基于Transformer目标检测研究综述
2021-10-16尹航范文婷
尹航 范文婷
摘要:目标检测是计算机视觉领域三大任务之一,同时也是计算机视觉领域内一个最基本和具有挑战性的热点课题,近一年来基于Transformer的目标检测算法研究引发热潮。简述Transformer框架在目标检测领域的研究状况,介绍了其基本原理、常用数据集和常用评价方法,并用多种公共数据集对不同算法进行对比以分析其优缺点,在综述研究基础上,结合行业应用对基于Transformer的目标检测进行总结与展望。
关键词:目标检测;Transformer;计算机视觉;深度学习
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2021)07-0014-04
A Summary of Research on Target Detection Based on Transformer
YIN Hang,FAN Wenting
(College of Information Science and Technology,Zhongkai University of Agriculture and Engineering,Guangzhou 510225,China)
Abstract:Target detection is one of the three major tasks in the field of computer vision. At the same time,it is also a basic and challenging hot topic in the field of computer vision. In almost a year,the research of object detection algorithms based on Transformer has caused a boom. This paper sketches the research status of Transformer framework in the field of target detection,introduces its basic principle,common data sets and common evaluation methods,and compares different algorithms with several public data sets,so as to analyze their advantages and disadvantages. On the basis of summarizing the research,also combined the industry application,this paper summarizes and prospects of the object detection based on Transformer.
Keywords:target detection;Transformer;computer vision;deep learning
收稿日期:2021-02-26
基金项目:广东省自然科学基金面上项目(2021A1515011605)
0 引 言
目标检测是计算机视觉领域的核心任务,是实现目标跟踪、行为识别的基础,目前主流基于卷积神经网络的目标检测算法分为一阶段和两阶段类型。由于Transformer[1]框架在自然语言处理(NLP)领域取得巨大成功,研究者尝试将其迁移到计算机视觉领域。
