基于ANN的新型MOFs性能预测①
2021-10-11毕志远阳庆元俞度立
赖 欣,卢 罡,王 磊,毕志远,阳庆元,俞度立,4
1(北京化工大学 信息科学与技术学院,北京 100029)
2(北京化工大学 信息科学与技术学院 智能无人系统研究中心,北京 100029)
3(北京化工大学 有机无机复合材料国家重点实验室,北京 100029)
4(北京化工大学 软物质科学与工程高精尖创新中心,北京 100029)
近年来,以机器学习、深度学习为代表的人工智能理论和方法受到人们的广泛关注.尤其是谷歌DeepMind 团队开发的AlphaGo,在围棋领域中的精彩表现令人印象深刻[1,2].在此之后,DeepMind 又迅速对计算机视觉等领域做出了可喜成果[3].如今,机器学习已被广泛应用于自然语言处理[4,5]、数据挖掘[6]、证券市场分析[7]、机器人应用[8,9]、医学诊断[10,11]等领域.
在材料科学领域,材料的各种反应、合成中会产生海量的数据,而将善于从海量数据中发掘规律的机器学习方法应用于材料科学领域便顺理成章[12,13].实验研究发现,由于MOFs 具有较高的孔隙率和具有规律性、可组合性、多元性等特点,能够高效地通过计算机模拟预测MOFs 材料的物理化学性质[14].通过GCMC (Grand Canonical Monte Carlo)分子模拟方法对MOFs 进行高通量筛选已经被证实是一种有效的实验手段[15,16].目前应用的分子模拟方法主要有分子动力学、蒙特卡罗、密度泛函理论等.在探寻物理化学性能优秀的MOFs 材料过程中,需要对材料的结构特性、物理性质、化学性质等进行搜索分析,通常可以应用GCMC 分子模拟方法.然而,可能存在的MOFs结构存在于一个近乎无穷大的样本空间,要将所有MOFs 材料逐一进行分子模拟计算,从而挑选出性能出众的材料,其计算成本是无法估量的.近年来,人们已经开始关注如何在准确预测MOFs 性能基础上,提高计算效率.Simon 研究组将少量MOFs 吸附材料放入综合数据库中,对其进行GCMC 模拟,找出吸附材料的物理结构特性与其对CH4吸附能力之间的关系[17].其中用到的MOFs 数据有Zeolites[18]、hypothetical MOFs(hMOFs)[19]、Porous Polymer Networks (PPNs)[20]、hypothetical Zeolitic Imidazolate Frameworks (hZIFs)[21]以及Computation-Ready Experimental (CoRE) MOF[22]等MOFs 材料数据.材料数据包含多种性质特征,利用机器学习挖掘其定量构效关系(Quantitative Structure-Property Relationship,QSPR)[23],可将这些结构性质作为参数,对材料分子的气体吸附能力进行回归分析和预测.Fernandez 等通过晶体学的RDF 分析方法,利用RDF 得分评估MOF,同时利用多元线性回归、支持向量机等方法,构建了处于不同压力环境下,MOFs 材料针对CO2、N2与CH4的气体吸附与RDF得分的QSPR模型[24].之后,Fernandez 小组利用孔隙率和孔径等物理结构变量,预测MOFs对CH4的吸收,并在实验中得到R2=0.85的结果[25].Fernandez 等还应用了分类方法,基于QSPR预测表现最佳的CO2吸附MOFs 材料,达到94.5%的准确率[26].Sezginel 等经过QSPR 分析,提出一种多变量线性模型,利用该模型与MOFs的结构特性,包括表面积、晶体密度、孔隙率、孔径以及等量热吸附(Qst),预测出MOFs 吸附剂对CH4的吸收能力,实验结果发现,孔隙率与等量热吸附是影响MOFs 气体吸附能力的关键因素[27].Chung 等利用遗传算法,对捕获CO2的MOFs进行筛选,在计算效率上获得了50 倍左右的提升[28].这些工作在材料筛选效率上有着出色的表现.
本文工作受到Chung 等2016年关于遗传算法(Genetic Algorithm,GA)方面工作[28]的启发.他们在材料数据库中通过遗传算法进行材料筛选,但是对于遗传算法生成的库中没有的新个体并未进行进一步的评估.本文用原始MOFs 数据集训练人工神经网络(Artificial Neural Network,ANN),并用ANN对遗传算法生成的新型MOFs 个体的性能进行预测评估,从而搜索对CH4气体具有较高吸附性的MOFs.我们首先通过GCMC 模拟计算文献[28]中数据集的每个MOFs在一定条件下对于CH4气体的吸附性能,然后用该结果训练一个ANN,使其能够评估和预测MOFs 基因与CH4气体吸附性之间的构效关系.实验结果表明,基于ANN 搜索并预测的材料吸附性能平均表现优于原始材料数据库中的最优材料,证实了该方法的可行性和有效性.
1 面向GA和ANN的MOFs 数据集
1.1 针对MOFs 材料数据进行基因编码
为了通过GA 搜索新型MOFs,需要根据MOF的特征设计GA 所需的基因编码.为MOFs 进行基因编码的方式没有特定的规则,但应能够尽量反映MOFs的结构特征及各组分、配体之间的组合特征,从而在GA 运行过程中,基因编码的变化能够反映出MOFs 组合结构的变化.
本文的原始数据来自于WLLFHS hMOF 数据集[19].该数据集中MOFs的参数由Wilmer 研究组汇编和验证,具有丰富多样的MOFs 材料结构,适合进行分子模拟筛选与机器学习分析.文献[28] 将该数据集中的MOFs 进行基因编码,该编码利用6 个整数作为“基因”,每个“基因”都表示了一种分子的特性或者功能[28].本文沿用该基因编码,具体设定如下:
第1 位基因,表示潜在互穿能力,共4 种,用0 至3的整数表达;第2 位基因,表示实际互穿能力,共4 种,用0 至3的整数表达;第3 位基因,表示无机配体,共5 种,用0 至4的整数表达;第4 位基因,表示主要有机连接单元,共40 种,用0 至39的整数表达;第5 位基因,表示次要有机连接单元,共40 种,用0 至39的整数表达;第6 位基因,表示化学官能团,共15 种,用0 至14的整数表达.
