基于改进生成对抗网络的汉字字体生成算法
2021-10-15王江江黄星宇战国栋
王江江,黄星宇,战国栋
(大连民族大学 计算机科学与工程学院,辽宁 大连 116650)
文字是一个国家和民族文化的重要象征,也是一种文化传播和交流的重要载体,文字在文明的传承和传播过程中起着至关重要的作用。但由于汉字数量较多,而且字形多样,结构复杂,所以设计一套具有个人风格的字体并不是一件容易的事情,现在电子设备上可用的字体主要由商业公司的专业字体设计师制作。在20世纪80年代Strassmann[1]提出了一个二维毛笔模型来模拟毛笔。庞云阶等人[2]提出了一种计算机控制的笔式绘图仪绘图系统,利用毛笔和墨水来实现毛笔书法的模拟。Lee等人[3]构建了一个三维笔刷模型。Xu等人[4]提出了一个六层的字符拆分和合成模型, Zhang等人[5]提出了一种将手写体汉字转换成手写体汉字的方法。 2015年,Gatys等人[6]首次提出了一种基于神经网络的风格迁移算法。自从Gatys提出了风格迁移网络之后,Yu等人[7]试图将图画的风格赋予字符,并将字符变成任何形式的艺术形式。2017年,Tian[8]提出了基于CNN风格迁移模型的“Rewrite”模型。Lian等人[9]提出了使用循环神经网络[10]的一种基于字符笔画提取的风格转换方法。Tian在Pix2pix[11]模型的基础上提出了一种新的方法“Zi2Zi2”[12]模型。
上述研究的汉字字体生成算法可以分为两类:基于计算机图像学的方法和基于深度学习的方法。基于计算机图形学的方法主要是基于笔画提取的方法,字体生成过程分为笔画提取和孤立笔画的重组,但是由于汉字字体的复杂性和多样性,笔画提取的准确性很难保证,使得基于计算机图形学的字体生成方法效果不佳。基于深度学习的主要采用基于CNN风格迁移模型和基于RNN字符笔画提取的风格转换方法,基于CNN神经网络的风格迁移方法缺乏对特定字体或手写风格的准确描述,基于RNN字符笔画提取的风格转换方法虽然对每种字体建立了非刚性的定位配准,准确分析了每个汉字各部分笔画的位置,但是该方法的数据准备过程十分复杂,大大制约了其推广应用。
本文主要针对现有汉字字体生成模型存在的问题进行了研究,提出了基于改进条件生成对抗网络的汉字字体生成算法FontToFont,通过引入U-Net网络结构,可以使生成器保存更详细的信息,并有利于模型性能。同时,在训练过程中使用了四个损失函数:对抗损失、像素损失、类别损失和感知损失。对抗损失有利于生成细节清晰的图像。像素损失表示真实图像和生成图像之间的像素空间距离,而感知损失从感知方面衡量它们之间的差异。类别损失对预训练很重要,它使模型能够同时从多种风格中学习。通过定量和定性的实验结果表明,本文提出的模型性能更好,能够生成结构层次更加鲜明、细节更加丰富、轮廓更加清晰的汉字。
1 基于改进生成对抗网络的汉字字体生成
1.1 数据集的建立与预处理
