基于贝叶斯纠错的矿山地质勘测数据纠错方法
2021-10-16陈弓


摘要:为解决传统纠错方法无法完全校正错误数据组的问题,设计了一种基于贝叶斯纠错的矿山地质勘测数据纠错方法,使用贝叶斯字典设计统计勘测数据流程,通过使用贝叶斯纠错器生成候选数据集合,并在此基础上按照层次的隶属关系,设定矿山地质勘测错误数据编码规则,对数据组进行逐层编码排序。为进一步实现对错误数据序列的校正,引进了k-spectrum算法,重组错误数据序列,以此实现对勘测错误数据的有效纠错。
关键词:贝叶斯纠错;矿山;地质;勘测数据;纠错方法
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)07-0085-04
Error Correction Method of Mine Geological Survey Data Based on
Bayesian Error Correction
CHEN Gong
(Geological Information Center,East China Geological Exploration Bureau,Nonferrous Metals,Jiangsu province,
Nanjing 210000,China)
Abstract:In order to solve the problem that the traditional error correction methods can not completely correct the wrong data group,a mine geological survey data error correction method based on Bayesian error correction is designed. The Bayesian dictionary is used to design the process for counting survey data,and the candidate data set is generated by using the Bayesian error corrector,and on this basis,according to the hierarchical membership relationship,set the coding rules of mine geological survey error data,and code and sort the data groups layer by layer. In order to further achieve the correction of the error data sequence,the k-spectrum algorithm is introduced to reorganize the wrong data sequence,so as to realize the effective error correction of the survey error data.
Keywords:Bayesian error correction;mine;geology;survey data;error correction method
收稿日期:2021-03-12
0 引 言
矿山地质勘测是开采矿产资源前期的重要工作之一,只有获取大量的矿山地质勘测数据,才能确保矿产资源开采工作的安全实施。由于矿山地质结构复杂,并且不同区域的地质环境是随着地壳变迁而相应变化的,因此,地质勘测单位对矿山地质勘测工作的实施,在精准度方面提出了要求[1]。为了满足此方面的需求,相关地质勘测单位设计一种针对勘测数据的纠错方法,此方法以增强现实技术作为支撑,将所获取的勘测数据进行集成与融合,并呈现在终端计算机显示屏幕中,将从多个渠道获取的相同位置信息进行叠加,以更为真实地将矿山地质环境表现出来。在对勘测数据进行显式处理的过程中,一旦所勘测的数据存在偏差或失真问题,在终端的成像中便会清晰地显示出来。相比人工纠错数据的方式,此方式具有更高的纠错效率,并极大地简化了记忆数据处理的复杂程度。但此种纠错方法在实际应用中,需要以智能化设备作为辅助,并在生成矿山地质图像时,要求以高清的计算机显示屏幕作为支撑,否则将影响到成像的分辨率与清晰度,从而干预到地质勘测错误数据的判断。因此,在本文的研究中,引进了贝叶斯纠错器,结合贝叶斯概率计算,得到字符串最大候选结果,并通过对数据的推导,达到对勘测数据纠错的目的。
