针对侦察低截获雷达的型号识别技术研究
2021-10-20张译方邱光辉张生杰徐才进
徐 晶 张译方 邱光辉 张生杰 徐才进
(西南电子设备研究所 成都 610036)
0 引言
雷达辐射源识别是电子侦察的重要环节,在信号分选基础上,对侦收的雷达参数进行分析,完成对雷达型号甚至个体的准确判识,为作战筹划、战术决策等提供重要的情报支撑[1]。
近年来,随着雷达技术体制不断升级更新,现代作战空间呈现电磁信号数量繁多、密级重叠、动态交叠、样式变化快的特点。大数据人工智能技术的发展,为雷达辐射源识别带来了新的思路:基于大量侦收数据,通过机器学习训练方法,自动完成对雷达特征的提取及识别空间的构建,以此解决对新体制、多功能雷达的准确判识。常见的智能化雷达辐射源识别有基于机器学习的识别方法[1]及基于神经网络的识别方法[3-4]。另一方面,受实战环境、战术使用及技术条件的限制,雷达辐射源识别所面临的信号是一种“小样本空间”[5],对应的数据存在完备性不足、连续性差、类别不均衡的缺点,基于数据驱动的人工智能识别方法存在对训练数据过拟合、泛化能力差、鲁棒性不足的问题,造成人工智能技术无法良好适应于电子战系统和装备的应用。
为解决上述问题,本文提出针对侦察低截获雷达的型号识别技术,具体地,提出基于K-means和组合采样的样本扩展技术,实现对小样本类别数据的扩展,达到不同类别数据的样本均衡,以此解决基于机器学习的雷达型号识别技术对大样本数据过拟合的问题,提高模型的泛化能力,提升对侦察低截获雷达的型号识别准确度。