本文从字体设计网站上选择了江南手书、刻石录颜体、刻石录钢笔鹤体三种字体构建本文多风格汉字字体数据集。每种字体使用ImageFont模块转为图像,每种字体的包含大约4000张汉字图像,同时本文将图像大小统一为256×256×3。数据集中部分汉字字体图像如图2所。采用源字体为黑体。训练集分别由2 000个源字符图像和2 000个对应的来自其他风格的目标字符图像组成。源字体中剩余的字符图像用于测试。汉字字体图像均为灰度图像,同时本文也对不同风格的汉字字体图像进行了中心对齐。
(1)数据集的大小。实验采用3种不同风格字体进行对比实验,字体数量选择500、1 000、1 500、2 000、2 500、3 000。采用RMSE定性指标进行评价。从图1的实验结果可以看出,随着字体数量的增大,RMSE的值逐渐降低,说明数据集与生成效果直接呈正比。但是当字体数量达到2 000时,生成的字体质量的效果提升并 不明显,所以本文考虑到设计师设计字体的劳动复杂度,本文选择2 000。
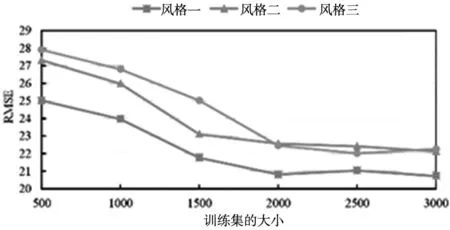
图1 字体生成质量与数据集大小的关系
(2)模型介绍。本文提出的网络结构如图2。由一个生成器和一个判别器组成,生成器主要有内容编码器、风格迁移模块、结果解码器组成。内容编码器第一层使用卷积神经网络,其余层均采用Conv-InstanceNorm[13]-ReLU结构;结果解码器最后一层采用tanh激活函数,与其他层对应的层采用Deconv-InstanceNorm-ReLU结构;风格迁移模块采用6个ResNet[14]中提出的残差网络模块构成。本文也采用了U-Net网络结构,考虑到参考字体和生成的字体应该具有相似的结构来表示相同的内容,本文将内容编码器中细节丰富的低层直接连接到相应的解码器层。在内容编码器和结果解码器之间添加层间跳跃链接,这样可以尽可能的保留字体图像的底层信息,避免字体图像在下采样过程中丢失形成和结构信息。
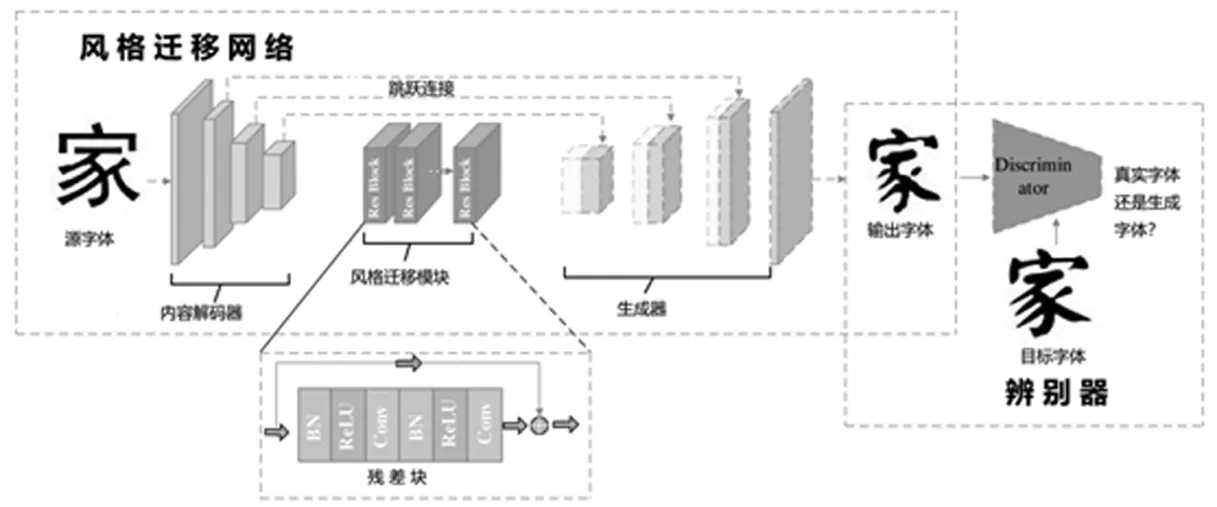
图2 网络模型
网络模型详细见表1。

表1 网络详细参数
1.2 损失函数设计
(1)对抗损失函数。从最初的生成性对抗损失开始。通过一个带有判别器D的最小最大值游戏,训 练生成器G将样本从噪声x映射到真实分布y。在训练阶段,生成器G试图生成具有真实 外观的假图像以混淆判别器D。同时,D旨在区分真实样本和生成的样本。对于图像到 图像的转换任务,本文关注的是将真实图像从一种风格转换为另一种风格,而不是从 随机噪声转换为真实图像,因此判别器D需要最小化下面定义的对抗损失函数:
(1)
此外,G试图生成具有真实外观的假图像以混淆判别器D,所示生成器G最小化下面定义的对抗损失函数:
(2)
本文为了提高生成对抗网络的训练稳定性以及提高生成对抗网络的图像生成质量,采用WGAN[15]提出的对抗损失来优化本文提出的汉字字体生成网络模型参数。并且在判别器D中使用梯度惩罚项,使得判别器D满足连续性条件。
(3)
其中‖‖采用L2范数,表示0到1之间的均匀分布,
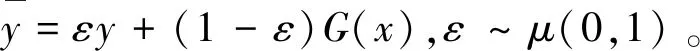
(4)
(2)像素损失函数。像素级损失在图像的像素级别进行惩罚,常见的像素级损失有欧氏距离、均方误差(Mean Square Error,MSE)、交叉熵损失(Cross Entropy Loss)等。本文采用了L1距离作为像素级别损失,因为其优化过程相比交叉熵损失稳定,比均方误差、L2距离的约束结果更锐利。
