小麦霉菌污染支持向量机判别模型的建立
2021-10-13吕都唐健波赵绪婷刘永翔李俊陈中爱王梅冯亚超
吕都,唐健波,赵绪婷,刘永翔,李俊,陈中爱,王梅,冯亚超
(1.贵州省农业科学院生物技术研究所,贵州 贵阳 550006;2.遵义师范学院生物与农业科技学院,贵州 遵义 563006;3.叶县食品检验检测中心,河南 平顶山 467200)
小麦(Triticum aestivum),为禾本科植物,是一种在世界各地广泛种植的谷类作物,在我国北方地区种植面积大,是主要粮食作物之一,约占全国粮食消费总额的20%[1-2]。小麦营养丰富,易被霉菌污染[3],其富含淀粉、蛋白质、脂肪和矿物质是霉菌等微生物生长的良好培养基[4]。当小麦的储藏条件适宜霉菌和其他微生物生长时,霉菌等微生物会快速繁殖消耗小麦的营养物质[5-6],并产生有毒有害的代谢毒素,造成小麦发霉变质使其商品性降低,甚至会对人畜产生毒害作用[7]。
目前,常用的霉菌污染检测方法主要有平板计数法[8]、酶联免疫法[9]和荧光染色法[10]等,这些方法灵敏度和精准度较高,但是需要的试验试剂多,试验的操作过程比较繁琐,试验花费的时间较长,检测的效率较低。近红外光谱分析技术是由硬件、化学计量学软件和模型三部分构成,傅里叶变换近红外光谱仪用于采集样品的近红外光谱,化学计量学软件用于建立预测模型,预测模型用于待测样品的定量和定性预测分析[11-12]。
常用化学计量学分类算法主要有偏最小二乘判别分析法(partial least squares-discriminant analysis,PLS-DA)和支持向量机分类法(support vector machine classification,SVM)。PLS-DA是一种有监督模式的分析方法,根据已知样品集的特征变量,选定适合的判别准则建立分析模型,将光谱数据与分类变量进行线性回归,对未知样品进行判别分析[13]。样本数量越多、差异性越显著,所建立的PLS-DA判别模型结果越准确[14]。SVM是一种研究小样本统计学习规律理论,由Cortes和Vapnik,在1995年首次提出并阐述了其基本原理[15]。SVM采用结构风险最小化准则来控制学习机器的容量从而揭示了过度拟合与泛化能力之间的关系,在样本量少的情况下,依然能够很好地对样本进行识别[16]。本研究以未污染霉菌的小麦和污染霉菌的小麦样品为研究对象,运用近红外光谱分析技术结合支持向量机分类方法,建立快速鉴别小麦霉菌污染的判别模型,旨在为小麦的储藏安全提供快速检测的技术手段。