1 基于贝叶斯纠错的矿山地质勘测数据纠错方法
1.1 基于贝叶斯纠错生成候选数据集合
为了实现对矿山地质勘测数据的准确纠错,本文引进贝叶斯纠错器,生成矿山地质勘测候选数据集合[2]。在此过程中,需要获取矿山地質勘查中不同维度的数据,并将勘测的数据从计算机终端导入贝叶斯纠错器,结合贝叶斯概率计算公式,对勘测数据集合中的最高正确率进行预测,计算公式为:
(1)
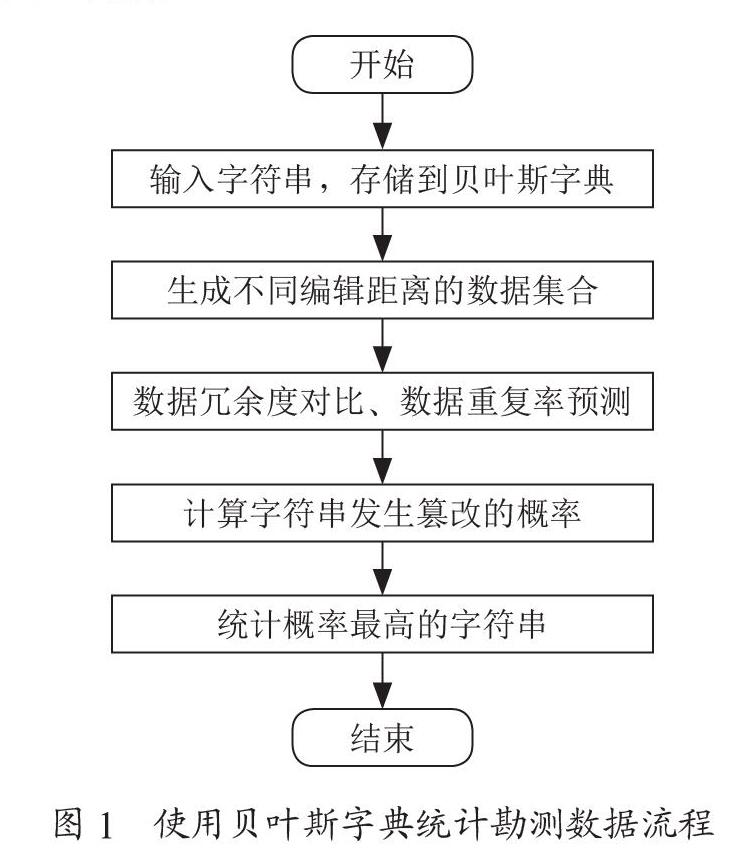
其中,P(wc|wi)表示所获取的矿山地质勘测数据集合中,数据最高正确率,wc为纠正数据,wi为前端输入的勘测数据。考虑到在前端输入的勘测数据中,可能含有大量的重复数据或冗余数据,此种数据会影响计算结果,因此需要通过贝叶斯字典对数据集合进行统计。统计过程如图1所示。
按照如图1所示的流程,对勘测数据进行初步统计,但在统计过程中,涉及对数据编辑距离的设计。因此,可将此作为数据纠错的依据,采用状态随机转变的方式,生成一个随机字符串[3]。在此过程中,对勘测的矿山地质数据进行一次编辑,可以实现字符的替换、删除、增加等操作,在编辑中每一个经过处理后的字符均可以作为候选集合中的新字符。在完成对字符串的初步处理后,打乱字符串,对其进行随机匹配,并使用贝叶斯纠错器输出最佳匹配项,将此数据项表示为argmaxlgP(wc|wi),此时最佳匹配字符串在统计集合中出现的概率,可以作为候选集合生成时贝叶斯纠错器的迭代处理次数。
在完成了对候选数据集合生成前提条件的准备之后,以不同类型的勘测数据字符串长度作为先检验概率,使用常规的噪声通道进行混淆字符串数量的统计[4]。例如,在纠错器前端输入d1→f1,后端便可能将“d1”识别为“f1”,或是将“d1→f1”识别为“f1→d1”,按照此种方式,可以得到一个编码混乱的候选数据集合。为了确保将打乱格式的勘测数据全部导入贝叶斯纠错器中,需要提前掌握勘测数据的字符串总数,并按照如图1所示的流程,在将勘测数据完全导入后,进行导入字符串的统计,对比导入后字符串总数与统计的字符串总数是否存在差异。假定前者与后者一致,此时可直接从贝叶斯终端输出混淆的数组集合。数组集合表达式为:
(2)
其中,len表示矿山地质勘测数据的字符串可编辑长度,i为数据编码;j为字符串首列字母。按照上述方式,生成候选数据集合。反之,当导入字符串总数与统计字符串总数存在差异时,需要再次对矩阵进行混淆处理,在不改变勘测数据中核心数据与权重数据的前提下,进行数组的二次处理,直到数组满足计算需求,便可按照标准输出候选数据,以此完成候选集合的生成。
1.2 设定矿山地质勘测错误数据编码规则
在完成候选数据集合的生成后,需要對勘测的数据进行编码,结合编码次序,掌握勘测数据的规范性。为满足这种需求,需要设定一个符合矿山地质勘测错误数据的编码规则[5]。在编码过程中,应当对候选集合中每个数据组的类目进行外延,细分知识层次,并严格遵循各类目对数据分的要求,将字符串进行平铺,此过程中,可允许字符串存在突出或合并的列类,并按照层次的隶属关系,进行逐层编码排序。同时,应当明确编码规则是由字符串识别编号、标识号与序列编号构成,每个不同的编号在规则中所代表的含义是不同的。例如,“W6300”表示字符串识别编号,其中“W”表示对矿山地质的勘测行为;“2020R”表示标识号,其中“2020”表示地质勘测工作实施的年限,“R”表示勘测过程中对不同区域的划分依据;“18,15,180BL”表示序列编号,其中“BL”表示对指定地质勘测区域内地质类型的划分,其中“18,15,180”可用来表示勘测点在空间中的坐标。通过上述方式,在完成对数据的编码后,可基本掌握数据集合的输出标准及规则。
在掌握矿山地质勘测错误数据输出标准后,应当明确矿山地质勘测过程中,不同文件格式信息的表达是使用字母进行描述的。因此,在设定字符串编码规则后,需要对常见的字母或符号编码规则进行编辑,具体内容如表1所示。
综合表1中提出的内容,对矿山地质勘测错误数据进行编码,此过程可参照如图2所示的流程进行。
按照表1中提出的编码规则,输出图2终端导出的字符串序列码,以此作为矿山地质勘测数据结果。