δL1=Ex∈pdata,z∈pinput||x-G(z)||1。
(5)
像素级损失一般只能约束生成图像的低频部分,也就是图像的轮廓、颜色等信息;像素级损失只能约束每个单独像素对比度的呈现,没有考虑到与周围像素的关系,因此需要进一步使用其他损失约束生成图像。
(3)字体风格类损失函数。为了生成高质量的字体图像,重要的是使模型不仅知道它自己的样式,还知道其他字体样式。因此,使模型能够同时学习多种字体样式是非常重要的[16],因此,在字符嵌入进入解码器之前,通过将不可训练的高斯噪声作为样式嵌入连接到字符嵌入来使用类别嵌入。为了防止模型将样式混合在一起并生成看起来不像任何提供的目标的字符,添加了多类类别损失来监督鉴别器预测生成的字符的样式[17]。其中表示经过判别器D得出的字体种类的概率分布,t表示目标字体真实图像,c表示目标字体的标签。字体风格类损失函数的定义为
(6)
将上述公式中的真实样本图像t替换为生成器生成的图像,就可以得到生成器的字体风格类损失函数。损失函数的定义如
(7)
生成器 G通过最小化这个损失函数,以此来保证生成的假图的风格种类能够被鉴别器正确的分类。
(4)感知损失函数。对抗损失和像素损失都是图像生成任务中常见的度量。此外,本文使用另一个更 接近感知相似性的损失函数。感知损失探索了从训练有素的CNN提取的图像的高维表示之间的差异[18]。本文根据预先训练的VGG16网络的ReLU激活层来定义感知损失。不同深度的层可以代表不同抽象级别的图像特征:从边缘、颜色到对象模式。感知网络中较低级和较高级激活的匹配指导合成网络学习细粒度细节以及全局排列[19]。本文在汉字字体生成中,要求生成的汉字字体图像与目标字体图像在汉字的形状结构方面保持一致性,这样的一致性可以用感知损失函数来进行权衡,来保证生成字体图像与目标字体图像在形状和结构方面保证一致。
(8)
本文使用CRN网 络[19]的参数配置。其中,代表VGG16的第l层网络 。采用conv1_2,conv2_2,conv3_2,conv4_2,conv5_2层来计算感知损失。对应层权重,在本文的实验中,本文设置λ1=λ2=λ3=λ4=1,λ5=10
(5)最终优化目标。通过上述损失函数的介绍,本文提出的汉字字体生成网络模型的损失函数为这四种损失函数的加权之和,最终得到本文网络训练需要优化的损失函数。
(9)
(10)
(11)
1.3 评价指标
本文为了更客观的进行汉字字体生成模型性能的评价,根据论文[20-21]中提出的评价方法,从定性和定量两个方面对提出的汉字字体生成模型性能的评价,评估生成图像的效果。除了直接对比较实验的定性结果外,还采用了均方根误差 (Root Mean Square Error, RMSE)和像素差异率 (Pixel Disagreement Ratio, APDR)这两个定量值作为评价标准。
2 实 验
