基于查询语言转换的多源数据统一访问框架①
2021-10-11李跃鹏温亮明黎建辉
李跃鹏,温亮明,黎建辉
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
1 引言
大数据应用系统是由多种数据处理工具构成的集成性系统,其数据结构、数据存储位置、数据管理与分析工具等均具有多样化特点[1,2].例如在电商系统中,通过关系数据库管理用户交易数据,商品数据存储于文档数据库;为加快系统响应速度,通过Key-Value 数据库缓存高频率访问数据;统计报表使用流处理工具、SQL 查询引擎等进行历史数据统计分析.在科学大数据管理领域,科研项目通过领域关系型数据库管理从传感器、遥感卫星等科学装置获得的实验数据;使用领域非结构化数据库进行高能物理对撞机事件数据的存储与索引;通过图数据库管理物种、基因组等知识图谱数据;借助领域数据分析工具对各类实验数据进行统计与交叉分析,进而得出实验结论[3].大数据集成系统使用的数据处理工具分为两类:数据提供者使用标准查询语言、WebService 等接口方式提供数据库、开放平台等基础数据管理服务;数据消费者调用多个数据提供者接口获取数据,并通过标准查询语言、WebService 等接口对多源异构数据进行查询、统计、分析、展示等操作,如SQL 查询引擎、数据仓库、管理系统等.数据消费者与数据提供者之间的数据访问方式具有以下特点:
(1)数据访问接口各异:数据提供者接口需经转换才能符合数据消费者的接口格式要求.比如报表系统中,数据消费者使用SQL 语言对数据进行统计,然而数据提供者的服务接口为文档查询、WebService 以及文件等形式.
(2)数据访问模式多样:数据消费者与数据提供者之间是多对多数据访问方式.例如数据仓库使用SQL语言对多个异构数据源进行分析;而异构数据源除了为数据仓库提供服务,还会被多个部门或外部应用系统消费.
(3)松耦合方式集成:数据消费者与数据提供者独立运行、部署与迭代更新.例如作为数据提供者,存储用户、业务与实验等数据的数据库会根据技术、场景等因素进行更新,然而数据消费者的访问接口却并不改变;相反,数据消费者会根据业务、性能等需要调整数据消费者的数据访问接口.
基于以上数据访问特点,要实现数据提供者接口与消费者接口的交互协作,集成系统必须提供一个接口适配器以满足双方需要,目前已有研究特定应用场景接口适配器的相关工作.随着数据提供者与数据消费者工具的更新变化,这种针对特定应用场景的一对一型接口适配器势必难以适应数据迁移与工具迭代更新需要,因此我们提出了一种基于查询语言转换的多源数据统一访问框架,通过引入中间数据模型和双端适配器将数据访问接口API 与实际数据模型相分离,使得集成系统具有更好的灵活性和扩展性.
2 相关工作
接口适配器以数据消费者数据模型或数据提供者数据模型作为中间数据模型.首先将数据提供者或数据消费者的Schema 映射为中间数据模型,然后通过数据转换或查询语言转换方式完成接口适配转换.数据转换适配器将数据提供者所持有数据动态或一次性转换为消费者可识别的数据格式进行存储或处理;查询语言转换适配器将数据消费者端的查询语言转换为数据提供者端的查询语言.
根据数据消费者对数据提供者的访问方式,数据消费者与数据提供者的接口适配方式分为一对一适配、多对一适配以及多对多适配3 种(如图1(a)至图1(c)所示).
(1)一对一适配:采用查询语言转换方式将数据消费者接口转换为数据提供者查询语言.例如文献Sql2Saprql (RETRO)[4]、Sparql2Sql (D2RQ)[5]、Cypher2sql (Cytosm)[6]等提出了将不同查询语言转换为SQL 查询语句或将SQL 查询语句转换为其它查询语言的方法.
(2)多对一适配:以消费者数据模型为中间数据模型,数据提供者向统一模型动态提供适配数据.例如SparkSQL[7],Presto[8]、Impala[9]等SQL 查询引擎适配器将关系数据库、文档数据库、CSV 文件、JSON 文件等数据源动态转换为临时关系表来实现SQL 统一查询.Gradoop 适配器将异构数据动态转换为属性图模型的节点和边来实现Cypher 语言统一查询[10].