1 识别框架设计
本文提出一种针对低侦察目标的雷达型号识别技术框架,如图1所示。在已有智能处理识别基础上,增加基于K-means和组合采样的样本均衡技术:首先,运用K-means算法对各型号样本进行聚小类处理;进一步,对于样本数量少的小类,运用SMOTE方法进行样本扩充,对于样本数量过多的小类,运用随机采样方法进行样本抽样。以此形成数量充足、分布均衡的样本数据,达到对机器学习算法的充分训练,形成泛化能力更强、适应性更广的智能识别模型,解决运用人工智能方法对侦察低截获雷达型号识别率低的问题,提升电子战系统或装备对威胁电子目标的识别效果。

图1 针对侦察低截获雷达的型号识别框架
2 基于组合样本采样的样本扩展
受限于战场环境和侦收条件,所收集的雷达型号样本数据往往存在类别不均衡的现象。因此,雷达型号识别问题属于不平衡分类问题,导致运用基于机器学习方法的识别结果向样本数量多的类别倾斜,而忽略样本少的类别,造成整体分类效果不理想。
针对上述问题,提出一种基于K-means和组合采样的样本均衡方法,用以对雷达型号样本库进行均衡处理,以此降低由于样本不均衡造成识别准确度低的问题,以二分类为例,所提出的技术识别流程如图2所示。
