改进粒子群算法求解分布式柔性车间调度问题
2021-10-15王宇嘉林炜星陈万芬
陈 强,王宇嘉,林炜星,陈万芬
(上海工程技术大学 电子电气工程学院,上海 201620)
随着经济全球化的不断加深和市场竞争的日益严峻,传统的单一车间制造模式已经无法满足我国制造业的生产需求,分布式生产制造模式已经成为企业提高生产竞争力的重要手段。由于不同工厂之间存在着技术水平、机器数量、物料运输等无法避免的差异,采用有效的分工协作方式使企业高效地生产出高质量产品成为当前的研究热点。
分布式柔性车间调度问题(Distributed Flexible Job-shop Scheduling Problem,DFJSP)是车间调度问题的一种特例。由于在工件分配过程中,要同时考虑到工件到不同工厂之间的分配以及工序在加工机器之间的分配,因此其具有更高的复杂度和求解难度。
DFJSP的概念于2006年被文献[1]提出,该研究使用基于支配基因策略的遗传算法求解最小化最大完工时间(Makespan)。文献[2]以最小化最大完工时间为调度目标,提出一种遗传算法来求解DFJSP,在选择阶段对个体进行基于完成工期的排序,然后选取应用于交叉阶段的染色体。文献[3]提出了一种混合遗传算法求解DFJSP,同样以最小化最大完工时间为调度目标。文献[4]提出了一种改进的人工蜂群算法来求解DFJSP,其编码方案采用了三维向量编码即工序排列向量、柔性加工单元(Flexible Manufacturing Unit,FMU)选择向量和加工设备选择向量,在跟随蜂的操作中,引入了基于关键路径的局部搜索算子。文献[5]在解决DFJSP时,提出了一种新型的编码方式,将一维染色体转换成精确的三维解,有效减少了计算量。文献[6]在解决DFJSP时,将K-means和混合蛙跳算法同蚁群算法相结合,通过判断蚁群所处的状态,动态调整蚁群的参数。文献[7]将组合拍卖机制与蚁群算法相结合来求解DFJSP,提高了工件的生产效率。
目前,对于DFJSP的研究相对较少,大部分研究者都是采用的遗传算法或蚁群算法来解决该问题。然而该类算法参数设置复杂且容易陷入局部最优,导致无法得到一组较满意的结果,因此本文提出一种更高效的优化算法来解决复杂的DFJSP。其次,在构建DFJSP数学模型时,大部分文献都将其简化为一个以Makespan为调度目标的单目标优化问题。然而,将该问题过于简单化并不能很好地描述出实际生产情况。粒子群算法(Particle Swarm Optimization,PSO)[8]是通过研究鸟群觅食规律而发展起来的一种群智能优化算法,其结构简单、收敛速度快、精度高,被广泛应用于各个领域[9-11]。粒子群算法也同时被成功地应用到车间调度问题中[12]。因此,本文采用一种改进粒子群算法IMPSO(Improved Particle Swarm Optimization)求解DFJSP。
