基于高光谱数据的乳香产地快速鉴别
2021-10-05程介虹陈争光
程介虹,陈争光
(黑龙江八一农垦大学信息与电气工程学院,大庆 163319)
乳香为橄榄科植物卡氏乳香树(Boswellia carterii Birdw)及同属植物鲍达乳香树(Boswellia bhawdajiana Birdw)的树皮渗出的树脂,具有活血行气止痛,消肿生肌的功效,在中医药中有着较高的药用价值。其种类分为索马里乳香、埃塞俄比亚乳香、印度乳香三种,不同产地的乳香的药用价值不同。由于三种乳香外观等较为接近,很难通过性状鉴别其产地。通过阅读文献,发现现有研究主要通过高效液相色谱法、液质联用法和气质联用法等鉴别,如:于新兰等[1]通过气相指纹图谱结合化学计量学,对三种乳香进行鉴别,王赵等[2]通过4 种鉴别技术(性状、显微、TLC 和HPLC 指纹图谱鉴别)系统地比较了3 种药用乳香的异同;孙磊等[3]通过色谱指纹图谱结合化学计量学,可以精确区分和系统评价3 种药用乳香;Michael Paul 等[4]通过薄层色谱法鉴别三种不同乳香树脂。但上述检测分析方法在操作、运行、维护等方面的成本较高,耗时较长。高光谱图像技术具有波段多、光谱分辨率高、图谱合一等优点,检测过程中无需对样品进行预处理、快速无损,被广泛应用到农业[5]、医疗[6]、化工[7]等方面的检测分析。因此,将具有快速、无损、批量检测特性的高光谱技术引入中药鉴定领域,试图寻找一种方法可以快速无损地进行乳香产地判别,以解决中药流通中乳香产地混杂的问题。
研究以三个产地的乳香样品为研究对象,提取乳香样本的高光谱数据中的近红外光谱数据,对近红外光谱进行归一化预处理,然后通过连续投影算法(Successive Projections Algorithm,SPA)进行特征波长提取,在特征波长基础上,分别基于极限学习机(Extreme Learning Machine,ELM)、支持向量机(Support Vector Machine,SVM)、线性判别分析(linear discriminant analysis,LDA)三种方法建立分类判别模型,进行乳香产地的预测判别,以实现高光谱技术对不同产地乳香种类的鉴别。
1 材料与方法
1.1 样本数据
所用数据来自于中国中医科学院中药资源中心,利用Hyspex 系列高光谱成像仪,收集索马里、印度、埃塞俄比亚三个产地的410~2 500 nm 乳香光谱数据。数据为高光谱原始数据(DN 值数据),已经过设备自带的RAD 校正,数据由两个镜头获取(410~990 nm 以及950~2 500 nm),光谱分辨率为6 nm。
选取11 个乳香样品的高光谱数据,其中3 个为索马里产地的乳香样本、4 个为印度产地的乳香样本、4 个为埃塞俄比亚产地的乳香样本,每个样本选取波长范围为950~2 500 nm 的近红外范围的光谱数据,共计288 个波长点。
1.2 SPA 特征波长选择算法
由于光谱数据波段多、波段高相关性,会引起“维度灾难”。特征波长选择是用来克服“维度灾难”和模型化高维数据的一种重要方法,可以有效解决这一问题。在扫描样品的光谱时由于仪器及环境的干扰,样本的光谱数据中通常会含有大量无信息变量甚至干扰变量,波长间也会存在严重的共线性及冗余信息,基于有效波长所建立的模型的稳健性和预测精度通常较全谱模型有所提高。因此,波长选择已经发展成为了光谱定量分析中的一个重要步骤。特征波长选择是从全谱数据中提取部分涵盖有用信息的光谱,去除噪声光谱及无用信息,建立一个更为简约、稳定的光谱模型,可以极大地减少变量数目,加快模型的计算效率,提高模型的稳健性[8]。
SPA 是由Araujo 等[9]提出的一种以消除变量间共线性为主要目的的特征波长选择算法,该方法主要原理是利用向量的投影分析,对全谱数据的有效变量进行提取,消除冗余信息及无信息变量[10]。假设已给出初始波长k(0)和所需提取波长数目N,算法步骤为[9,11-12]:
Step 0:在第一次迭代(n=1)之前,将校正集Xcal的第j 列光谱数据赋值给xj,j=1,…,J,J 为总波长数。