1 材料与方法
1.1 材料与试剂
小麦:河南省豫粮粮食集团有限公司;黑曲霉(ATCC 16404):中国工业微生物菌种保藏中心;马铃薯葡萄糖琼脂培养基:上海博伟生物科技有限公司;75%乙醇(分析纯):天津科密欧化学试剂有限公司。
1.2 仪器与设备
60Co辐照场:贵州金农辐照科技有限责任公司;MPA型傅里叶变换近红外光谱仪:德国Bruker公司;YXQ-LS-75SII型高压灭菌锅、SPX-150B-Z型生化培养箱:上海博迅实业有限公司医疗设备厂;SW-CJ-2D型超净工作台:苏州净化设备有限公司;AB104-N电子天平:上海第二天平仪器厂。
1.3 方法
1.3.1 样品制备
用自封袋将小麦样品分装成200g/份,共分装63份。放置在60Co辐照场内进行辐照处理,处理辐照剂量为15 kGy,确保小麦样品中的霉菌和其他微生物都被杀灭。将辐照后的每份样品分为两份。一份不作任何处理,另一份进行模拟霉菌污染。将黑曲霉活化培养,并制备浓度1×106CFU/mL的菌悬液。加入菌悬液模拟霉菌污染,放置在恒温恒湿箱中培养备用,共计126份样品。
1.3.2 近红外光谱的采集
以镀金的漫反射体作参比校正,工作期间,每隔0.5 h扫描一次背景光谱。使用OPUS 7.5软件,调用积分球不旋转程序,扫描光谱区域选用3 594.9 cm-1~12 790.3 cm-1,分辨率为 16 cm-1,扫描次数为 64 次,每个样品扫描3次。每隔1 h,进行1次背景光谱采集。
1.3.3 异常光谱的剔除与光谱数据降维
由于样品制备和人员操作等原因会获得少量异常光谱,这可能会导致模型偏差[17-18]。本试验采用基于马氏距离的主成分分析来剔除异常光谱。近红外光谱吸收谱带重叠严重,因此,需要对其进行降维处理。将原始光谱数据进行“压缩”,获得的少量能代表样本差异和原始数据的变量集合称为主成分[19],并将获得的主成分作为支持向量机的输入变量。用获得的主成分代替原始光谱数据计算马氏距离,马氏距离的阈值范围由阈值权重系数决定,如果样本的马氏距离超过阈值范围,则将该样品定义为需要去除的异常样品。
1.3.4 样品训练集和验证集的划分
