基于属性相关性与特征选择的K-近邻缺失值顺序填充算法
2021-10-12唐晗


摘要:由于K-局部近邻插补算法无法直接计算相关性,因此在插补时难以进行特征选择,提出一种基于属性相关性的对于多维数据缺失按顺序并进行特征选择的填充方法,在解决相关性计算的问题同时提出了采用相关性进行填充顺序选择。算法首先提取完整数据集或者投影计算距离相关性,并按照一定的方式按相关性从大到小进行填充,保证在填充时不会因为特征选择出现参照数据集为空的情况,在填充时选择大于相关性临界点的特征在投影的基础上进行近邻填充。实验分别在不同缺失率下计算该方法与其它算法的均方误差结果,结果表明,该算法在填充效果上明显优于其它算法。
关键词:距离相关性;特征选择;顺序插补
引言
数据缺失在现实中是一种非常常见的现象,它产生的原因可能是信息难以获取或者是数据传输中发生错误产生遗漏。数据缺失会导致模型难以建立,使决策分析无法达到好的效果。数据挖掘中预处理占最大比重,而预处理中最关键的就是对缺失数据的处理。
常用的处理方法有加权法、删除法和插补法。加权法通过某些方法把权数从缺失单位上转移到非缺失单位上,删除法则是直接删除存在缺失单位的样本,直接得到一个完整的数据集。删除法虽然简单,但当缺失率比较高的时候可能会删除较多的样本,产生较多误差,因此国内外学者更希望采用其他方法来填补不完整数据,以保证数据的质量,即插补法,插补法是用一个或者多个估计值来代替缺失值的方法,前后分为单值插补和多重插补,常用的单值插补有均值填充、回归填充、冷卡填充和热卡填充等。
K-近邻填充(K-nearest neighbor imputation, KNNI)是一种比较典型的冷卡填充,它是Olga Troyanskaya提出的基于局部相似性的插补算法,它将完整数据集提取出来,缺失值的近邻样本将从完整数据集中提取,分类值采用众数填充,连续值采用平均数填充,这种方法的填充效果极大程度上收到了缺失率的影响,当缺失率极大时,完整数据集的样本数量将会非常少,这意味着这种情况下得到的近邻样本实际上相似性并不高,这可能导致产生较大的误差,在这个基础上,杨日东、李琳等提出了基于局部K近邻的填充算法,它并不直接提取完整数据集,而是在填充缺失值时,将当前样本的完整属性投影出来,并根据属性投影结果从数据集中提取完整数据集,这在缺失率较大的情况下极大地改善了K近邻插补的缺陷,但以上都并未考虑过属性相关性以及填充顺序对填充准确率的影响。刘春英提出了一种基于属性依赖度的顺序填充方法,利用填充树按依赖度从大到小进行填充。谢霖铨、赵楠等和张晓琴、王敏都采用了主成分分析法进行二次插补。现有的将相关性应用到算法中的方法很多,但对于填充顺序进行处理的方法却相对较少,本文将通过距离相关性研究填充顺序与特征选择在提升K-近邻填充准确率的能力。
1相关概念与原理