Step 1:没有被选择的列向量的集合记为S,S={j,1≤j≤J,j∉{k(0),…,k(n-1)}}
Step 2:计算xj在子空间正交于xk(n-1)的投影,,j∈S,其中P为投影算子。
Step 3:令k(n)=arg(max‖Pxj‖),j∈S
Step 4:令xj=Pxj,j∈S
Step 5:令n=n+1,如果n<N 返回Step 1 循环。
End:最后得到的波长为{k(n);n=0,…,N-1}
其中k(0)和N 的选择是很关键的一个步骤。为了得到全局最优结果,k(0)的取值是在1~J 之间变化。N 的变化范围是:1≤N≤Mcal,Mcal 为校正集样本数,具体取值由模型的误差决定。
1.3 分类建模方法
1.3.1 ELM 判别方法
极限学习机[13]是2004 年由南洋理工大学黄广斌副教授提出的一种新型单隐层前馈神经网络(SLFN),具有结构简单、学习速度快、非线性处理能力和全局搜索性能良好等优势。ELM 只需设置网络中隐含层的神经元数和激活函数[14],输入层和隐含层的连接权值、隐含层的阈值可以随机设定,且不需要更新调整,相比于传统的神经网络(BP、RBF),其网络参数的随机赋值避免了多次迭代耗时长和易陷入局部最小值的缺点,使得ELM 在学习速率和泛化能力方面具有较强的优势。
1.3.2 SVM 判别方法
支持向量机是1995 年由Cortes 和Vapnik 首先提出的,是一种非线性的统计学习方法,抗噪性能强、效率高。它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。其基本原理是将输入数据空间映射到高维空间,寻找一个最优分离曲面,使数据的间隔尽可能大,从而得到一个全局最优解,以达到分类的目的[15]。SVM 的关键在于核函数,较为常用的核函数包括线性核函数、多项式核函数、径向基核函数以及sigmoid 核函数。
1.3.3 LDA 判别方法
线性判别分析是1936 年由Ronald Fisher 最早提出的,又称为“Fisher 判别分析”,它是一种模式识别的经典方法,属于有监督的判别方法。其基本原理是找到一个投影方向,将高维的向量投影到最优的鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果,使得向量在新的子空间有最大的类间聚类和最小的类内距离[16],通俗的说就是每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。其计算量较小,能够从高维数据提取出主成分信息,以提高分类的准确度[17]。
1.4 数据分析工具
实验所用软件包括MATLAB R2015b、The Unscrambler X 10.3(64-bit)和ENVI 5.5(64-bit)。MATLAB 是由美国MathWorks 公司出品的一款较为常用的数据处理软件,可实现数值分析、用户界面、编程语言、图像处理等多种功能,为图像处理及建模仿真提供高效全面的解决方案。The Unscrambler 是一款多元数据分析软件,具有较强的回归、分类以及预测的建模工具,操作简便,易于使用。ENVI 是一款遥感图像处理软件,具有信息提取、图像分类、数据融合变换等多种技术,包含处理高光谱数据的多种工具。
感兴趣区域的提取在ENVI 软件中实现,光谱数据的预处理在Unscrambler 软件中实现,变量选择、图形的绘制、三种分类模型(极限学习机、支持向量机、线性判别分析)的建立及预测判别等在MATLAB中实现。
2 结果与分析
2.1 光谱数据特征
高光谱图像为三维数据块,第一维和第二维为图像大小,第三维为近红外波长信息。为了提取乳香样本的近红外信息,利用ENVI 软件提取乳香高光谱图像的感兴趣区域(region of interest,ROI)的近红外光谱数据,每个高光谱图像选取7 个ROI,计算ROI内的平均光谱值,以此平均值作为该样本的一条近红外光谱数据,每个样本收集7 条光谱曲线,共收集77 条光近红外光谱曲线(图1),其中埃塞俄比亚产地28 条,索马里产地21 条,印度产地28 条。为消除数据之间的量纲影响,对原始光谱数据进行Min-Max 归一化预处理,公式如下:
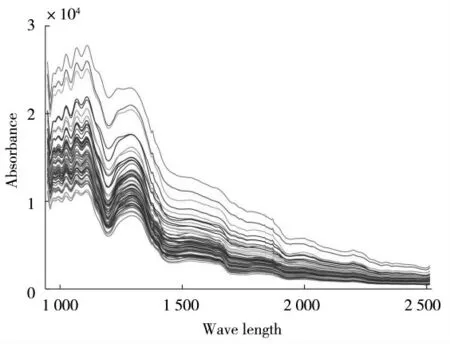
图1 原始光谱图Fig.1 Original spectrum
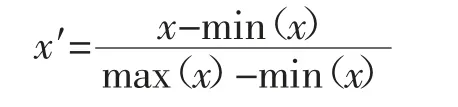
其中,min(x),max(x)分别是x 中最小值和最大值。通过Min-Max 归一化处理可以将数据映射到(0,1)之间,可以消除样本表面散射、光程变化的影响,降低同一样品多次测试间误差[18]。预处理后的光谱图如图2 所示。由图2 可以发现预处理后的光谱数据在一定程度上消除了基线漂移、强化了谱带特征、可以清晰分辨波峰波谷,所以后续的波长选择及模型建立均基于预处理后的光谱数据进行。
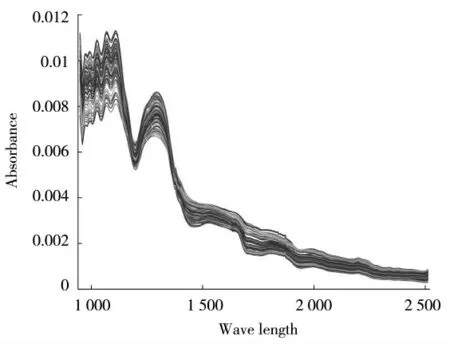
图2 预处理后光谱图Fig.2 Pre-processed spectrum
2.2 样本集划分
SPXY(sample set portioning based on joint x-y distance)算法是一种能够同时考虑样本光谱数据信息与理化性质特性的样本集划分方法,将77 个样本通过SPXY 划分为75%建模集和25%预测集,建模集包含57 个样本,预测集包含20 个样本。其中建模集包含22 个埃塞俄比亚产地、17 个索马里产地、18个印度产地的乳香,预测集包含6 个埃塞俄比亚产地、4 个索马里产地、10 个印度产地的乳香,然后分别赋值作为判别依据,将埃塞俄比亚产地的乳香赋值为1,索马里产地的乳香赋值为2,印度产地的乳香赋值为3,以便进行后续分类模型的判定。
2.3 特征波长选取
由SPA 方法选择特征波长建立多元线性回归模型,设置N 的最大最小值分别为:Nmin=5、Nmax=56,选取RMSEV 最小值对应的波长个数即为最终的特征波长个数。图3 中的正方形标记所示为SPA 多元线性回归模型选择的变量数,RMSEV 的最小值为0.192,此后各模型的RMSEV 值基本稳定,不再大幅度降低。此时特征波长N 的个数确定为20 个,图4中方块所对应的20 个点即为SPA 选择的最佳特征波长,分别为949、954、965、1 123、1 167、1 199、1 216、1 336、1 396、1 412、1 423、1 450、1 548、1 608、1 717、1 881、1 935、2 006、2 240、2 300 nm。其中分布在1 900 nm 区域的波长,对应于乳香结构中-COOH 化学键的吸收;分布在1 015、1 195 nm 区域的波长,对应于乳香结构中-CH3化学键的吸收。
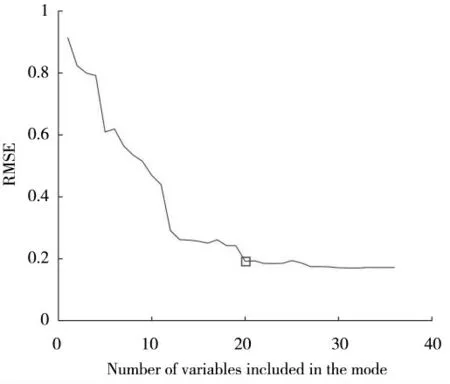
图3 模型选择的变量数Fig.3 Number of variables selected by the model

图4 SPA 所选特征波长点Fig.4 Characteristic wavelength points selected by SPA
2.4 建立分类模型
2.4.1 ELM 分类模型
通过研究发现“Sigmoid”激活函数较“Sine”和“Hardlim”函数具有更高的预测精度和稳定性[19],所以选择“Sigmoid”函数为激活函数。一般情况下,隐层节点数小于或远小于训练集样本数,即:隐层神经元个数=训练集样本数* 隐层神经元数目的比例参数(0.2~0.5),所以隐含层神经元数目设置为20 个。
由表1 可以看出,采用ELM 对三种产地的乳香建立判别模型,基于特征波长提取后的SPA-ELM 模型预测集准确率高达100%,而原始光谱ELM 模型的预测集准确率仅为85%,结果表明,基于SPA 算法提取的20 个特征波长能代替原始光谱信息,不但可以降低数据冗余度,减少模型的输入量,还可以提高预测的准确率。可见,连续投影算法结合极限学习机建立的分类模型可以有效识别出三种不同产地的乳香,基于SPA-ELM 和高光谱技术对乳香产地判别是一种有效的方法。