1 分布式柔性车间调度问题
在DFJSP中,有n件工件、m台机器和s间分布式工厂。每件工件都有自己的预定义和确定性处理工序,这些工序构造了工件一组操作。在对每一件工件分配过程中,第一个阶段是将工件分配给某间工厂。在分配了某间工厂之后,工件通过预定义的阶段进行处理。在每个预处理阶段,都有一组用于加工工件的候选机器,这是该问题的第二个阶段,即为每件工件从候选机器中选择合适的机器。在为每件工件分配了合适的机器之后,第三个阶段是在每间工厂分配的机器上调度相关工件的工序。因此,DFJSP的关键问题如下:(1)工件分配合适的工厂;(2)工件分配合适的机器;(3)在合适的机器上确定所有工序的加工顺序。
调度过程中遵循的分配原则如下:(1)每台机器每次只能处理一道工序;(2)每道工序只能在其前一道工序处理完成之后才能处理;(3)每道工序只能在一台机器上处理;(4)任意一件工件分配到某一工厂时,其所有工序只能在这同一工厂内加工处理;(5)所有工序要全部加工完成后,生产活动才能停止;(6)工件在工厂内部的运输时间忽略不计;(7)机器的加工时间是连续的。
为了方便表述DFJSP,表1给出了构建数学模型所用的符号及其定义。

表1 符号及其定义
通过以上信息,建立如下的3目标数学模型:
(1)最大完工时间(Makespan),该目标保证了加工所有工件总的用时最短
f(1)=max(Cp|p=1, 2, …,n)
(1)
(2)机器最大负载,该目标强调了机器之间要保持负载平衡
f(2)=max(wk|k=1, 2, …,m)
(2)
(3)机器总负载,该目标保证了所有机器总的负载量要小
f(3)=T
(3)
综上所述,DFJSP的数学优化模型如式(4)所示。
min(F)=min(f(1),f(2),f(3))
(4)
2 任务分配策略的粒子群算法
2.1 粒子的编码与解码
DFJSP是离散优化问题,而PSO算法一般解决的是连续优化问题,因此在求解之前要确定粒子的编码与解码方案。
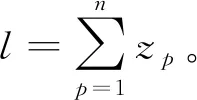
操作向量(OS)为基于工序的编码,用来确定工序Opj的先后加工顺序。