(3)多对多适配:为数据提供者和数据消费者提供接口适配.例如Polystore[11]要求系统支持多种全局数据模型与本地数据模型之间的转换,通过数据提供者与数据消费之间的成对查询语言转换适配器为上层应用提供多样化数据查询接口.
以数据访问接口适配方法存在的问题是中间数据模型与查询语言模型绑定,使得接口适配器只在单个数据提供者与数据消费者之间产生效用.对于数据转换适配器,当多个数据消费者的数据模型不同时,数据提供者必须向数据消费者提供不同的适配数据.对于查询语言转换适配器,多对多访问同样必须采用case by case 方式实现成对查询语言转换.当系统中存在n个异构数据提供者和n个数据消费者时,要支持多对多访问就必须开发n!个适配器,如果新增一个异构数据提供者则需要实现2n个转换器,从而影响系统对新数据源的扩展性.因此,本文尝试探索提出一种双适配器数据统一访问框架(如图1(d)所示),通过数据提供者与数据消费者两端适配器将查询语言与数据模型分离,从而对新数据提供者与数据消费者的支持只要按需实现一个适配器即可.

图1 数据提供者与消费者接口适配方式
3 框架设计
双Adapter 数据统一访问框架BAF4DUA 将多个异构数据消费者与数据提供者接口进行适配,为上层应用提供多样化的数据服务接口.该框架使用中间模型统一表示数据提供者所持有数据,中间查询计划统一表示消费者与提供者查询语言的语义;数据消费者与数据提供者两端分别与中间模型进行接口适配,将数据访问接口与数据模型分离,从而支持消费者与提供者多对多数据访问,提高系统的灵活性与扩展性.
如图2所示,双Adapter 数据统一访问框架由数据消费端Adapter、中间数据模型、中间查询计划、数据提供者端Adapter 以及数据映射5 部分构成.
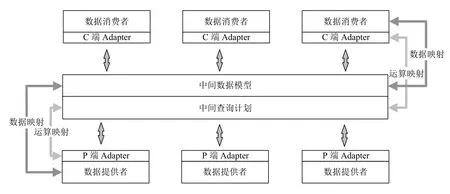
图2 双Adapter 数据统一访问框架
(1)数据消费者端Adapter是系统数据访问请求的编码器.它将消费者查询语句涉及的目标数据与中间数据模型进行映射,同时将查询语句的语义编码为中间查询计划.根据系统设计需要,数据消费者端Adapter还需对查询结果进行格式转换以满足消费者应用需求.
(2)数据提供者端Adapter是系统数据访问请求的解码器,它将中间查询计划解码为数据提供者可识别的查询语句,实现中间数据模型与数据提供者的数据映射.根据系统设计需要,数据提供者端Adapter 还需要将查询结果转换统一数据格式.
(3)中间数据模型为系统多源异构数据提供统一语义视图,它定义数据的统一表示方式,记录中间模型的元素构成与数据持有者的映射关系,支持数据的增、删、改、查、合并等操作.根据系统设计需要,中间数据模型还需定义通用数据格式以供数据消费者与数据提供者之间进行查询结果转换.
(4)中间查询计划将数据提供者和数据消费者接口对数据的操作进行抽象化处理,定义系统支持的运算类型,实现数据提供者与数据消费者查询操作与中间查询计划运算的相互转换.由于不同数据提供者和数据消费者对数据运算操作的支持程度不同,根据系统设计需要,还必须对不支持的数据操作进行补偿运算.
(5)数据映射将数据提供者所持有数据与中间数据模型进行映射,在映射过程中数据提供者根据中间数据模型的定义,将其所持有的数据按照映射规范向中间数据模型注册.在此过程中,数据映射规范需要适量增加或减少原有数据的限制以满足中间数据模型的定义.
4 框架实现
为了验证BAF4DUA 框架在实际系统中的应用,本文实现了一个多对多数据统一访问系统,其中数据消费者接口为标准查询语言,数据提供者接口为常用数据库.该系统中间数据模型使用实体与关系对数据进行统一表述,数据映射将数据库、WebService 等查询接口的数据对象映射为中间数据模型元素.中间查询计划选择四类运算形式化描述查询语句的语义信息,消费者与提供者Adapter 将各自接口与中间数据模型和中间查询计划进行适配.目前系统支持通过SQL、Cypher、MongoDB 等查询语言接口对不同数据提供者进行数据访问,在不影响系统其它组成部分的情况下,可实现数据库迁移、缓存、统一管理等应用需求.