在Matlab 2019b中使用基于联合x-y距离的样本集划分法(sample set partitioning based on joint x-y distance,SPXY),将样本按照训练集和验证集之比为3∶1进行划分。
1.3.5 光谱的预处理
为了消除基线漂移、噪声和散射效应对近红外光谱图的影响,本研究采用平滑(smoothing)、卷积平滑导数(savitzky golay derivative,SG derivative)、基线校正(baseline)、标准正态变换(standard normal variate,SNV)、多元散射校正(multiplicative scatter correction,MSC)、消除噪音(noise)、数据元素解析处理(deresolve)和归一化处理(normalize)等预处理方法对输入变量进行处理,以提高模型的稳健性和准确性[20-21]。
1.3.6 SVM判别模型的建立和优化
将主成分作为支持向量机分类判别模型的输入变量,将无霉菌污染样品定义为“1”类,霉菌污染样品定义为“2”类,作为支持向量机分类判别模型的输出变量,使用支持SVM方法建立判别模型。以训练集准确度和内部交叉验证准确度为指标,探究线性核函数(linear)、多项式核函数(polynomial)、径向基核函数(radial basis function,RBF)和 S型核函数(sigmoid)的建模效果,然后采用网格全局寻优算法确定核函数参数C和g的最佳值。
1.3.7 判别模型验证
将31份外部验证集样品(未参与判别模型建立的样品)的近红外光谱数据,带入建好的判别模型中进行验算获得判定结果,对判别模型进行外部验证,根据判别准确度来评价判别模型的预测能力。
1.4 数据处理
本实验数据采用 OPUS 7.5、Unscrambler 10.4、Matlab 2019b、和Origin 9.5.0处理分析和作图。
2 结果与分析
2.1 小麦样品的近红外光谱图
小麦样品的近红外光谱图见图1。
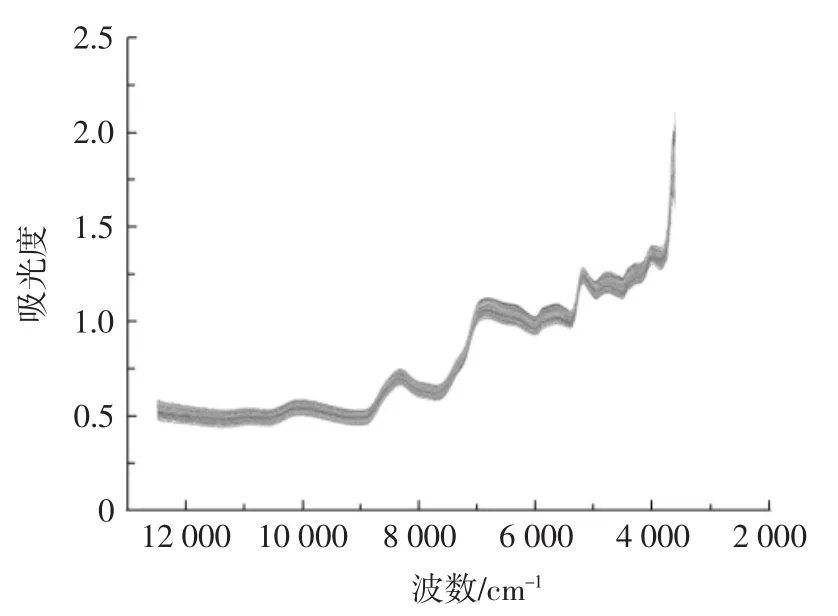
图1 小麦样品的近红外光谱图Fig.1 Near infrared spectra of wheat samples