机器向量(MA)为基于机器的编码,用来确定每道工序分配的加工机器。
表2给出了一个可行的粒子编码的表达式。

表2 粒子编码的表达式实例
其中,该实例共有两个工厂,且每个工厂含有3台机器。从表2中可以看出粒子的维度为2×l=22,粒子位置可表示为(OS,MA),OS可以解释为工序的加工顺序为(O21→O41→O11→O31→O42→O32→O12→O22→
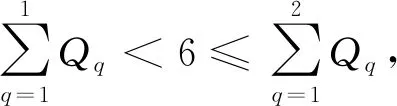
M12→M21)。
种群粒子在迭代过程中,根据速度更新式和位置更新式,生成新的粒子。然而新粒子的位置不一定是有效的整数。因此需要对新粒子的位置进行调整。首先对粒子位置进行四舍五入和边界限制,使新生成的粒子转换为有效的整数。然后,判断粒子的OS值,对所有的工序进行多余和缺失的查找,并将多余的工序转变为缺失的工序。接着遵循以下原则对粒子中的MA进行调整:(1)少数服从多数原则。当某工件被不同的工厂加工时,分别计算不同工厂中加工该工件的工序个数,通过该原则将该工件中的工序从较少的工厂中转移到较多的工厂;(2)当不满足上条原则时,采用后到服从先来原则,即当某工件的工序平均被不同的工厂加工,则排位靠后的工序要转移到前面工序所在的工厂中。通过上述的两个原则可将新粒子中多余的部分转化成缺少的部分。最后,判断所有工序是否在可行的机器上被加工,若不在,则随机从该工厂选取可行的机器作为该工序的加工机器。通过以上所有操作,新粒子就转换成得到一组可行解。
2.2 任务分配策略
粒子的任务分配策略使用文献[13]给出的计算方法。
勘探任务:在勘探过程中,粒子的速度和位置的更新式如式(5)和式(6)所示。
vid(t+1)=ωvid(t)+c1r1(Xid-xid(t))+c2r2(Xgd(t)-xid(t))
(5)
xid(t+1)=xid(t)+vid(t+1)
(6)
式中,ω表示权重向量;c1和c2表示学习因子;r1和r2表示(0,1)的随机数;Xid和Xgd分别表示个体最优位置和群体最优位置。
开采任务:反向学习是一种区间收敛的算法,将其应用到开采任务中,可以更好地发挥种群精确收敛的作用。本文应用文献[14]给出的反向学习策略作为粒子的更新策略,计算式为
(7)
2.3 改进拥挤距离
对于传统的拥挤距离,仅仅能够计算某点到上下两点之间的欧式距离,无法区分该点的位置关系。如图1所示,数字表示位置,字母表示粒子,在图1(a)和图1(b)中,根据原有拥挤距离计算可得B点的拥挤距离相等。然而,图1(a)的B点位置的分布性劣于图1(b)中的B。因此,本文采用式(8)计算拥挤距离