根据上述设定,MOFs 材料的搜索空间大小为:4×4×5×40×40×15=1920 000.在这种编码方式下,构象异构体之间以及只有官能团定位不同的MOFs 之间具有相同的基因编码.Chung 等[28]分析发现,构象异构体之间、只有官能团定位不同的MOFs 之间不仅结构类似,化学性能也相当.因此,他们从类似的MOFs中选择一个作为代表,缩减数据集的规模.最终,文献[28]整理了具有51 163 个MOF 基因编码的数据集.
1.2 计算对CH4 气体的吸附值
在文献[28]整理的数据集基础上,我们进一步采用自主开发的力场参数和自主研发的模拟计算软件,通过GCMC 模拟计算其中每个MOFs在298 K (K为开尔文,热力学温度单位,下同)条件下对CH4气体的吸附能力.
MOF 材料和气体分子之间的相互作用采用范德华力(vdW)和库仑势的组合来表示[29].其中范德华力采用Lennard-Jones (LJ)方程描述.LJ 势能参数取自UFF 力场,CH4分子势能参数取自TraPPE 力场.不同原子之间的LJ 势能参数采用Lorentz-Berthelot 混合规则计算.
在前期的研究工作中,我们利用量子密度泛函和Monte Carlo 模拟相结合的跨尺度手段开发出了新的力场[30],其中基于量子力学层次的密度泛函理论(Density Functional Theory,DFT)[31]计算被用于确定材料与气体分子之间的精确相互作用参数.DFT 计算基于Materials Studio 软件中的Dmol3 模块,采用GGA 交换泛函Perdew-Burke-Ernzerhof (PBE)和含轨道极化函数的双数值轨道基组(DNP),并结合Grimme的色散校正作用(DFT-D2),对MOF 中获取的模型簇进行优化,并计算出不同距离下无机单元与CH4之间的相互作用能.在此基础上,通过Monte Carlo 模拟实现了MOFs对CH4气体在298 K 条件下吸附量的量化,计算得到了数据集中每个MOF对CH4气体的吸附值.
本文基于自主研发的模拟计算软件HT-CADSS(http://jshx.buct.edu.cn/yjcg/bzxcg/86799.htm),采用GCMC 方法研究了298 K 条件下,文献[28]的数据集中51 163 个MOFs对CH4气体的吸附能力.在GCMC 模拟中,采用Peng-Robinson (PR)方程将压力转换为逸度作为计算的输入值.所有的MOFs 均视为刚性材料,并在三维尺度上采用周期性边界条件.计算范德华作用的截断半径(cut-off)设置为1.4 nm.对于每一个吸附模拟过程,模拟总步数为3000 万步,前1500 万步用于系统平衡,后1500 万步用于获得热力学性质的统计平均值.对CH4单组分吸附模拟,涉及分子的平移、插入和删除.在无限稀释条件下,MOF 骨架与气体分子之间相互作用力的相对强弱采用无限稀释吸附热进行表征.无限稀释吸附热采用基于正则系综(NVT)的Widom测试粒子方法[32]计算.
经过以上的计算,最终得到51 163 个经过基因编码的MOFs对CH4气体的吸附值,最大为528,其基因编码为2-0-0-29-29-12.数据示例如表1所示.
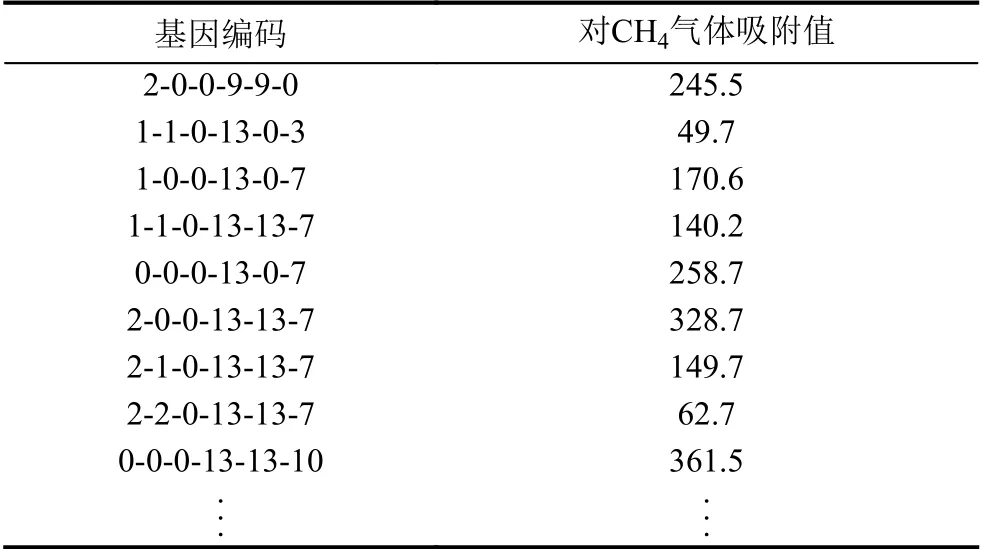
表1 数据示例
1.3 单特征分析
1.1 节中,一个MOF 被编码成了一个具有6 个基因的染色体,6 个基因分别代表了它的6 个结构特征.本节中,我们分别分析了这6 个特征与MOFs的CH4气体吸附能力之间的构效关系,结果如图1所示.