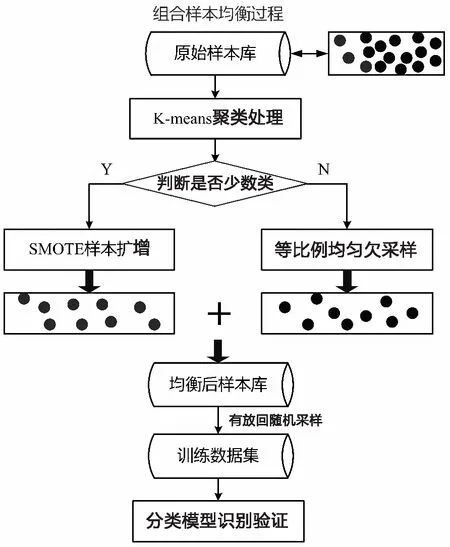
图2 基于组合样本采样的识别流程图
2.1 SMOTE基本原理
SMOTE是一种被广泛应用于不平衡分类问题的数据预处理方法[6]。SMOTE基本思想是在每个少数类样本和K个类内近邻样本之间线性插值,随机地生成一个新样本。因为合成的样本是两个样本间的随机值,所以能有效增加少数类样本多样性,解决了由随机过采样导致的过拟合问题。SMOTE原理如图3所示。
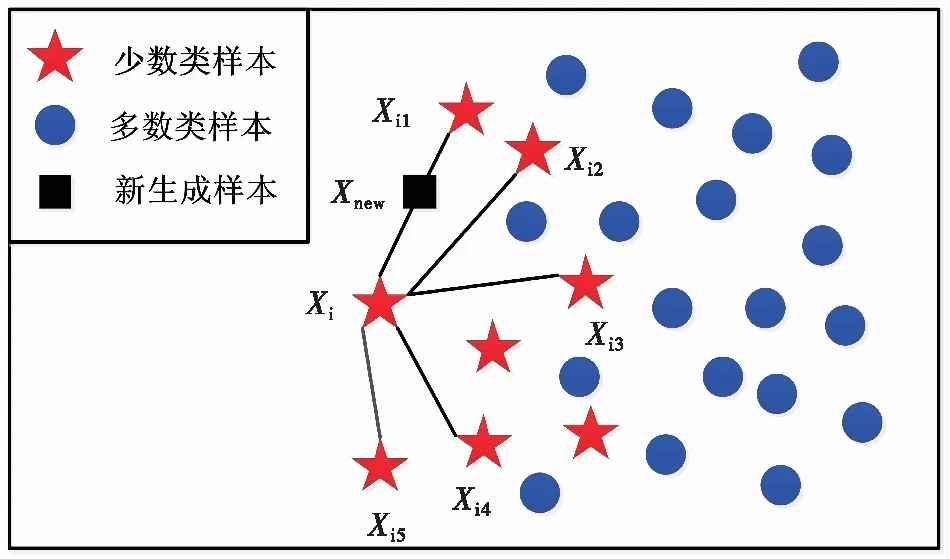
图3 SMOTE算法说明图
SMOTE算法运用K-NN算法计算近邻,K-NN分类算法是数据挖掘领域一种非常成熟而典型的分类方法,具有思路简单、易于实现的优点,同时往往具有较高的分类准确率。算法基本思路是给定含有类别标签的标记样本集,对于无标签的待测样本,计算其与所有已标记样本集中所有样本的距离,选择聚类最近的K个样本作为近邻,然后根据这K个近邻样本的类别标签,采用少数服从多数的原则对待测样本进行类别标注。
SMOTE的基本步骤为:
首先,利用K-NN算法,在类内寻找少数类样本Xi的K个近邻样本,作为合成新样本的根样本,样本间的相似性度量用欧氏距离来表示为
(1)
然后,从K个根样本中随机选择一个作为合成样本的辅助样本,重复n次,在Xi和每个辅助样本Xij之间进行线性插值,最终得到n个新合成样本。线性插值可表示为