4.1 中间数据模型与数据映射
中间数据模型对集成系统中的异构数据采用统一方式进行语义描述,系统数据用实体(Entity)与关系(Relation)两个概念对常见数据源进行描述[12].实体为具有相似意义的数据集合,实体元素的具体数据格式不限,既包括结构化形式的表数据,也包括非结构化形式的文档数据;关系为实体间的语义关联,可通过多种方式进行表示,关系表示形式包括实体条件表达式或存储的关系数据.中间数据模型的形式化表示如下:

其中,E表示实体集合,R∈(E×E)表示关系集合,S表示数据源集合,L表示用于实体与关系标识的标签集合,K表示L、S与E、R之间的映射关系,ρ表示S与R之间的数据映射方式.
异构数据源S包括两种形式:一是以标准查询语言为访问接口的数据库管理工具,如关系数据库、文档数据库以及图数据库等;二是其它非标准化数据访问接口,如WebService、Shell 命令以及文件系统等.S中的每个元素必须包含连接访问该数据源的所有参数,如连接字符串、URL 以及用户名密码等.
映射关系K由两部分构成:标签映射Kl:(E∪R)→L表示标签与ER 元素之间的映射关系,即实体集合与关系由一个标签唯一标识;数据映射Ks:(E∪R)→(S∪ρ)表示数据源与Entity、Relation 元素之间的映射关系,即Entity 与Relation 由数据源与数据映射方式构成.
针对不同数据源,数据映射方式ρ采用多种方法将异构数据源映射为Entity和Relation 元素.对于提供标准查询语言接口的数据源,可使用通用的数据映射规范自动将数据源映射到中间数据模型.如表1所示,将关系模型数据中的Table 映射为中间数据模型的Entity 元素,将“外键”或属性相关的逻辑表达式映射为中间数据模型中的Relation 元素;将文档模型数据源中的Collection 映射为中间数据模型的Entity,将文档的DBref 或属性的逻辑表达式映射为中间数据模型的Relation;将属性图模型数据源中具有相同Label的节点集合映射为Entity,而将具有同样Label的边集合映射为Relation.
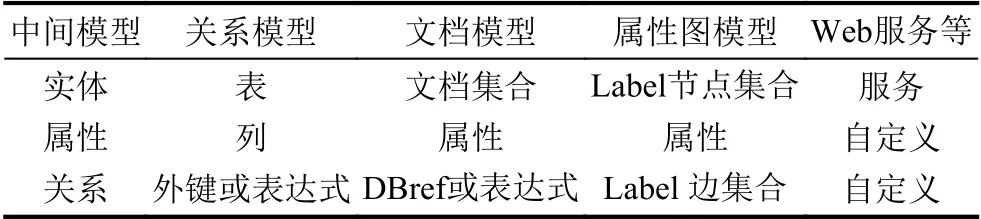
表1 数据映射关系
对于无标准查询语言接口的数据提供者,需要根据数据提供者的数据访问接口特点自定义数据源与中间数据模型的映射方式.例如WebService 接口与中间数据模型的映射需要根据服务URL、Token 以及业务参数等与实体、关系进行映射.
4.2 中间查询计划
查询计划是对查询语句所表达语义的形式化描述,它是一个节点为数据模型运算的树形结构.中间查询计划p:umsrc→umtarget描述了从数据umsrc向查询目标数据umtarget转换的运算过程,它代表了查询语句的查询目标,系统支持的运算类型越多,执行计划能够支持的查询功能越丰富.在实现过程中,我们选择了4 类中间数据模型运算作为中间查询计划的基础组成部分:
(1)scan(umsrc,umtarget,item)运算对参加运算的中间数据模型中实体与关系进行选择.其中item指umsrc中的实体或关系元素,scan运算将umsrc中的item元素加入umtarget.如果item类型为Relation,scan运算同时将与该Relation 关联的Entity 添加到umtarget.