图1(a)为MOFs 潜在互穿能力与MOFs对CH4气体吸附能力的关系.WLLFHS 数据库以材料结构的多样性著称,因此,具有不同潜在互穿能力的MOFs在CH4气体吸附能力上分布较为均匀,体现了该数据集中样本的多样性和完整性.图1(b)显示了在实际互穿能力的维度上,数据集中MOFs对CH4气体吸附能力的分布.可以看到,实际互穿能力越高的MOFs对CH4气体吸附能力相对越差.这是由于互穿较多的MOFs稳定性较高,一定程度上阻碍了气体分子的吸附[33].对于图1(c)中的无机节点而言,带有锌或铜桨轮与对位连接的MOFs,在分析结果中表现出更强的CH4气体吸附性能,这是由于部分MOFs 材料在活化的过程中,遇金属簇配位溶剂分子或水分子易脱落,形成不饱和金属位点,从而增强了对CH4气体的吸附作用.另外,研究表明,当MOFs 材料与水接触时,结构的结晶性会在一定时间内消失.大多数情况下,水的存在是不可避免的,具有二价金属离子(例如Zn2+和Cu2+)的MOF在有水的情况下极易出现这种不稳定性[34,35].主有机连接单元与次有机连接单元对MOFs的CH4气体吸附性能的影响分别如图1(d)和图1(e).可以看到,表现良好的有机连接单元主要集中在12-30 号区间内,而31-39号有机连接单元在低性能MOFs 中缺失.图1(f)显示,含有0 号、7 号、10 号、12 号化学官能团的MOFs 材料对CH4气体吸附能力突出,其中0 号表示不考虑官能团影响,其余3 种官能团分别对应甲基、乙基、丙基[28].我们认为,这是因为这类烃基官能团与CH4有相似的机构和化学性质.
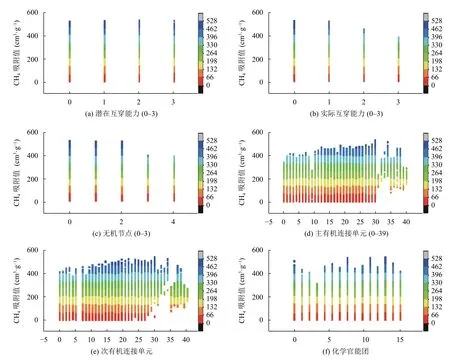
图1 各基因编码与CH4 气体吸附能力的构效关系
对于单特征的分析表明,MOFs对CH4气体吸附能力受多种因素共同作用影响,包括MOFs 材料的拓扑结构、有机配体和无机单元的结构、官能团的选择等.单纯的针对其中某一方面进行修改,并不能保证有效提升MOFs 材料对于CH4气体的吸附能力.这也进一步体现了应用包括ANN在内的机器学习方法发掘这种非线性构效关系的意义.
2 ANN 模型的训练
对于GA 产生的新型MOFs 个体,从仅有的6 个基因位点的值构建MOF 结构,再生成相应的数据进行GCMC 模拟计算,从而进行性能评估,将是一个非常繁琐及耗时的过程.因此我们提出将MOFs的基因编码作为输入,GCMC 模拟计算的目标性能作为输出,训练ANN 作为挖掘MOFs 构效关系的机器学习模型,从而能够对GA 生成的新的MOFs 个体进行性能预测评估.
2.1 ANN 模型评价指标
ANN 通过模仿人类大脑的思维方式,进行大规模高维数据处理和分析.一个ANN 包含输入层、隐含层和输出层,其中隐含层可以有多层.ANN的本质是非线性函数映射,通过对高维数据的低维非线性映射,转变为人类可理解的结果输出.由于需要预测MOFs对CH4气体的吸附值,因此我们将ANN 构建为输出层只有一个神经元的回归神经网络,从而输出一个实数值.作为预测具体数值的回归ANN,其评价指标R2的值越接近1,模型的预测性能越好,其定义如下:

其中,n是测试集中MOFs 个体的数量,为第i个MOFs 结果的预测值,是通过GCMC 模拟得到的结果.是所有的平均值.另一个评价指标均方误差(Mean Square Error,MSE),是预测值和真实值之间误差的平方和,其定义为:
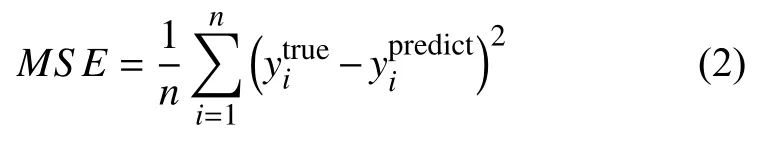
2.2 数据集准备
对1.2 节生成的数据集中51 163 条MOFs 数据的CH4气体吸附值以20为长度进行区间划分,进而对数据的分布情况进行初步统计,结果如图2所示.统计结果显示,在该数据集中,存在极少数CH4气体吸附值大于480的MOFs.这种数据分布的倾斜,会影响模型的学习和预测性能.因此,我们从吸附值大于280的MOFs样本中随机重复抽取一定数量的样本,然后对每一个样本的吸附值引入以该吸附值为均值、方差为1的高斯随机误差.经过这样的随机上采样后,数据集扩充到67 878 条,其分布如图3所示.