Xnew=Xi+(Xi-Xij)·γ
(2)
其中,Xi是原有样本;Xij是近邻样本,j=1,2,…,K;γ是[0,1]之间的随机数;Xnew是新合成的样本。
2.2 基于K-means和SMOTE的样本均衡
新体制、多功能雷达呈现模式多样、频率捷变快、参数变化多的特点。同一雷达型号的样本数据呈现离散程度高,分布不平衡的特点。如机载相控阵雷达,大部分时间工作于搜索或跟踪模式,造成我方侦收、处理形成的参数大多为上述两种模式的样本,而缺少LPI、频率分集等特殊运用模式的样本。造成同一雷达型号的样本数据呈现出类内不均衡的特点。
如果直接运用SMOTE方法对上述类内不均衡的样本进行采样,所形成的样本数据分布无法拟合真实的样本分布情况,难以全面刻画雷达型号的样本特征,造成对LPI等特殊模式下雷达的识别准确度低。直接运用SMOTE扩增造成识别错误的示意如图4所示。
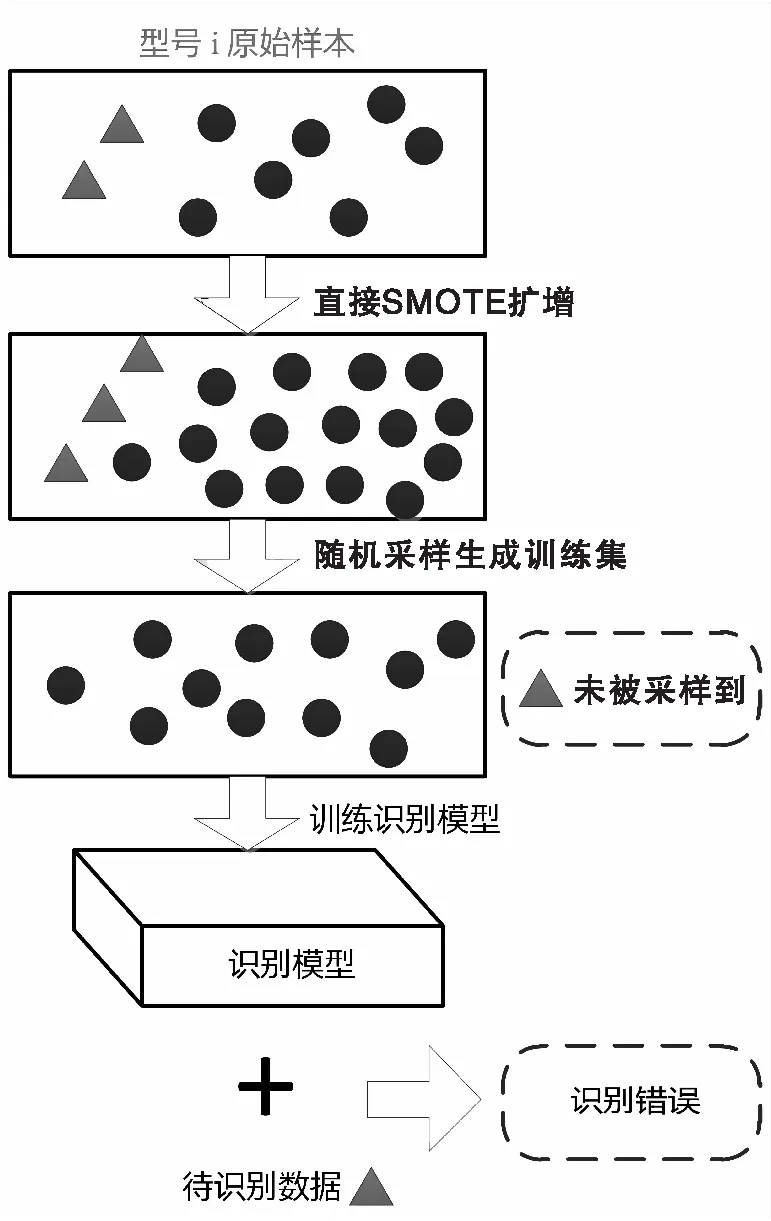
图4 类内不均衡导致识别错误示意
针对上述问题,本文提出结合K-means和SMOTE的样本均衡方法。运用K-means方法对不同类别的雷达型号进行类内的聚类,形成类内的小类划分;进一步,运用SMOTE和随机采样方法对所有小类进行均衡处理,以此形成类内、类间分布均衡的样本数据集。