(8)
式中,distanceid表示第i粒子的第d维拥挤距离;disd表示在第d维上第i-1和i+1两粒子之间的欧式距离;d1和d2分别表示第i-1和i+1两粒子分别到第i个粒子之间的欧式距离。从图1可以进一步看出,图1(a)中B点的拥挤距离小于图1(b)中B点的拥挤距离。对比图1(a)中B和图1(c)中的B,通过式(8)可得,图1(c)中B的拥挤距离好于图1(a)中的B。从中也可以看出,对于距离大但分布性不好的个体,其拥挤距离仍有可能小于距离小但分布性好的个体。
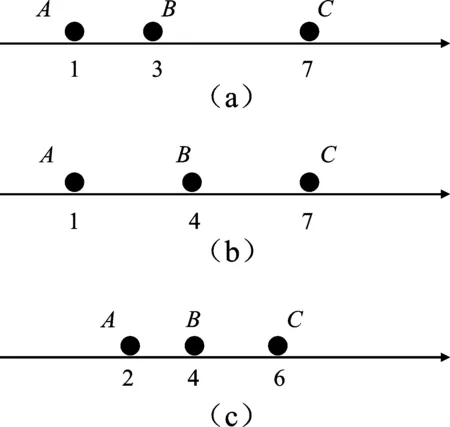
图1 拥挤距离示意图
对于边界粒子,设置拥挤距离为无限大。
通过上述分析可以看出,本文提出改进的拥挤距离可以有效地克服传统拥挤距离无法解决的问题。
3 算法流程
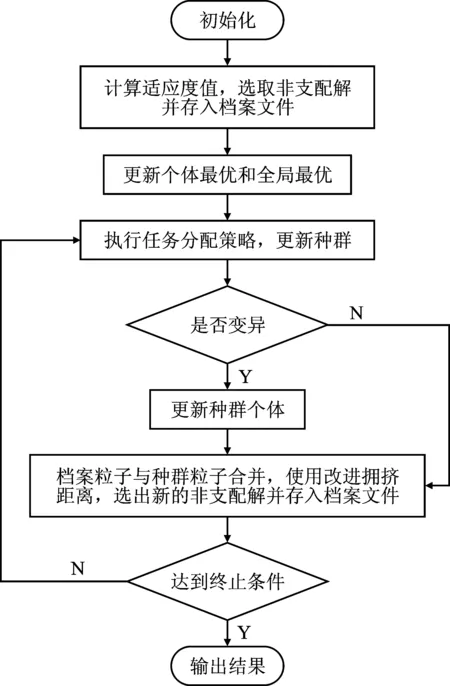
图2 IMPSO算法流程图
下面为算法详细步骤:
步骤1参数设置,依据调度规则,种群初始化;
步骤2根据粒子的编码与解码方式,计算初始化种群的适应度值,同时根据Pareto支配策略产生非支配解。若非支配解的个数大于外部档案的大小,则通过改进拥挤距离从非支配解中选出部分非支配解存入外部档案中,否则直接将非支配解存入外部档案;
步骤3更新个体最优粒子和全局最优粒子,随机从外部文档选取全局最优粒子;
步骤4粒子执行任务分配策略,并对新生成的粒子进行编码与解码,计算适应度值,更新个体最优粒子和全局最优粒子;
步骤5选取部分粒子执行多项式变异操作;
步骤6对变异后的粒子进行编码与解码操作,更新种群个体;
步骤7将外部文档粒子与种群粒子合并,通过Pareto支配选取非支配解,若非支配解的个数大于外部档案的大小,则通过改进拥挤距离从非支配解中选出部分非支配解存入外部档案中,否则直接将非支配解存入外部档案;
步骤8判断算法是否满足停止条件,若条件满足,算法停止迭代,否则转到步骤4。
4 实验结果与分析
4.1 测试算例
目前对于分布式柔性车间调度问题,仍没有标准的测试算例,因此本文使用的算例DMK01-DMK10是通过经典的柔性车间调度算例MK01-MK10[15]改进而来的。所有的测试算例分别在2工厂和3工厂下完成生产。算例的生成规则如表3所示。
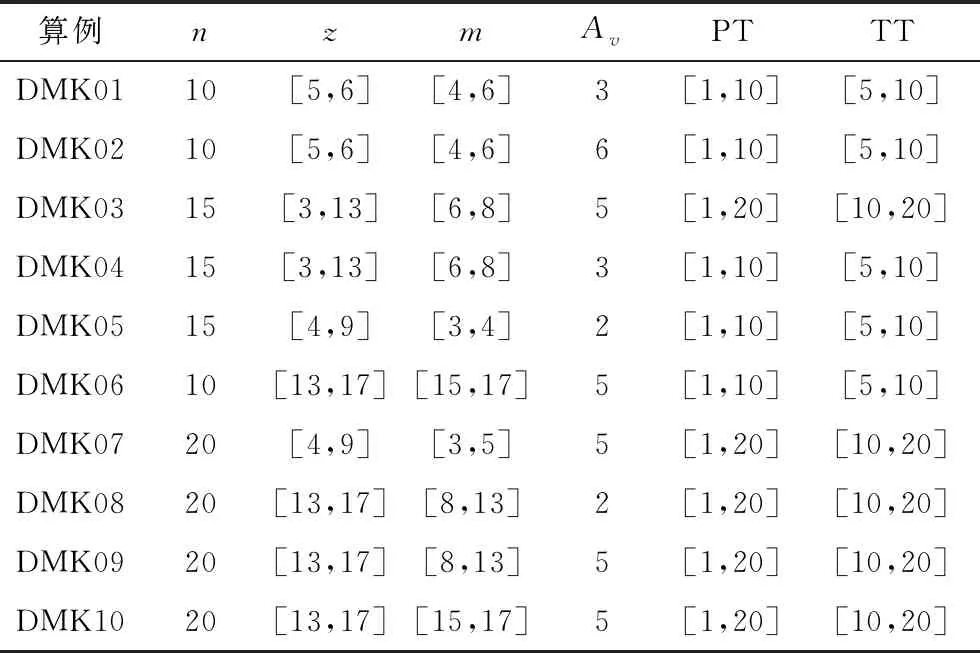
表3 算例参数
