合理对待学术不端检测结果
2021-10-09李艳娜
李艳娜,毛 星,董 里
(《消防科学与技术》编辑部 天津300381)
0 引 言
随着信息检索技术的发展,信息的透明化和公开化逐步增强,学术不端行为被发现的几率也越来越大。近年来不断有学术不端行为被曝光,涉及人员包括在校生、教授甚至院士等各类群体,由此也引发了关于学术不端的大讨论。
学术不端一般指不符合学术道德或规范的学术行为。美国联邦学术不端行为政策(The US Federal Research Misconduct Policy)中,将学术不端定义为“在提出观点、实施研究或总结研究成果的过程中,伪造、篡改或抄袭的行为”[1]。其他学术不端还包括:把属于同一研究成果的素材“支解”为多篇“香肠论文”、同行评议造假、故意删除数据、在文章中挂名等行为。Joeri等[2]对比利时几所医学机构的315名学术人员进行问卷调查时,将学术不端行为分为12种,并按照严重程度分为3类,包括学术欺骗行为(伪造数据、篡改、剽窃)、严重学术不端行为及一般学术不端行为。结果发现15%的应答者承认近3年内有过伪造、篡改或剽窃数据的行为,学术欺骗行为在年轻学者中更加普遍。另外,72%的应答者表示发表成果的压力太大。作者认为,发表成果的压力和学术不端现象的严重程度之间有较强的相关性。
关于学术不端的讨论由来已久。在CNKI中以“Scientific misconduct”为篇名检索得到的结果中,最早的文献发表于1985年,早期文献以外文为主,且多见于医学类期刊,内容多涉及临床试验方面学术成果的学术不端现象。1996年,陈民[3]介绍了美国当时关于学术不端行为如何界定的争议。这是早期关于学术不端的介绍性质的中文文献。2000年后,关于学术不端讨论的中文文献逐渐增多,反映了国内学术界对于学术不端行为关注的变化,如图1所示。2003年,洪明苑[4]针对科学活动中的不端行为进行讨论,分析当时学术和社会环境下学术不端行为产生的原因,并从有效监督方面提出治理学术不端行为的建议。2003年5月7日,科学技术部、教育部、中国科学院、中国工程院、国家自然科学基金委员会联合发布《关于改进科学技术评价工作的决定》,明确提出:加强科学道德建设,营造良好的创新文化,坚决反对任何形式的学术不端行为。并进一步提出:对于浮夸、剽窃、抄袭、造假和拼凑数据的单位或个人,以及借评价之虚、行谋取私利之实的学术不轨行为,一经查实,除相关管理部门给予行政处分和公开通报之外,要禁止直接责任者在未来一段时间申请政府投资的任何科技项目。
2009年初,中国学术期刊(光盘版)电子杂志社与同方知网共同开发的“科技期刊学术不端文献检测系统”面世,期刊编辑部逐步采用该系统对投稿文章进行检测,由此也引发了关于学术不端检测系统使用的争议。从图1中2009年后几年间相关文献量的大幅度增加也可以看出这一点。
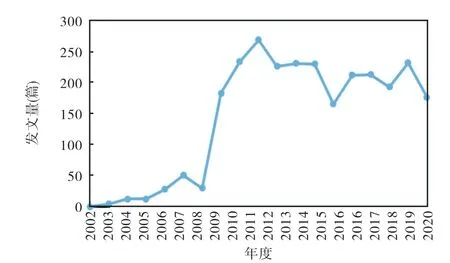
图1 知网2002—2020年“学术不端”文献发文量变化Fig.1 Number of papers about 'academic misconduct'from 2002 to 2020 in CNKI