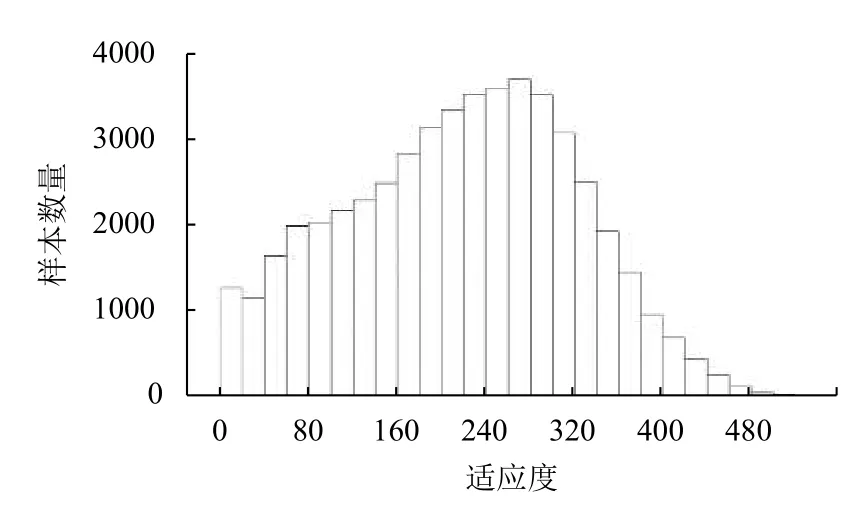
图2 原始数据集分布直方图
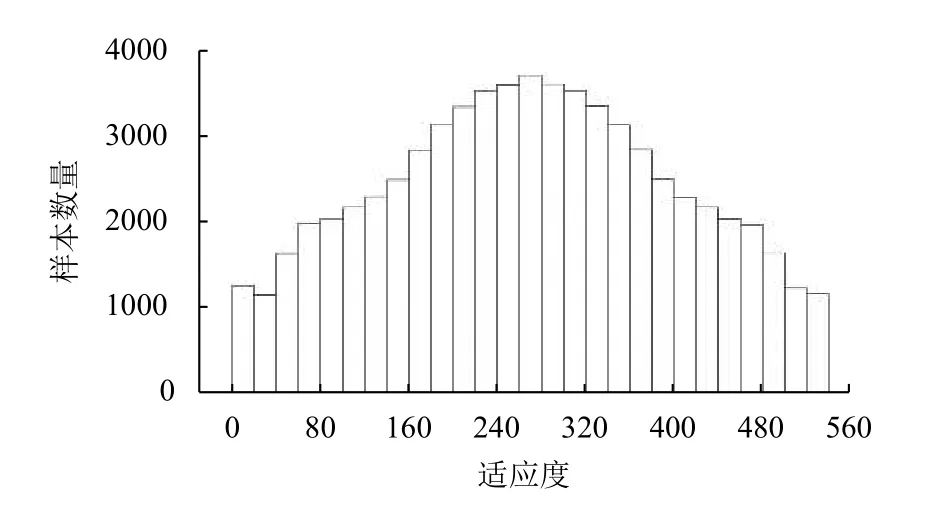
图3 上采样后数据集分布直方图
对经过上采样后的67 878 条数据的各特征值进行最大最小标准化预处理,以消除数据集不同特征取值范围不同对模型训练的影响,并加快模型训练的收敛速度.最大最小标准化的方法如式(3)所示:
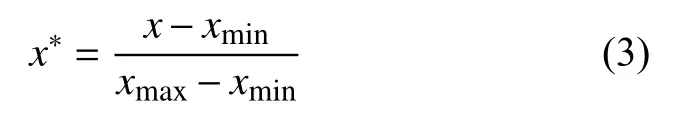
其中,xmax是样本数据的最大值,xmin是样本数据的最小值.
经过以上预处理后,我们将所有67 878 条数据随机抽取80%作为训练集,剩余20%作为测试集.
2.3 BPNN和RBFNN
本文分别采用BP 神经网络(Back Propagation Neural Network,BPNN)和径向基函数神经网络(Radial Basis Function Neural Network,RBFNN)对GA 生成的新型MOFs 个体进行了针对CH4气体吸附性能的预测评估实验.利用BP 神经网络与径向基函数神经网络进行针对CH4气体吸附性能预测评估的优点主要有:
(1)BP 神经网络拥有高容错性,并行计算,自适应和可学习等优点,在针对MOFs 材料吸附CH4气体能力这类非线性关系的预测方面具有显著的优势.
(2)径向基神经网络在本文中设置为BP 神经网络的对照,作为一种性能优秀的前馈型神经网络,理论上可以逼近任意非线性函数,具有全局逼近能力,从根本上解决了BP 神经网络由于梯度下降所导致的局部最优问题,且由于其整体网络结构紧凑,收敛速度快.而BP 神经网络中权值调节采用负梯度下降法,收敛速度递减而较慢.
(3)BP 神经网络学习速率是固定的,因此对于一些复杂问题,BP 算法需要的训练时间可能非常长,这主要是由于学习速率太小造成的.而径向基神经网络是高效的前馈式网络,它训练速度相对较快的同时,具有BP 神经网络所不具有的最佳逼近性能和全局最优特性.
2.3.1 BPNN的构建和训练
BPNN是ANN 中经典且常见的一种神经网络.结构上,BPNN 包含输入层、隐含层和输出层.其本质是通过对高维数据的低维非线性映射,转变为人类可理解的输出结果.由于1.1 节中将MOFs 结构编码为具有6 个基因的染色体,故本文BPNN的输入层相应地设置为6 个神经元,对应6 个基因的输入,而输出为1 个神经元,用于预测吸附值.在保持较为简单的网络结构的前提下,经过多次调整、实验,最终确定了2 个隐层后增加1 个批归一化层的基本结构.具体地,隐藏层的激活函数使用ReLU 函数,输出层以Sigmoid 函数作为激活函数.训练的epoch 设为100,batch_size 设为128,采用随机梯度下降(Stochastic Gradient Descent,SGD)迭代训练模型,并采用Adam 方法进行优化,学习率设为0.002.其中,激活函数是一种神经网络常用的非线性函数,用于实现对上一层神经元输出的线性组合进行非线性变换.批归一化(Batch Normalization,BN)层的Scale and Shift 操作,可以加速训练过程的收敛、控制过拟合、降低网络对初始化权重的敏感程度,并允许使用比较大的学习率.
通过用训练集进行5 折交叉验证,最终网络结构调整实验的结果如表2所示.表中结果按照R2降序排列.可以看到,2 个隐层神经元个数分别为32和15 时的模型准确度最高.BPNN 训练过程需要调节的参数个数为6 ×32×15+15=2895.