近红外光谱图主要反映的是有机物中含氢基团(包含C-H、O-H和N-H)振动吸收的情况。由图1可知,未污染霉菌小麦样品的近红外光谱图和污染霉菌小麦的近红外光谱峰形相似,且吸收谱带重叠严重,直接从近红外光谱图中获取的信息较少,因此需要使用化学计量学知识和化学计量学数据软件,对其进行更深的分析处理。
2.2 异常光谱的剔除
基于马氏距离的主成分分析[22]剔除异常光谱图,结果见图2。
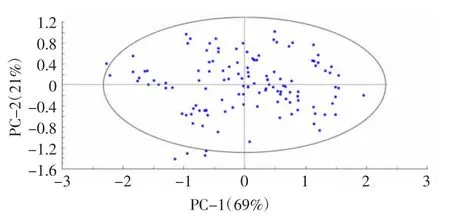
图2 基于马氏距离的主成分分析剔除异常光谱Fig.2 Elimination of abnormal spectra by principal component analysis based on Mahalanobis distance
由图2可知,设置置信区间为95%时,有5个样品被认定为异常样品,将其从样品中剔除掉,剩余有效样品121份。
小麦样品的近红外光谱图含有的信息非常多,将剔除异常光谱样品剩余的121个有效样品,进行主成分分析提取到8个主成分能够代表原始样本的98.80%,主成分分析结果见表1。
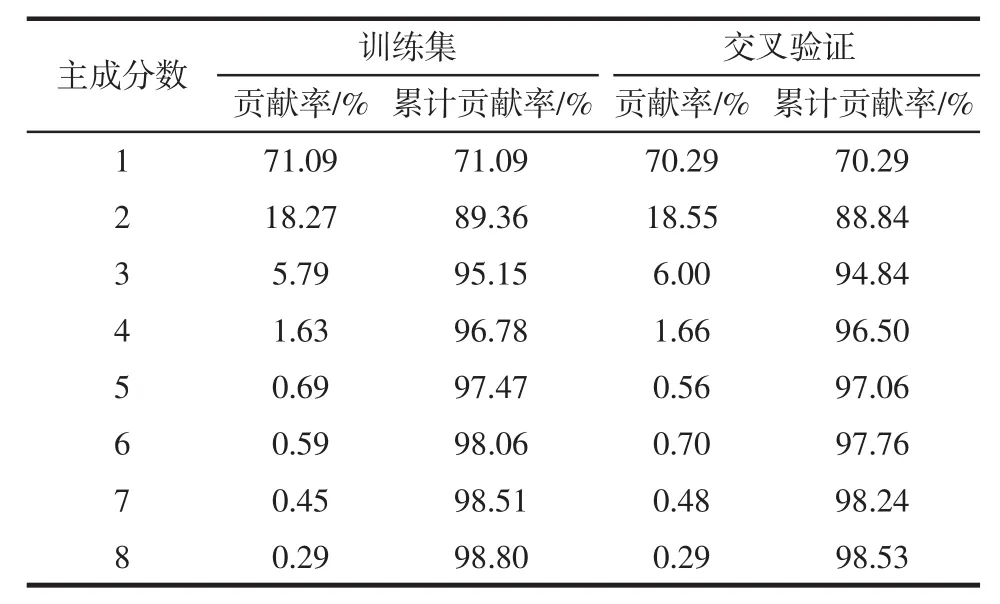
表1 样品主成分分析结果Table 1 Results of principal component analysis of samples
2.3 样品训练集和验证集的划分
将121份有效样品进行主成分分析获得的主成分矩阵,按照训练集与验证集之比3∶1的比例,在Matlab 2019b软件中使用SPXY样本划分方法,将样本划分为训练集90份和验证集31份。将训练集90份样品建立判别模型,验证集31份样品为外部验证样品,对判别模型进行检验。
2.4 最佳预处理方式的选择
采用 smoothing、SG dericative、baseline、SNV、MSC、noise、deresolve和normalize等预处理方法对输入变量进行处理,处理后的输入变量,见图3。

图3 不同预处理方式处理后的输入变量谱图Fig.3 Input variable spectra after different preprocessing methods
选择支持向量机分类模型核函数为RBF,核函数参数C取值1,参数g取值0.125。以训练集准确度和内部交叉验证准确度为指标,将预处理后的输入变量使用支持向量机分类方法建立判别模型,结果见表2。
