基于强化学习的高速飞行器巡航段高度控制
2021-10-13池海红于馥睿郭泽会
池海红, 于馥睿, 郭泽会
(1.哈尔滨工程大学 智能科学与工程学院,黑龙江 哈尔滨 150001; 2.北京空天技术研究所, 北京 100074)
高速飞行器是指飞行速度大于5Ma的飞行器,具有飞行速度快,突防能力强等特点[1]。近年,随着航天技术的发展,高速飞行器成为研究的热点,随着研究的深入和不断的实验验证,它在军事和民用上的作用变得越来越重要。
然而,由于高速飞行器模型具有高度非线性,严重耦合以及参数不确定等特点,有效合理地设计高速飞行器的控制器是非常困难的。除此之外,由于高速飞行器跨介质飞行,其飞行包线大,因此其气动参数呈现出强非线性特点以及明显的不确定性,采用一些传统的控制算法已经不能满足其控制指标的要求。现代控制方法经过几十年的蓬勃发展,已经形成一个完整的体系,将现代控制算法应用在高速飞行器上成为国内外许多学者研究的热点。
文献[2]对高速飞行器纵向模型设计了一种鲁棒自适应Backstepping控制器,将高度子系统分解成弹道倾角回路、攻角回路以及俯仰角速度回路。文中对这几个回路分别设计控制器,并且采用指令滤波方法防止微分爆炸,同时设计自适应律估计不确定参数。文献[3]针对高速飞行器纵向模型设计了一种反馈线性化方法。通过状态反馈,将飞行器高度子系统和速度子系统进行输入输出线性化,分别近似为四阶积分系统和三阶控制系统,最后在此基础上进行滑模控制器的设计。文献[4]针对高速飞行器具有外部扰动以及输入舵偏角饱和的特点,设计了一种基于滑模干扰观测器的抗饱和滑模控制器,对于系统中存在的扰动和不确定性,采用滑模干扰观测器对其进行估计并在滑模控制器中进行补偿。文献[5-7]采用自抗扰控制算法对高超声速飞行器进行控制,将飞行器的外部和内部扰动看作总扰动,设计扩张状态观测器对总扰动进行估计并进行补偿。文献[8]针对传统的扩张状态观测器连续但非光滑的特性,改进了扩张状态观测器,构造了连续光滑的qin函数,在此基础上设计高速飞行器姿态的自抗扰控制算法。由于高速飞行器具有模型阶数高的特点,以上的控制算法中均或多或少地包含了模型信息。由于建模不确定性,这些模型信息有时很难准确获得。
近年,随着人工智能的快速发展,智能控制在飞行器上的应用引起了学者们的广泛关注。由于神经网络具有逼近任意非线性连续函数的能力,因此具有很强的泛化能力。文献[9]将高速飞行器纵向模型转换为严格反馈形式,针对模型的不确定性设计了单隐藏层反馈神经网络对控制器进行学习,采用极限学习机对隐藏层的参数进行学习更新。文献[10]针对高速飞行器外部扰动以及参数不确定的特点,将纵向模型基于欧拉法转换为速度、高度、弹道倾角、俯仰角以及俯仰角速度这5个一阶离散子系统,并对每个子系统设计反馈控制器。由于反馈控制器中包含了模型信息,所以采用神经网络对其进行近似,最后构造李雅普诺夫函数证明系统的稳定性。文献[11]对高速飞行器纵向模型并考虑弹性模态进行连续神经网络控制器的设计。
强化学习作为机器学习的一个分支,由于其不同于以往监督学习的特点,智能体在与环境交互过程中,通过环境的奖励反馈来判断当前动作的品质,在这种与环境交互学习的过程中,控制策略收敛的方法不需要了解被控对象的内部模型信息,因而这种模拟人类学习过程的方法近几年被广泛关注。在强化学习控制中,由于因果性,普遍采用神经网络来近似性能指标以及控制策略。文献[12]对高速飞行器纵向模型进行强化学习与滑模结合控制,其中滑模控制器的作用是稳定系统,强化学习为辅助控制,用于在线估计扰动。文献[13]采用强化学习方法对高速飞行器纵向模型的建模不对定性进行估计,并采用鲁棒自适应控制进行系稳定以及对估计的建模不确定性进行补偿。
以上文献中提及高速的强化学习方法都是将强化学习作为辅助控制的,最核心的控制依然是现代控制。本文提出的基于强化学习的高速飞行器高度控制算法,不同于以上文献,本文将强化学习作为核心控制,并且以强化学习控制作为系统唯一的稳定控制算法。本文提出的算法不包含任何模型信息,只需要输入输出量及其相应导数即可。对于模型不确定问题,在仿真试验中,对气动参数进行正负极限拉偏,从而验证本方法对于模型不确定性依然有很好的控制效果。
1 高速飞行器高度纵向模型
高速飞行器高度纵向模型为:
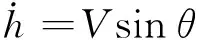
(1)
(2)
(3)
(4)
式中:h为飞行高度;θ为弹道倾角;α为攻角;ωz为俯仰角速度;V为飞行速度;L为升力;T为推力;m为飞行器质量;Mz为俯仰力矩;Jz为转动惯量。L、T、Mz、r、q计算表达式为:
L=qSCL
(5)
T=qSCT
(6)
(7)
r=h+Re
(8)
(9)
式中:q为动压;ρ为大气密度;CL、CT和CM分别为升力系数、推力系数以及俯仰力矩系数;S为飞行器参考面积;r、Re分别为地心距和地球半径。纵向气动参数为:
CL=0.620 3α
(10)
CM(α)=-0.035α2+0.036 617α+5.326 1×10-6
(11)
CM(δe)=ce(δe-α)
(12)
(13)
由于高速飞行器采用的是超燃冲压发动机,在飞行过程中攻角要保持在一定小的范围内,因此式(2)中L+Tsinα≈L。在高速飞行器巡航飞行过程中,弹道倾角始终保持在较小值,即使做高度机动动作,变化的高度相对于飞行器所在高度仍然是可以忽略的,因此弹道倾角在飞行器做高度机动的过程中看做较小值也是合理的。因此式(1)可变为:

(14)
假设在高速飞行器做高度机动的过程中,速度保持为定值。对式(14)求导并将式(2)代入式(14)可得:
(15)
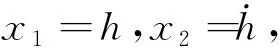
(16)
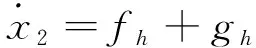
(17)
式中ϑ为俯仰角。fh与gh表达式为:
(18)
(19)
根据几何关系:ϑ=α+θ。令x3=ϑ,x4=ωz,则式(3)和(4)可写成:
(20)
(21)
fϑ与gϑ表达式为:
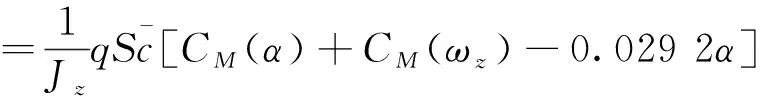
(22)
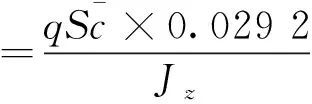
(23)
2 强化学习控制器设计
2.1 BP神经网络逼近
在强化学习控制器中,BP神经网络将被用于逼近控制策略和性能指标函数。BP神经网络理论上在节点足够多的情况下能够以任意精度逼近定义在紧集Ω⊆Rn上的任何非线性连续函数。BP神经网络在输入量x=[x1x2…xn]T∈Ω⊆Rn与输出量y∈Rn之间形成的映射定义为:
y=ωTφ(vTx)
式中:ω∈RN×1为隐藏层和输出层之间的权值;N为隐藏层节点数;φ(·)为隐藏层的激活函数通常取为φ(·)=tanh(·);v∈Rn×N为输入层和隐藏层之间的权值。对于一个未知连续非线性函数f(x),存在理想权值ω*∈RN×1使得:f(x)=ω*Tφ(vTx)+ε,|ε|≤εM。ε和εM分别为逼近误差和逼近误差的上界。
2.2 高度子系统强化学习控制器设计
高度子系统强化学习控制器设计的目的是使飞行器高度能够以一定精度并且稳定地跟踪期望高度指令hd。高度子系统的输入是期望俯仰角ϑd。这里假设飞行器的高度、俯仰角能够通过传感器测量得到。
令x1d=hd,定义高度跟踪误差为:
eh=h-hd=x1-x1d
(24)
定义滤波误差为:
(25)
式中λh>0,λh∈。
求导可得:
(26)
理想控制律可以设计为:
(27)
由于理想控制律中包含fh、gh等模型信息,因此在实际中不能应用。接下来,将采用强化学习来进行控制器设计,该控制器结构由动作网络和评价网络组成,评价网络的作用是根据飞行器当前状态来评价表现好坏,动作网络则是根据评价网络的评价输出来产生相应的控制量。
2.2.1 评价网络设计
定义性能指标函数为:
(28)