(2)filter(umtarget,item,cond,type)运算对umtarget中Entity 或Relation 集合内数据对象进行条件约束.其中item指umtarget中的实体或关系元素,cond为item中数据对象满足的逻辑表达式条件,type为过滤运算类型.根据不同过滤运算类型,filter运算采用不同形式过滤umtarget中的数据.
(3)link(umsrc,umtarget,item1,item2)运算在Entity 元素item1与item2之间建立一个关系加入umtarget中.建立Relation的方式有两种:一是通过item1与item2之间的逻辑表达式创建一个临时Relation;二是从umsrc选择与item1、item2对应的Relation 加入umtarget.
(4)project(umtarget,cond)运算根据cond条件选择umtarget中的元素或元素内容保留参与后续运算.cond条件包括两类:umtarget中Entity 或Relation 元素;Entity或Relation 数据的属性、列等子元素.
4.3 消费者端Adapter 与数据提供者端Adapter
BAF4DUA 架构中适配器对数据消费者和数据提供者的数据查询接口进行转换翻译:第1 步,数据消费者端Adapter 将数据消费者查询语句编码为中间查询计划统一表示;第2 步,数据提供者端Adapter 将中间查询计划解码为数据提供者可识别的查询语句.通过中间查询计划对查询语句的统一形式化表示,BAF4DUA框架将查询语言接口与数据模型解耦.
查询语句在数据源执行过程中会解析节点为数据模型运算的逻辑查询计划树,数据源执行引擎遍历查询计划树依序执行运算节点.数据消费者端Adapter对查询语句的语义编码过程需实现中间查询计划与逻辑查询计划、中间数据模型与数据源的运算映射两部分内容:
(1)数据映射:主要过程是解析数据消费者请求的查询语句,获取查询语句的目标数据对象,根据数据映射方式ρ获取目标数据对象与中间数据模型Entity和Relation的对应关系,收集相应的数据作为后续运算参数.
(2)运算映射:主要过程是将数据消费者查询语句解析为逻辑查询计划树并自底向上遍历,根据根节点到当前运算节点路径计算逻辑查询计划树中的每个运算节点所处的状态并据此确定后续运算映射.逻辑查询计划树的运算节点与中间执行计划运算节点之间存在一对一、一对多、多对一以及多对多关系,根据运算映射关系生成中间执行计划的运算节点以及中间执行计划树.
与数据消费者端对查询语句的编码过程相反,数据提供者端Adapter对中间执行计划树解码操作,生成数据提供者查询语言接口的逻辑查询计划树.解码过程根据数据映射方式ρ从中间执行计划运算节点的参数中抽取出数据源的操作对象,实现中间数据模型与数据源的有效映射.根据中间执行计划运算节点与逻辑查询计划运算节点的对应关系生成逻辑查询计划树,进而生成目标查询语句提交给数据提供者执行.
5 案例示范
5.1 BAF4DUA 案例工具实现
根据第4 节提出的BAF4DUA 框架实现方案,本文实现了一个支持关系模型、属性图模型和文档模型与中间数据模型的相互映射,以及SQL、Cypher、Mongo 命令3 种查询语言的相互转换的案例工具.
如图3所示,BAF4DUA 案例工具的具体实现主要包括10 个类.UnifiedDataModel 类为Entity 与Relation 组成的图数据结构,在使用BAF4DUA 案例工具之前需根据数据提供者的数据进行初始化,通过UnifiedDataModel 类,查询语言转换过程中可以确定中间查询计划、数据提供者查询对象、数据消费者查询对象之间的映射关系.接口类Encoder 与Decoder 包含查询语言与中间查询计划UnifiedQueryPlan 进行转换的encode与decode函数.SqlEncoder、CypherEncoder以及MongoEncoder为Encoder 接口类的具体实现,其中SqlEncoder 首先利用Apache Calcite[13]将SQL 语句解析为SQL 查询计划,然后通过遍历SQL 查询计划将SQL 查询计划中的JOIN、FILTER 运算以及表达式转换为UnifiedQueryPlan 中对应运算Operator.类似的,我们使用开源工具Cytosm[14]以及Mongo-Shell-Like-Query[15]分别将Cypher 与Mongo 命令分别解析成相应的查询计划,根据4.3 节所述遍历该查询计划生成对应的UnifiedQueryPlan对象.SqlDecoder、Cypher-Decoder 以及MongoDecoder为Decoder 接口类的具体实现.其中SqlDecoder 假设最终生成的SQL 语句模式为:

图3 BAF4DUA 案例工具类
SELECT <RESULT>
FROM <TABLES>
WHERE <CONDITION>
根据UnifiedQueryPlan 类的Entities 与Relations成员生成SQL 语句的SELECT 与FROM 元素;通过解析查询计划中的运算Operator 生成SQL 语句的WHERE条件对结果进行过滤;类似的,CypherDecoder 主要针对如下Cypher 句式:
MATCH <ENTITY>
MATCH <RELATION>
WHERE <CONDITION>
RETURN <RESULT>
根据中间查询计划UnifiedQueryPlan 生成句式的各部分的内容;MongoDecoder 则将UnifiedQueryPlan中的Operator 运算统一组合成一个Pipeline,将Scan、Filter、Link 以及Project 四类运算转换为Mongo 命令Pipeline 中的JSON 运算对象,最后将整个Pipeline对象序列化为Mongo Shell 命令语句.
