基于EBAP模型的中文情感分类
2021-10-16朱海东侯秀萍
朱海东, 郑 虹*, 侯秀萍
(长春工业大学 计算机科学与工程学院, 吉林 长春 130012)
0 引 言
随着互联网技术的发展,越来越多的人们喜欢通过网络发表自己的观点、看法以及一些评论,从而产生大量带有情感色彩的文本信息。这些文本通常包括对时事的热评、商品评论、酒店评论[1]。因此,从这些海量的评论信息中分析和挖掘出用户的情感倾向具有重要的意义和研究价值。例如,电商卖家可以根据买家对商品及服务的评价来制定合适的营销策略。政府可以根据网民评论信息的分析结果进行合理的舆论监控[2]。从互联网的文本信息中可以看出,挖掘出人们的情感倾向是非常值得研究的问题。
目前,应用比较广泛的神经网络模型有卷积神经网络[3](CNN)和循环神经网络[4-5](RNN),预训练模型有Transformer和Bert。但是它们在处理非结构化的文本时,不能有效捕获全局语义特征和局部语义特征,不能准确表达语义信息,除此以外,还不能有效获取文本中关键的情感信息。针对以上模型存在的不足,文中提出一种将ERNIE[6]预训练模型和Attention[7]注意力机制与CNN和BIGRU[8](门控单元循环神经网络)两种神经网络相结合的方法对文本进行情感分析。
1 相关工作
随着深度学习技术的快速发展,越来越多的深度学习模型应用于自然语言处理领域,尤其是情感分类的任务中。Bengio等[9]首次将神经网络模型用于自然语言处理任务中来训练特定的语言模型;白静等[10]提出利用BiLSTM网络模型对微博文本中所蕴含的情感进行立场检测;Xu J等[11]提出一种能捕获长期情绪信息的带有缓存机制的LSTM。表明循环神经网络在情感分类任务中是有效的;徐菲菲等[12]提出一种结合卷积神经网络和最小门控单元注意力模型来进行情感分析,通过在公开数据集IMDB、Sentiment140上进行实验,证明该模型可以有效地提高分类效果;Tian Z等[13]为了提升短文本的情感分类效果提出一种将双向GRU与注意力机制结合的模型,该模型有效地提高了分类效果。表明BiGRU与注意力机制结合能够进行更加精准的分类;史振杰等[14]提出Bert+CNN模型对电商评论进行情感分析;雷景生等[15]提出一种ERNIE_BIGRU的中文文本分类方法在新浪新闻公开的数据集上取得良好的分类效果。这些工作表明预训练模型与神经网络结合在获得完整语义及全局特征方面是有效的。
文中提出中文情感分类模型在现有ERNIE情感分类模型和ERNIE_BIGRU模型的基础上进行改进 ,与现有工作既有联系又有区别,在一定程度上弥补了上述模型无法识别出不同词的贡献度和无法提取局部重要特征的不足,在情感分类任务上分类的准确率有明显的提高。
2 EBAP模型
2.1 模型设计
EBAP中文情感分类模型主要由四层网络结构组成,分别是ERNIE层、BIGRU层、池化层和注意力机制层。EBAP模型通过结合不同层的各自优势来实现准确的情感分类目标。通过ERNIE层学习更多的先验知识增强语义表示,通过不同的知识掩蔽策略来学习更准确的语义信息。并通过双向GRU层捕获上下文的语义信息,同时减少了网络的张量计算和参数的数量,提高了网络训练的执行效率。在进行前面一系列的特征提取之后,通过引入注意力机制层将重要的特征和情感信息赋予较大的权重,通过池化层进行特征降维,去除冗余信息,把最重要的信息提取出来,同时也防止了过拟合。最终送入Softmax函数进行分类。
EBAP模型结构如图1所示。

