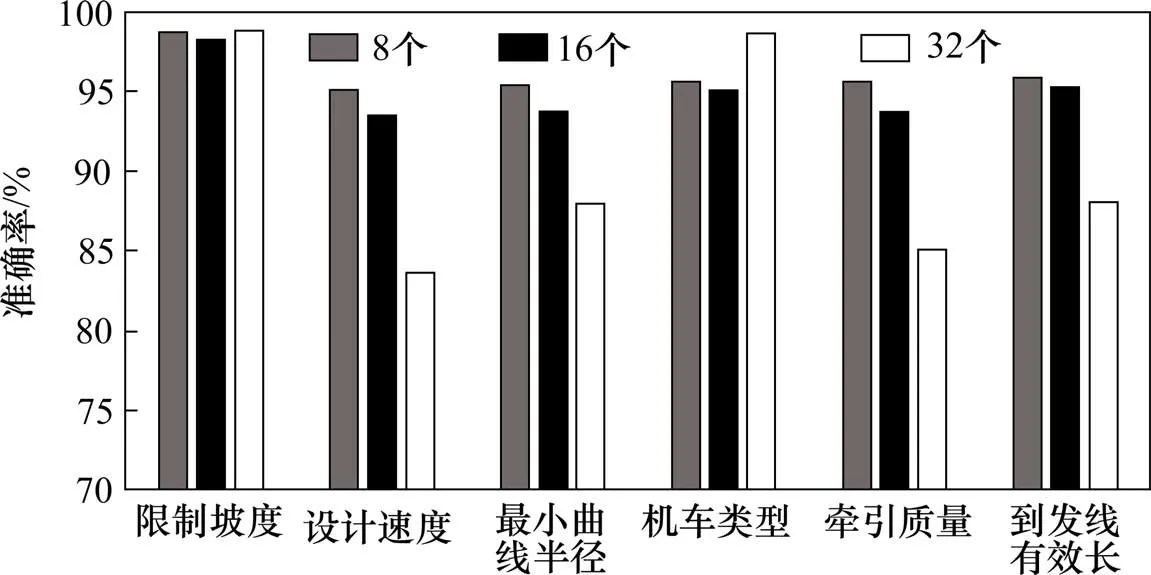
图8 卷积核数量对网络准确率的影响Fig.8 Effect of the number of convolution kernels on the accuracy of networks
5) 全连接层层数通常深层的全连接网络具有更强的表达能力,但是过深的网络可能会导致网络训练困难,引起性能退化。由于并行多任务网络中最多有3个全连接模块首尾相连,本研究分别取1,2 和3 作为全连接模块中的网络层数,即总全连接层分别为3,6和9层,设置5个卷积层,每层8个卷积核,其他网络参数同基准模型,试验结果如下:
从图9 可看出,全连接模块的层数取2 时即可以提升网络的表达能力,因此本研究取全连接模块的层数为2。
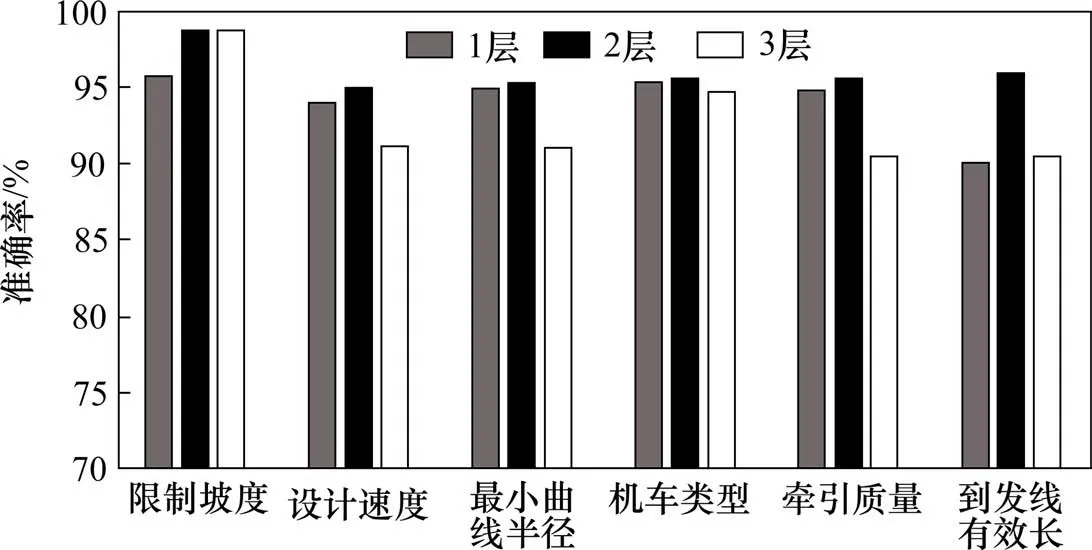
图9 全连接层层数对网络准确率的影响Fig.9 Effect of the number of fully connected layers on the accuracy of network
6) 全连接层神经元数目在全连接层中,神经元数目越多,网络自由度越高,能够拟合更加复杂的规律,但过于复杂的模型可能会导致实验出现过拟合。为了避免模型过于复杂以至于出现过拟合的现象,在AlexNet 的基础上(全连接层有4 096 个神经元)减少了全连接层的神经元数目。本研究分别将全连接层的神经元数目设置为128,256,512 和1 024,卷积层层数、卷积核数量、全连接模块中网络层数分别取5,8 和2,试验结果如下:
实验结果表明,全连接层采用512 个神经元时,网络性能最好,因此,多任务网络中神经元数目取512个。
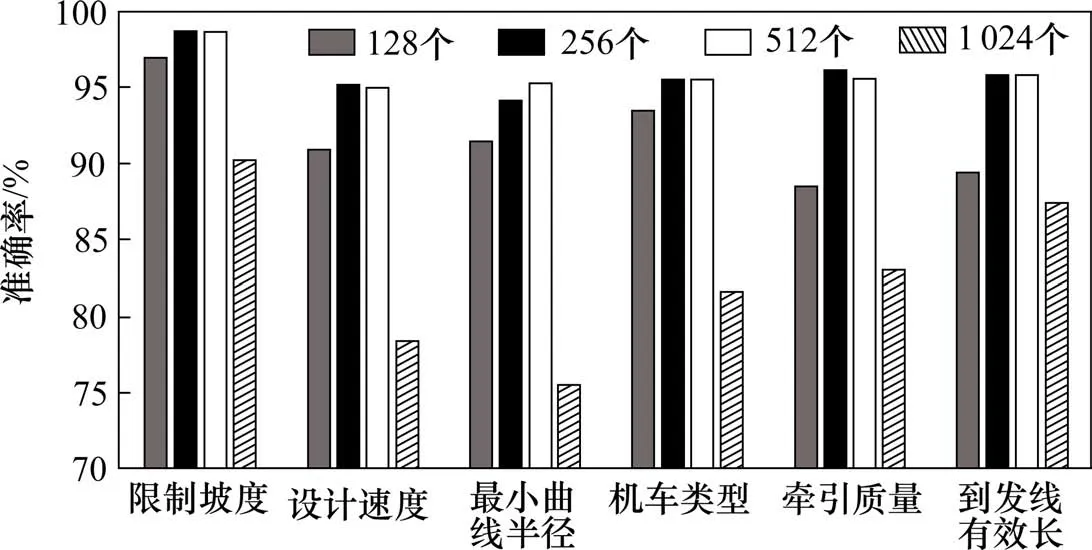
图10 全连接层神经元数目对网络准确率的影响Fig.10 Effect of the number of neurons in the full connection layer on the accuracy of the network
最终,确定并行多任务学习的结构参数为5个卷积层,各有8个卷积核,每个全连接网络模块包含2个全连接层,每层包含512个神经元。
4 实例分析
本研究从各大铁路设计单位,收集了包含32条铁路共5 736 km 线路数据。地形数据来源于地理空间数据云(http://www.gscloud.cn/),数据类型为DEM,地形图分辨率为30 m。在32 条铁路中,干线与支线比例为26:6。由于神经网络只能处理固定大小的地形图,而每个铁路区间的地形图大小不一,因此本文将每个铁路区间的地形图裁剪为若干尺寸为333×333 像素,即9.99 km×9.99 km 的局部地形图,每个局部地形图和线路的运输需求、在路网中的作用及其6项主要技术标准组成一个案例。因此1个铁路区间可以产生多个案例,最终32个铁路区间裁剪出2 624了个案例样本。