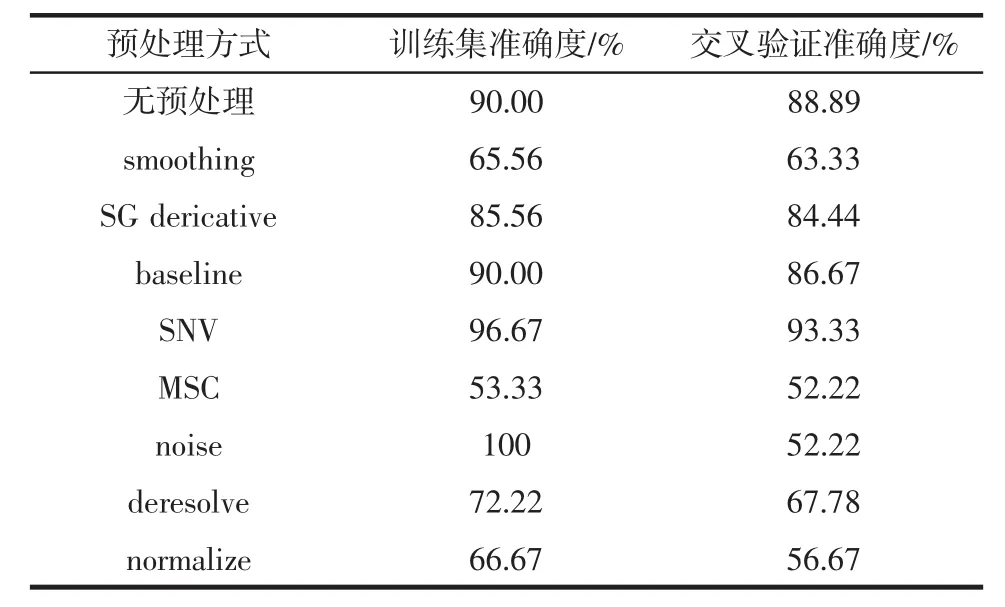
表2 不同预处理方式对判别模型的影响Table 2 The influence of different preprocessing methods on discriminant model
表2结果表明,noise方法处理后,模型的训练集准确度达到100%,但是内部交叉验证准确度只有52.22%,可能是此方法处理的输入变量建立的判别模型出现了过拟合现象。综合内部训练集准确度和内部交叉验证准确度,最终确定SNV为最佳预处理方式,与李军涛[23]的研究结果一致,SNV预处理方式可以消除固体颗粒大小、表面散射以及光程变化对近红外光谱的影响。SVM判别模型的内部训练集准确度为96.67%,内部交叉验证准确度为93.33%。
2.5 SVM判别模型的建立与优化
用最佳预处理方式处理后的输入变量,选择线性核函数(linear)、多项式核函数(polynomial)、径向基核函数(radial basis function,RBF) 和 S型核函数(sigmoid),核函数参数C取值1,参数g取值0.125,建立SVM判别模型,以训练集准确度和内部交叉验证准确度为指标,结果见表3。
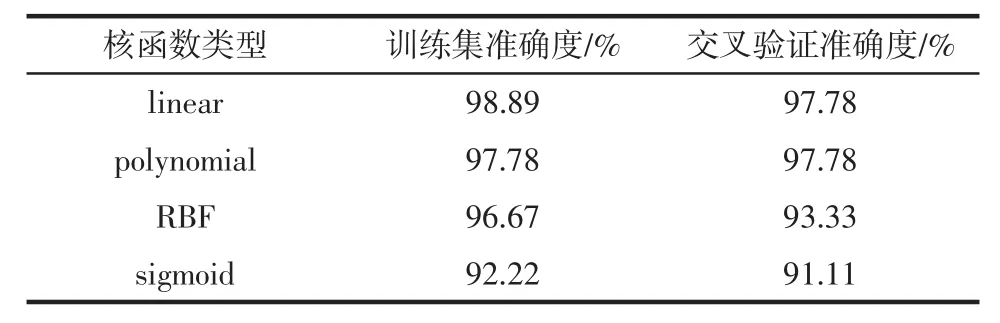
表3 不同核函数对判别模型的影响Table 3 The influence of different kernel functions on discriminant model
表3结果表明,选用的核函数为linear时,建立的判别模型,内部训练集准确度为98.89%,内部交叉验证准确度为97.78%。
以linear为支持向量机分类模型核函数,以训练集准确度和内部交叉验证准确度为指标,由于核函数为linear,核函数参数g值为1,采用网格全局寻优算法[24]确定参数C的最佳值。由于核函数参数C值取值范围较广,为了作图方便,以lgC值为横坐标,以判别模型的准确度为纵坐标,结果见图4。

图4 不同核函数参数C值对判别模型的影响Fig.4 The influence of different kernel function parameter C value on discriminant model