表1 ELM 预测模型性能比较Table 1 Performance comparison of ELM prediction model
2.4.2 SVM 分类模型
以多分类SVM 建立乳香产地分类模型,构造多个二分类模型,将每个二分类的模型结果组合起来以实现多分类SVM 模型。在上述四种核函数中,径向基(RBF)函数在小样本的情况下更容易获得好的结果,所以选用径向基核函数建立SVM 分类模型,采用网格寻优法和五折交叉验证得到最优参数——惩罚因子C、核参数σ。SVM 对全谱及特征波长选择后数据的分类建模预测结果如表2 所示。

表2 SVM 预测模型性能比较Table 2 Performance comparison of SVM prediction model
由表2 可以看出,采用SVM 对三种产地的乳香建立判别模型,基于特征波长提取后的SPA-SVM 模型预测集准确率为85%,而FULL-SVM 模型的预测集准确率仅为70%,表明,特征波长选择在一定程度上对模型的精度有所提高。
2.4.3 LDA 分类模型
LDA 对全谱及特征波长选择后数据的分类建模预测结果如表3 所示。

表3 LDA 预测模型性能比较Table 3 Performance comparison of LDA prediction model
由表3 可以看出,采用LDA 对三种产地的乳香建立判别模型,基于特征波长提取后的SPA-LDA 模型预测集准确率高达100%,而基于原始光谱的LDA模型的预测集准确率仅为80%,SPA 特征波长选择后的LDA 判别模型与全谱的LDA 判别模型效果相比,预测准确率有所提升,说明波长选择后保留了对建模有益的变量,消除了冗余干扰信息变量。并且,SPA-LDA 是一种较为有效的方法,可以进行乳香产地的预测判别,以实现高光谱技术对不同产地的乳香种类鉴别。
3 讨论
从上述三种分类模型所得的结果可以看出,其中SPA-ELM 和SPA-LDA 的分类精度优于SPASVM,其原因可能是因为ELM 可以有多种方式投影到高维,而且训练速度快,我们可以通过训练多种ELM 模型,从中选择较好的一部分,然后再bagging,组合起来加强效果,所以获得了较优的结果。而SVM算法处理高维数据具有较大优势,但首先即对全谱数据进行了降维处理,这可能使得SVM 无法发挥优势,所以较SPA-ELM 和SPA-LDA 模型的分类精度略差。所提出的SPA-ELM 和SPA-LDA 两种分类模型均获得了100%的分类判别结果,可以进行乳香产地的预测判别。相比于前人的试验结果,如:王赵等[2]通过TLC 指纹图谱鉴别对3 种药用乳香进行区分,但处理方法繁杂,需要对乳香进行前处理;许佳等[20]建立了乳香药材的高效薄层色谱指纹图谱,与数码轮廓图谱结合分析比较,对不同产地的乳香进行鉴别、归类。但同样需要对乳香进行甲醇超声提取等前处理,操作较为复杂。而本文所提出的方法,无需对乳香样本进行前期化学处理,操作便捷,并且判别的准确率较高,可以准确判别三种乳香的产地,高光谱分析是一种有效可行的方法能够进行乳香产地判别。
4 结论
为减少建模所需的波长点和计算工作量,得到预测能力强、鲁棒性高的模型,对归一化预处理后的数据采用SPA 算法提取特征波长,分别建立ELM、SVM、LDA 三种分类模型,然后通过比较全谱及特征波长选择后数据的分类建模结果,寻找一种有效的方法可以进行乳香产地判别。结果表明:三种分类方法下,特征波长选择后的判别模型相较于全谱的判别模型预测准确率均有所提升,表明波长选择消除了冗余变量,提高了模型预测精度。其中,SPA-ELM、SPA-LDA 两种方法的预测准确率均为100%,两种方法均可实现乳香产地的快速、无损鉴别。综上所述,利用高光谱技术对乳香产地进行检测是可行的。研究为乳香产地的快速无损检测分析提供参考。