K-means聚类是一种无监督学习方法,可用于分析数据的分布特性[7]。基本步骤如下:
1)选取K个初始聚类中心;
2)分别计算每个样本点到K个簇心的距离(一般为欧氏距离),找到离该点最近的簇心,将其划分到对应的簇;
3)所有样本点被划分到K个簇后,重新计算各簇中心(平均距离中心);
4)反复迭代步骤2)和3),直到达到终止条件。
为获取同一类别内样本的分布信息,利用K-means对每类样本进行聚类,使特征参数接近的样本归为统一小类。每种型号的样本可被划分为多个小类。
对于样本数量少的小类,运用SMOTE方法进行插值扩增。对于样本数量冗余的小类,运用随机不放回抽取的方法,对样本进行抽样精简。以此,形成小类间样本数据相当的均衡样本集。对小类进行处理的过程如图5所示。
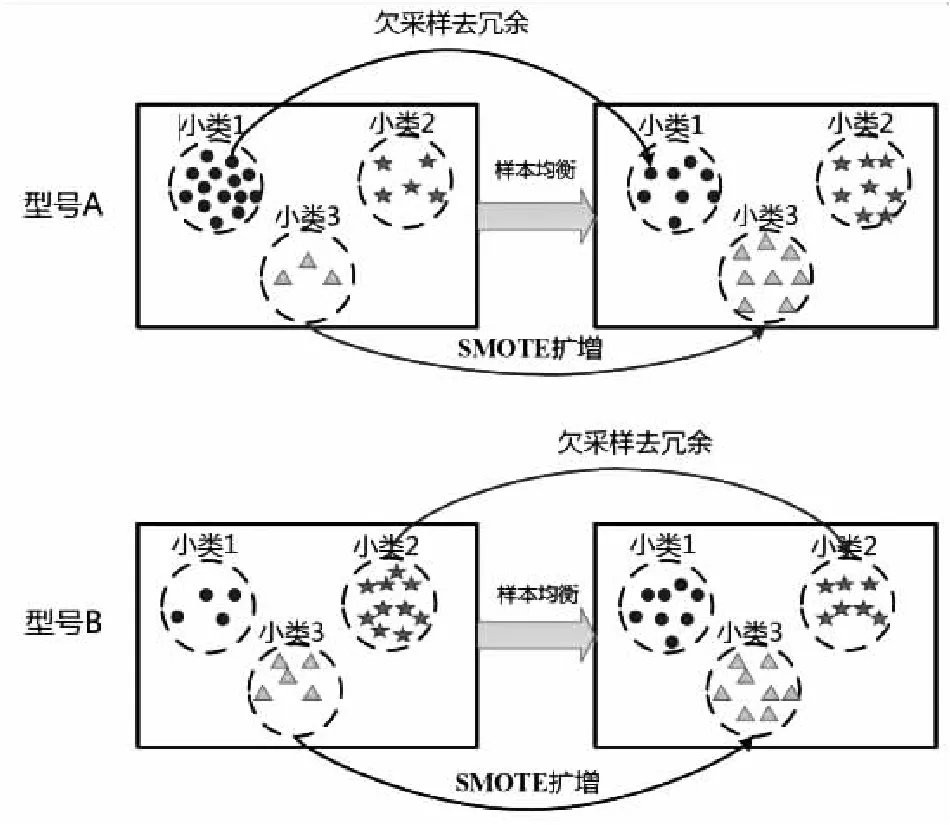
图5 样本均衡过程示意
3 仿真分析
本节运用仿真形成的7型雷达型号数据验证所提出方法的有效性。利用识别率RC评估分类效果(NC为识别正确的样本个数,NA为待识别样本总数)
(3)
本文分别运用原始样本和均衡后样本对卷积神经网络模型进行训练,并对比分析上述两种情况的识别准确度。
本文采用的卷积神经网络由三个卷积计算层(卷积层+池化层)和一个全连接层组成。网络结构示意如图6所示。