图1 EBAP模型整体结构
图中,s={w1,w2,w3,…,wn}表示长度为n的输入语句。wi表示句子中的单词。x={x1,x2,x3,…,xn}表示语句S经过ERNIE层的向量表达形式。B={B1,B2,B3,…,Bn}表示经过BIGRU层特征提取的结果。A={A1,A2,A3,…,An}表示赋予不同权重后的特征向量表达形式。P={P1,P2,P3,…,Pn)表示池化层特征提取结果。
2.2 ERNIE预训练模型
ERNIE 预训练模型是在Bert模型的基础上进行改进,通过改进不同的遮蔽策略,以及利用先验知识增强语义表示。而ERNIE模型和Bert模型本质上都是采用多层双向的Transformer结构,利用双向的Transformer结构作为编码器来训练深度双向文本表示向量[16]。Transfomer采用编码-解码结构,其中编码器部分就是将输入序列(x1,x2,…,xn}映射到连续表示z=(z1,z2,…,zn},在解码器端生成一个输出序列(y1,y2,…,yn},每一时刻输出一个结果。
Transformer编码单元如图2所示。
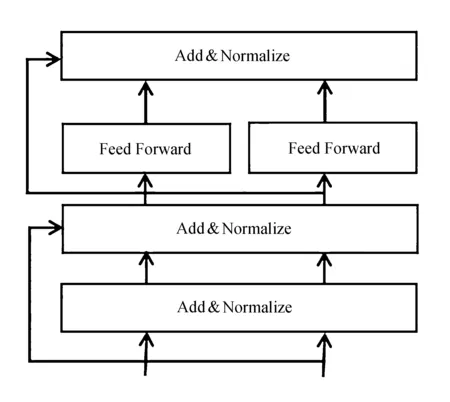
图2 Transformer编码单元
由图2可以看出,编码器端有6层这样的结构,每一层包括两个子层:第一个子层是多头自注意力机制,用来计算输入的自注意力机制层;第二个子层是全连接层。在每一个层中都使用了残差网络。因此每一个子层的输出都是
LayerNorm(x+Sublayer(x)),
(1)
式中:Sublayer(x)----子层对x做的映射。
Transformer解码单元如图3所示。

图3 Transformer解码单元
由图3可以看出,解码器端也是6层,每一层包含三个子层。同encoder相比多一个注意力机制层。第一个子层是遮蔽的多头自注意力机制层,同样也是计算输入的自注意力机制,Mask掉未来的信息。第二个子层是对encoder的输入做attention运算层。第三个子层是一个简单的全连接层。从中可以看出,ERNIE及Transformer最主要的就是自注意力机制,对于Attention机制假设输入query,key,value,其中key和value的维度分别为dk和dv。但实践中将query,keys,values都处理成对应的矩阵Q,K,V。因此Attention相应的公式可表示为
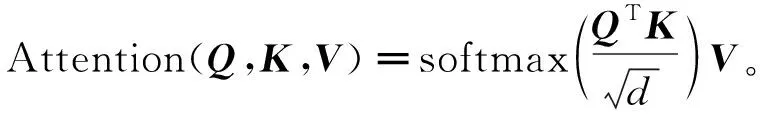
(2)
ERNIE预训练模型是一种新的语言表示模型,在之前提出的Bert预训练模型中只是通过上下文来预测缺失部位的单词,而没有考虑在句子中应用先验知识。ERNIE模型通过知识推理来增强模型表示,通过应用与Bert不同的遮蔽策略----实体级和短语级的遮蔽,即我们在遮蔽的时候是以一个实体或者短语为一个遮蔽单位。在没有直接知识嵌入的情况下,通过这种方式在训练过程中就能隐式地学习到先验知识,例如能学习到实体之间的关系、属性等知识信息。从而获得完整的语义表示。Bert模型Mask的是字,因此在训练过程中只能学习到字与字之间的语义联系。而ERNIE模型Mask的是一些连续的token、词和实体,因此在训练过程中不仅能学习到字与字之间的关系,还能学习到实体之间的知识信息,因此模型会得到更加准确的语义表示。
2.3 BiGRU层
GRU是LSTM(长短时记忆网络)的一种改进,在LSTM的基础上,将输入门和遗忘门合并为更新门,从而使网络结构变得更为简单,在训练过程中减少了网络参数的数量,加快了收敛时间,提高了模型的训练效率,同时也降低了出现过拟合的可能性。
GRU公式表示如下:
rt=σ(Wrxt+Urht-1),
(3)
zt=σ(Wzxt+Uzht-1),
(4)

(5)

(6)
式中:zt----更新门,功能是控制下一时刻信息的输入;
rt----重置门,决定信息的保留与丢弃;
xt----t时刻的输入;

ht,ht-1----t时刻及t-1时刻的隐藏状态;
Wr,Wz,W,Ur,Uz,U----权重矩阵,更新门和重置门决定隐藏状态的输出。
GRU只能捕获单向的语义信息和情感信息,对于一个情感词只能从这个词之前的时刻进行单向学习,而无法到这个词之后的语义特征,从而忽略了之后时刻的语义重要性,因此,文中使用BIGRU从两个方向捕获语义信息[17]。
2.4 Attention层
对于BIGRU层不能识别出评论文本不同的部分对于情感分类结果的重要程度,因此,文中提出的模型中BIGRU层之后增加了注意力机制层。用于标记和识别出不同的词对于待分类文本情感极性的贡献度,极大地提高了分类的准确率。Attention模型具体公式如下:
eij=a(si-1,hj),
(7)