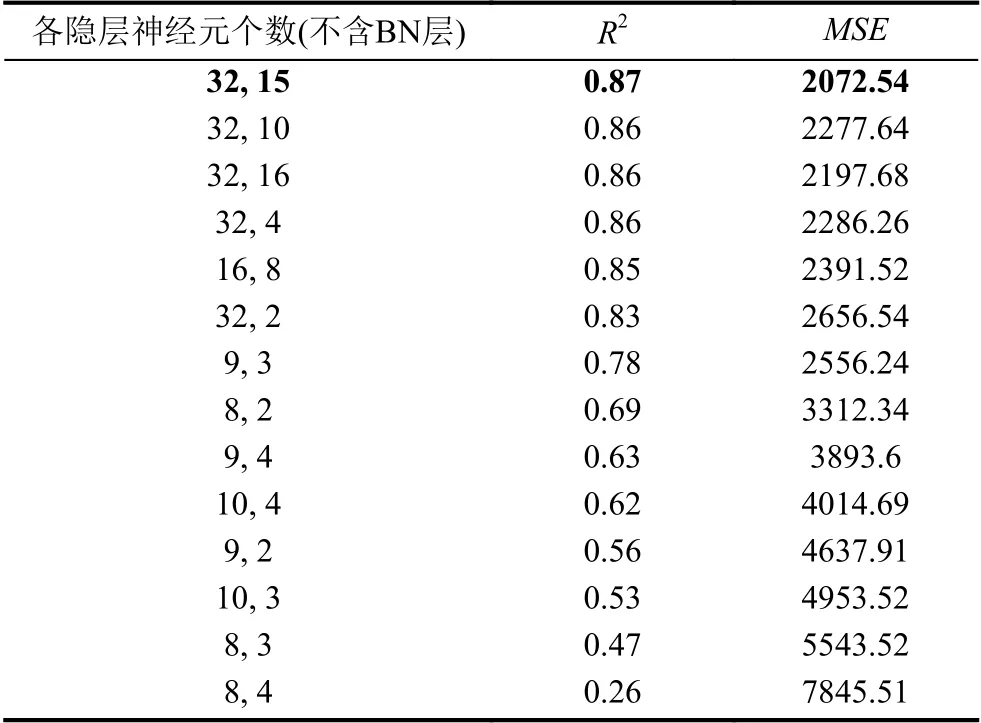
表2 BPNN 结构调节实验结果
2.3.2 RBFNN的构建和训练
作为比较,我们还构建了另外一种常见的人工神经网络——径向基函数神经网络.RBFNN是一种前馈型的3 层神经网络,激励函数使用径向基函数.其隐含层中神经元与输入、输出层的神经元之间的关系不再是全连接,而是用径向基函数代替.本文中,采用常用的高斯函数作为径向基函数.与BPNN 相比,RBFNN通常泛化能力更强,能够避免BPNN 可能出现的局部最优问题,理论上能够在充分训练的情况下完全逼近要拟合的数据.该网络可以方便地增加神经元进行训练,直到满足精度要求为止,这样的网络结构拥有更为突出的定向信息处理能力.本文通过调整神经网络的结构,将隐含层神经元个数从100 个开始,逐次递增,每次调节增加100 个神经元,观察评价指标R2与MSE的数值变化情况,从而确定最优的网络结构.
使用与2.3.1 节相同的训练集进行5 折交叉验证,比较训练结果,得到当隐层节点设置为600 个时,其MSE=2264.83、R2=0.854为最优,即RBFNN的结构确定为6-600-1.调节隐含层神经元个数的比较结果如表3所示.从中可以看到,隐层节点数为800 时,结果与隐层节点数为600的相差无几,但从模型复杂度、参数数量等角度综合考虑,最终,选取隐层节点数为600为最合适的网络隐层节点个数.由于径向基函数神经网络是局部逼近网络,其对于输入空间的某个局部区域只有少数几个连接权值影响输出,故而该网络实际需要调节的参数数量大大小于BP 神经网络.

表3 RBFNN 结构调节实验结果
2.3.3 BPNN和RBFNN的性能比较
通过上述对BPNN和RBFNN 结构的优化,我们分别训练并确定了BPNN和RBFNN的结构和参数.该过程已经初步显示了二者的性能.图4和图5分别展示了二者在测试集上回归预测的具体性能表现.
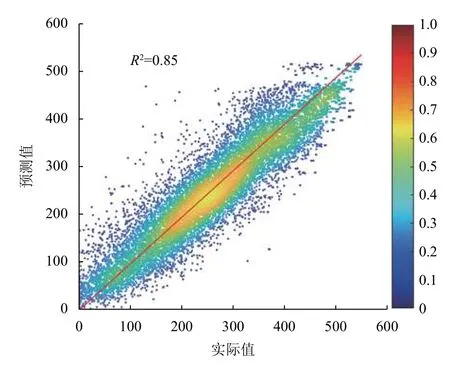
图4 BPNN 网络模型在测试集上的回归散点图
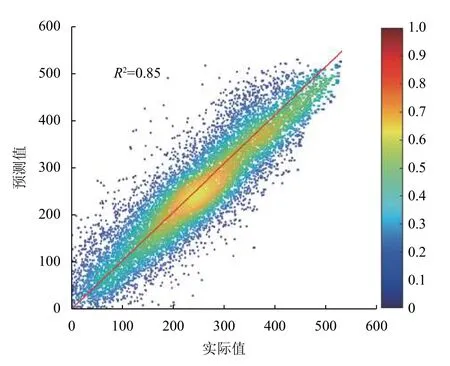
图5 RBFN 网络模型在测试集上的回归散点图
上述模型回归结果图中,颜色表明数据点的密集程度,颜色越接近红色,数据分布越密集.当实际值与预测值接近时,数据点会均匀分布在红色标识实线及两侧.从图4中可以直观地看出,采用2.3.1 节所得的6-32-15-1 结构的BPNN 时,在测试集上的实验结果R2=0.85;类似地,RBFN 以2.3.2 节所得的隐层节点数为600 时,其在测试集上得到R2=0.85.可见,两种模型在测试集上均可以实现较为准确的回归.这些结果表明基于训练数据构建的非线性模型具有可以预测新型MOFs 材料气体吸附性能的能力.