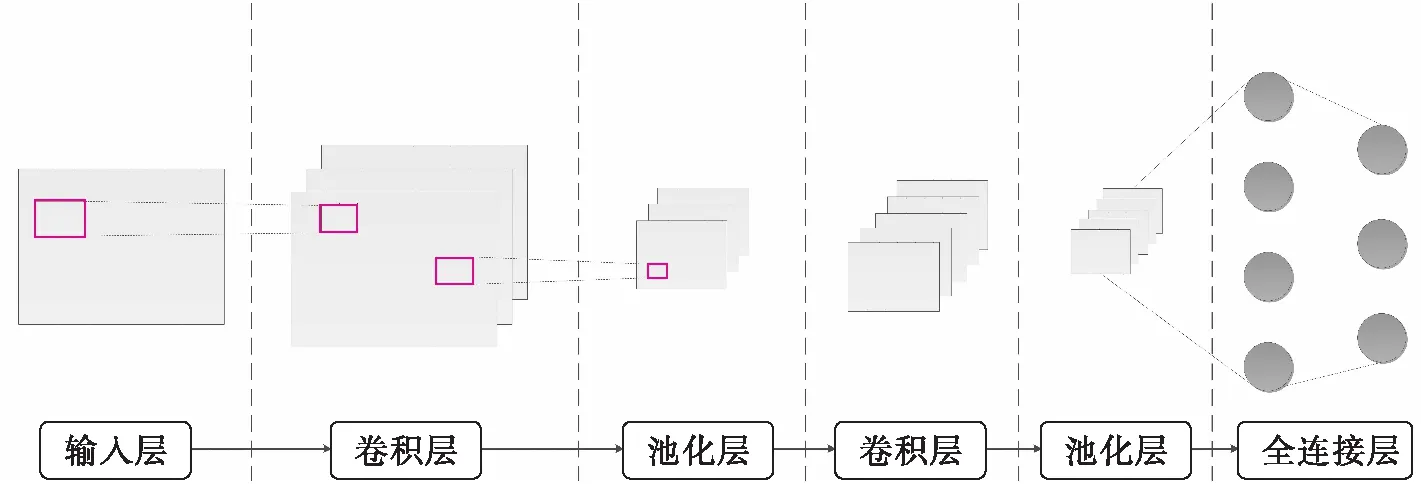
图6 本文采用的卷积神经网络示意
图7、图8分别为A、D两种型号均衡前后的样本分布图。由图可以看出,对于每一种型号,采用本文提出的样本扩展方法,能在不改变原有样本总体分布的基础上,对各参数范围内的样本进行合理扩充,既能让每个新增样本与原有样本保持相似,也能够对样本比例进行一定调整,使得各小类的样本数目更加均衡,从而确保模型具有良好的训练效果。
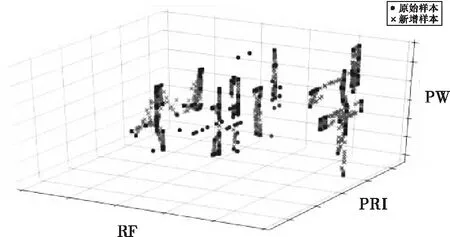
图7 型号A原始样本与均衡后样本分布图
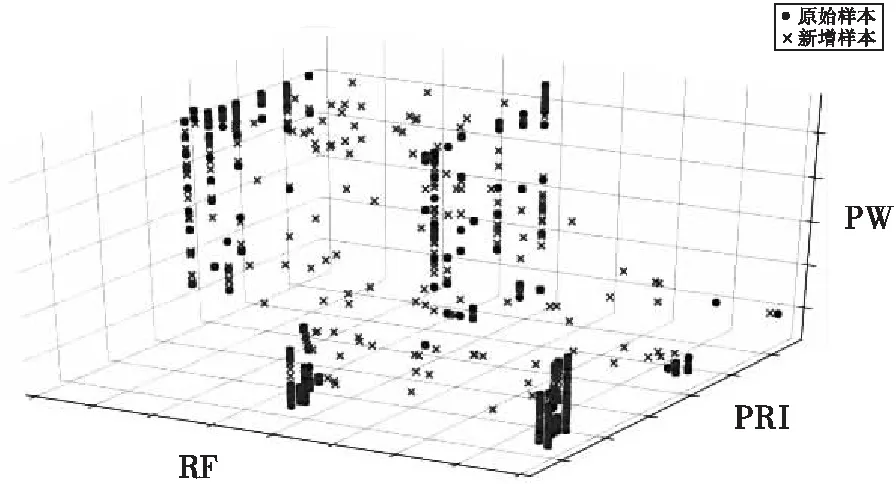
图8 型号D原始样本与均衡后样本分布图
表1为均衡前后各型号样本数量的对比情况,从表1中可看出,运用所提出方法进行样本均衡后,各型号的样本数量能够达到相同的数量级。
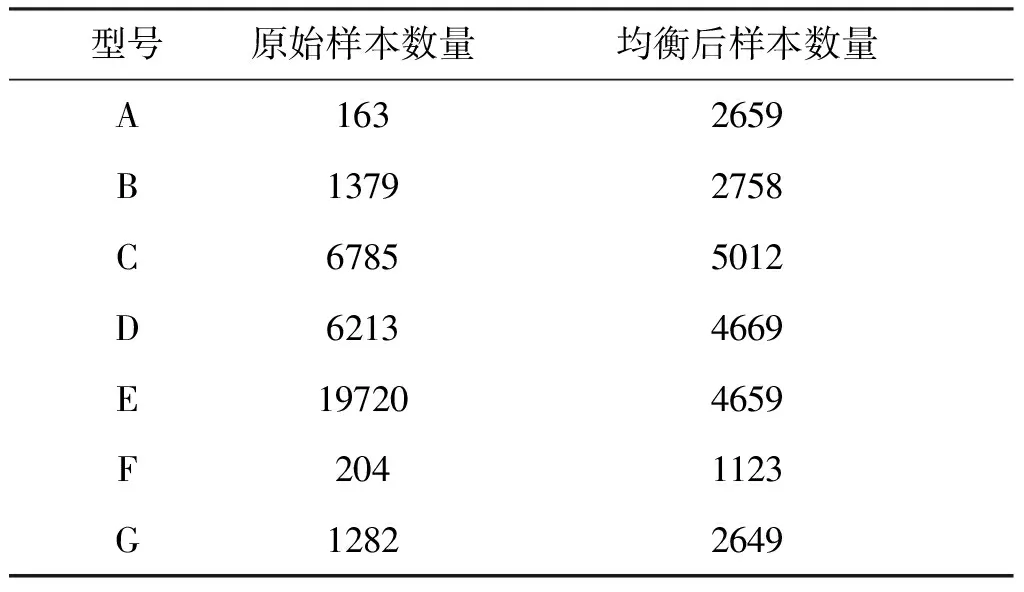
表1 各型号样本数量
为进一步说明组合样本均衡方法对识别性能提升的有效性,表2给出了样本均衡前后,卷积神经网络对不同型号的识别准确度。
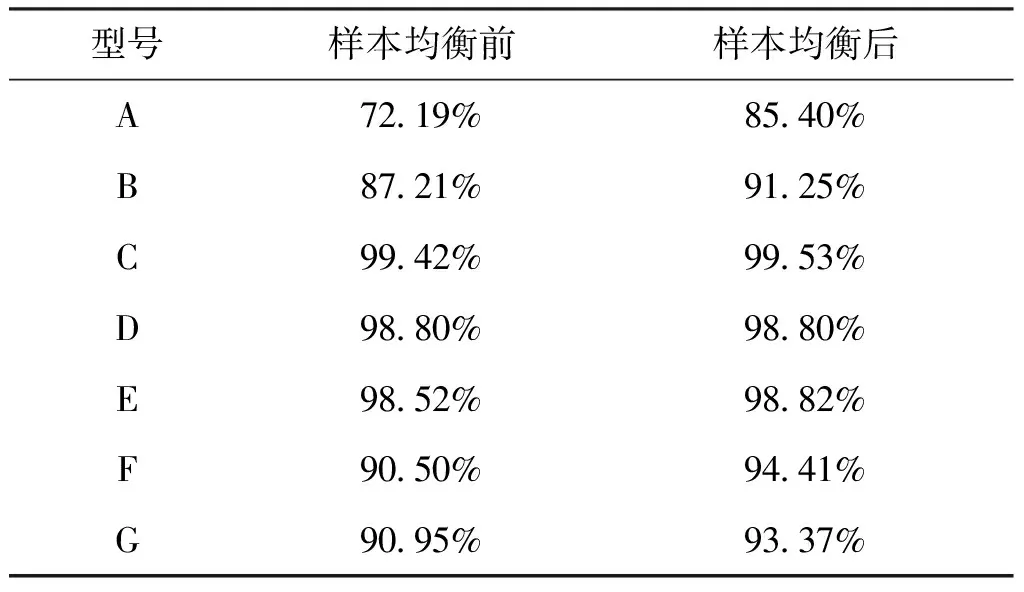
表2 不同型号的识别结果