需要指出的是,本文中案例工具的实现方式存在一定的局限性,尤其是Decoder 部分的实现还有很大的提升空间.例如本文使用了固定的查询语句模式,根据中间查询计划分别转换为固定句式中的组成部分,而不是将中间查询计划直接转换为数据提供者查询语句对应的查询计划.除此之外,本文的案例没有对聚合查询、多语句查询等操作进行处理.
5.2 查询语言转换性能
为了验证查询语言转换对查询性能的影响,我们将生成的1 GB TPCH[16]数据导入关系型数据库MySQL、图数据库Neo4j 以及文档型数据库MongoDB 中,对TPCH 基准测试中单表查询语句Q1 与多表查询语句Q2的查询语言转换与数据查询时间进行了统计,其中MySQL、Neo4j和MongoDB 数据库的运行环境如表2所示,查询时间结果如表3所示.在数据导入过程中,TPCH 数据集的8 个文件分别导出为MongoDB的8 个Collection 以及Neo4j的8 类节点.根据TPCH提供的ER 模型,我们在Neo4j 中创建了节点之间的边.需要说明的是,TPCH 数据集的不同导入方式以及索引会对后续查询时间产生一定影响.
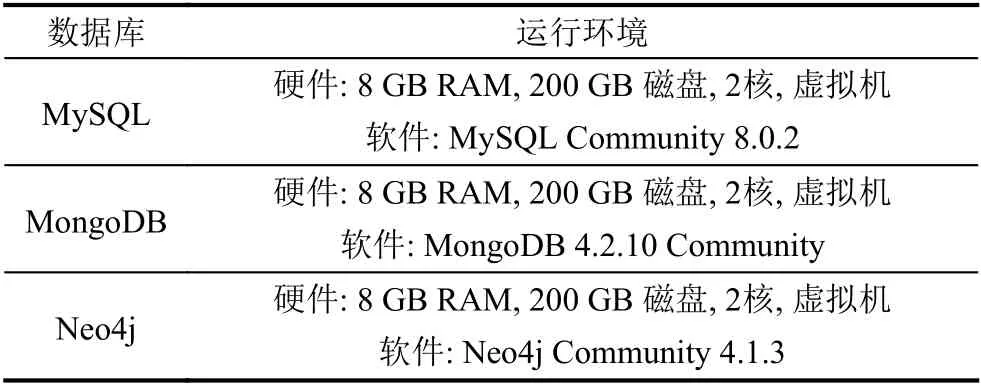
表2 数据库运行环境

表3 查询语言转换与数据查询时间(ms)
由表3可知,查询语言转换时间在70 ms 内,相对于数据查询时间占比最高不大于1%,并且随着数据量的增加查询语言转换的时间占比会越来越少.由于Mongo 命令的解码过程使用了第三方的JSON 转换工具,因此中间查询计划解码为MongoDB 接口的时间要比其它接口的解码时间更多,故而查询语言的编码时间均在10 ms 以下.总体而言,在提高开发效率与系统扩展性、满足数据统一访问的前提下,查询语言转换带来的查询性能损失在可接受范围之内.