3 实验结果
基于1.2 节构建的基础数据集,以及2.2 节对于数据集的处理和划分,我们应用GA 实现了对MOFs 个体的演化搜索,并应用ANN对搜索到的新型MOFs 进行了基于CH4吸附值的性能预测评估实验.
3.1 基于GA的MOFs 搜索
GA是一种具有生存与检测特征、不断进行迭代过程的一种全局优化搜索算法.在迭代过程中,会产生大量通过基因编码表示的个体,每个个体的基因特征会随着进化的进行,根据优胜劣汰的基本原则进行代际遗传,从而产生优秀个体,实现在搜索空间中对最优解的搜索.
GA的主要参数包括种群规模M、进化代数N、遗传交叉率a,以及遗传变异率b.其中,a决定了两个个体进行交叉操作从而产生新子代的概率,b为一个个体的某个随机基因发生变异的概率.GA 中的种群规模,代表着数据域内数据点的密度,密度越大,其覆盖最优解的可能性越高,即对求解最优解越有利.但相应的,其计算量也将会快速增加;对于GA 进化代数的限制,是为了让算法能够在合理的实验时间内完成迭代搜索;GA 中的变异概率与交叉概率设定,是为了让数据域内的数据点保持相对分散的分布,避免陷入局部最优的困境,文献[28] 中的设定为<M=100,N=100,a=0.65,b=0.05>.此外,适应度函数也是GA的一项重要设定.通过适应度函数,GA 计算个体的适应度,评估个体的性能.适应度越高,种群越朝着有利于发展的方向进化.文献[28]采取的操作是,在原数据集中查找新生成的个体,若找到,则通过GCMC 模拟方法计算它对CO2的工作容量、CO2/H2的选择性,以及对CO2的吸附值,分别以这3 个指标作为个体的适应度值以评估个体性能;若新生成的个体不在原数据集中,则重新进行基因操作,直到生成数据集中存在的个体.也就是说,文献[28]中并未对原数据集中不存在的新个体进行评估并加入新的子代.
本文以1.2 节计算的MOFs对CH4气体的吸附值F作为适应度,参照文献[28]中的参数设定,以产生新型MOFs 个体的数量X、搜索到最优个体所进化的代数G,以及搜索到的最优个体吸附值F为评价指标,针对M和N两个参数进行了6 组参数设定的实验.具体步骤为:
(1)在原始数据集上构建初始种群.初始种群中的个体可从数据集中进行多次随机选择并择优,也可加入一些人为设定的策略.例如,文献[28]中人工选择100 个MOFs 个体构建初始种群,从而保证所设计的每个基因都至少出现一次,个体演化过程中不会有基因的缺失.
(2)执行遗传算法,开始种群的演化.这个过程包含了遗传算法中的经典操作,例如从种群中进行个体的择优、交叉、变异,从而产生下一代种群,不断迭代,直到算法停止
(3)在GA 迭代演化过程中,对于产生的MOF 个体,如果存在于原数据集中,则直接使用其已经计算得到的目标性能指标值作为个体性能的评估结果,并加入下一代种群;否则将新个体暂存.
(4)算法的停止条件,可以为指定的演化迭代次数、指定的搜索到新的优秀个体数量等.
按照上述实验步骤不断循环迭代,本文依据实际实验条件,综合考虑遗传算法的计算效果与计算周期,调整实验参数,经过6 组实验最终将遗传算法参数设定为<M=50,N=200,a=0.65,b=0.05>,如表4所示.
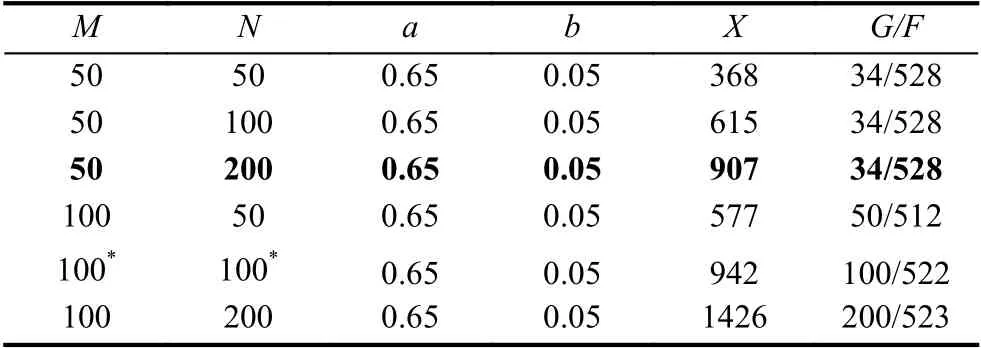
表4 GA 参数组合实验结果
最终,GA 算法搜索到907 个原数据集中不存在的新MOFs 个体.同时我们观察到,原始数据集中,第1 个基因(潜在互穿能力)的值均不小于第2 个基因(实际互穿能力)的值.这是因为,潜在互穿能力表示理论上可能的互穿能力,所以实际互穿能力不会超过它.因此,我们将907 个新型MOFs 个体中不符合该条件的144 个删除,剩余763 个新型MOFs 个体作为实验对象.
3.2 ANN对新型MOFs 个体的性能预测
本文分别采用前文所述的BPNN和RBFNN对GA 搜索到的763 个新型MOFs 个体进行CH4气体的吸附值预测,取二者预测的对CH4气体吸附值最高的前10 位MOFs 个体进行比较,如表5所示.