由表2可知,低侦察型号A、B、F、G的识别准确率均得到显著提高。图9详细给出了均衡前样本和均衡后样本训练生成模型对型号A的识别结果对比图(其中0为正确识别、1为错误识别)。可得出,所提出方法能够有效提高对低侦察型号的识别准确度。
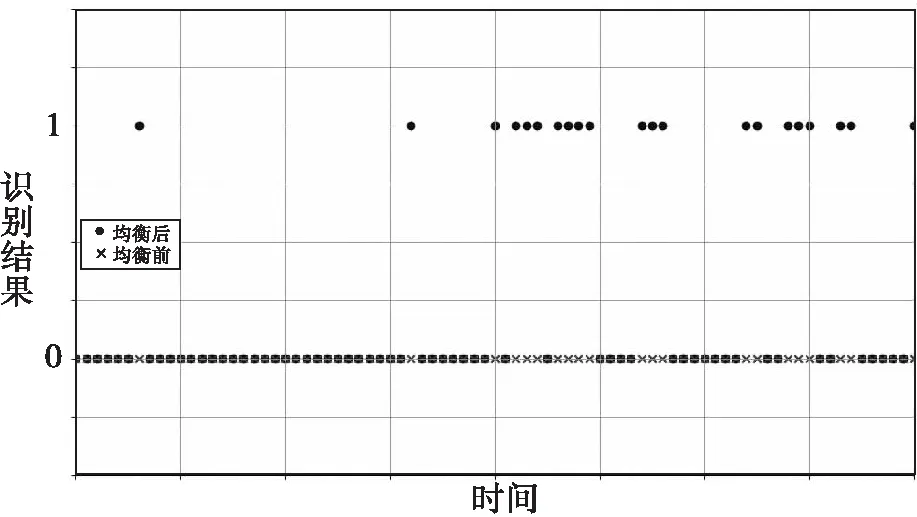
图9 型号A识别结果图
对于样本数据充足的型号C、D、E,识别准确度仍能保持在98%以上,表明对于样本充足型号,所提出方法能够保持原有的高识别准确度。
以上实验结果表明,本文提出的组合均衡方法能够有效解决样本数据不平衡的问题,改善机器学习算法对大样本过拟合情况,使得训练生成的识别模型能够同时适用于大样本和小样本场景,具备更强的泛化能力,整体提升机器学习算法对雷达型号的识别准确度。
4 结束语
本文研究并设计了一种基于K-means和组合采样的样本均衡方法:针对新体制雷达参数分布广的特点,首先提出运用K-means算法对各型号雷达样本进行聚类处理,将特征相似的样本划分为同一小类;进一步,提出了基于组合采样的样本均衡策略,对样本量较少的低侦察型号采用SMOTE扩充,对样本量充足的型号采用均匀抽样去冗余,以实现各型号样本数量的平衡。仿真结果表明,本文方法能有效增强智能识别模型的可靠性和泛化能力,明显提升了侦察低截获雷达的型号识别准确率,同时也能保持样本充足型号的高识别准确度,具有较高的工程应用价值。