距离相关性(Distance Correlation)
皮尔逊相关系数常被用于度量两个变量之间的线性相关程度,两个变量必须服从正态分布的假设,对于非线性关系无法进行测量,即pearson相关系数为0时,两个变量不一定是独立的,自然界中的变量仍有大部分是非线性关系,而距离相关系数能很好地克服这个缺点,距离相关系数为0时,我们可以说这两个变量一定是独立的。王黎明、吴香华等对比了皮尔逊相关系数、秩相关系数、距离相关性的利弊,最终采用距离相关系数来衡量预报因子和PM2.5之间的相关性。
研究变量 和 的独立性,记为 。当 时, 和 相互独立; 越大,代表 和 的相关性越强。设 是总体 的随机样本, Székely等 (2008) 定义两随机变量的 和 的DC样本估计值为
1.2K-局部投影
传统K-近邻填充在缺失率较大的时候可能导致完整数据集的样本数量过小或者为空,填充时难以找到真正的近邻,K-局部近邻插补针对这个缺点做了改进,使能够参考的完整数据集更多。
K-局部近邻插补中,投影是其中最关键的部分。若样本 在属性 上的值是缺失值,对于 在数据集T上投影的完整数据子集为TC,其中 ,任意 对应的TC都是不同的。例如表1来说,如果需要對数据aB进行填充,那么缺失属性集 ,完整数据子集 ,近邻样本则在TC中取舍。而对于传统K-近邻填充,完整数据集 。
1.3基于属性相关性与特征选择的K-近邻缺失值顺序填充算法
在K-局部近邻插补中,插补从样本中缺失值最多、属性中缺失最少的数据开始,这说明算法的插补顺序完全是由数据的缺失分布确定的,并且在计算样本相似度时,也未曾考虑属性之间的依赖程度,这可能导致相关性不高的属性介入相似度计算,使计算出的近邻是相似度不高的伪近邻。如果要在该算法基础上将相关性计算与它结合,有缺失值的数据集会无法进行相关性的计算,若在对每个缺失值做相似度计算前计算属性的相关性再进行属性筛选,这将极大地增加算法的运行时间与复杂度。因此本文将K-近邻插补和K-局部近邻插补两种算法结合后进行改进,使属性相关性能够同时对填充顺序和特征选择作出干预,同时最小化相关性计算、顺序填充和特征选择的运算时间代价。
1.3.1 属性相关性计算
K-近邻插补的优点在于它直接筛选出没有缺失值的完整数据子集,所有插补计算都在这个完整数据子集上进行,因此它十分简便,计算速度也很快。由于不存在缺失值,距离相关性也可以在完整数据子集上很方便地计算出来。但K-近邻插补的缺点在于,当缺失率较大时,无法找到完整数据子集或者子集容量太小无法进行计算,此时将属性两两筛选完整子集进行相关性计算,最终计算出属性相关性矩阵C。
在数据集 中,属性集 的数量为 , 表示标签列的数量,样本数量为 ,样本中存在缺失值的属性集为 ,该数据集相关性矩阵为 。 变量 的距离相关性, ,因此 为轴对称矩阵,其中 。当缺失率较小、通过删除法得到的完整数据子集 的样本数量i'占数据集T样本数量i的比例≥一个给定的 假设值时,直接使用完整数据子集通过式(1)计算相关性矩阵 ;当缺失率较大,可能导致比率 时,通过对数据集 的属性列 作删除法,将得到的子集 通过式(1)计算相关性矩阵 。