每个案例样本输入包括地形图、运输需求和路网中的作用,所有输入在进入网络前都进行了归一化处理。对应的标签包括设计速度、限制坡度、最小曲线半径、机车类型、牵引质量和到发线有效长6项标准。
基于谷歌深度学习TensorFlow 框架,实验中训练集和验证集的比例为6:4,训练轮数为50。网络采用Adam 算法进行批量训练,批大小为16,学习率为3×10−4。深度学习网络优选的主要技术标准与人工决策对比,准确率达到96.88%(限制坡度)、81.25%( 设 计 速 度)、 87.5%( 最 小 曲 线 半 径)、93.75%(机车类型)、84.38%(牵引质量)、84.38%(到发线有效长)。其中,人工决策结果与网络推荐标准的对比如表1所示。

表1 深度学习网络优选的主要技术标准与人工决策对比Table 1 Comparison table of main technical standards between deep learning network and manual decision making
实例验证,本研究提出的基于并行多任务深度学习的铁路主要技术标准优选方法具有较好的效果,可为新建铁路项目主要技术标准的优选提供有效的技术决策支持。
5 结论
铁路主要技术标准优选的本质是建立运量需求、自然条件、装备水平等多维环境因素到限制坡度、最小曲线半径、牵引种类、机车类型等主要技术标准之间的潜在映射关系。现有的智能选线技术只能间接提升主要技术标准决策效率,无法从根本上解决该问题。既有的直接法以模型为中心,通过有限样本统计回归模型参数的方法,无法准确反映客观规律且不具有普适性。对此,本研究基于最新的机器学习方法,提出了基于并行多任务深度学习的铁路主要技术标准优选方法,具有以下特点:
1) 将连续分布的地形进行分割并转换为多通道图像;再建立卷积神经网络提取特征转化为数值数据;然后与枚举型铁路性质、数值型铁路运量融合;最终形成适于深度学习的输入参数,有效解决了主要技术标准深度学习多模态输入端参数的构建问题。
2) 针对主要技术标准优选的输出端各标准之间相互关联的问题,建立了适于主要技术标准优选的并行多任务神经网络结构,并通过大量实验,确定了网络模型中的关键参数。
3) 经5 736 km 既有线路实例验证,主要技术标准决策的平均准确率可达88%以上,证明了本文方法的有效性。