(8)
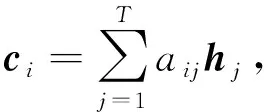
(9)
式中:hj----编码器中第j时刻的隐藏状态向量;
si-1----解码器端第i-1时刻的状态向量;
eij----评分函数对当前词的重要程度进行打分;
aij----经过计算后的语义权重。
通过对每个词的隐藏状态和对应的语义权重进行加权求和,得到相应的语义向量ci。
2.5 池化层
评论文本在经过前述过程的特征捕获及分配权重后得到C={c1,c2,c3,…,cn}文本语义向量。利用池化层提取局部最重要的语义特征,最后把CNN层输出的向量进行拼接,得到最终向量C={c1,c2,c3,…,cn}。文中提出的模型采用最大池化的方式为
C=max(c)。
(10)
最后,将之前经过不同网络结构提取到的特征送入到全连接层和分类器,为了防止过拟合在全连接层后融入dropout机制,分类器采用softmax分类函数,通过softmax函数得到最终的情感分类结果。
3 实验及结果分析
3.1 实验环境
文中实验在CentOS 7.9 环境下运行,实验使用GPU为NVIDIA TITAN XP*4 ,编程语言为Python,使用的深度学习框架为Pytorch,实验所用的预训练模型为百度推出的基于知识策略和实体遮蔽的ERNIE 。
3.2 实验数据集
文中使用的数据集是由谭松波老师整理的酒店评论的中文公开数据集Chnsenticorp,该数据集是带有情感标签的情感分类中文数据集,情感极性为积极和消极两种,即为二分类。为了防止实验验证模型出现过拟合现象,将数据集按照8∶1∶1切分为训练集、测试集和验证集。将测试集上得到的实验数据作为实验结果。积极文本的情感标签记为1,消极文本的情感标签记为0。
3.3 超参数说明
为了使模型能表现出自身最佳的分类性能,模型中的超参数设置见表1。

表1 实验的超参数表
3.4 评价指标
文中提出的情感分类模型采用的评价指标有精确率P、召回率R和F1值。具体计算公式为:

(11)

(12)

(13)
式中:Tp----实际值和预测值情感极性都为积极时的数据个数;
Fp----实际的情感极性为消极,预测的情感极性为积极时的数据个数;
Fn----实际的情感极性为积极,预测的情感极性为消极时的数据个数。
F1值由精确率和召回率共同决定。
3.5 情感分类实验
为了验证在相同数据集及同等实验条件下文中提出的EBAP中文情感分类模型要优于文献[6]提出的情感分类的基线模型及文献[15]提出的中文文本分类模型,文中逐步探索,陆续提出了ERNIE_CNN,ERNIE_BiGRU_Attention,ERNIE_BiGRU_CNN,Bert_BiGRU_CNN_Attention等情感分类模型。
在此基础上,结合这些模型各自的优缺点提出了EBAP模型。为了验证EBAP模型的有效性,在完成EBAP模型实验的基础上又完成了上述情感分类模型,以及其他基准模型的对比验证实验。
实验中RNN网络都是采用双向GRU门控单元循环神经网络。所用的损失函数是交叉熵损失函数。
不同模型在测试集上的准确率及损失值见表2。

表2 不同模型在测试集上的准确率及损失值
不同模型在积极测试集文本上的不同评价指标见表3。
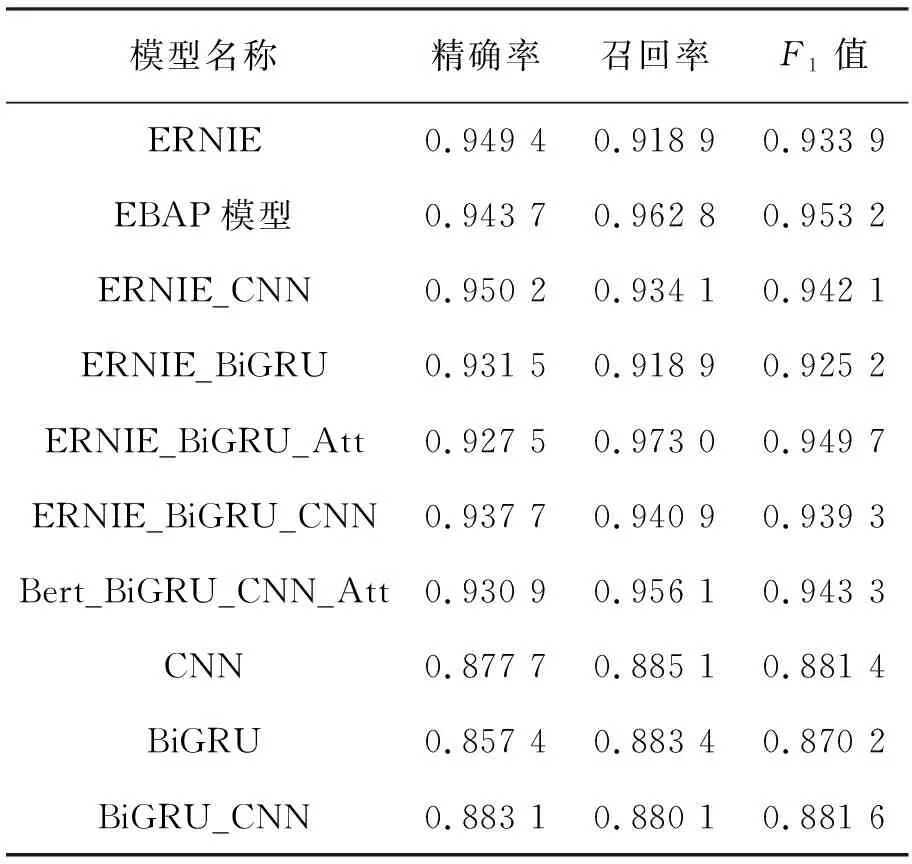
表3 不同模型在积极测试集文本上的不同评价指标
不同模型在消极测试集文本上的不同评价指标见表4。
不同模型在测试集上准确率分布的条形统计图如图4所示。