1.3.2 特征选择
在进行插补时,如果采用全部的属性集做近邻插补,某些属性与待填充数据的属性相关性较小或者是相互独立的情况下,无论是计算相似度还是近邻填充都会扭曲近邻分布,降低插补的准确率,因此需要根据相关性剔除参照属性中相关性过低的属性。参照属性指的是对于待插补值选出的用于计算近邻的完整数据集的属性,参照集是该完整数据集。对于待插补值 ,首先通过投影得到参照数据集D,其中属性集为 ,设定相关性临界点Cr,当 中的属性在相关性矩阵 中的属性 列中的对应值小于 时将剔除该属性列。
当 时,算法不做特征处理,相当于有排序的K-局部近邻插补; 时,表示只有强相关的属性才能进行近邻计算,此时将无法进行填补运算。经过大量实验, 的取值在0.6左右表现为最好。
1.3.3 顺序选择
由于本文针对的是属性中的缺失值插补,而标签中的数据是完整的,因此当标签列作为参照属性时,不会减少参照集的样本数量,因此当按照与标签的相关性从大到小的顺序进行插补能得到较多的参照样本数量,在极限情况下与当前属性的相关性只有标签列达到临界点要求时,不会出现参照集太小或者为空的情况。
选择第二个填充列时,选择 中使值最大的 作为当前填充列 ,以此类推,直到填充完毕。
1.3.4 极端情况
当数据集的缺失率较大时,存在一种情况,即选择的填充列 与其它属性列的相关性并不大,甚至小于 ,该列在特征选择上会删除所有的参照集的属性,导致无法进行插补。对于这种情况,本文作如下设计:对于当前设定的相关性临界点 ,如果在填充时由于 比较高导致参照集为空,那么将 减去一定的值,直到使参照集非空,然后在下一个缺失值填补时返回原设定的 值。
1.4算法的实现
基于属性相关性与特征选择的K-近邻缺失值顺序填充算法流程如图1所示。
2实验结果及分析
2.1 实验方法
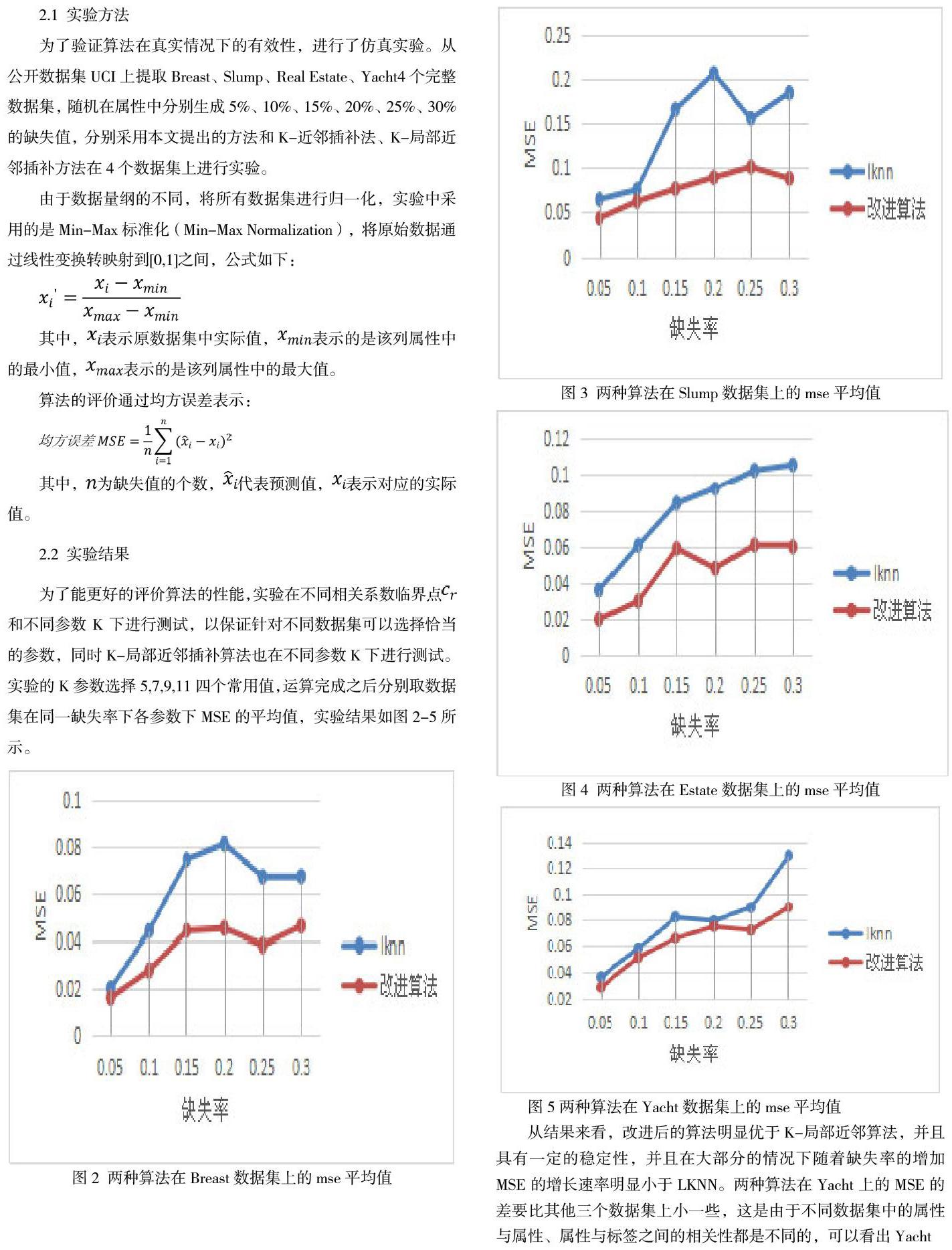
为了验证算法在真实情况下的有效性,进行了仿真实验。从公开数据集UCI上提取Breast、Slump、Real Estate、Yacht4个完整数据集,随机在属性中分别生成5%、10%、15%、20%、25%、30%的缺失值,分别采用本文提出的方法和K-近鄰插补法、K-局部近邻插补方法在4个数据集上进行实验。
由于数据量纲的不同,将所有数据集进行归一化,实验中采用的是Min-Max标准化(Min-Max Normalization),将原始数据通过线性变换转映射到[0,1]之间,公式如下:
从结果来看,改进后的算法明显优于K-局部近邻算法,并且具有一定的稳定性,并且在大部分的情况下随着缺失率的增加MSE的增长速率明显小于LKNN。两种算法在Yacht上的MSE的差要比其他三个数据集上小一些,这是由于不同数据集中的属性与属性、属性与标签之间的相关性都是不同的,可以看出Yacht数据集的相关性比较强,导致即使做了特征选择,剔除的属性也没有其他三个数据集多,使算法和K-局部近邻方法更相当一些。
3结语
为解决特征选择无法直接在KNN局布近邻插补法上使用的问题,本文采用K近邻插补算法中提取完整数据集的方法计算距离相关性,并采用距离相关性同时对插补顺序和特征选择进行了融合改进,通过观察仿真实验结果,可知基于属性相关性与特征选择的K-近邻缺失值顺序填充算法在填充准确率上明显优于K-局部近邻插补算法。
但算法也有不足之处,在属性值较多的情况下,频繁进行特征选择将大量提高算法的时间复杂度,在未来的研究中将会对这一不足之处进行优化。
参考文献
[1]LUKASZ A K, PETR M. A survey of knowledge discovery and data mining process models[J]. Knowledge Engineering Review, 2006, 21(1):1-24.
[2]邓建新,单路宝,贺德强,唐锐.缺失数据的处理方法及其发展趋势[J].统计与决策,2019,35(23):28-34.
[3]王敏. 基于成分数据的缺失值补全方法研究[D].山西大学,2016.
[4]晔沙.数据缺失及其处理方法综述[J].电子测试,2017(18):65-67+60.
[5] TROYANSKAYA O, CANTOR M, SHERLOCK G, et al. Missing value estimation methods for DNA microarrays. Bioinformatics, 2001, 17(6): 520-525.
[6]杨日东,李琳,陈秋源,周毅.LKNNI:一种局部K近邻插补算法[J].中国卫生统计,2019,36(05):780-783.
[7]刘春英.基于属性依赖度的缺失值顺序填充算法[J].计算机应用与软件,2013,30(09):215-218.
[8]谢霖铨,赵楠,徐浩,毕永朋.基于属性相关性的K N N近邻填补算法改进[J].江西理工大学学报,2019,40(01):95-101.
[9]张晓琴,王敏.基于主成分分析的成分数据缺失值插补法[J].应用概率统计,2016,32(01):101-110.
[10]王黎明,吴香华,赵天良,程国胜,张祥志,汤莉莉,贾梦唯,陈煜升.基于距离相关系数和支持向量机回归的PM_(2.5)浓度滚动统计预报方案[J].环境科学学报,2017,37(04):1268-1276.
作者简介:唐晗,女,1993年11月,汉,江西省吉安市,工学学士,江西应用工程职业学院,数据挖掘。