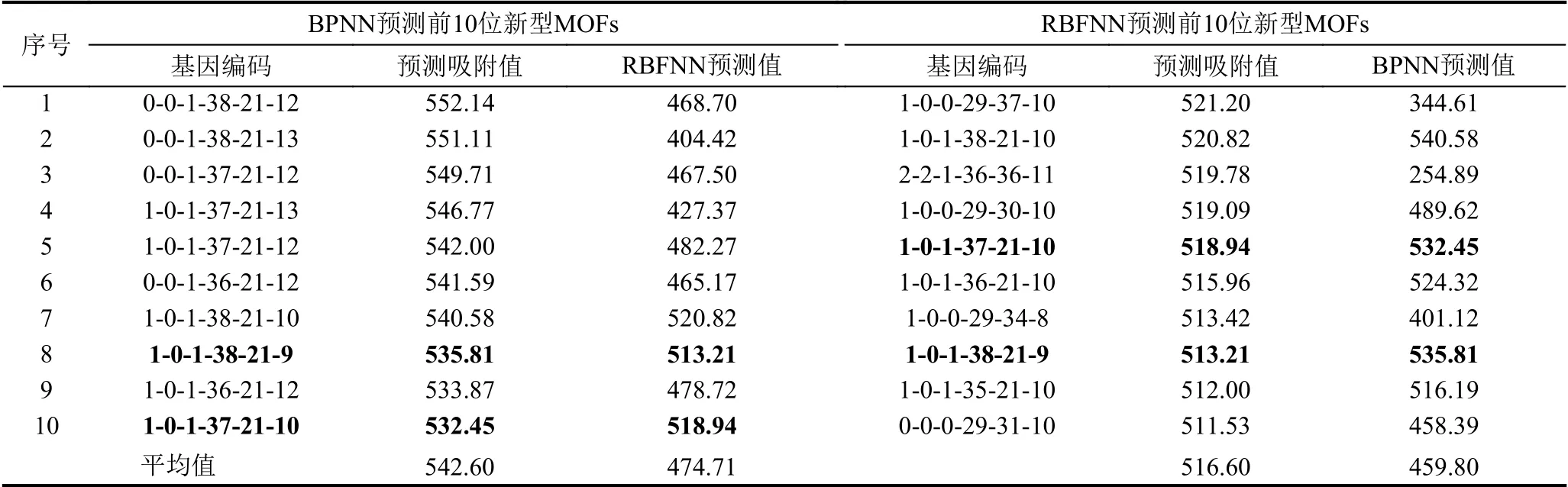
表5 BPNN和RBFNN 分别对新型MOFs 个体的CH4 气体吸附值预测结果TOP10对比
从两者结果比较可以看出,BPNN 预测的前10 种新型MOFs 材料,其CH4气体吸附能力的均值为542.60,略高于RBFNN 预测结果前10 名的516.60.有趣的是,BPNN 预测的前10 位MOFs,对CH4气体的吸附性能均在530 以上,高于原始数据集内的最大值528,突破了训练集的限制,具有更好的泛化能力.而RBFNN 预测的CH4气体吸附值最大为521.20,未能突破训练集的范围.从基因编码的结构上看,BPNN对于结构相近的MOFs 个体,预测的CH4气体吸附值也较为接近.例如,预测基因编码结构为0-0-1-38-21-12的CH4气体吸附值为552.14,与其相近的基因编码结构为0-0-1-38-21-13的CH4气体吸附值为551.11.这个结果具有一定的合理性.另一方面,RBFNN的预测结果具有更强的多样性,得到的高CH4气体吸附值的基因编码结构与BPNN 预测得到的有很大不同.
具体地,BPNN 预测得到的高CH4气体吸附值的MOFs 个体,其潜在互穿性仅限于1 或0,而实际互穿性均保持在0;而RBFNN 预测得到的高CH4气体吸附值的MOFs 个体,潜在互穿性和实际互穿性均出现了2的取值.对于第3 个基因编码,BPNN 预测得到的高CH4气体吸附值的前10 名均为1,而RBFNN的结果中还包含0.根据文献[28]的补充材料中的设定,该位基因为0和1 所表示的无机配体,如图6所示.
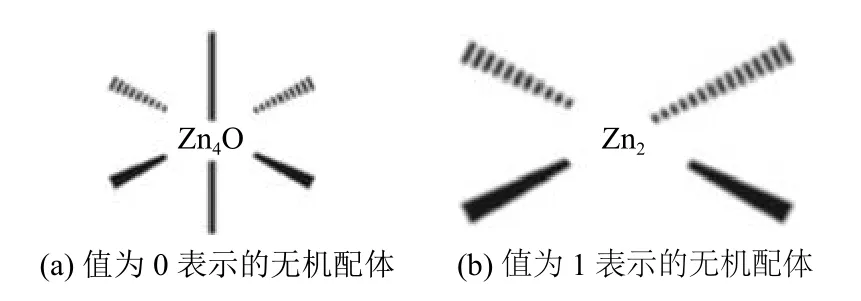
图6 无机配体的表示[28]
BPNN的结果中,主要有机连接单元出现了36、37、38,而RBFNN的结果中还出现了29和35.第5 位的次要有机连接单元,BPNN 预测得到的结果中均为21,RBFNN的结果中除了21,还出现了30、31、34、36、37.根据文献[28]的补充材料中的设定,它们表示的结构如图7所示.