笔者拟结合目前国内主流的2种文献检测系统——CNKI、万方检测,对比系统检测功能,结合检测结果与编辑部对检测结果的使用,以及因复制比高而催生的洗稿、拼凑等行为,对学术不端检测系统的利与弊进行探讨。
1 学术不端检测系统的现实意义
学术不端检测系统是应对学术不端行为而诞生的,系统主要针对学术不端中的剽窃、伪造、篡改、不当署名、一稿多投等行为进行检测。用户将文章上传到检测系统后,文章会被与系统数据库中已有的成百上千万学术文章、书籍、会议论文、学位论文,以及海量网页内容进行比对,按照一定的算法得到文章的相似度数值,并生成详细的检测报告,显示与已有文献疑似重合的内容以及是如何重复的。最终,用户可以根据检测结果判断文章的原创性。
随着学术不端检测系统在各期刊编辑部的使用日益广泛,一定程度上遏制了论文抄袭行为,保证了文章的原创性。以笔者所在的《消防科学与技术》期刊为例,2012—2019年投稿文章相似度(知网检测)变化见表1。可以看出,相似比高于20%的投稿及占比均随时间呈现下降趋势,从侧面也反映了检测系统对学术不端行为的抑制作用。
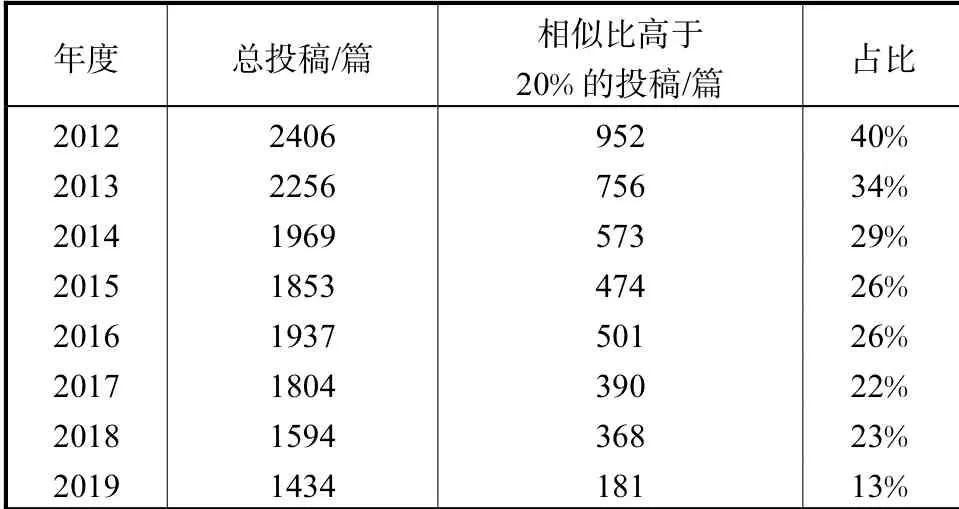
表1 《消防科学与技术》2012—2019年投稿统计Tab.1 Statistics of contributions of Fire Science and Technology from 2012 to 2019
2 知网检测和万方检测系统对比
文章通过对国内使用较为广泛的两大检测系统的功能进行对比,主要从比对范围、相似比计算方法、参数定义、检测报告等方面进行分析,以进一步探讨检测系统使用中存在的问题。
2.1 比对范围
知网针对期刊论文的检测系统为“科技期刊学术不端文献检测系统”(简称AMLC)。万方针对期刊论文的检测系统为“学术预审版”(Academic Plaglarism Prevention Service,简称APPS)。两者均是面向期刊论文检测的,文献检测范围对比见表2。
从表2可以看出,两者收录资源丰富,均涵盖了学术期刊、博硕士论文全文、会议、专利、互联网资源、英文数据库等。其中图书资源和源代码库为ALMC的检索范围,APPS不包括;而“中国标准全文数据库”为ASSP的检索范围,AMLC不包括。另外,与期刊论文检索相关性最大的为期刊库。CNKI检索期刊库范围为中国学术期刊网络出版总库(即通常所说的CNKI数据库),出版内容以学术、技术、政策指导、高等科普及教育类期刊为主,内容覆盖自然科学、工程技术、农业、哲学、医学、人文等各个领域。ASSP检索期刊库范围为中国学术期刊数据库,该数据库是万方数据知识服务平台的重要组成部分,集纳了多种科技及人文和社会科学期刊的全文内容。分析发现,两者均全文收录国内大部分期刊文献资源。区别在于,万方与知网数据库均有独家与唯一授权期刊,即独家与唯一授权数据库进行数字出版的期刊。其中,知网独家与唯一授权期刊见图2。