2018年,Parmar首次将Transformer应用于图像生成,提出Image Transformer模型[2]。2020年,Carion等人将CNN与Transformer结合,提出一个完备的端到端的DETR目标检测框架[3],首次将Transformer应用到目标检测。随后的一年内,类似算法不断涌现:Zhu[4]等人提出借鉴可变卷积神经网络的Deformable DETR模型;Zheng[5]等人提出降低自我注意模块计算复杂度的ACT算法;谷歌提出ViT模型[6]并应用于图像分类。图1为近年来基于Transformer目标检测模型。
1 Transformer 模型
Transformer模型也称为基于注意力机制模型,多应用于自然语言处理领域,模型包括Encoder和Decoder两部分,结构如图2所示。
其中Encoder编码器由6个具有相同结构的层组成,每层包含2个子层:多头注意力和前馈网络,每组子层进行残差连接,后做归一化处理。每层Encoder输出如式(1)所示:
(1)
其中,x为输入序列。
Decoder解码器与Encoder结构类似,但多一个掩码层,该层用于掩盖未预测的信息,保证每次预测结果都只基于已知信息。Decoder层的输入为Encoder的输出和上一层Decoder的输出,把Encoder层的输出作为K和V,上一层Decoder层输出作为Q,将Q、K、V输入到注意力模块进行attention操作。Transformer通过Encoder编码器对输入序列进行编码,将编码结果输入到Decoder,最后將Decoder的输出通过线性变换和一个Softmax层来预测下一个输出,此框架具有较强的语义特征提取和长距离特征捕获能力,其并行计算能力与CNN相当。如果考虑图像与文本的维度差异,将图像转换为序列,便可输入到模型进行处理,因此将Transformer迁移到计算机视觉领域是有理论依据、切实可行的。
2 常用目标检测数据集及评价方法
2.1 常用目标检测数据集
数据集是衡量和比较算法性能的共同基础[7]。常用的目标检测数据集有VOC和COCO,行人检测常用数据集有CityPersons,如表1所示。
2.2 常用目标检测评价方法
目标检测常用评价方法包括:平均精度(AP)和每秒检测图片数量(FPS),行人检测常用的评价方法为MR-2,下文进行具体说明。
2.2.1 平均精度
平均精度AP特指PR曲线下方面积,式(2)式(3)描述了精确度(Precision)与召回率(Recall)的计算公式。
(2)
(3)
在PR曲线基础上,通过计算每个召回率对应的准确率求平均,可以获得AP。
各类AP的平均mAP是最常用的指标,它表示模型在所有类别上表现的好坏,通常数值越高表示效果越好。mAP公式为:
(4)
2.2.2 FPS
每秒检测图片数量(FPS)用于衡量模型的检测速度,通常每秒处理图片数量越多,模型效果越好。
2.2.3 MR-2
Log-average miss rate(MR-2)是行人检测中最常用的度量标准,也被称为漏检率。它以对数标度计算每个图像的假阳性漏检率,范围为[0.01,100]。
3 基于Transformer目标检测模型
3.1 CNN+Transformer目标检测模型
基于CNN+Transformer目标检测模型包括DETR和Deformable DETR。
3.1.1 DETR
2020年,Carion[1]等人成功將Transformer框架应用于目标检测领域中,提出了DETR模型,将ResNet特征提取网络与Transformer结合,把检测任务分为特征提取和目标预测两个部分,整体结构如图3所示。