图4结果表明,当核函数参数C值由0.01逐渐增大时,判别模型的训练集准确度和内部交叉验证准确度也随着增大。当核函数参数C值为10时,建立的SVM判别模型,其内部训练集准确度为100.00%,内部交叉验证准确度为98.89%。当核函数参数值C大于10时,内部训练集准确度为100.00%,但是内部交叉验证准确度呈现下降趋势,准确度为96.67%,因此,确定判别模型核函数参数C的最佳取值为10。
2.6 判别模型的验证
将31个外部验证集样品的主成分作为输入变量,带入建立并优化好的SVM判别模型中,获得样品的判别结果,将判别结果与样品的真实分类结果进行比较结果见表4。
由表4可知,16个无霉菌污染样品,即定义为“1”类的样品,全部判定正确;15个霉菌污染样品,即定义为“2”类的样品,全部判定正确。因此,本研究所建立的SVM判别模型识别能力强,可以用于小麦中霉菌污染的快速检测。
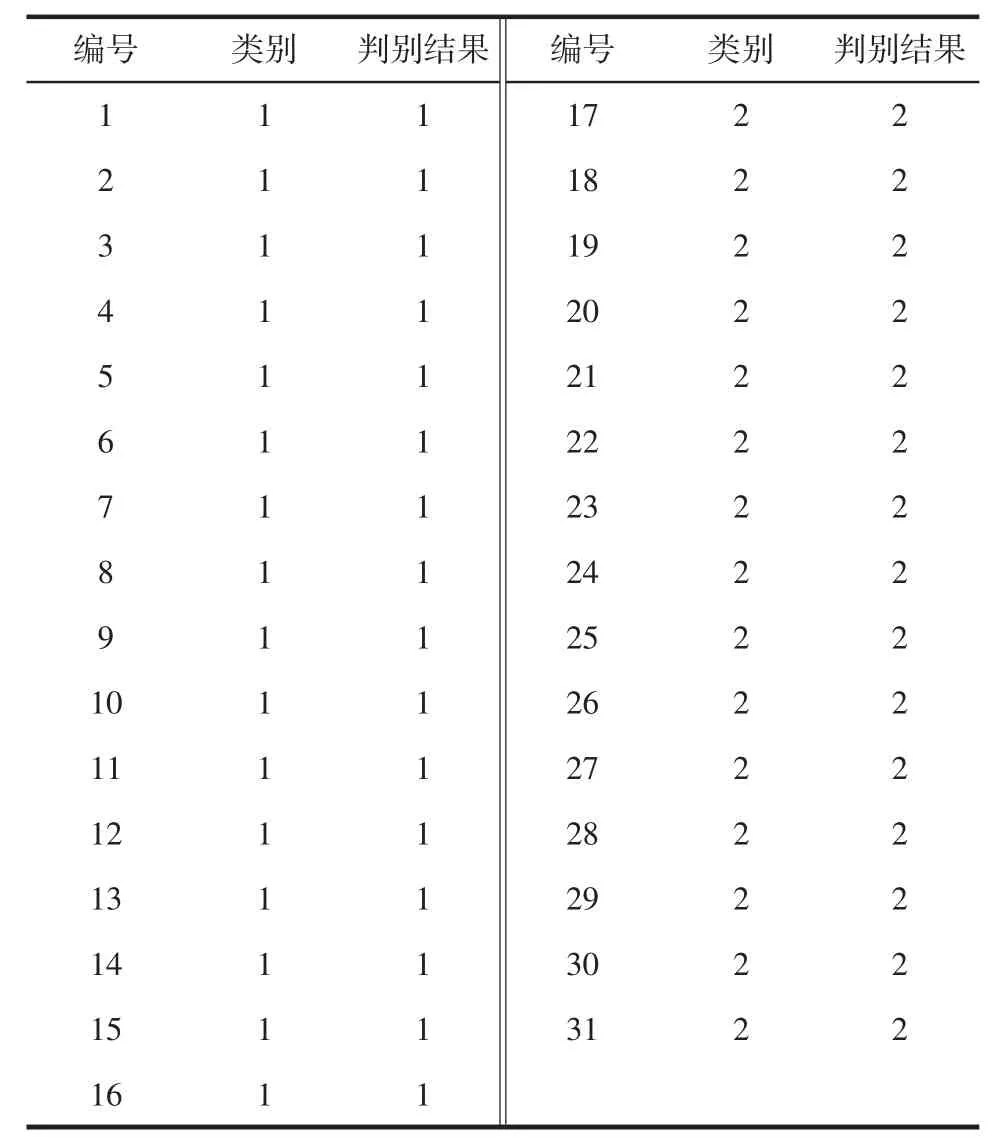
表4 SVM判别模型对外部验证集样品的判别结果Table 4 Discriminant results of SVM discriminantmodel for samples of external verification set
3 结论
本研究采用近红外光谱技术结合支持向量机分类法(SVM)建立快速鉴别小麦霉菌污染的判别模型,并对鉴别模型进行了优化和验证。将小麦样品的原始光谱进行主成分分析提取了8个主成分,能够代表98.80%的样本信息,输入变量的预处理方式为SNV时,SVM判别模型内部训练集准确度为96.67%,内部交叉验证准确度为93.33%。继续优化SVM判别模型的参数,当判别模型的核函数为linear时,SVM判别模型,内部训练集准确度为98.89%,内部交叉验证准确度为97.78%。进一步采用网格全局寻优算法优化核函数linear参数C值,当时核函数linear参数C值为10时,SVM判别模型,其内部训练集准确度为100.00%,内部交叉验证准确度为98.89%。将未参与建立模型的外部验证集31份样品光谱,带入鉴别模型进行判断,模型判断正确率为100%。本研究建立的模型准确可靠,与传统的培养法和化学分析法相比具有检测时间短、操作便捷、检测效率高等优点,可以为小麦的安全储藏提供技术支持。