为了验证本文提出的模型的性能。本文构建了多风格的汉字字体的数据集,并且使用均方根误差(RMSE),像素差异率(APDR)两个定性评价指标,从图像的像素差异性以及像素差异率两个方面对生成的汉字字体图像进行评价,并且设计了四个实验。本文提出的汉字字体生成模型FontToFont与现有的三种字体生成算法进行对比实验,模型的消融实验,验证各部分的有效性,不同训练数据集对于模型性能的影响,以及不同源字体对于模型性能的影响。
2.1 实验数据集及实验环境
通过使用python类库中的ImageFont 模块[22]将字库文件TrueType转为汉字字体图像。从字体设计网站上选择江南手书、刻石录颜体、刻石录钢笔鹤体三种字体构建本文多风格汉字字体数据集。每种字体使用ImageFont 模块转为图像,每种字体包含大约4 000张汉字图像,同时本文将图像大小统一为256×256×3。数据集中部分汉字字体图像如图3,采用源字体为黑体。训练集分别由2 000个源字符图像和2 000个对应的来自其他风格的目标字符图像组成。源字体中剩 余的字符图像用于测试。本文也讨论了不同训练数据集规模对于模型性能的影响,训练数据样本依次为500,1 000,1 500,2 000,2 500,3 000个。汉字字体图像均为灰度图像,同时本文也对不同风格的汉字字体图像进行了中心对齐。

图3 多风格字体汉字图像示例
使用Pytorch框架搭建本文的汉字字体生成网络。采用Adam[23]优化方法对所提模型进行训练,并将学习率设置为0.000 1,判别器D先训练,生成器G次之,交替进行训练。在本文构建的多风格汉字字体数据集上训练40轮,每轮次10 000次,批次大小设置为1。学习率遵循StepLR策略,每50次迭代降 低一次。本文所有的实验都是在Ubuntu18.04系统,Intel(R) Core(TM) i7-7700K CPU, 英伟达GeForce GTX TITAN XP GPU上进行的。算法1如图4,详细讨论了本文模型的训练流程。

图4 算法1详细过程
2.2 实验结果分析
为了在整体上展示本文提出的汉字字体生成
模型的效果,将《早春呈水部张十八员外》为内容进行生成如图5,分别使用三种目标字体进行生成。为了增强可读性,可对比性,本文将真实的字体文字变成了风格一至三的第二列和第六列。

图5 《早春呈水部张十八员外》生成结果
图5展示了《早春呈水部张十八员外》三种字体的生成效果。其中图5a展示的是黑体表示的需要生成的文字内容,图5b~5d展示的是三种不同风格字体对应的生成结果。从图5b~d中可以看出,本文的模型生成效果较好,生成的字体与真实字体直接没有差别。此外,从图中也可以看出,模型对于汉字的结构和形状的特征把握比较好。能够当地保留重要的笔画细节,如笔画的开始、转折和结束区域。同时从图5c的笔画连接情况可以看出,本文提出的U-Net网络结构以及感知损失函数,能够保留笔画的重要信息特征,做到了一致性。
接下来本文选取三种字体进行汉字字体生成对比实验,分别选择Pix2pix、Zi2zi、HGAN三种汉字字体生成模型进行对比实验。本文对实验结果进行定量和定性的评价。定性评价的图如图6,定量评价结果见表2。

图6 风格一部分生成结果示例