该模型将输入图片放入CNN特征提取网络,得到低分辨率特征图。将特征图展平成一个序列并加上空间位置编码后输入到Transformer的编码器中,得到各个物体编码后的特征,随后将其与Object Query输入到解码器中进行并行解码。与原始解码器不同,该解码器在做Multi-Head Attention时也加上了空间位置编码,在解码器中的每个输出都连上一个前馈网络用于预测目标类型和边界框。在训练时使用Hungarian loss来计算预测值与真实标注之间的损失。
该模型在COCO和自定义数据集上的AP与Faster RCNN[6]效果相当,但其在小目标检测上效果不如Faster RCNN,因此2020年10月Zhu[7]等人提出使用Deformable DETR来解决上述问题。
3.1.2 Deformable DETR
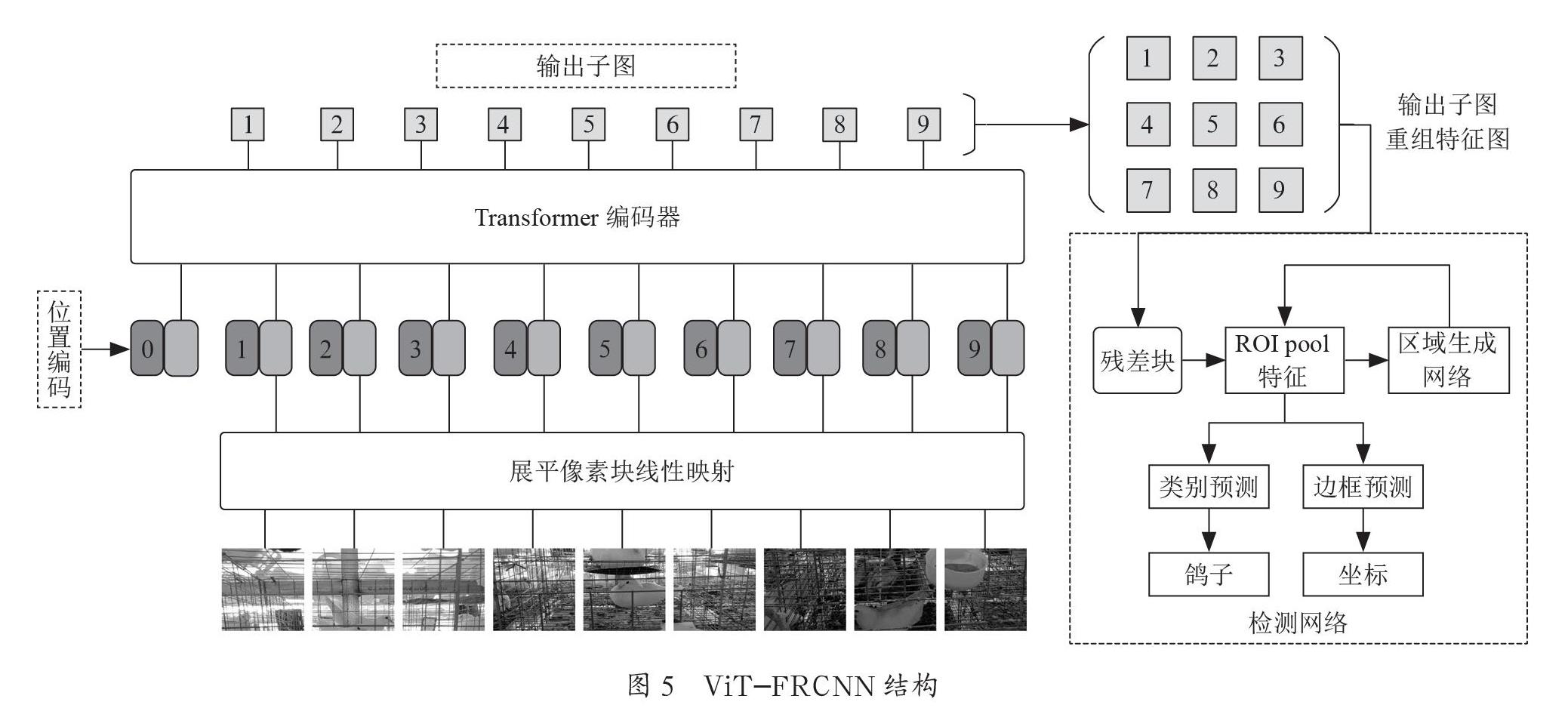
Deformable DETR借鉴了可变形卷积网络的思想,使用可变形注意模块代替DETR中Transformer注意力模块,缩小K采样范围,让Q与更有意义的K进行比较,减少计算量,提升速度。对于小目标检测效果不佳的问题,该模型使用多尺度可变形注意力模块,对不同尺度特征图进行可变形注意,将每层的注意力结果相加得到多尺度注意力,从而提高小目标检测效果,结构如图4所示。
该模型与DETR相比,收敛速度快10倍、小目标检测AP提升3.9%,大目标检测AP与Faster RCNN相比,提高4.6%。虽然该模型在训练速度和小目标检测上得到了很大的改进,但对于遮挡目标的检测效果仍然不佳。
3.2 基于Transformer特征提取网络目标检测模型
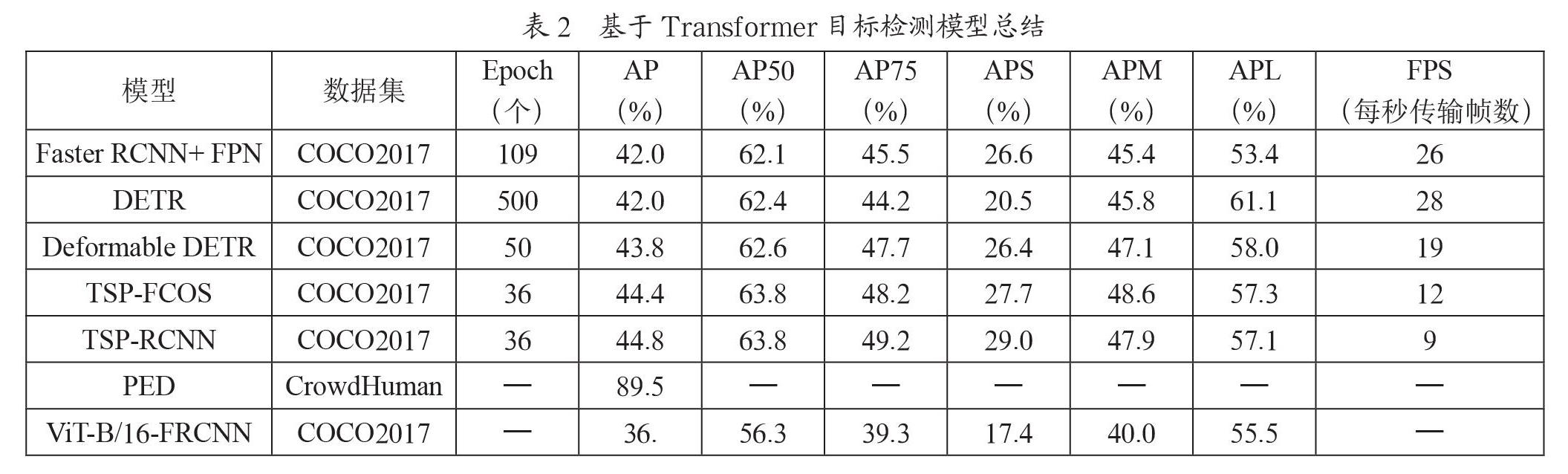
2020年10月Dosovitskiy等[8]提出Vision Transformer(ViT)模型,在大型数据集JFT300M上的图像分类效果超越当前SOTA的结果,因此Beal等人利用ViT模型作为特征提取网络,提出用于目标检测的ViT-FRCNN模型[9]。ViT-FRCNN模型结构如图5所示。
ViT-FRCNN模型首先将图片分割成N个P×P子图,将其按顺序排列,转换为序列化数据,随后将其输入到ViT网络,将每个子图的输出重新组合成特征图,输入到含有RPN模块的检测网络中实现预测。
3.3 对比实验
本文为了衡量各基于Transformer目标检测模型的性能,基于公共数据集开展对比实验,如表2所示。通过对比实验,可见基于Transformer模型的目标检测精度优于Faster RCNN模型,但检测速度明显不足。在基于COCO数据集的对比测试中发现,基于Transformer模型算法平均响应时间为Faster RCNN模型的2.1倍;对水果、蔬菜等小目标检验测试平均响应时间为Faster RCNN模型的2.8倍,高于人物等较大目标检测的平均响应时间,由此可见基于Transformer模型目标检测在工业农业生产等领域的实际应用还不够成熟。
4 结 论
本文对基于Transformer目标检测模型进行了分析,虽然此类模型在目标检测任务中有较好表现,但仍存在许多不足。如DETR系列模型的检测速度较慢,对小目标检测性能不佳;TSP模型提高了检测速度,但大目标检测性能退化。目前,基于DETR算法的改进主要是针对模型收敛速度和小目标检测,收敛速度的改进通过调整注意力模块的输入来降低自注意的计算量来达到加速效果,而小目标检测任务则通过加入多尺度特征融合来实现。基于特征提取网络的ViT-FRCNN系列模型提升了收敛速度,但平均精度有待提高。同时,实际目标检测应用场景环境复杂,反光倒影、灰尘遮挡等各类噪声突出,SIRR等算法可用于基于Transformer模型的前期去噪处理,提高整体精度。