5.3 查询语言转换应用案例
案例1.数据库缓存:为提高系统的响应速度,应用系统通常采用主数据库与缓存数据库相结合的方式管理业务数据,例如使用Redis对用户信息进行缓存.此时系统开发需同时使用SQL 与Redis 语言进行数据查询,如果能够将SQL、Mongo 命令以及Cypher 编码为中间查询计划,同时将中间查询计划解码为Redis 查询语句,那么系统就可以为不同主数据库增加缓存功能,并且保持系统开发的接口统一性.
为实现以上目标,系统需要一个数据提供者端Adapter 将中间查询计划转换为Redis 查询语言.其中数据映射将Redis 数据库中具有一定模式的Key 定义为中间数据模型的Entity;Entity的属性值与Key 值相对应;Relation 则根据用户定义表达式进行Entity的关联.中间查询计划与Redis的具体运算映射方式如表4所示.

表4 中间查询计划与Redis 运算映射
以客户Customer 数据为例,假设客户数据在Redis中Key的存储模式为<Cust_ID_USERNAME_NATION,customer_object_hash>,那么Customer 实体定义为以字符串“Cust”开头的Key,实体属性ID、USERNAME、NATION的值分别对应以“_”进行分割的每个值.如图4所示,假设系统要查询“李”姓中国籍客户,那么使用SQL、Cypher 以及MongoDB 命令进行查询时会首先编码为中间查询计划,然后再转换为Redis查询语句,最后实现Redis对3 类主数据库的缓存.

图4 Redis 查询语言转换案例
案例2.数据统一管理:科学数据管理系统通常会查询多个数据源,甚至会调用不同学科的数据源来验证假设的真伪.国家重点研发计划“科学大数据管理系统”项目为用户提供包括天文、高能物理和微生物3 种异构数据在内的多元异构数据的统一访问接口.以高能物理数据处理系统EventDB[17]为例,它通过分布式存储与数据索引,能够对高能物理实验中产生的EB级事例进行存储与查询.EventDB的接口形式为特定命令,如有以下查询命令:time=178789800~178807800&detID=1&channel=12&pulse=0~255&eventType=0,其含义为查询2017年8月31日15:50:00 至2017年8月31日20:50:00 之间5 小时内1 号探测器、12 号通道、0 号事件的脉冲跨度的变化情况.
数据提供者Adapter的数据映射需根据科研用户的查询需求和习惯,根据实验因素与中间模型进行映射.例如相同特征的事例映射与Entity 集合对应;实体属性为EventDB 中事例的相关数据值;Relation 根据自定义表达式进行Entity 关联.中间查询计划与EventDB命令的映射如表5所示.

表5 中间查询计划与EventDB 运算映射
假设用户习惯按照探测器进行事例查询,EventDB中的探测器编号为n的事例与Entity 映射,事例的time、detID、channel、pulse 与eventType 等属性为Entity的属性值.如图5所示,如果要查询3 号探测器在2017年8月31日15:50:00 至2017年8月31日20:50:00 之间内的所有脉冲变化,那么SQL、Cypher、MongoDB的查询语句可根据以上映射关系首先编码为中间查询计划,然后转换为EventDB 查询命令.

图5 EventDB 查询语言转换案例
6 结论与展望
在大数据时代,集成系统使用多样化工具对内外部数据进行统一管理分析,这增加了系统开发、数据管理工具更新迁移以及数据统一管理等任务的接口适配成本.本文提出了一种基于查询语言转换的多源数据统一访问框架BAF4DUA,该框架特色之处在于采用了双Adapter 模式:数据消费者Adapter 先将消费者数据访问接口语言转换为中间数据模型的查询计划,而后通过数据提供者端Adapter 将中间查询计划转换为数据提供者的数据访问接口.通过BAF4DUA 框架,可实现数据消费者的查询语言接口与数据源的数据模型相分离,数据消费者和数据提供者可采用即插即用的方式增加或更新相应的Adapter,增加了系统的灵活性与扩展性,更符合集成系统多对多数据访问的特点.
本文所提BAF4DUA 框架的局限性在于仅考虑了单一使用场景下的数据查询操作,还需要进一步完善以适应更复杂的数据统一访问应用场景.后续研究可从以下几个方面进一步拓展:(1)设计与实现支持具备count、sum 等更丰富功能的查询运算类型;(2)设计与实现查询数据位于不同数据库场景下的数据处理方案;(3)设计与实现智能化数据统一插入存储方案.