(29)
评价网络的作用是通过当前飞行器的状态信息从而输出对性能指标函数的估计值。因此评价网络设计为:
(30)

2.2.2 动作网络设计
动作网络的作用是根据评价网络对性能指标函数的估计值来计算控制量。对于理想控制律(27),可以采用动作网络来对其进行逼近。动作网络设计为:
(31)
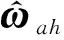
那么理想控制律(27)可表示为:
(32)
2.2.3 评价网络权值更新
对于评价网络,其权值更新的目标是最小化估计误差ech。因此定义评价网络的目标函数为:
(33)
根据梯度下降法,评价网络更新律为:
(34)
式中σch为评价网络的学习率,0<σch<1。
对式(34)进一步推导:
(35)

2.2.4 动作网络权值更新
动作网络的逼近误差为:
(36)


(37)
动作网络权值更新的目标就是最小化目标函数。因此根据梯度下降法,评价网络更新律为:
(38)
式中σah为动作网络的学习率,0<σah<1。
对式(38)进一步推导:
(39)
由于在动作网络权值更新律表达式中存在ξah项。因此无法将其获得。接下来,根据滤波误差表达式来将其求出。
由式(26)可得:
(40)
将式(31)和(32)代入式(40)可得:
gh(ξah-εah)-K1rdh
(41)
因为εah很小可忽略,所以可以求得:
(42)
将式(41)代入式(39)可得:
(43)
因此,经过一系列推导之后得出的动作网络权值更新律中的所有项均可获得,而且不包含任何模型信息。
2.3 姿态子系统强化学习控制器设计
姿态子系统强化学习控制器的设计目的是使飞行器的俯仰角能以一定精度并且稳定地跟踪由高度子系统产生的期望角指令ϑd。姿态子系统的输入是升降舵偏角δe。由于姿态子系统数学模型的形式与高度子系统一致,所以姿态子系统强化学习控制器设计步骤也与高度子系统相同。
令x3d=ϑd,定义俯仰角跟踪误差为:
eϑ=ϑ-ϑd=x3-x3d
(44)
定义滤波误差为:

(45)
式中λϑ>0,λϑ∈R。
对滤波误差求导可得:
(46)
理想控制律可以设计为:
(47)
2.3.1 评价网络设计
定义性能指标函数为:

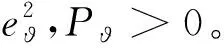

(48)
评价网络设计为:
(49)
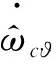
2.3.2 动作网络设计
动作网络设计为:
(50)
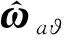
那么理想控制律(47)可表示为:
2.3.3 评价网络权值更新
(51)
式中σcϑ为评价网络的学习率,0<σcϑ<1。
对式(51)进一步推导:
(52)

2.3.4 动作网络权值更新
动作网络的逼近误差为:
(53)
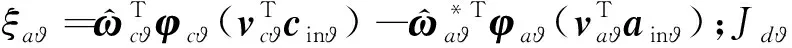
姿态子系统动作网络权值更新律的推导步骤与高度子系统完全相同,这里直接给出动作网络权值更新律表达式:
(54)
2.4 高速飞行器纵向高度强化学习控制算法结构图
综合前2部分的推导,基于强化学习的高速飞行器高度控制算法结构图如图1所示。