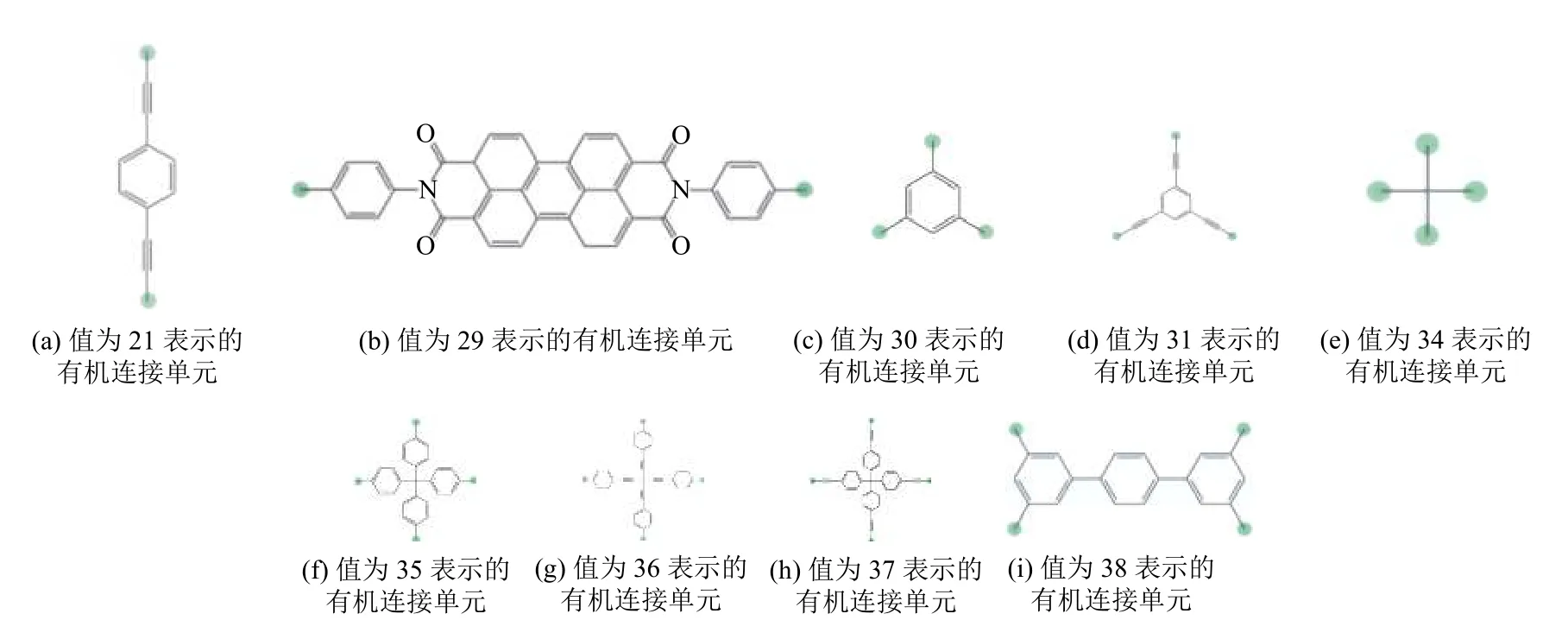
图7 有机连接单元的表示[28]
最后一位基因值表示的化学官能团,BPNN 预测的结果中出现了9、10、12、13,而RBFNN的结果中则为8、9、10、11.根据文献[28]的补充材料中的设定,它们表示的结构如图8所示.
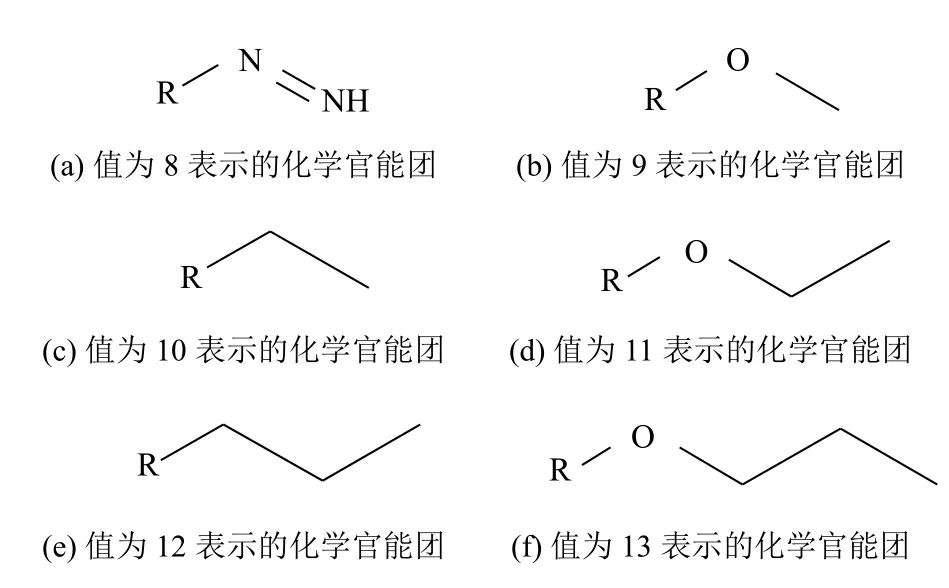
图8 化学官能团的表示[28]
以上结果表明,特定的几种结构将给MOFs 带来较高的CH4气体吸附值.值得注意的是,BPNN和RBFNN 均预测出1-0-1-38-21-9、1-0-1-37-21-10 结构的MOF 具有相对较高的CH4气体吸附值,这值得后续的研究工作进一步关注.
4 结论与展望
本文首先根据我们提出的力场参数,基于现有的MOFs 数据集,通过GCMC 模拟计算构建了面向一定条件下CH4气体吸附能力的MOFs 数据集,并通过上采样技术调整了数据集的分布.其次,以该数据集分别训练了BPNN和RBFNN 模型,使其具备较强的预测CH4气体吸附性的能力.然后,通过GA 基于MOFs 数据库搜索新型的MOFs 个体.搜索时,对于搜索到的数据集中已有的MOFs,直接查询数据集中其对应的CH4气体吸附值;对于搜索到的不在数据集中的新型MOF,则暂存它们.最后搜索出763 个新型MOFs 个体,并分别用训练好的BPNN 与RBFNN对其CH4气体吸附性进行预测,得到了优于原始数据集的结果.通过以上过程,实现了通过GA 搜索新型MOFs,并用ANN对其进行性能预测,从而实现高性能MOFs的高效搜索与评估.
实验结果表明,BPNN在模型的准确性,泛化能力方面略优于RBFNN,而RBFNN 预测结果则更具备多样性.二者的预测结果均表现出特定的结构对MOF 性能有一定的影响.对于二者均预测出具有较高CH4气体吸附值的两种MOF 新型结构,则需要进一步的研究和验证.
未来可进一步拓展现有工作,从而引入多种机器学习方法作为参照进行比较和相互佐证.对GA 参数更深入的优化研究也是一个有挑战性的课题方向.同时,可考虑结合实际化学材料领域中的自组装技术,通过材料组装,模拟,优化出新材料的分子结构,然后再利用GCMC 手段,添加材料的实际化学特征值数据,完善成果.