表2 AMLC和APPS文献检测范围对比Tab.2 Comparison of literature test range of AMLC and APPS
综合上述分析,两者的查重数据库有重叠交叉,但并不完全相同,而且具体到某领域来看差别并不小。以笔者所在期刊为例,与期刊栏目有交叉重叠的期刊中,将近一半为知网独家授权期刊。即假如论文抄袭了某知网独家授权期刊的内容,但是用户使用的检测系统为万方检测的话,那么极有可能检测不到相似部分,导致检测结果不准确,失去参考意义。笔者将某篇文章分别在2个系统中进行检测,得到的结果如图2所示。可以看出,知网检测相似比远远高于万方的检测结果,原因就是《安全与环境工程》为知网独家授权期刊,所以知网的检测范围中包含了这篇被重复文献,而万方则未包括,因此未检出,导致两者的检测结果差距较大。笔者认为,取消独家,学术资源知识共享,打破学术信息的垄断才是解决之道。

图2 同一文献的检测结果对比Fig.2 Comparison of test results of same literature
2.2 检测报告对比
AMLC提供简洁、全文(标明引文)、去除本人文献、全文对照4种类型的检测报告单。ASSP提供原文标注报告、详细片段报告和全文比对报告3种类型的检测报告单。鉴于AMLC的全文对照报告和ASSP的详细片段报告展示的内容较为详尽,下面仅对这两者进行对比分析。将同一篇文献分别上传至2个检测系统进行检测,得到的检测报告中相似比详细指标如图3所示。

图3 AMLC和APPS检测报告详细指标Fig.3 Detailed index of AMLC and APPS test reports
对比图3(a)和图3(b)可以看出,虽然指标的名称不同,但主要指标的含义是相同的,均包括了引用复制比、去除自引复制比、单篇最大文字复制比等指标。针对同一篇文献,AMLC的综合检测结果为1.2%,而ASSP的综合检测结果为5.14%。分析原因发现,两者检测得到的“单篇最大文字复制比重复文献”并非同一篇文献。进一步针对重复内容进行对比,如图4、图5所示,可以看出,万方检测单篇最大重复内容为英文部分,包括作者单位的英文及英文摘要。而在知网检测中,文章的英文部分不参与检测。笔者认为,这一点上知网的处理更加合理。

图4 知网检测单篇最大重复内容Fig.4 Content of maximum repetition of a single article by CNKI
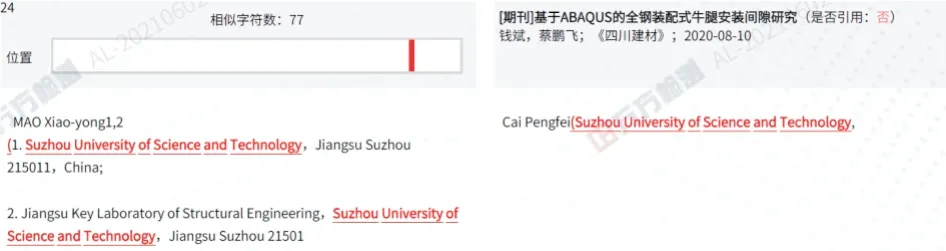
图5 万方检测单篇最大重复内容Fig.5 Content of maximum repetition of a single article by APPS
图6 为待检测文章重复相同文献的万方检测结果。对比图4和图6可以看出,知网对句子是否重复的认定更加灵活,连续的几句话中,即使有个别地方内容不一致,只要大部分内容被检测为重复,则会认定为连续重复。

图6 相同文献万方检测结果Fig.6 Test results of same literature by APPS
2.3 其他
AMLC和ASSP的检测报告均以不同颜色标示了文字复制部分和引用部分。不同的是,AMLC中,系统会对自动识别待检测文献的题目、作者、单位及参考文献、原创性声明等信息,并在检测时将这些内容排除在外。而ASSP检测时只排除参考文献,其他内容全部参与检测,其他内容全部相同的情况下更容易出现检测结果相对较高的情况。
此外,AMLC新增加了对表格、公式及图片OCR识别处理后的检测功能,一定程度上提高了文献检测的准确率。
3 对学术不端检测结果使用的讨论
近年来,为严厉打击学术造假、学术不端等行为,维护期刊形象,赢得读者信任,对投稿文章的复制比检测成为编辑部审核稿件的第一关。相似比几乎成为作者投稿的“敲门砖”[5]。然而,机器查重也有局限性,由于是基于算法的对文字重复的简单计算,简短语句的相同也会被认定为重复,而这种重复在论文写作中是无法避免的。因此,重复率的高低不能完全界定一篇文章的质量,过度依赖重复率也是一种偷懒的做法,甚至会导致作者为了降低重复率而采用一些不合理的手段,如颠倒语序、同义词替换、长句拆分、将文字转换为图片格式等。反之,重复率低也未必没有抄袭的可能,从洗稿服务已由前些年的人工洗稿发展到AI智能洗稿可见一斑。技术是中立的,关键在于使用的人,正确对待查重结果,保证人工审核的质量才是解决问题的最好办法。