图1 控制器结构Fig.1 Controller structure
3 仿真分析
本文采用数值仿真来验证所设计的强化学习高度控制算法的有效性。飞行器的模型采用的是式(1)~(4)的非线性模型进行的数值仿真。飞行器的初始状态为:V=4 590.3 m/s,h(0)=33 528 m,θ(0)=0°,α(0)=0°,ωz(0)=0°/s。机动后高度为h(∞)=34 028 m,机动爬升高度为500 m。期望高度变化参考模型为:
式中:hd为高度参考指令;hc为机动后高度;ω1=0.2,ω2=0.1,ζ=0.7。
强化学习控制器参数为:高度子系统与姿态子系统的动作网络和评价网络的隐藏层节点数均为20,即Nch=Nah=Ncϑ=Naϑ=20。
vch、vah、vcϑ、vaϑ取(0,1)的随机数并且保持不变。wch、wah、wcϑ、waϑ初始值均为0。学习率σch=0.2,σah=0.2,σcϑ=0.2,σaϑ=0.2。λh=300,λϑ=300,Ph=50,Pϑ=50,K1=5,K2=15。
3.1 标称状态下仿真分析
在气动参数无拉偏条件下仿真结果如图2~6所示。由图2可以看出,对于高度子系统来说,所设计的强化学习控制器能够快速稳定地跟踪高度参考指令。姿态子系统跟踪曲线如图3所示,俯仰角同样能够快速稳定地跟踪高度子系统的俯仰角指令。图4为升降舵偏角变化曲线,从图4中可以看出,舵偏角始终保持在合理范围内。图5和图6分别为评价网络权值变化曲线和动作网络的权值变化曲线,可以看出评价网络的变化曲线逐渐趋于收敛且稳定,动作网络权值曲线变化逐渐趋于平稳并收敛,因此控制策略也随之收敛。
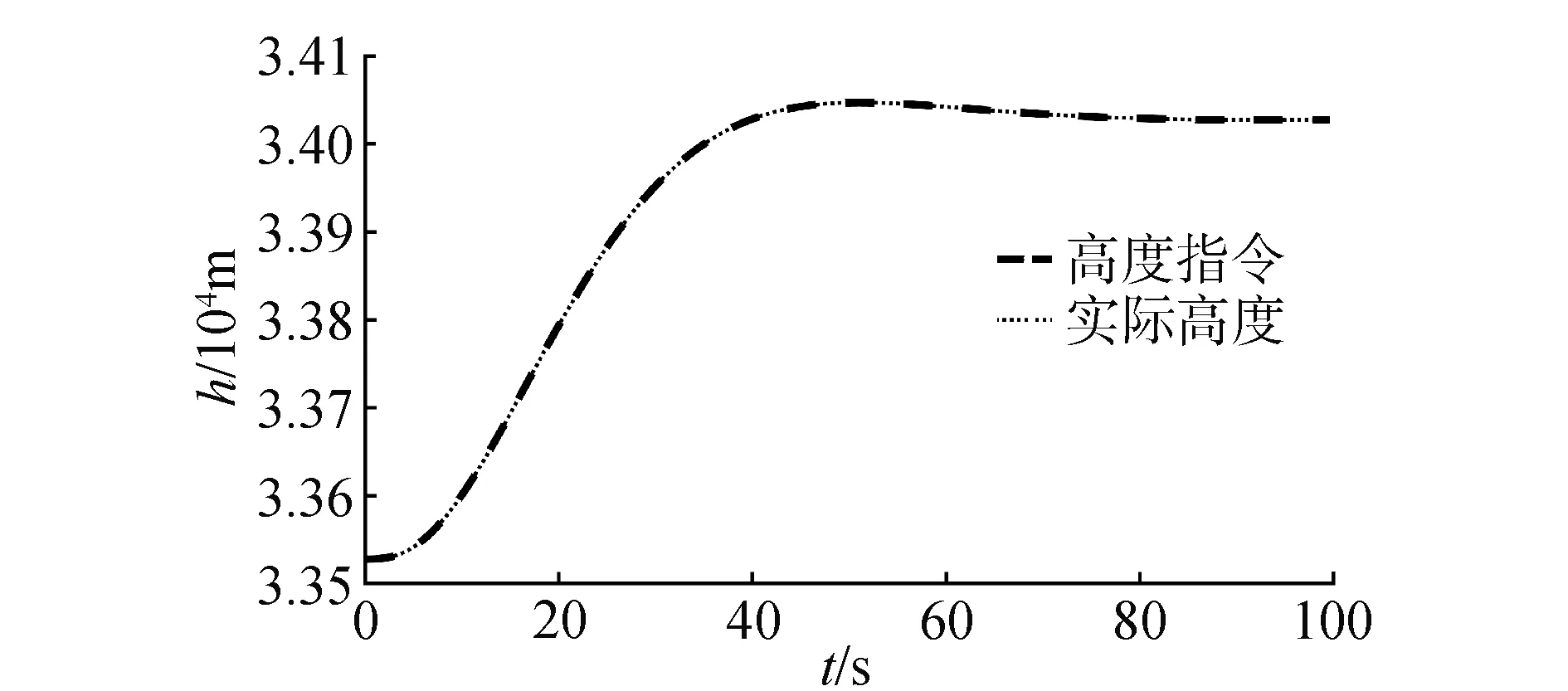
图2 高度跟踪曲线Fig.2 Altitude tracking