参考文献:
[1] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [C]//Advances in Neural Information Processing Systems.Long Beach,2017:5998-6008
[2] PARMAR N,VASWANI A,USZKOREIT J,et al. Image Transformer [J/OL].arXiv:1802.05751 [cs.CV].(2018-02-15).https://arxiv.org/abs/1802.05751.
[3] CARION N,MASSA F,SYNNAEVE G,et al. End-to-End Object Detection with Transformers [M].Switzerland:Springer,2020.
[4] ZHU X Z,SU W J,LU L W,et al. Deformable DETR:Deformable Transformers for End-to-End Object Detection [J/OL].arXiv:2010.04159 [cs.CV].(2020-10-18).https://arxiv.org/abs/2010.04159.
[5] ZHENG M H,GAO P,WANG X G,et al. End-to-End Object Detection with Adaptive Clustering Transformer [J/OL].arXiv:2011.09315 [cs.CV].(2020-11-18).https://arxiv.org/abs/2011.09315v1.
[6] LIU L,OUYANG W L,WANG X G,et al. Deep Learning for Generic Object Detection:A Survey [J]. International Journal of Computer Vision,2020,128:261–318.
[7] DAI J F,QI H Z,XIONG Y W,et al. Deformable Convolutional Networks [C]//2017 IEEE International Conference on Computer Vision(ICCV).Venice:IEEE,2017:764-773.
[8] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al. An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].(2020-10-22).https://arxiv.org/abs/2010.11929.
[9] BEAL J,KIM E,TZENG E,et al. Toward Transformer-Based Object Detection [J/OL].arXiv:2012.09958 [cs.CV].(2020-12-17).https://arxiv.org/abs/2012.09958.
作者簡介:尹航(1978—),男,汉族,山东东明人,副教授,博士,研究方向:机器学习。