1.3 基于k-spectrum算法重组错误数据序列
通过前期的相关研究,已完成了对矿山地质勘测数据的基本处理,为校正数据序列,利用k-spectrum算法对数据进行重组。在此过程中,考虑到原始数据集合与生成的候选数组集合,其中含有质量参差不齐的reads,因此,需要在纠错前,对数据进行前端预处理,即过滤数据并调整其格式,使数据在终端的输出更加规范化。在预处理过程中,应明确k-spectrum算法中k表示为可信度系数,是指数据集合中不同数据集的规范化操作可能性。在此基础上,在计算机终端导入矿山地质图示,将前端的数组按照编码顺序,依次输入计算机中,根据处理的图像,对勘测区域进行切割[6]。切割过程中,按照碱基序列,将其划分为多个k-mers,其中mers的字符串长度决定了重组序列的长度,k值的大小表示数组的复杂度。而重组错误数据序列的过程,便是求取一个针对k-mers中k的最优值。为了区分冗余数据类型,可设定一个基因值G,G也可以表示勘测数据中的核心值,即数组中不发生变化的数值,为了实现对k最优解的计算,应首先对数组中的单次勘测周期进行描述。表达式为:
(3)
其中,t为矿山地质单次数据勘测周期,e为最佳阈值范围。将e的实际值代入计算过程中,并根据错误可能发生的概率性,将t代入k的计算公式中,计算过程为:
(4)
其中,G为矿山地质勘测数组中的基因值,ρ为散列表。按照上述计算公式,输入k值,得到勘测数组中的可信度数据集合。删除可信度较低的数据值,按照逻辑层数据编码规则,对可信度较低的数组与矿山地质成像中的信息进行光学描述。为了确保数组对应的数组满足勘测需求,可将对应的数组与图像进行计算机终端成像放大处理,并在Web端检查数组序列与图像是否匹配,对于不匹配的数据,可通过旋转、重叠、缩放等处理方式进行校正。通过这种方式完成对矿山地质勘测数据的纠错。
2 实验论证分析
上文结合贝叶斯纠错器的使用,设计了一种针对矿山地质勘测数据的纠错方法,在完成对方法的设计后,本章介绍了基于ASEC算法的纠错方法,将此方法与本文设计的方法进行对比,并希望通过此次实验可以证明本文所设计方法的纠错结果更为准确。
为确保实验结果的真实可靠,选择某地质勘测工作单位近三个月的地质勘测数据,作为此次实验的数据组。对实验数据的描述如表2所示。
在完成对矿山地质勘测错误数组的描述后,将表1提出的错误数组与正确数组进行打乱处理,控制输入端的数组数量为50 000.0 bit。将数据集合上传到终端计算机设备,在相同的操作环境下,分别使用本文设计的方法与传统方法对数据集合中的错误数据组进行纠错处理。并根据终端输出的错误数组与纠错结果,对方法进行可行性评估,实验结果如表3所示。
综合表3的结果可知,两种纠错方法均可以实现对错误数组的识别,但基于ASEC算法的纠错方法,在校正错误数组时,仅能校正部分错误数组,无法完全校正错误数据组,而本文设计的纠错方法在进行错误数组纠错时,可以实现对所有错误数组的准确校正。
3 结 论
本文从生成候选数据集合、设定错误数据编码规则、重组错误数据序列三个方面,对基于贝叶斯纠错的矿山地质勘测数据纠错方法展开设计,并通过对比实验证明,本文设计的纠错方法可以实现对所有错误数组的准确校正,而传统方法仅能实现对错误数组的校正。
参考文献:
[1] 文丰,雷武伟,刘东海.基于CY7B923/933的可纠错HOTLink数据传输方案设计 [J].兵器装备工程学报,2020,41(2):134-138.
[2] 李贵良,欧阳琴,唐标,等.基于反馈纠错机制的数据远程传输优化技术研究 [J].信息技术,2021(5):141-146+152.
[3] 肖文磊,邹捷,冯江伟,等.基于贝叶斯纠错的AR辅助飞机装配数据纠错方法 [J].航空制造技术,2020,63(6):14-22.
[4] 景文芳.嵌入式光网络传输数据自动纠错系统设计 [J].激光杂志,2020,41(1):181-184.
[5] 郑穆,罗铁威.一种用于光盘数据存储的冗余恢复码纠错方法 [J].光电工程,2019,46(3):110-117.
[6] 寇马可,钟升,唐磊.一种基于小波变换的数据位迭代纠错算法设计与Matlab实现 [J].微电子学与计算机,2019,36(6):60-63.
作者简介:陈弓(1988—),男,汉族,江苏南京人,工程师,学士,研究方向:测绘、地理信息系统、信息化。