图4 不同模型在测试集上准确率分布的条形统计图
不同模型在测试集上损失值分布的折线统计图如图5所示。
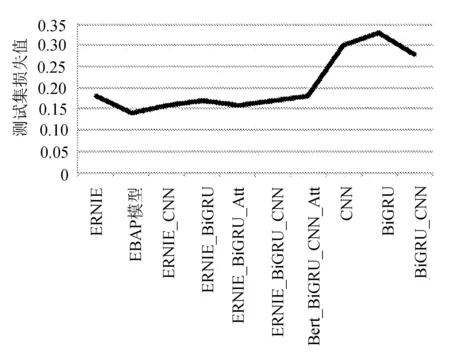
图5 不同模型在测试集上损失值分布的折线统计图
3.6 实验结果分析
从以上实验结果可以看出,文中提出的EBAP模型在同等实验条件下要比文献[6]所提出的ERNIE模型在中文情感分类问题上效果好,在测试集上的准确率提升了1.75%。同时可以看出,EBAP模型在中文情感分类问题上比文中其他几种对比模型的实验效果好,说明ERNIE预训练模型与RCNN及Attention机制结合在中文情感分类问题上是有效的。通过实验还可以看出,BiGRU加入了ERNIE预训练模型之后效果有明显的提升,提升了5.67%,说明通过ERNIE预训练模型得到的词向量比Word2vec[18]得到的词向量在语义表示方面更加准确、更加完整。同时,EBAP模型比Bert_BiGRU_CNN_Att模型在分类效果上提升了1%,说明在中文情感分类问题上,尤其是获得语义表示方面ERNIE要优于Bert。
在评价指标方面,从表3可以看出,对比ERNIE模型和EBAP模型在精确率相差不大的情况下,EBAP模型在测试集积极文本上的召回率比ERNIE提高了4.39个百分点,说明EBAP模型比ERNIE模型更能捕捉积极的情感信息。对比Bert_BiGRU_CNN和EBAP模型两者在测试集积极和消极文本上的F1值可以看出,EBAP模型的F1值均比Bert_BiGRU_CNN模型高,这也说明了对于捕捉情感词方面EBAP模型更有优势。
从表3和表4可以看出,EBAP模型的F1值和Precision均高于其他情感分类模型,说明EBAP模型更适合于中文情感分类任务。通过不同模型损失值的折线图可以看出,EBAP模型损失值最小。
4 结 语
采用与传统情感分类不同的方法,利用ERNIE预训练模型不同的知识遮蔽策略生成更完整、更精准的词向量语义表示,在此基础上,结合RCNN神经网络和Attention机制提出了EBAP模型,并在Chnsenticorp中文公开数据集实验,在相同的实验参数和同等实验条件下,EBAP中文情感分类模型测试集的准确率及评价指标F1上要优于文献[6]所提的ERNIE模型及文献[15]所提的中文文本分类ERNIE_BiGRU模型,同时也优于文中提到的其他情感分类模型,并取得了很好的分类效果。
EBAP模型虽然取得了很好的分类效果,但是也存在着诸多不足,如EBAP模型所能判断的情感极性只有积极和消极两种,不能实现多类别的情感分类。除此以外,EBAP模型对于段落级文本和篇章级文本实验效果还未知,需要进一步研究和探索。所以接下来的工作就是着手处理解决以上存在的几个问题, 使得文中提出的模型更加完善、更具适应性。