以DMK01为例,总的工件个数n表示在该算例中,需要被加工的工件。工序数量z是表示每件工件中包含的数量,其取值范围是[5,6]中的随机取值。机器数量m是指每个工厂中的机器数量,从[4,6]中随机取值。可用机器数量Av是指在同一个工厂内,每道工序可使用的机器的数量。加工时间PT是指每道工序的加工时间,其取值是从[1,10]中随机选取。运输时间TT是指每件工件从原料产地运输到加工工厂所花费的时间,从[5,10]中随机选取。以上的随机取值都取整数。
4.2 性能指标
为了测试所提算法在解决分布式柔性车间调度问题的性能,采用文献[16]给出的平均Pareto距离Dp来评价算法的性能。其中,设S*为一组参考点,该参考点是通过所有对比算法运行3 000次迭代得到的所有非支配解个体组成的。平均Pareto距离Dp越小,算法的性能越好。性能指标的计算过程请参考上述文献。
4.3 参数设置
将本文所得结果与NSGA-II[17]和IGASA[18]进行对比。表4给出了算法在求解该问题上的参数设置。所有算法的种群大小都为25,外部文档大小为25,迭代次数为1 000,取平均值。

表4 参数设置
4.4 结果分析
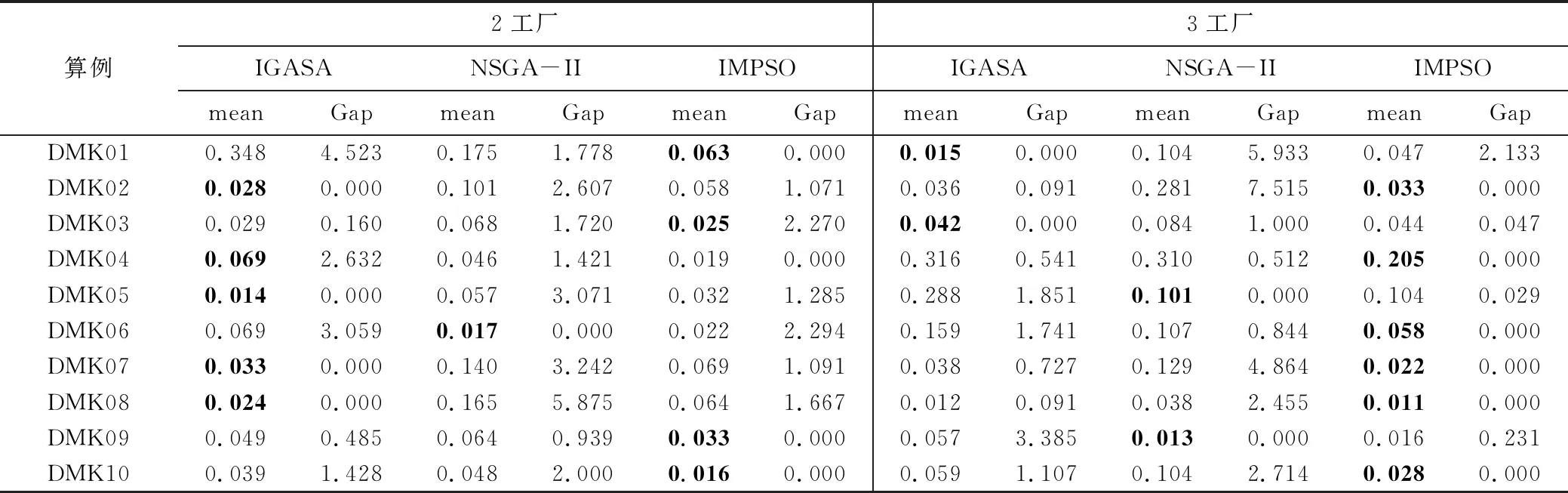
表5 平均Pareto距离
表6给出了IMPSO算法在DMK01测试算例下得到的分配数据,在2工厂的情况下,工件4、5、7和9在工厂1被加工,工件1、2、3、6、8和10在工厂2被加工,所有工件的最小化完成时间为52,最小化机器总负载为189,最小化机器负载为34。在3工厂的情况下,工件3、5和9被工厂1加工,工件4、6和10被工厂2加工,工件1、2、7和8被工厂3加工,所有工件的最小化完成时间为40,最小化机器总负载为196,最小化机器负载为18。
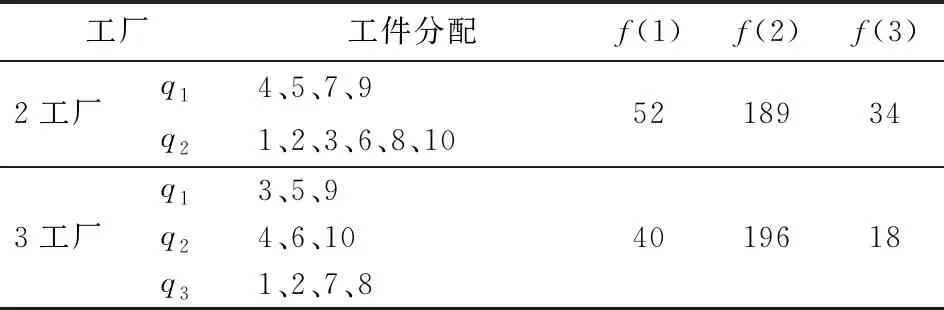
表6 IMPSO在DMK01测试算例下得到的分配数据
5 结束语
本文将任务分配策略、反向学习和改进拥挤距离相结合,提出了一种改进的粒子群算法。实验结果表明,在解决分布式柔性车间调度问题时,该算法能够有效地提高解的收敛性和分布性。目前,随着科技的不断进步,制造业也在相应地发展,这就意味着分布式柔性作业车间调度问题会越来越复杂,对于该问题的研究也需要更加深入。因此,在未来的课题中将会对实际生产问题进行深入分析,从离线性问题向实时性问题转变,建立更实用的多目标约束的数学模型。将本文所提算法应用到更复杂的车间调度问题上也将是下一步的研究重点。