图3 俯仰角跟踪曲线Fig.3 Pitch angle tracking

图4 升降舵偏角变化曲线Fig.4 Elevator deflection

图5 评价网络权值变化曲线Fig.5 Critic NN weights

图6 动作网络权值变化曲线Fig.6 Actor NN weights
3.2 极限拉偏状态下仿真分析
在建模具有参数不确定性时,通过仿真验证所设计的强化学习控制器的控制性能。采用正反极限拉偏来验证所设计的控制器的控制能力,拉偏条件I为:CL拉偏+10%,CM拉偏+30%,m拉偏+5%,Jz拉偏+5%,ρ拉偏+5%。拉偏条件II为:CL拉偏-10%,CM拉偏-30%,m拉偏-5%,Jz拉偏-5%,ρ拉偏-5%。
在气动参数拉偏条件下仿真结果如图7~10所示。在极限拉偏I和极限拉偏II条件下,所设计的强化学习控制算法依然能够使高度快速、稳定地跟踪高度参考指令。说明设计的强化学习控制算法对模型参数不确定依然具有很好的控制效果。

图7 拉偏情况下高度变化曲线Fig.7 Altitude tracking with deviations

图8 拉偏I情况下俯仰角变化曲线Fig.8 Pitch angle tracking with deviations I
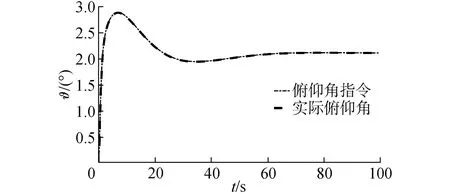
图9 拉偏II情况下俯仰角变化曲线Fig.9 Pitch angle tracking with deviations II
3.3 与PID控制算法相对比
将本文提出的算法与传统PID相对比,姿态子系统分别采用内环俯仰角速度反馈的阻尼回路,外环采用PI控制,高度子系统采用PI控制。2种算法的对比结果如图11、图12所示。从图中可以看出,对于稳态阶段,2种控制算法的稳态误差都在可接受范围内,误差大小没有实质上的区别。但是在动态过程,PID控制算法响应要慢于本文提出的控制算法,本文提出的算法能快速跟踪期望轨迹,但是PID控制算法要稍滞后于期望轨迹。从而验证了本文提出的算法的有效性。

图11 高度跟踪曲线Fig.11 Altitude tracking

图12 俯仰角跟踪曲线Fig.12 Pitch angle tracking
4 结论
1)对飞行器参数标称情况以及极限拉偏情况下均做了仿真试验,同时将本文提出的算法与传统PID控制算法进行对比,验证了其有效性。仿真结果表明,本文提出的方法对高速飞行器参数不确定的情况下有很好地控制效果。
2)本文提出的控制器不需要精确了解飞行器的模型信息,因此减少了对模型的依赖,为高速飞行器高度控制系统设计提供了一种新的思路。