Pix2pix、Zi2zi、HGAN模型生成效果如图6所示,在三种风格的汉字字体生成任务中,在Zi2zi、HGAN,Pix2pix中出现的一些不完整的笔画现象以及笔画模糊的现象。Pix2pix只能产生模糊的图像,很难识别字符的内容,无法捕捉相似手写风格之间的细微差异。相反,本文提出的汉字字体生成模型能够产生逼真的合成结果,并适当地保留重要的汉字笔画结构和形状细节,如笔画的开始、转折和结束区域。但是在字体风格形状结构复杂时候,本文的模型也有一些不完整的笔画问题。
从上面的分析结果可以看出,相比较与Pix2pix、Zi2zi、HGAN三种模型,本文的模型能够生成质量较高的汉字字体图像。此外从图6中可以看出,在汉字字体形状结构相对复杂的时候,本文的模型还是取得了比较好的生成效果,能够较好的捕捉到字体的形状和结构的信息,但是Pix2pix网络模型却产生了笔画缺失,整体模糊的现象。这也在一定程度上证明了本文模型的泛化能力比较强。而Pix2pix、Zi2zi、HGAN这三种模型,虽然在模型训练的过程中产生比较好的效果,但是测试时生成结果却很差。
从表2分析出,从黑体生成字体一,模型的像素差异率最低,均方根误差比HGAN稍高,比Pix2Pix和Zi2Zi低很多;从黑体生成字体二,模型的像素差异率和均方根误差比HGAN稍高,比Pix2Pix高很多;从黑体生成字体三,模型的像素差异率和均方根误差比Pix2Pix、Zi2Zi和HGAN都低很多。所以从定量分析的角度看,文中所建立的模型生成效果较优。
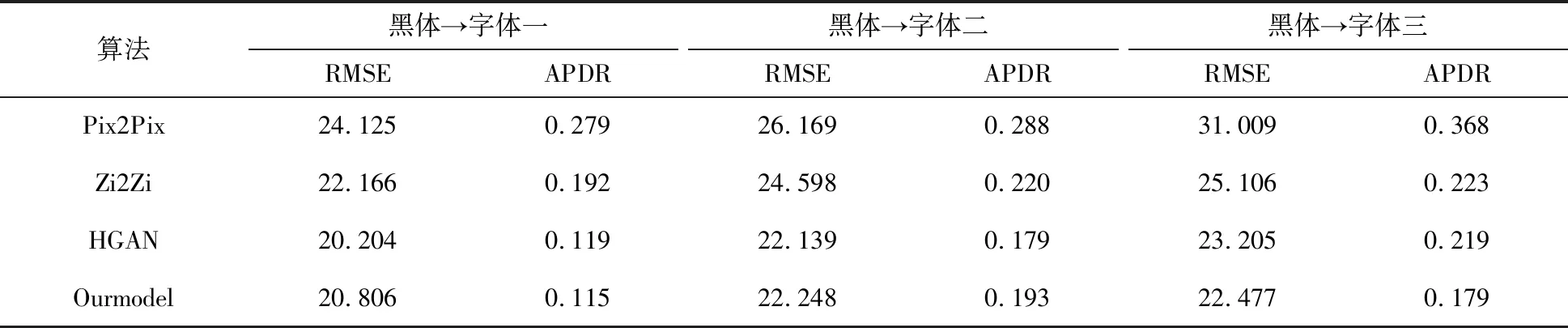
表2 定量分析
为了验证本文提出的感知损失函数的有效性,设计了对比实验,在本文提出的模型中加入感知损失函数以及不加感知损失函数进行对比实验,生成效果如图7。使用感知损失函数,可以看出模型生成的字体轮廓更加清晰,也保证了源字体和目标字体必须保持一致的文字拓扑,生成字体的局部信息丢失较少。但是去除感知函数之后可以发现,生成的字体出现局部信息丢失,字体轮廓模糊的现象,因此也验证了本文提出的感知损失函数的有效性。

图7 使用/不使用感知损失的生成结果示例
在上述的实验对比以及模型消融实验中,采用黑体作为参考字体来进行实验。为了求证不同参考字体对汉字字体生成模型生成效果的影响,本文的实验采用宋体、楷体作为参考字体分别进行实验。实验对比结果如图8~9。

图8 源字体为楷体的部分实验结果

图9 源字体为宋体的部分实验结果
从这两幅实验对比图8和图9可以看出,不管是楷体还是宋体,汉字字体生成模型的生成效果都没有受到影响。这也进一步证明了本文的汉字字体生成模型比现有的汉字字体生成模型的性能更好,能够生成结构层次更加鲜明、细节更加丰富、轮廓更加清晰的汉字。
3 结 语
本文研究了利用生成对抗网络来实现汉字字体生成。通过在不同风格下字体生成效果分析,可以看出本文模型的整体性和一致性均有保证;通过与Pix2pix、Zi2zi、HGAN三种经典模型在同一风格生成效果分析,可以看出本文模型无论在简单还是复杂的字体结构中均取得比较好的生成效果;通过分析不同源字体的生成效果,本文模型的生成效果均没有收到影响。从以上三方面的分析中可以看出本文提出的算法FontToFont与MSAFont均有效地提升了生成字体的质量,在一定程度上满足了实际应用的需求。
